kubernetes 已经成为容器编排领域的王者,它是基于容器的集群编排引擎,具备扩展集群、滚动升级回滚、弹性伸缩、自动治愈、服务发现等多种特性能力。
本文将带着大家快速了解 kubernetes ,了解我们谈论 kubernetes 都是在谈论什么。
一、背景
1、部署方式的变迁

- 传统部署时代:
- 在物理服务器上运行应用程序
- 无法为应用程序定义资源边界
- 导致资源分配问题
例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况, 结果可能导致其他应用程序的性能下降。 一种解决方案是在不同的物理服务器上运行每个应用程序,但是由于资源利用不足而无法扩展, 并且维护许多物理服务器的成本很高。
- 虚拟化部署时代:
- 作为解决方案,引入了虚拟化
- 虚拟化技术允许你在单个物理服务器的 CPU 上运行多个虚拟机(VM)
- 虚拟化允许应用程序在 VM 之间隔离,并提供一定程度的安全
- 一个应用程序的信息 不能被另一应用程序随意访问。
- 虚拟化技术能够更好地利用物理服务器上的资源
- 因为可轻松地添加或更新应用程序 ,所以可以实现更好的可伸缩性,降低硬件成本等等。
- 每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
缺点:虚拟层冗余导致的资源浪费与性能下降
- 容器部署时代:
- 容器类似于 VM,但可以在应用程序之间共享操作系统(OS)。
- 容器被认为是轻量级的。
- 容器与 VM 类似,具有自己的文件系统、CPU、内存、进程空间等。
- 由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器优势:
- 敏捷性:敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 及时性:持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性),支持可靠且频繁的 容器镜像构建和部署。
- 解耦性:关注开发与运维的分离:在构建/发布时创建应用程序容器镜像,而不是在部署时。 从而将应用程序与基础架构分离。
- 可观测性:可观察性不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨平台:跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
- 可移植:跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 简易性:以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 大分布式:松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 隔离性:资源隔离:可预测的应用程序性能。
- 高效性:资源利用:高效率和高密度
2、容器化问题
- 弹性的容器化应用管理
- 强大的故障转移能力
- 高性能的负载均衡访问机制
- 便捷的扩展
- 自动化的资源监测
3、为什么用 Kubernetes
容器是打包和运行应用程序的好方式。在生产环境中,你需要管理运行应用程序的容器,并确保不会停机。 例如,如果一个容器发生故障,则需要启动另一个容器。如果系统处理此行为,会不会更容易?
这就是 Kubernetes 来解决这些问题的方法! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。linux之上的一个服务编排框架;
Kubernetes 会满足你的扩展要求、故障转移、部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary 部署。
Kubernetes 为你提供:
- 服务发现和负载均衡 Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
- 存储编排 Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
- 自动部署和回滚 你可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态 更改为期望状态。例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
- 自动完成装箱计算 Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。
- 自我修复 Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。
- 密钥与配置管理 Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥
为了生产环境的容器化大规模应用编排,必须有一个自动化的框架。
kubernetes 架构
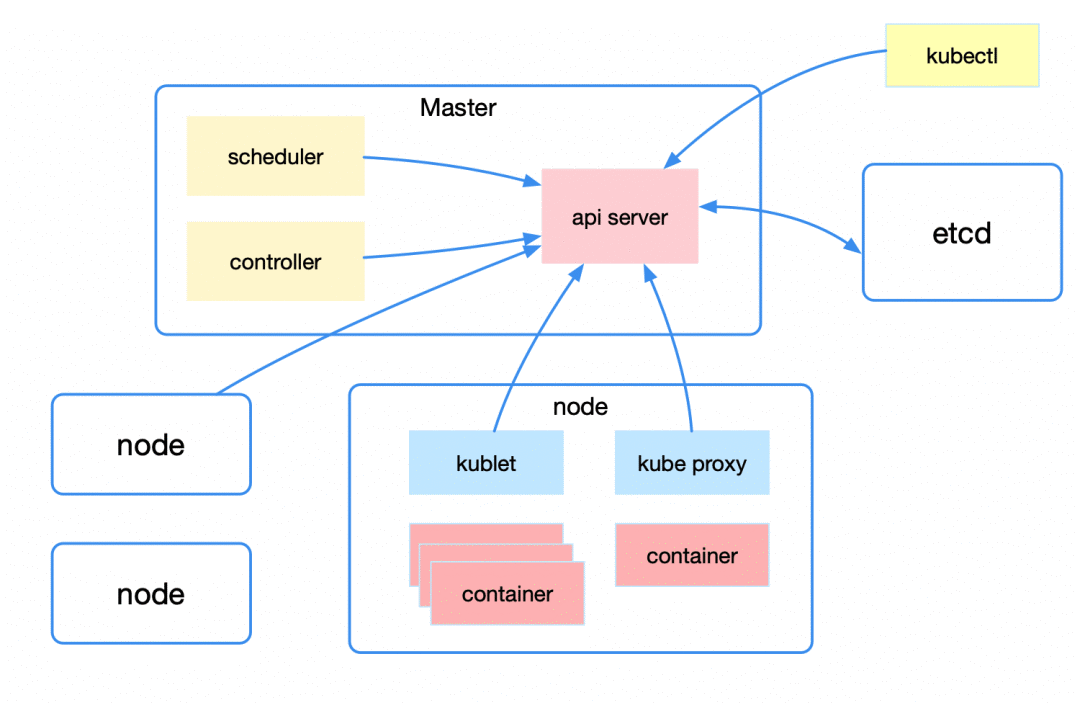
从宏观上来看 kubernetes 的整体架构,包括 Master、Node 以及 Etcd。
Master 即主节点,负责控制整个 kubernetes 集群。它包括 Api Server、Scheduler、Controller 等组成部分。它们都需要和 Etcd 进行交互以存储数据。
Api Server:主要提供资源操作的统一入口,这样就屏蔽了与 Etcd 的直接交互。功能包括安全、注册与发现等。
Scheduler:负责按照一定的调度规则将 Pod 调度到 Node 上。
Controller:资源控制中心,确保资源处于预期的工作状态。
Node 即工作节点,为整个集群提供计算力,是容器真正运行的地方,包括运行容器、kubelet、kube-proxy。
kubelet:主要工作包括管理容器的生命周期、结合 cAdvisor 进行监控、健康检查以及定期上报节点状态。
kube-proxy: 主要利用 service 提供集群内部的服务发现和负载均衡,同时监听 service/endpoints 变化并刷新负载均衡。
从创建 deployment 开始


为了更好地解决服务编排的问题,k8s在V1.2版本开始,引入了deployment控制器,值得一提的是,这种控制器并不直接管理pod,
而是通过管理replicaset来间接管理pod,即:deployment管理replicaset,replicaset管理pod。所以deployment比replicaset的功能更强大。
deployment的主要功能有下面几个:
- 支持replicaset的所有功能
- 支持发布的停止、继续
- 支持版本的滚动更新和版本回退
deployment 是用于编排 pod 的一种控制器资源,我们会在后面做介绍。这里以 deployment 为例,来看看架构中的各组件在创建 deployment 资源的过程中都干了什么。
1. 首先是 kubectl 发起一个创建 deployment 的请求
2. apiserver 接收到创建 deployment 请求,将相关资源写入 etcd;之后所有组件与 apiserver/etcd 的交互都是类似的
3. deployment controller list/watch 资源变化并发起创建 replicaSet 请求
4. replicaSet controller list/watch 资源变化并发起创建 pod 请求
5. scheduler 检测到未绑定的 pod 资源,通过一系列匹配以及过滤选择合适的 node 进行绑定
6. kubelet 发现自己 node 上需创建新 pod,负责 pod 的创建及后续生命周期管理
7. kube-proxy 负责初始化 service 相关的资源,包括服务发现、负载均衡等网络规则
deployment的资源清单文件
apiVersion: apps/v1 #版本号
kind: Deployment #类型
metadata: #元数据
name: #rs名称
namespace: #所属命名空间
labels: #标签
controller: deploy
spec: #详情描述
replicas: #副本数量
revisionHistoryLimit: #保留历史版本,默认是10
paused: #暂停部署,默认是false
progressDeadlineSeconds: #部署超时时间(s),默认是600
strategy: #策略
type: RollingUpdates #滚动更新策略
rollingUpdate: #滚动更新
maxSurge: #最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavaliable: #最大不可用状态的pod的最大值,可以为百分比,也可以为整数
selector: #选择器,通过它指定该控制器管理哪些pod
matchLabels: #Labels匹配规则
app: nginx-pod
matchExpressions: #Expression匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: #模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80创建deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: pc-deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1deployment功能

扩缩容
方式一:命令行
格式
kubectl scale deploy deploy名称 --replicas=pod数量 -n 命名空间
通过命令行变更pod数量为5个
[root@master ~]# kubectl scale deploy pc-deployment --replicas=5 -n dev deployment.apps/pc-deployment scaled [root@master ~]# kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pc-deployment-5d89bdfbf9-bhcns 1/1 Running 0 83s pc-deployment-5d89bdfbf9-cfls7 1/1 Running 0 83s pc-deployment-5d89bdfbf9-k8j9n 1/1 Running 0 8m54s pc-deployment-5d89bdfbf9-vw87k 1/1 Running 0 8m54s pc-deployment-5d89bdfbf9-x7nsm 1/1 Running 0 8m54s
方式二:编辑deploy文件
格式
kubectl edit deploy deploy名字 -n 命名空间
通过编辑deploy文件编辑pod数量为3个
[root@master ~]# kubectl edit deploy pc-deployment -n dev 找到replicas,将其数量改为3 spec: progressDeadlineSeconds: 600 replicas: 3 [root@master ~]# kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pc-deployment-5d89bdfbf9-k8j9n 1/1 Running 0 15m pc-deployment-5d89bdfbf9-vw87k 1/1 Running 0 15m pc-deployment-5d89bdfbf9-x7nsm 1/1 Running 0 15m
镜像更新
deployment支持两种镜像更新策略:重建更新和滚动更新(默认),可以通过strategy选项进行配置
strategy:指定新的pod替换旧的pod的策略,支持两个属性:
type:指定策略类型,支持两种策略
Recreate:在创建出新的pod之前会先杀掉所有已存在的pod
RollingUpdate:滚动更新,就是杀死一部分,就启动一部分,在更新过程中,存在两个版本pod
rollingUpdate:当type为RollingUpdate时生效,用于为RollingUpdate设置参数,支持两个属性
maxUnavailable:用来指定在升级过程中不可用pod的最大数量,默认为25%
maxSurge:用来指定在升级过程中可以超过期望的pod的最大数量,默认为25%
重建更新
编辑pc-deployment.yaml,在spec节点下添加更新策略
spec:
strategy: #策略
type: Recreate #重建更新策略
[root@master ~]# vim pc-deployment.yaml [root@master ~]# kubectl apply -f pc-deployment.yaml Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply deployment.apps/pc-deployment configured
创建deploy进行验证
#首先记录原本的pod名 [root@master ~]# kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pc-deployment-5d89bdfbf9-bqf86 1/1 Running 0 8s pc-deployment-5d89bdfbf9-kz6jt 1/1 Running 0 8s pc-deployment-5d89bdfbf9-z7d9z 1/1 Running 0 8s #更改pod镜像 [root@master ~]# kubectl set image deploy pc-deployment nginx=nginx:1.17.2 -n dev deployment.apps/pc-deployment image updated #再次查看镜像 [root@master ~]# kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pc-deployment-675d469f8b-b9rwd 1/1 Running 0 27s pc-deployment-675d469f8b-kc7rr 1/1 Running 0 27s pc-deployment-675d469f8b-kxgkq 1/1 Running 0 27s
发现pod镜像已经改变了
滚动更新
编辑pc-deployment.yaml,在spec节点下添加滚动更新策略(也可以把strategy去掉,因为默认滚动更新策略)
strategy:
type: RollingUpdate #滚动更新策略
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
[root@master ~]# vim pc-deployment.yaml [root@master ~]# kubectl apply -f pc-deployment.yaml Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply deployment.apps/pc-deployment configured
创建deploy进行验证
#记录以前的pod [root@master ~]# kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pc-deployment-5d89bdfbf9-526wf 1/1 Running 0 61s pc-deployment-5d89bdfbf9-b5x5v 1/1 Running 0 64s pc-deployment-5d89bdfbf9-kc7hb 1/1 Running 0 59s #更新镜像 [root@master ~]# kubectl set image deploy pc-deployment nginx=nginx:1.17.2 -n dev deployment.apps/pc-deployment image updated #查看pod状态 [root@master ~]# kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pc-deployment-5d89bdfbf9-526wf 0/1 Terminating 0 2m2s pc-deployment-5d89bdfbf9-b5x5v 1/1 Running 0 2m5s pc-deployment-5d89bdfbf9-kc7hb 0/1 Terminating 0 2m pc-deployment-675d469f8b-7vw6x 1/1 Running 0 3s pc-deployment-675d469f8b-rzq82 0/1 ContainerCreating 0 2s pc-deployment-675d469f8b-zk4fs 1/1 Running 0 5s [root@master ~]# kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pc-deployment-675d469f8b-7vw6x 1/1 Running 0 38s pc-deployment-675d469f8b-rzq82 1/1 Running 0 37s pc-deployment-675d469f8b-zk4fs 1/1 Running 0 40s
发现pod是旧的一遍停止新的一边创建,最后全变成了新的
滚动更新的过程
镜像更新中rs的变化
前期准备:
#重建deployment [root@master ~]# kubectl delete -f pc-deployment.yaml deployment.apps "pc-deployment" deleted #添加record参数,表明创建时记录 [root@master ~]# kubectl create -f pc-deployment.yaml --record deployment.apps/pc-deployment created [root@master ~]# kubectl get deploy,rs,pod -n dev NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/pc-deployment 3/3 3 3 81s NAME DESIRED CURRENT READY AGE replicaset.apps/pc-deployment-5d89bdfbf9 3 3 3 81s NAME READY STATUS RESTARTS AGE pod/pc-deployment-5d89bdfbf9-4bg2j 1/1 Running 0 81s pod/pc-deployment-5d89bdfbf9-gbt95 1/1 Running 0 81s pod/pc-deployment-5d89bdfbf9-tstlh 1/1 Running 0 81s
新建两个xshell窗口,用于监听rs和pod

在2窗口中监听rs,3窗口中监听pod
#在2窗口中输入 [root@master ~]# kubectl get rs -n dev -w NAME DESIRED CURRENT READY AGE pc-deployment-5d89bdfbf9 3 3 3 6m18s #在3窗口中输入 [root@master ~]# kubectl get pod -n dev -w NAME READY STATUS RESTARTS AGE pc-deployment-5d89bdfbf9-4bg2j 1/1 Running 0 6m56s pc-deployment-5d89bdfbf9-gbt95 1/1 Running 0 6m56s pc-deployment-5d89bdfbf9-tstlh 1/1 Running 0 6m56s
在1窗口中改变pod镜像
[root@master ~]# kubectl set image deploy pc-deployment nginx=nginx:1.17.2 -n dev deployment.apps/pc-deployment image updated
查看3窗口中pod的变化,发现序号5开头的pod在逐渐暂停,序号6开头的pod在逐渐创建

查看2窗口中rs的变化,可以看见序号5开头的rs的pod数在减少,序号6开头的rs的pod数在增加
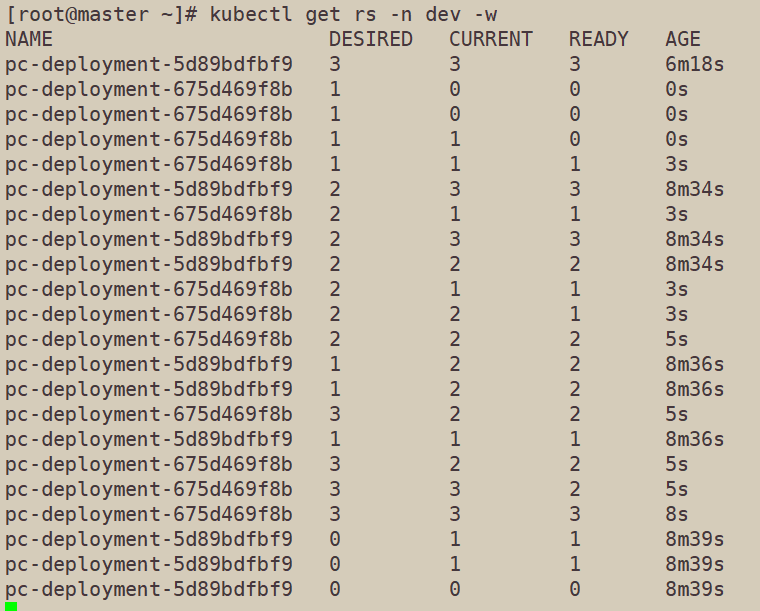
在1窗口中查看最终rs变化,发现原来的rs依旧存在,只是pod数量变为了0,而后又新产生了一个rs,pod数量为3,其实这就是deployment能够进行版本回退的奥妙所在,后面会详细解释
[root@master ~]# kubectl get rs -n dev NAME DESIRED CURRENT READY AGE pc-deployment-5d89bdfbf9 0 0 0 11m pc-deployment-675d469f8b 3 3 3 3m12s
版本回退
deployment支持版本升级过程中的暂停,继续功能以及版本回退等诸多功能,下面具体来看
kubectl rollout:版本升级相关功能,支持下面的选项:
- status:显示当前升级状态
- history:显示升级历史记录
- pause:暂停版本升级过程
- resume:继续已经暂停的版本升级过程
- restart:重启版本升级过程
- undo:回滚到上一级版本(可以使用--to-revision回滚到指定版本)
#查看升级状态 [root@master ~]# kubectl rollout status deploy pc-deployment -n dev deployment "pc-deployment" successfully rolled out #查看升级历史(注意:如果只显示版本号说明一开始使用yaml创建文件的时候没有加上--record命令) [root@master ~]# kubectl rollout history deploy pc-deployment -n dev deployment.apps/pc-deployment REVISION CHANGE-CAUSE 1 kubectl create --filename=pc-deployment.yaml --record=true 2 kubectl create --filename=pc-deployment.yaml --record=true #版本回滚 #这里使用--to-revision=1回滚到1版本,如果省略这个选项,则会回退到上个版本 [root@master ~]# kubectl rollout undo deploy pc-deployment --to-revision=1 -n dev deployment.apps/pc-deployment rolled back #查看是否回滚成功,发现5序号开头的rs被启动了 [root@master ~]# kubectl get rs -n dev NAME DESIRED CURRENT READY AGE pc-deployment-5d89bdfbf9 3 3 3 31m pc-deployment-675d469f8b 0 0 0 22m
金丝雀发布
deployment支持更新过程中的控制,如"暂停(pause)"或"继续(resume)"更新操作
比如有一批新的pod资源创建完成后立即暂停更新过程,此时,仅存在一部分新版本的应用,主体部分还是旧的版本。然后,再筛选一小部分的用户请求路由到新的pod应用,继续观察能否稳定地按期望的方式运行。确定没问题之后再继续完成余下的pod资源滚动更新,否则立即回滚更新操作。这就是所谓的金丝雀发布。
#更新deployment版本,并配置暂停deployment [root@master ~]# kubectl set image deploy pc-deployment nginx=nginx:1.17.2 -n dev && kubectl rollout pause deploy pc-deployment -n dev deployment.apps/pc-deployment image updated deployment.apps/pc-deployment paused #查看rs,发现老版本rs没有减少,新版本rs增加一个 [root@master ~]# kubectl get rs -n dev NAME DESIRED CURRENT READY AGE pc-deployment-5d89bdfbf9 3 3 3 44m pc-deployment-675d469f8b 1 1 1 35m #在窗口2中查看deploy状态,发现deploy正在等待更新且已经有1个更新好了 [root@master ~]# kubectl rollout status deploy pc-deployment -n dev Waiting for deployment "pc-deployment" rollout to finish: 1 out of 3 new replicas have been updated... #在窗口1中继续deploy的更新 [root@master ~]# kubectl rollout resume deploy pc-deployment -n dev deployment.apps/pc-deployment resumed #查看窗口2的状态 Waiting for deployment spec update to be observed... Waiting for deployment spec update to be observed... Waiting for deployment "pc-deployment" rollout to finish: 1 out of 3 new replicas have been updated... Waiting for deployment "pc-deployment" rollout to finish: 1 out of 3 new replicas have been updated... Waiting for deployment "pc-deployment" rollout to finish: 2 out of 3 new replicas have been updated... Waiting for deployment "pc-deployment" rollout to finish: 2 out of 3 new replicas have been updated... Waiting for deployment "pc-deployment" rollout to finish: 2 out of 3 new replicas have been updated... Waiting for deployment "pc-deployment" rollout to finish: 1 old replicas are pending termination... Waiting for deployment "pc-deployment" rollout to finish: 1 old replicas are pending termination... deployment "pc-deployment" successfully rolled out #在窗口1查看rs更新结果,发现老版本均停止,新版本已经创建好 [root@master ~]# kubectl get rs -n dev NAME DESIRED CURRENT READY AGE pc-deployment-5d89bdfbf9 0 0 0 49m pc-deployment-675d469f8b 3 3 3 40m
至此,经过 kubenetes 各组件的分工协调,完成了从创建一个 deployment 请求开始到具体各 pod 正常运行的全过程。
Pod
在 kubernetes 众多的 api 资源中,pod 是最重要和基础的,是最小的部署单元。
首先我们要考虑的问题是,我们为什么需要 pod?pod 可以说是一种容器设计模式,它为那些”超亲密”关系的容器而设计,我们可以想象 servelet 容器部署 war 包、日志收集等场景,这些容器之间往往需要共享网络、共享存储、共享配置,因此我们有了 pod 这个概念。
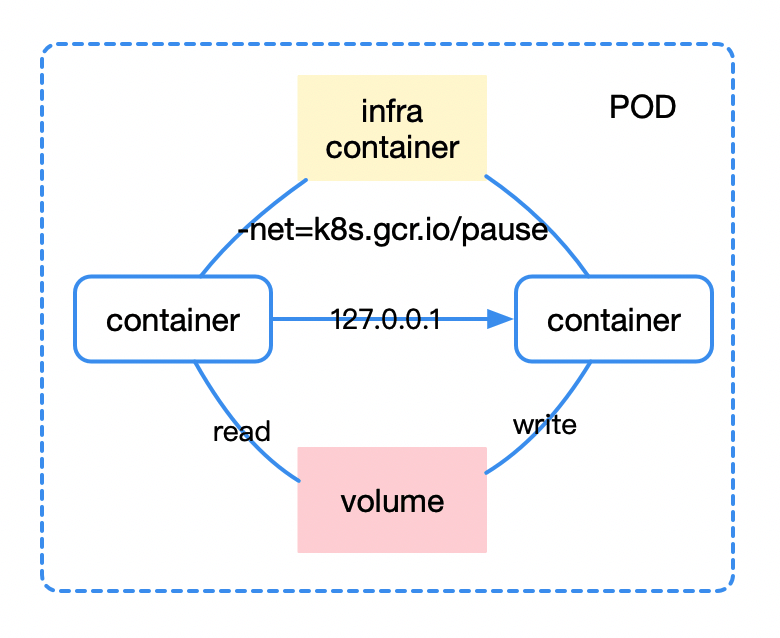
对于 pod 来说,不同 container 之间通过 infra container 的方式统一识别外部网络空间,而通过挂载同一份 volume 就自然可以共享存储了,比如它对应宿主机上的一个目录。
容器编排
容器编排是 kubernetes 的看家本领了,所以我们有必要了解一下。kubernetes 中有诸多编排相关的控制资源,例如编排无状态应用的 deployment,编排有状态应用的 statefulset,编排守护进程 daemonset 以及编排离线业务的 job/cronjob 等等。
我们还是以应用最广泛的 deployment 为例。deployment、replicatset、pod 之间的关系是一种层层控制的关系。简单来说,replicaset 控制 pod 的数量,而 deployment 控制 replicaset 的版本属性。这种设计模式也为两种最基本的编排动作实现了基础,即数量控制的水平扩缩容、版本属性控制的更新/回滚。
水平扩缩容
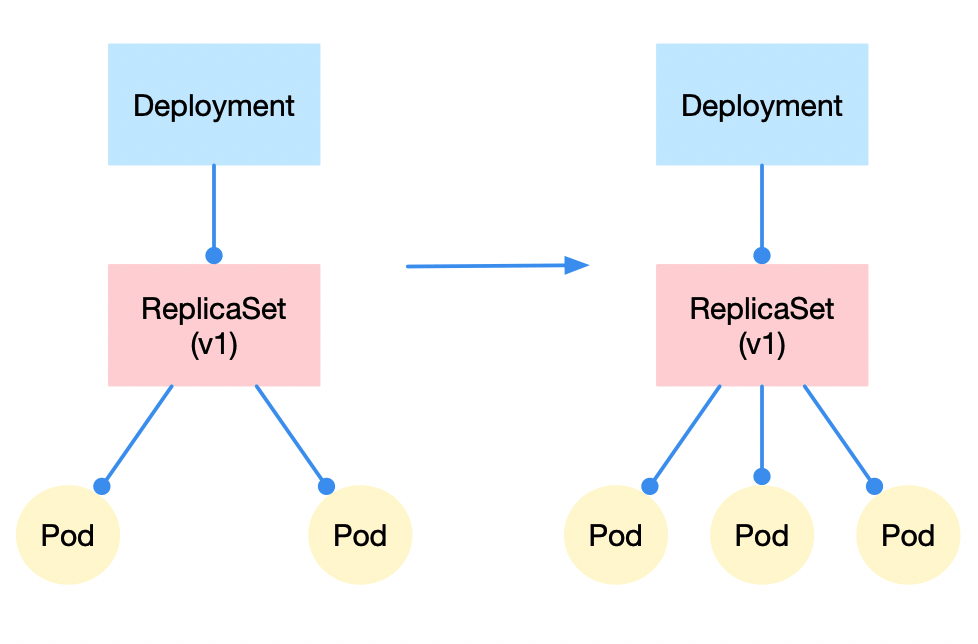
水平扩缩容非常好理解,我们只需修改 replicaset 控制的 pod 副本数量即可,比如从 2 改到 3,那么就完成了水平扩容这个动作,反之即水平收缩。
更新/回滚
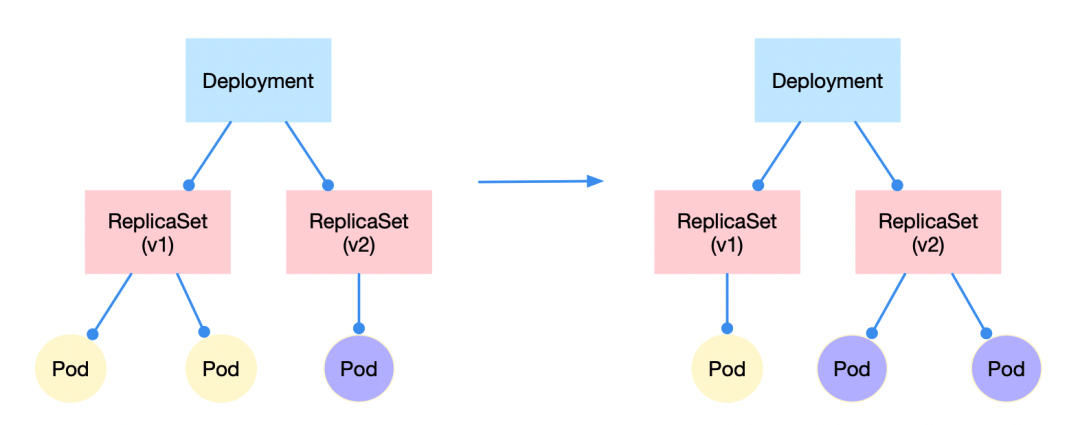
更新/回滚则体现了 replicaset 这个对象的存在必要性。例如我们需要应用 2 个实例的版本从 v1 改到 v2,那么 v1 版本 replicaset 控制的 pod 副本数会逐渐从 2 变到 0,而 v2 版本 replicaset 控制的 pod 数会注解从 0 变到 2,当 deployment 下只存在 v2 版本的 replicaset 时变完成了更新。回滚的动作与之相反。
滚动更新
可以发现,在上述例子中,我们更新应用,pod 总是一个一个升级,并且最小有 2 个 pod 处于可用状态,最多有 4 个 pod 提供服务。这种”滚动更新”的好处是显而易见的,一旦新的版本有了 bug,那么剩下的 2 个 pod 仍然能够提供服务,同时方便快速回滚。
在实际应用中我们可以通过配置 RollingUpdateStrategy 来控制滚动更新策略,maxSurge 表示 deployment 控制器还可以创建多少个新 Pod;而 maxUnavailable 指的是,deployment 控制器可以删除多少个旧 Pod。
kubernetes 中的网络
我们了解了容器编排是怎么完成的,那么容器间的又是怎么通信的呢?
讲到网络通信,kubernetes 首先得有”三通”基础:
1. node 到 pod 之间可以通
2. node 的 pod 之间可以通
3. 不同 node 之间的 pod 可以通

简单来说,不同 pod 之间通过 cni0/docker0 网桥实现了通信,node 访问 pod 也是通过 cni0/docker0 网桥通信即可。
而不同 node 之间的 pod 通信有很多种实现方案,包括现在比较普遍的 flannel 的 vxlan/hostgw 模式等。flannel 通过 etcd 获知其他 node 的网络信息,并会为本 node 创建路由表,最终使得不同 node 间可以实现跨主机通信。
微服务—service
在了解接下来的内容之前,我们得先了解一个很重要的资源对象:service。
我们为什么需要 service 呢?在微服务中,pod 可以对应实例,那么 service 对应的就是一个微服务。而在服务调用过程中,service 的出现解决了两个问题:
1. pod 的 ip 不是固定的,利用非固定 ip 进行网络调用不现实
2. 服务调用需要对不同 pod 进行负载均衡

service 通过 label 选择器选取合适的 pod,构建出一个 endpoints,即 pod 负载均衡列表。实际运用中,一般我们会为同一个微服务的 pod 实例都打上类似app=xxx的标签,同时为该微服务创建一个标签选择器为app=xxx的 service。
kubernetes 中的服务发现与网络调用
在有了上述”三通”的网络基础后,我们可以开始微服务架构中的网络调用在 kubernetes 中是怎么实现的了。
这部分内容其实在说说 Kubernetes 是怎么实现服务发现的已经讲得比较清楚了,比较细节的地方可以参考上述文章,这里做一个简单的介绍。
服务间调用
首先是东西向的流量调用,即服务间调用。这部分主要包括两种调用方式,即 clusterIp 模式以及 dns 模式。
clusterIp 是 service 的一种类型,在这种类型模式下,kube-proxy 通过 iptables/ipvs 为 service 实现了一种 VIP(虚拟 ip)的形式。只需要访问该 VIP,即可负载均衡地访问到 service 背后的 pod。
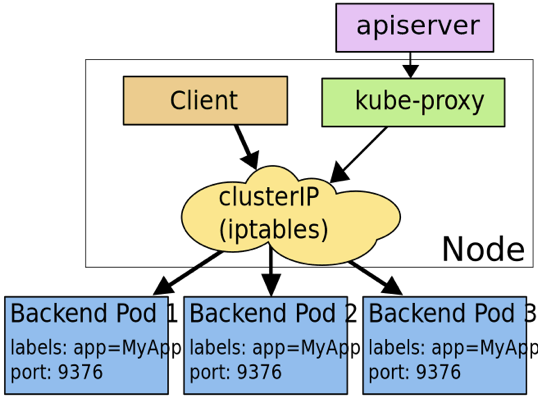
上图是 clusterIp 的一种实现方式,此外还包括 userSpace 代理模式(基本不用),以及 ipvs 模式(性能更好)。
dns 模式很好理解,对 clusterIp 模式的 service 来说,它有一个 A 记录是 service-name.namespace-name.svc.cluster.local,指向 clusterIp 地址。所以一般使用过程中,我们直接调用 service-name 即可。
服务外访问
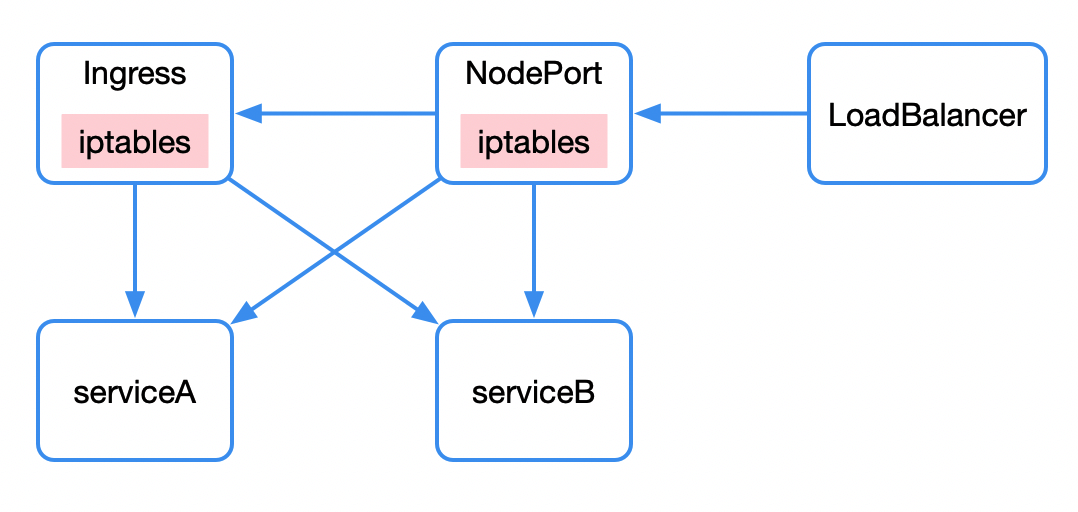
南北向的流量,即外部请求访问 kubernetes 集群,主要包括三种方式:nodePort、loadbalancer、ingress。
nodePort 同样是 service 的一种类型,通过 iptables 赋予了调用宿主机上的特定 port 就能访问到背后 service 的能力。
loadbalancer 则是另一种 service 类型,通过公有云提供的负载均衡器实现。
我们访问 100 个服务可能需要创建 100 个 nodePort/loadbalancer。我们希望通过一个统一的外部接入层访问内部 kubernetes 集群,这就是 ingress 的功能。ingress 提供了统一接入层,通过路由规则的不同匹配到后端不同的 service 上。ingress 可以看做是”service 的 service”。ingress 在实现上往往结合 nodePort 以及 loadbalancer 完成功能。
到现在为止,我们简单了解了 kubernetes 的相关概念,它大致是怎么运作的,以及微服务是怎么运行在 kubernetes 中的。于是当我们听到别人讨论 kubernetes 时,我们可以知道他们在讨论什么。