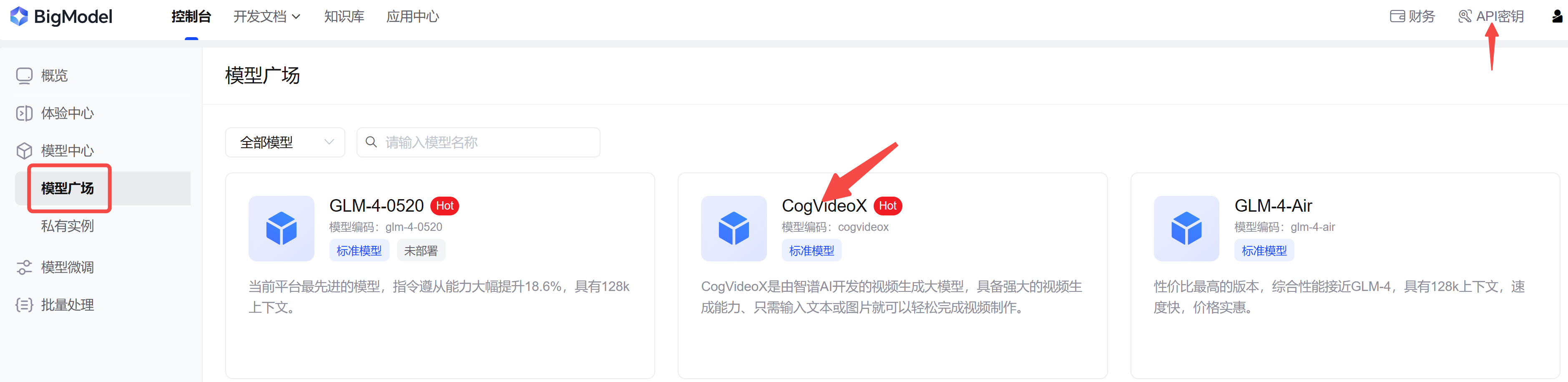
一、爬取需求
就是用python,获取某百度贴吧的标题
二、代码
import lxml.html
import requests
ydm = requests.get('https://tieba.baidu.com/f?ie=utf-8&kw=%E5%BC%A0%E5%A7%93%E4%B9%8B%E5%AE%B6').content.decode()
selector = lxml.html.fromstring(ydm)
info = selector.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a/text()')
for infoo in info:
print(infoo)三、代码说明
import lxml.html import requests 前两行的代码是导入模块,这两个第三方库,都是需要安装的,python并不是自带的,安装方法自行百度。 ydm = requests.get('https://tieba.baidu.com/f?ie=utf-8&kw=%E5%BC%A0%E5%A7%93%E4%B9%8B%E5%AE%B6').content.decode() 这一行代码是获取某贴吧的源代码赋值给ydm selector = lxml.html.fromstring(ydm) 这一行是利用lxml库里的html.fromstring info = selector.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a/text()') 这一行是把获取到的列表赋值info,其中.xpath也是lmxl库里的一个功能,后面的那串代码 是需要到网页上去点开源代码查看的 for infoo in info: print(infoo)
打印贴吧目录列表
四、优化
其实百度贴吧每页的代码是一样的,所以我们是否可以用input函数让大家自己输入网址,然后就可以获得该贴吧第一页所有标题列表,尝试代码如下
import lxml.html
import requests
url = input('请输入百度贴吧的网址')
ydm = requests.get(url).content.decode()
selector = lxml.html.fromstring(ydm)
info = selector.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a/text()')
for infoo in info:
print(infoo)测试贴吧,郑智化吧 地址https://tieba.baidu.com/f?ie=utf-8&kw=%E9%83%91%E6%99%BA%E5%8C%96

输出结果
请输入百度贴吧的网址https://tieba.baidu.com/f?ie=utf-8&kw=%E9%83%91%E6%99%BA%E5%8C%96
无标题贴
【郑式影响】传奇
【郑式影响】一首MV
【郑式影响】大国民的MV和高音质音频文件链接,请自行下载。
【郑式影响】想得到郑智化所有歌曲
【郑式影响】最近化哥的《游戏人间》又火了一把
【郑式影响】关于2016年的一张照片
【郑式影响】吧内的等级都是有什么名称,有没有朋友知道?
【郑式影响】有关于堕落天使的一点事
【郑式影响】我改编了化哥的《让我拥抱你入梦》大家看看我文笔怎么样
英雄之歌歌词赏析
【郑式影响】想问一下各位年龄
【郑式影响】大家伙看到化哥的最新微博了嘛?
【郑式影响】【随笔】有棱有角没有圆
化歌海报剪辑
张显道你是寂寞难耐呀
【郑式影响】无题
【郑式影响】张显道,这里只想对你说一个字
【郑式影响】退吧不退心,再来一贴
郑智化历年音乐创作不完全统计
【化哥原版MV】大国民
【郑式影响】新专辑有消息吗
进程已结束,退出代码为 0