1 微服务介绍
1)什么是微服务
微服务(Microservices)是一种软件架构风格,它将一个大型应用程序拆分成许多较小的、松散耦合的、独立运行的服务。这些服务通常围绕特定功能或业务领域组织,可以独立开发、部署、扩展和更新。微服务之间通过轻量级的通信协议(如HTTP/REST、消息队列等)相互协作。
采用微服务架构的优点包括:
- 可扩展性:每个服务都可以根据需求单独进行扩展。
- 敏捷开发:团队可以独立开发和部署各自负责的服务,加快开发速度。
- 容错性:当某个服务出现问题时,不会影响整个系统的正常运行。
- 技术栈灵活性:可以针对具体任务选择最佳技术和编程语言,而不受整体约束。
然而,微服务架构也存在一些挑战,例如网络延迟、数据一致性和服务间通信复杂性等问题。在实践中,需要根据项目需求审慎权衡是否采用微服务架构。
2)什么是分布式
分布式(Distributed)是指一个系统的组件分散在不同的网络节点上,这些组件协同工作以完成整个系统的任务。分布式系统可以提高可扩展性、容错能力和资源利用率。由于组件在物理上分隔,分布式系统需要处理诸如数据一致性、通信延迟和故障恢复等问题。
微服务是一种特定的分布式系统架构风格,它强调将应用程序拆分为许多较小的、松散耦合的、独立运行的服务。这些服务围绕特定功能或业务领域组织,并通过轻量级通信协议进行交互。
3)分布式和微服务的区别:
- 范围:分布式是更广泛的概念,涵盖了各种类型的分布式系统;而微服务是一种具体的分布式架构风格。
- 设计原则:微服务强调每个服务的独立性、职责单一、松耦合和自治性,这使得微服务更容易适应不断变化的需求。而其他类型的分布式系统可能没有这些特性。
- 技术实现:虽然两者都涉及跨多个节点的组件,但实现方式可能有所不同。微服务通常使用HTTP/REST、消息队列等轻量级通信协议,而其他分布式系统可能使用RPC、一致性算法等技术。
总之,微服务是分布式系统中的一种特殊类型。虽然它们在概念上有重叠,但它们在设计原则和实现细节上有所不同。
2 springcloud介绍
1)springcloud组件
Spring Cloud是一个基于Spring Boot的微服务框架,旨在简化分布式系统中的开发、部署和管理工作。它提供了一系列模块和工具,可以帮助开发者快速搭建弹性、可扩展且易于维护的微服务应用。以下是一些常见的Spring Cloud组件:
- Spring Cloud Config:分布式配置中心,允许您在集中位置管理所有服务的配置,并实时更新。
- Spring Cloud Netflix Eureka:服务注册与发现组件,提供了自动化的服务注册、注销和查找功能,支持负载均衡。
- Spring Cloud Netflix Ribbon:客户端负载均衡器,可以在调用其他服务时为请求选择合适的实例,提高系统的可用性。
- Spring Cloud Netflix Hystrix:熔断器和隔离组件,用于防止故障级联和提供降级处理。
- Spring Cloud Netflix Zuul:API网关, 责处理客户端请求并将其转发到适当的内部服务 。
- Spring Cloud Gateway:API网关,负责转发请求、聚合响应、路由、认证授权和限流等功能。
- Spring Cloud Sleuth 和 Zipkin:分布式追踪组件,用于监控和诊断跨服务的请求链路。
- Spring Cloud Stream:基于消息驱动的微服务通信组件,支持异步处理和解耦服务间的通信。
- Spring Cloud Security:安全性模块,提供了一些基本的安全措施,如认证、授权和API保护等功能。
- Spring Cloud Bus:事件总线,用于实现服务间消息传递和广播配置更新等功能。
- Spring Cloud OpenFeign:声明式HTTP客户端,简化了RESTful服务之间的通信。
由于Netflix公司已经停止了对Spring Cloud Netflix组件的维护和更新工作, 所以Netflix 相关的组件已经目前已经有对应的替代组件:
Eureka --> Nacos; Ribbon --> LoadBalancer; Zuul --> Gateway; Hystrix --> Sentinel
2)springcloud alibaba
Spring Cloud Alibaba 是一个基于 Spring Cloud 的微服务开发框架,它提供了与 Alibaba 相关组件(如 Nacos、Sentinel、RocketMQ 等)的集成。Spring Cloud Alibaba 旨在简化开发者构建分布式应用的过程,并帮助实现高可用、弹性伸缩和快速故障恢复等目标。
主要功能包括:
- 服务注册与发现:Spring Cloud Alibaba 集成了阿里巴巴的 Nacos 作为服务注册中心,支持针对各种场景的服务管理。
- 分布式配置管理:通过 Nacos 提供统一的配置管理服务,实现配置的动态更新和版本控制。
- 服务熔断与限流:集成阿里巴巴的 Sentinel 组件,提供流量控制、熔断降级和系统负载保护等功能,保证服务的稳定性。
- 消息队列:集成阿里巴巴的 RocketMQ,提供分布式消息队列服务,实现异步通信、解耦和削峰填谷等功能。
- 分布式事务:通过 Seata 组件提供分布式事务处理能力,帮助解决微服务架构下的数据一致性问题。
- 链路追踪:集成阿里巴巴的 Arthas 和 SkyWalking,实现链路追踪和性能监控等功能。
通过使用 Spring Cloud Alibaba,开发者可以更轻松地基于阿里巴巴的技术栈构建微服务应用,并充分利用其丰富的功能和稳定性。
3)版本对应关系
spring boot和spring cloud以及 spring cloud alibaba的版本对应关系;
| Spring Cloud Alibaba Version | Spring Cloud Version | Spring Boot Version |
|---|---|---|
| 2.2.10-RC1* | Spring Cloud Hoxton.SR12 | 2.3.12.RELEASE |
| 2.2.9.RELEASE | Spring Cloud Hoxton.SR12 | 2.3.12.RELEASE |
| 2.2.8.RELEASE | Spring Cloud Hoxton.SR12 | 2.3.12.RELEASE |
| 2.2.7.RELEASE | Spring Cloud Hoxton.SR12 | 2.3.12.RELEASE |
| 2.2.6.RELEASE | Spring Cloud Hoxton.SR9 | 2.3.2.RELEASE |
| 2.2.1.RELEASE | Spring Cloud Hoxton.SR3 | 2.2.5.RELEASE |
| 2.2.0.RELEASE | Spring Cloud Hoxton.RELEASE | 2.2.X.RELEASE |
| 2.1.4.RELEASE | Spring Cloud Greenwich.SR6 | 2.1.13.RELEASE |
| 2.1.2.RELEASE | Spring Cloud Greenwich | 2.1.X.RELEASE |
| 2.0.4.RELEASE(停止维护,建议升级) | Spring Cloud Finchley | 2.0.X.RELEASE |
| 1.5.1.RELEASE(停止维护,建议升级) | Spring Cloud Edgware | 1.5.X.RELEASE |
spring cloud alibaba组件之间的对应关系
| Spring Cloud Alibaba Version | Sentinel Version | Nacos Version | RocketMQ Version | Dubbo Version | Seata Version |
|---|---|---|---|---|---|
| 2022.0.0.0-RC2 | 1.8.6 | 2.2.1 | 4.9.4 | ~ | 1.7.0-native-rc2 |
| 2021.0.5.0 | 1.8.6 | 2.2.0 | 4.9.4 | ~ | 1.6.1 |
| 2.2.10-RC1 | 1.8.6 | 2.2.0 | 4.9.4 | ~ | 1.6.1 |
| 2022.0.0.0-RC1 | 1.8.6 | 2.2.1-RC | 4.9.4 | ~ | 1.6.1 |
| 2.2.9.RELEASE | 1.8.5 | 2.1.0 | 4.9.4 | ~ | 1.5.2 |
| 2021.0.4.0 | 1.8.5 | 2.0.4 | 4.9.4 | ~ | 1.5.2 |
| 2.2.8.RELEASE | 1.8.4 | 2.1.0 | 4.9.3 | ~ | 1.5.1 |
| 2021.0.1.0 | 1.8.3 | 1.4.2 | 4.9.2 | ~ | 1.4.2 |
| 2.2.7.RELEASE | 1.8.1 | 2.0.3 | 4.6.1 | 2.7.13 | 1.3.0 |
| 2.2.6.RELEASE | 1.8.1 | 1.4.2 | 4.4.0 | 2.7.8 | 1.3.0 |
| 2021.1 or 2.2.5.RELEASE or 2.1.4.RELEASE or 2.0.4.RELEASE | 1.8.0 | 1.4.1 | 4.4.0 | 2.7.8 | 1.3.0 |
| 2.2.3.RELEASE or 2.1.3.RELEASE or 2.0.3.RELEASE | 1.8.0 | 1.3.3 | 4.4.0 | 2.7.8 | 1.3.0 |
| 2.2.1.RELEASE or 2.1.2.RELEASE or 2.0.2.RELEASE | 1.7.1 | 1.2.1 | 4.4.0 | 2.7.6 | 1.2.0 |
| 2.2.0.RELEASE | 1.7.1 | 1.1.4 | 4.4.0 | 2.7.4.1 | 1.0.0 |
| 2.1.1.RELEASE or 2.0.1.RELEASE or 1.5.1.RELEASE | 1.7.0 | 1.1.4 | 4.4.0 | 2.7.3 | 0.9.0 |
| 2.1.0.RELEASE or 2.0.0.RELEASE or 1.5.0.RELEASE | 1.6.3 | 1.1.1 | 4.4.0 | 2.7.3 | 0.7.1 |
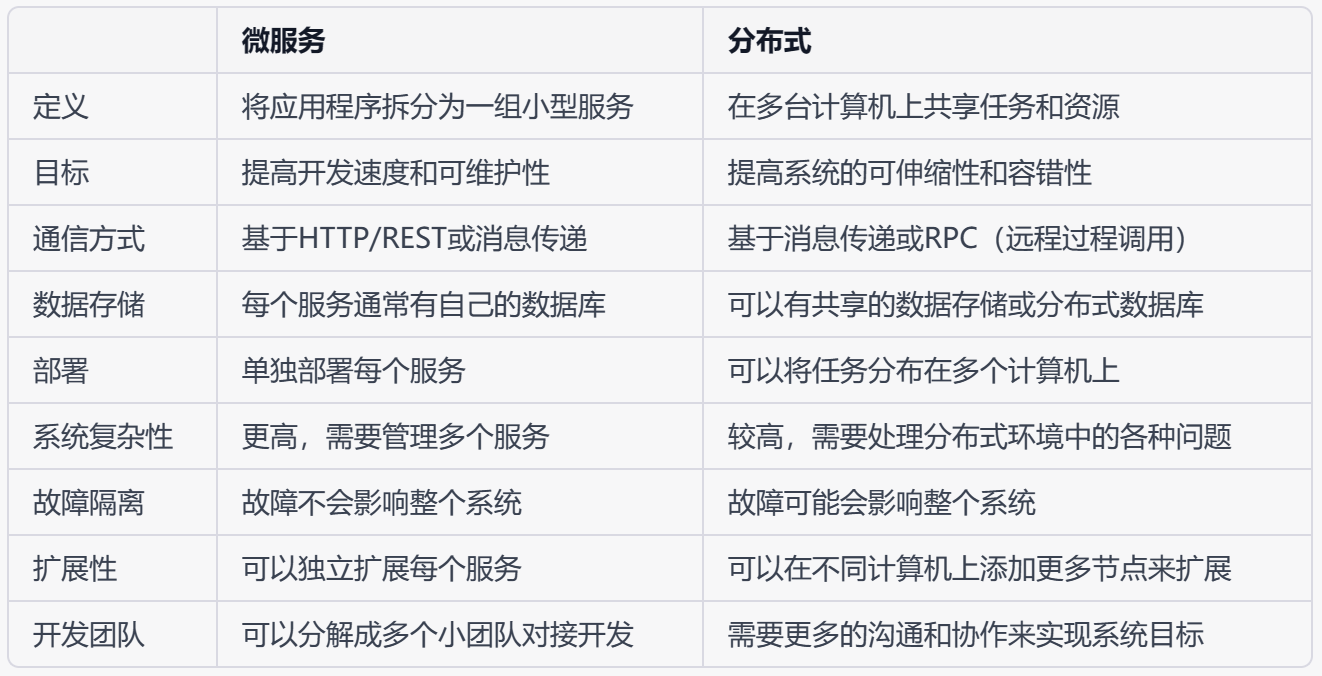
3 服务注册和发现
在 Java 微服务架构中,服务注册与发现是一种关键的设计模式,它允许各个微服务实例自动注册、发现其他服务和负载均衡。这样做的优势主要包括:
-
简化服务调用:服务间可以通过服务名而非硬编码的 IP 地址或端口号进行相互调用。
-
动态伸缩:支持自动添加或删除服务实例,无需手动维护服务列表。
-
负载均衡:根据某种策略(如轮询或最少连接)将请求分发到多个服务实例,从而提高系统整体容错性和可用性。
在 Java 生态中,常见的服务注册与发现解决方案有以下几种:
- Eureka:Eureka 是 Netflix 开源的一款服务注册与发现组件,它基于 RESTful API,具有较好的可扩展性和容错能力。与 Spring Cloud 配合使用时,只需简单的配置即可实现服务注册与发现功能。
- Consul:Consul 是由 HashiCorp 开发的一款服务网格解决方案,提供服务注册与发现、配置管理和服务分段等功能。同样可以与 Spring Cloud 集成,便于构建微服务应用。
- Nacos:阿里巴巴开源的 Nacos 提供了服务注册与发现以及配置管理功能,可以与 Spring Cloud Alibaba 集成使用。Nacos 支持多种服务注册方式(如域名、IP 等),并提供丰富的负载均衡策略和健康检查机制。
- Zookeeper:Apache ZooKeeper 是一个分布式协调服务,虽然它并非专为服务注册与发现而设计,但由于其强大的分布式一致性能力,被广泛用于实现服务注册与发现功能。通过 Curator 客户端库,可以方便地与 Spring Cloud 集成。
1)nacos介绍
Nacos(Naming and Configuration Service)是阿里巴巴开源的一款用于服务注册与发现、配置管理的中间件。它具有易用性、高可用性和强大的功能,旨在帮助开发者构建动态、可扩展的分布式系统。以下是 Nacos 的主要特点和功能:
-
服务注册与发现:Nacos 提供了一个基于 DNS 和 HTTP 的服务注册与发现框架,支持多种服务注册方式(如域名、IP 地址等),并提供丰富的负载均衡策略和健康检查机制。
-
动态配置管理:Nacos 支持配置信息的实时推送和更新,以满足应用程序在运行过程中对配置数据的需求。通过其 UI 控制台,使用者可以轻松管理不同环境、集群和命名空间下的配置。
-
分组及分区:Nacos 支持根据服务实例元数据进行分组和分区,从而实现精细化的服务治理。
-
高可用和容错:Nacos 具有良好的高可用设计,支持集群部署,保证在节点故障的情况下也能正常提供服务。此外,Nacos 还提供了临时存储,以确保用户在网络状况不佳的情况下仍然能够访问配置。
-
多环境支持:Nacos 支持多环境、多集群的管理,方便用户在不同的场景下使用 Nacos。
-
易于集成:Nacos 可以轻松与其他 Java 微服务框架(如 Spring Cloud、Dubbo 等)集成。在 Spring Cloud Alibaba 体系下,只需简单的配置就可以实现 Nacos 与应用程序的无缝对接。
-
社区活跃:作为阿里巴巴开源的项目,Nacos 拥有活跃的社区和丰富的文档资源,方便开发者快速上手和入门。
Nacos = Spring Cloud Eureka + Spring Cloud Config
2)nacos基本运行
Nacos 依赖 Java 环境来运行。所以需要安装jdk1.8+以及配置环境变量;
2.1 nacos-server下载和启动
根据spring-cloud-alibaba中的版本说明, nacos我们下载使用2.1.0;
如果在github上下载太慢, 可以在gitee上下载源码, 然后使用maven打包, 安装; (maven需配置环境变量)
mvn -Prelease-nacos -Dmaven.test.skip=true clean install -U
运行nacos:
1) 使用cmd, 跳转到nacos下的bin文件下,
2) 单机运行指令: startup.cmd -m standalone
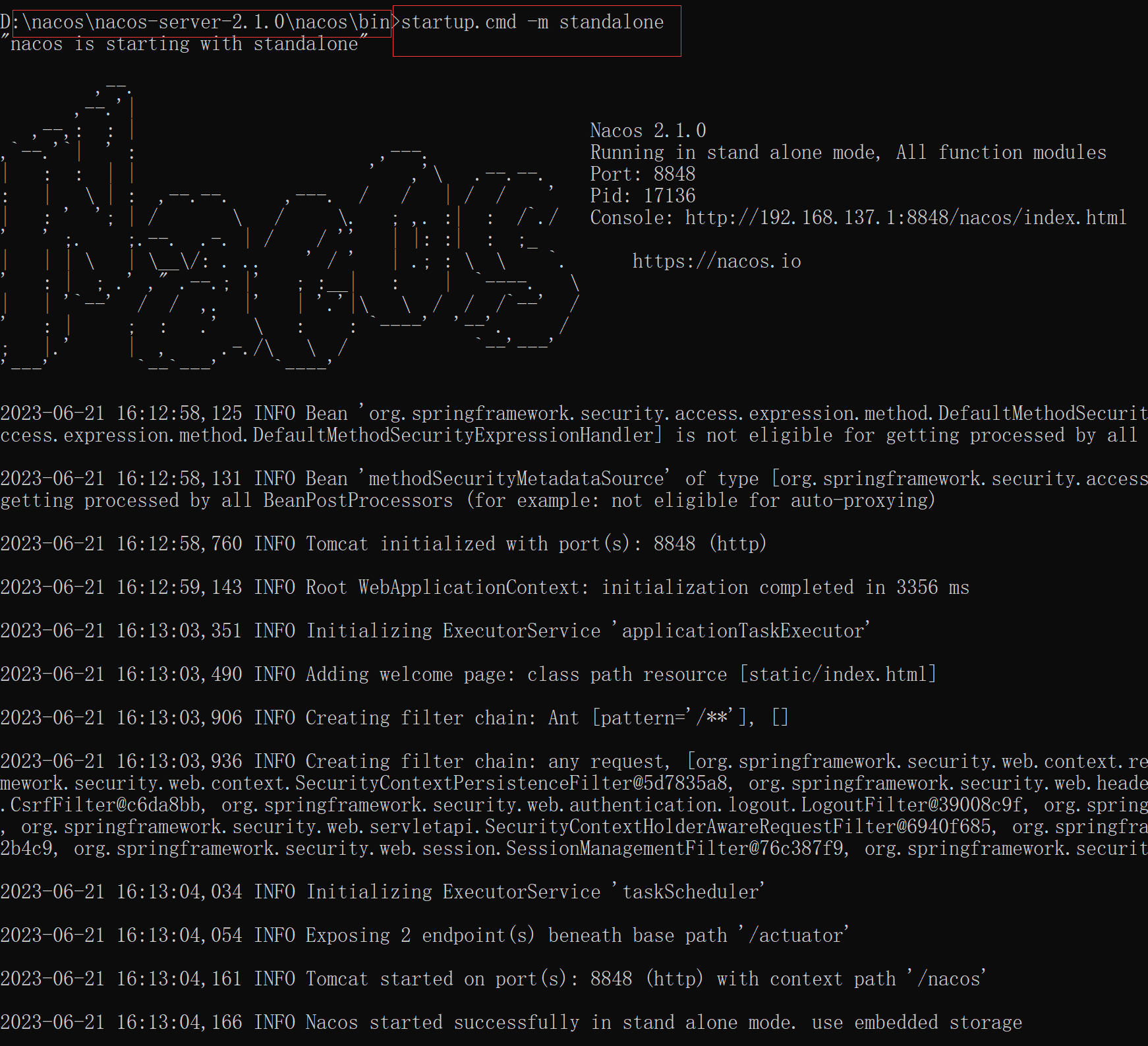
3)nacos后台管理: http://127.0.0.1:8848/nacos/,
输入账号: nacos 密码: nacos
2.2 创建聚合项目
创建聚合项目进行依赖的版本管理;
pom.xml文件
<packaging>pom</packaging>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-boot-version>2.3.12.RELEASE</spring-boot-version>
<spring-cloud-version>Hoxton.SR12</spring-cloud-version>
<spring-cloud-alibaba-version>2.2.9.RELEASE</spring-cloud-alibaba-version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot-version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud-version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring-cloud-alibaba-version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
2.3 订单服务
POM文件
<parent>
<groupId>com.qs.cloud</groupId>
<artifactId>cloud-117</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>order-server</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
</dependencies>
启动类:
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
public class OrderApp {
public static void main(String[] args) {
SpringApplication.run(OrderApp.class);
}
}
配置文件:
spring.application.name=order-server
server.port=9001
spring.cloud.nacos.discovery.server-addr=http://127.0.0.1:8848
feign接口:
@FeignClient("stock-server")
public interface StockFeign {
@GetMapping("index")
String index();
}
controller:
@RestController
public class OrderController {
@Autowired
StockFeign stockFeign;
@GetMapping("/index")
public String index(){
String index = stockFeign.index();
return index;
}
}
4)配置中心
nacos除了作为注册中心以外, 同时也可以作为配置中心来使用;
1)配置中心的基本使用
导入依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
创建项目的bootstrap.properties文件
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
spring.application.name=order-server
在nacos配置中心发布改项目的配置文件:
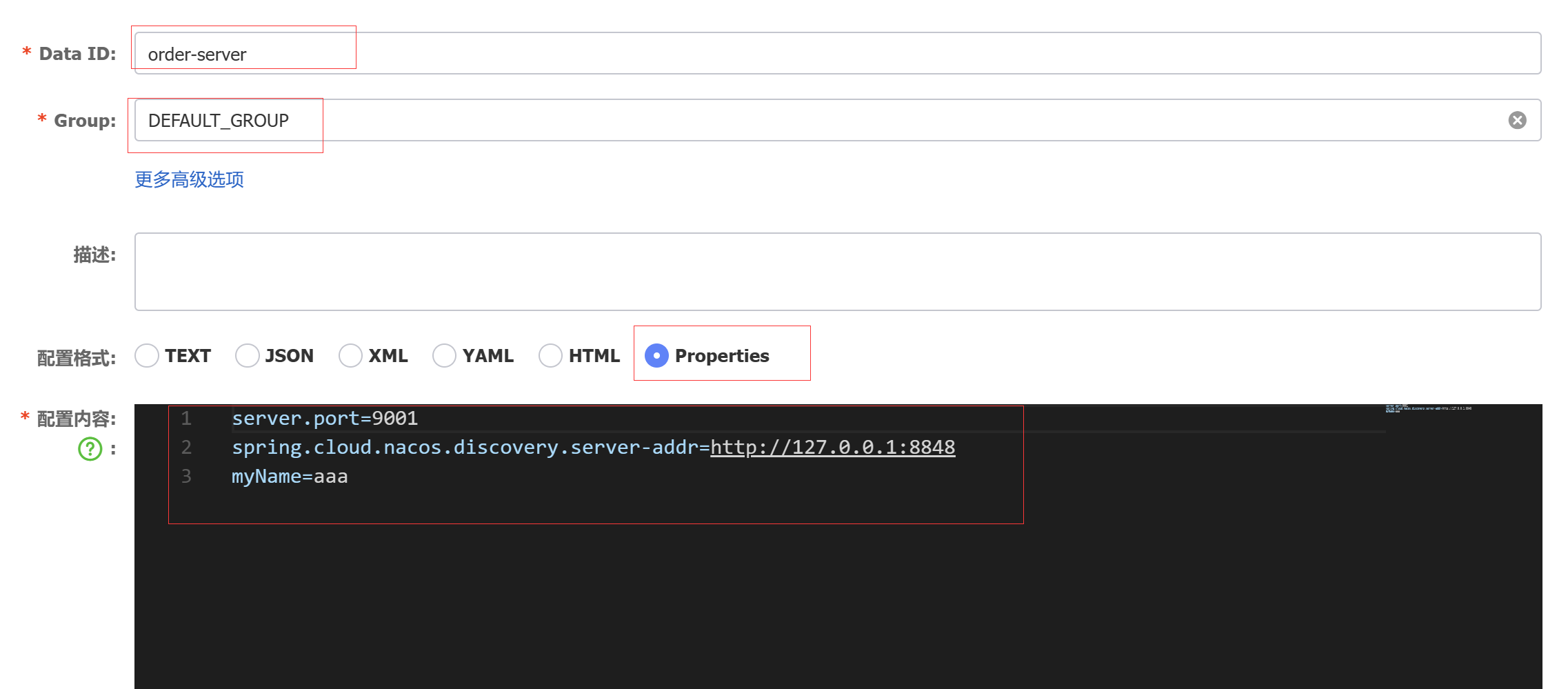
dataId 的完整格式如下:
服务名称-运行环境.后缀名
- 服务名称: 默认为所属项目配置
spring.application.name的值(即:order-server) - 运行环境: 即为当前环境对应的 profile,配置文件中spring.profiles.active设置的值:当 这个值为空时,对应的连接符 - 也将不存
- 后缀名: 为配置内容的数据格式,可以在项目配置文件中通过配置项
spring.cloud.nacos.config.file-extension来配置。目前只支持properties和yaml类型。
总结:配置所属工程的spring.application.name的值 + “.” + properties/yml
2)使用命名空间
Nacos配置中心的命名空间,它用来隔离不同的配置信息,类似于不同的环境或应用程序之间的划分。通过使用不同的命名空间,可以在不同的场景下管理和控制配置信息,实现配置的灵活性和可维护性。每个命名空间都有自己独立的配置集合,可以设置不同的权限和访问控制,方便团队协作和管理配置的版本控制。
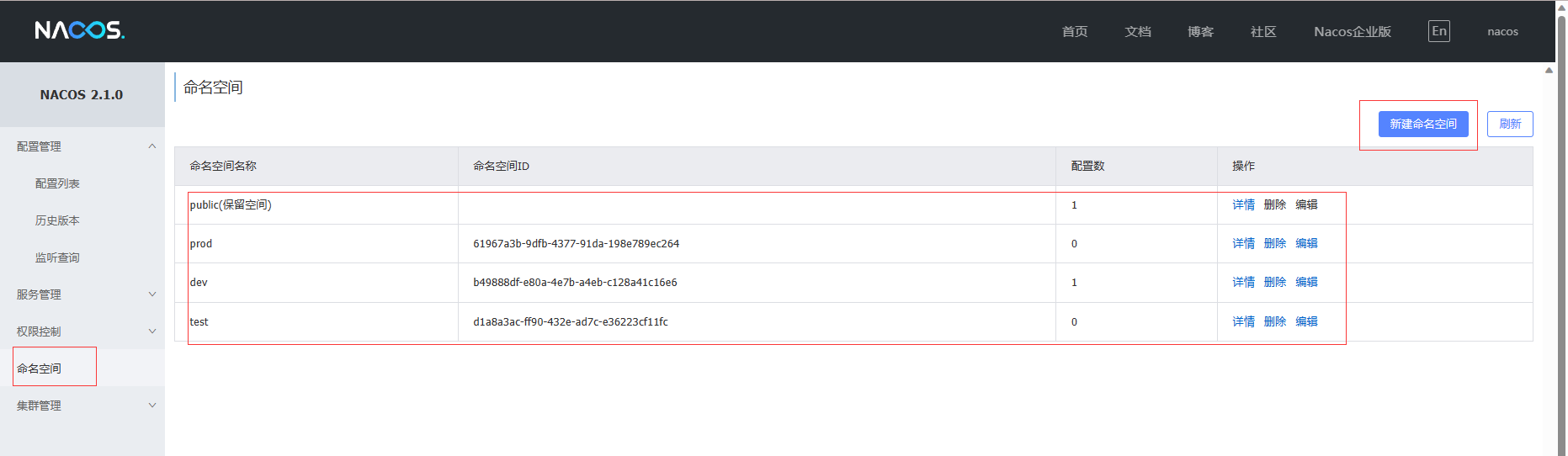
nacos配置中心新建配置文件:order-server-dev.yml
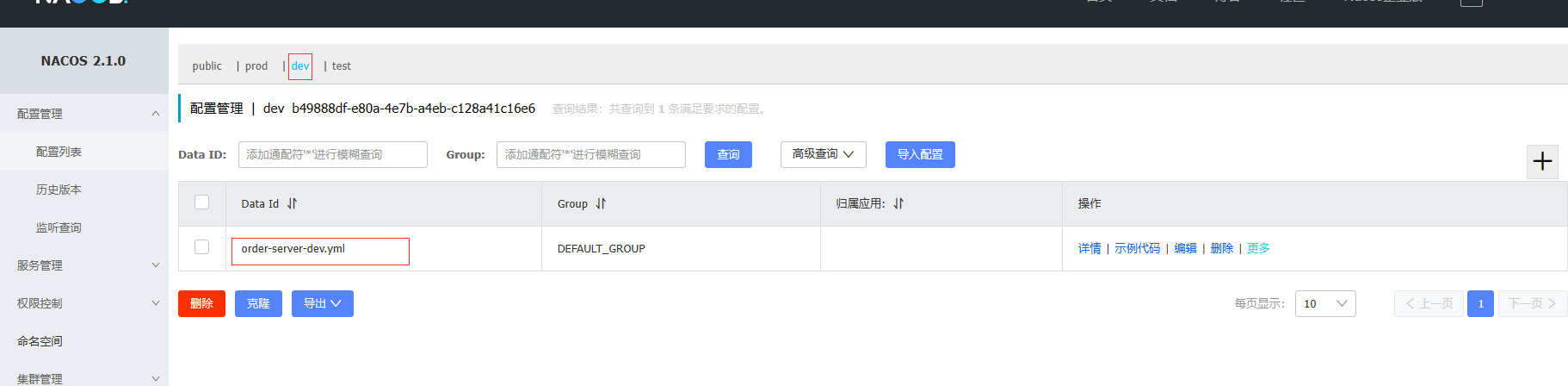
myName: 赵六
server:
port: 9001
spring:
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
项目bootstrap.properties中指定命名空间和运行环境:
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
spring.application.name=order-server
spring.cloud.nacos.config.file-extension=yml
spring.cloud.nacos.config.namespace=b49888df-e80a-4e7b-a4eb-c128a41c16e6
spring.profiles.active=dev
以上是专门为dev运行环境创建命名空间和配置文件, 也可以为其他prod,test等生产环境创建命名空间.
3)使用组名
分组(Group)用于对配置进行逻辑上的分类和管理。通过将不同项目的配置归属到不同的分组中,可以方便地对配置进行组织、查找和管理.
nacos中新建配置文件:
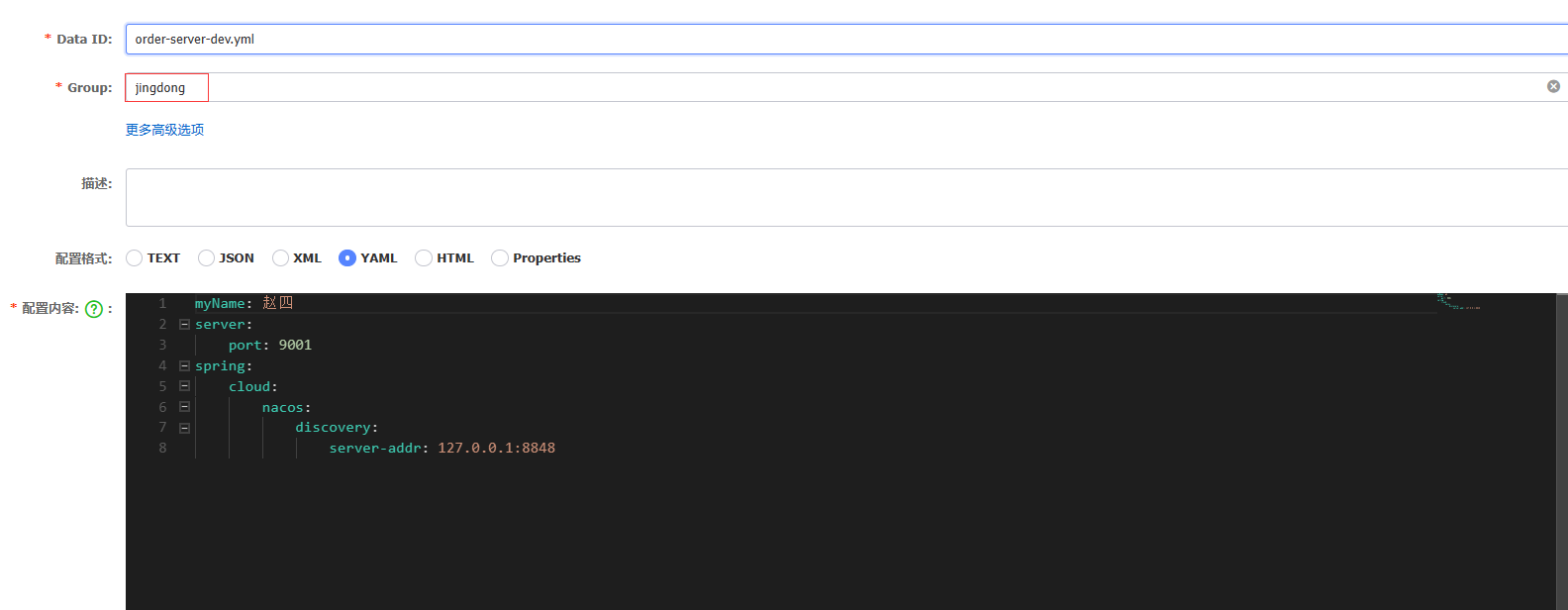
项目的bootstrap.properties文件中加入组的配置:
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
spring.application.name=order-server
spring.cloud.nacos.config.file-extension=yml
spring.cloud.nacos.config.namespace=b49888df-e80a-4e7b-a4eb-c128a41c16e6
spring.cloud.nacos.config.group=jingdong
spring.profiles.active=dev
4)配置自动刷新
5)加载多配置文件
在不同的组创建两个配置文件, 文件的命名也没有按照之前的命名规则:
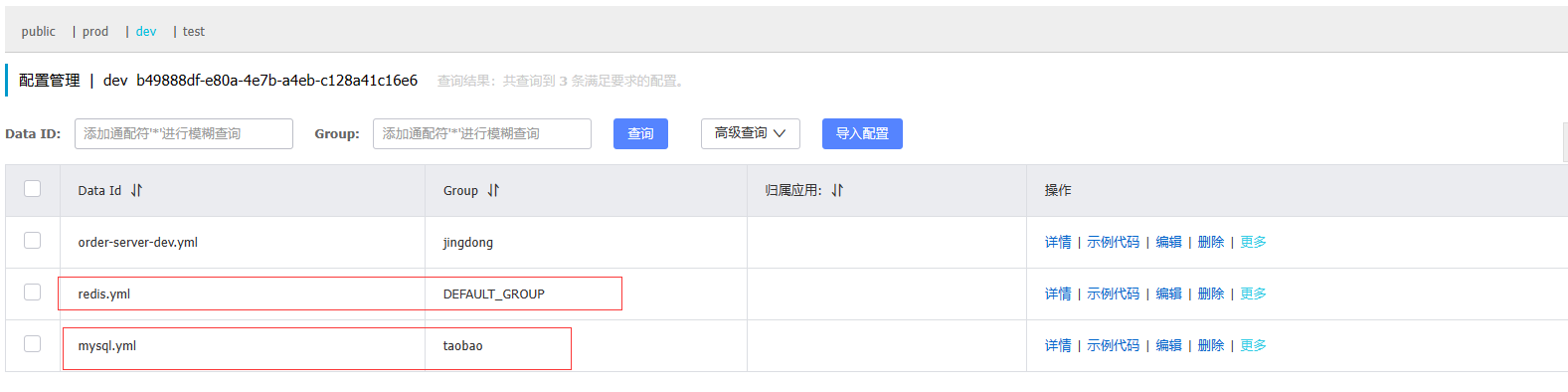
配置文件内容分别为: redis: 1234, mysql: 3306;
bootstrap.properties
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
spring.application.name=order-server
spring.cloud.nacos.config.file-extension=yml
spring.cloud.nacos.config.namespace=b49888df-e80a-4e7b-a4eb-c128a41c16e6
spring.cloud.nacos.config.extension-configs[0].data-id=redis.yml
spring.cloud.nacos.config.extension-configs[1].data-id=mysql.yml
spring.cloud.nacos.config.extension-configs[1].group=taobao
多配置文件刷新需要加上:
spring.cloud.nacos.config.extension-configs[0].refresh=true
5 服务之间的远程调用
- HTTP/REST:使用HTTP协议进行通信,通过RESTful API进行数据交换。每个微服务可以作为独立的服务端和客户端。
- 消息队列:使用消息队列系统(如RabbitMQ、Kafka)来实现异步通信。微服务之间通过发布和订阅消息来进行通信。
- RPC(远程过程调用):微服务之间直接调用对方提供的方法,就像本地方法调用一样。可以使用框架如gRPC、Thrift、Dubbo等来简化远程调用过程。
- 事件驱动架构:微服务之间通过发布和订阅事件进行通信。一个微服务可以产生事件并将其发布到事件总线,其他微服务可以订阅感兴趣的事件并做出响应。
- Service Mesh:使用Service Mesh框架(如Istio、Linkerd)来管理和控制微服务之间的通信。它在微服务之间插入代理,提供了流量管理、安全性、故障恢复等功能。
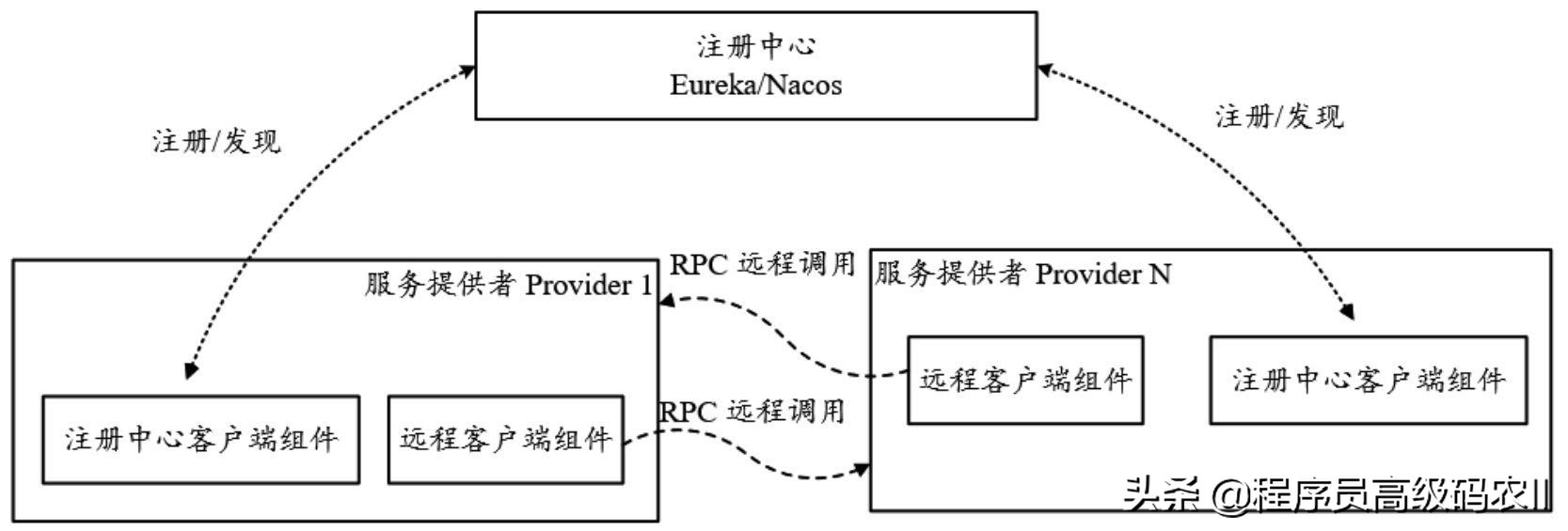
1)openfeign的使用
实现: 订单服务远程调用库存服务
导入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
Feign接口:
@FeignClient("stock-server")
public interface StockFeign {
@GetMapping("index")
String index();
}
OrderController:
@RestController
public class OrderController {
@Autowired
StockFeign stockFeign;
@GetMapping("/index")
public String index(){
String index = stockFeign.index();
return index;
}
}
StockController:
@RestController
public class StockController {
@Value("${server.port}")
Integer port;
@GetMapping("/index")
public String index(){
return "这里是stock........."+port;
}
}
2)传值
3)ribbon负载均衡的配置
openfeign默认使用的负载均衡是ribbon, 而ribbon默认的负载均衡策略是轮询机制:
启动2个stock-server, 端口号分别为:9002,9003;
当访问order-server中controller时, 会发现9002和9003的stock-server时轮流访问的;
ribbon自带的负载均衡策略有:
1)轮询策略: RoundRobinRule,按照一定的顺序依次调用服务实例。比如一共有 3 个服务,第一次调用服务 1,第二次调用服务 2,第三次调用服务3,依次类推.
2)权重策略: WeightedResponseTimeRule,根据每个服务提供者的响应时间分配一个权重,响应时间越长,权重越小,被选中的可能性也就越低。 它的实现原理是,刚开始使用轮询策略并开启一个计时器,每一段时间收集一次所有服务提供者的平均响应时间,然后再给每个服务提供者附上一个权重,权重越高被选中的概率也越大.
3)随机策略: RandomRule,从服务提供者的列表中随机选择一个服务实例.
4)最小连接数策略: BestAvailableRule,也叫最小并发数策略,它是遍历服务提供者列表,选取连接数最小的⼀个服务实例。如果有相同的最小连接数,那么会调用轮询策略进行选取
5)重试策略: RetryRule,按照轮询策略来获取服务,如果获取的服务实例为 null 或已经失效,则在指定的时间之内不断地进行重试来获取服务,如果超过指定时间依然没获取到服务实例则返回 null
6)可用性敏感策略: AvailabilityFilteringRule,先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例.
7)区域敏感策略: ZoneAvoidanceRule,根据服务所在区域(zone)的性能和服务的可用性来选择服务实例,在没有区域的环境下,该策略和轮询策略类似.
配置负载均衡策略有以下两种方式:
1)使用配置文件配置负载均衡策略:
# 格式: 服务名称.ribbon.NFLoadBalancerRuleClassName=负载均衡策略
stock-server.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RandomRule
2)java类中配置负载均衡策略:
@Configuration
public class MyConfig {
@Bean
public IRule loadBalancedRule(){
return new RandomRule()
}
}
3)自定义负载均衡策略:
public class MyRule implements IRule {
private ILoadBalancer lb;
private List<Integer> excludePorts;
public MyRule() {
}
public MyRule(List<Integer> excludePorts) {
this.excludePorts = excludePorts;
}
@Override
public Server choose(Object o) {
List<Server> allServers = lb.getAllServers();
Random random = new Random();
return allServers.get( random.nextInt(allServers.size()) );
}
@Override
public void setLoadBalancer(ILoadBalancer iLoadBalancer) {
this.lb = iLoadBalancer;
}
@Override
public ILoadBalancer getLoadBalancer() {
return lb;
}
}
@Configuration
public class MyConfig {
@Bean
public IRule loadBalancedRule(){
return new MyRule();
}
}
3)SpringCloudLoadBalancer
由于Netflix公司已经停止了对Spring Cloud Netflix组件的维护和更新工作, 所以Netflix 相关的组件已经目前已经有对应的替代组件:
所以Ribbon逐渐被LoadBalancer给替换;
SpringCloudLoadBalancer官方文档:Cloud Native Applications (spring.io)
导入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
关闭对ribbon的支持:
spring.cloud.loadbalancer.ribbon.enabled=false
SpringCloudLoadBalancer自带的负载均衡策略有2中:
1)轮询策略:RoundRobinLoadBalancer (默认)
2)随机策略:RandomLoadBalancer
可以使用以下方式设置改变负载均衡策略:
@Configuration
public class MyConfig {
@Bean
ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RandomLoadBalancer(loadBalancerClientFactory
.getLazyProvider(name, ServiceInstanceListSupplier.class),
name);
}
}
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
@LoadBalancerClients(defaultConfiguration = {MyConfig.class})
public class OrderApp {
public static void main(String[] args) {
SpringApplication.run(OrderApp.class);
}
}
6 微服务网关
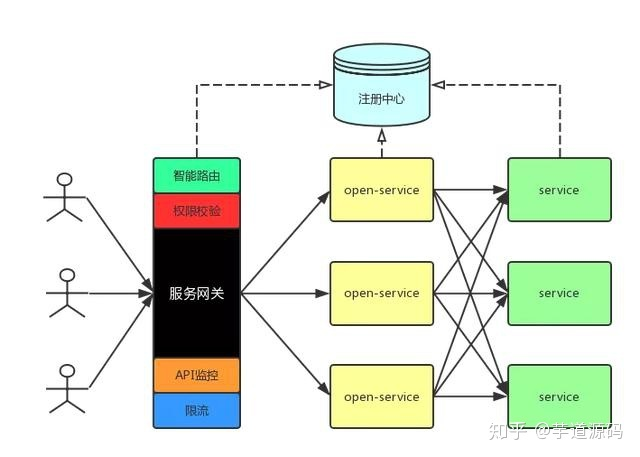
1)网关介绍:
Java微服务是一种用于构建和管理微服务架构的核心组件。它充当了系统的入口点,负责接收来自客户端的请求,并将其转发到适当的微服务实例进行处理.
主要功能和优势:
- 路由和负载均衡:网关可以根据请求的URL、路径或其他条件,将请求路由到相应的微服务实例。同时,它还可以通过负载均衡算法,将请求分发给多个实例,实现高可用和性能优化。
- 安全认证和授权:网关可以集成各种安全机制,例如基于令牌的身份验证、OAuth、JWT等,对请求进行认证和授权。这样可以确保只有经过验证的用户才能访问受保护的微服务。
- 请求转换和协议适配:网关可以在前后端之间进行请求和响应的转换,使不同的客户端能够使用适合的协议和数据格式进行通信。例如,将RESTful请求转换为SOAP请求,或者将JSON请求转换为Protobuf请求等。
- 缓存和性能优化:网关可以对某些请求进行缓存,以减少对后端微服务的请求次数,提供更快的响应速度。此外,它还可以进行请求的压缩、合并和优化,减少网络传输量,提高性能。
- 监控和日志:网关可以收集和记录请求的统计信息、异常情况和日志,方便进行系统的监控和分析。这对于故障排除、性能优化和安全审计非常有帮助。
- 灰度发布和路由策略:网关可以支持灰度发布和路由策略,使得可以逐步将流量从旧版本的微服务迁移到新版本,同时还能够根据一些规则对请求进行动态路由。
常见的Java微服务网关包括Netflix Zuul、Spring Cloud Gateway, 由于Netflix 已经停止维护, 所以目前常用的微服务官网Gateway.
2)基本使用
导入依赖:
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
</dependencies>
配置文件:
server.port=9000
spring.application.name=gateway-server
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
spring:
cloud:
gateway:
routes:
- id: order-server
uri: http://127.0.0.1:9001
predicates:
- Path=/order/**
order-server:
@GetMapping("/order/index")
public String index(){
return "hello"+redis+"+++"+mysql;
}
浏览器访问: 127.0.0.1:9000/order/index, 会直接访问到order-server里面;
3)路由规则
以上的配置中routes就是网关的路由配置,路由是一个List的集合, 而每一个RouteDefinition都包含以下几条属性:
id: 服务器唯一标识;
uri: 服务器的地址;
predicates: 断言集合; 用于匹配请求的路径、方法、头部等信息,从而确定该请求是否应该被路由到某个目标服务。
filters: 过滤器集合; 用于匹配请求的路径、方法、头部等信息,从而确定该请求是否应该被路由到某个目标服务。
路由根据断言进行匹配,匹配成功就会转发请求给服务器URI,在转发请求之前或者之后可以添加过滤器。
3.1)断言工厂
断言用于匹配请求的条件,以确定是否应该将请求路由到某个目标服务。Spring Cloud Gateway提供了多种类型的断言,可以根据请求的路径、方法、头部等信息进行匹配。
Spring Cloud Gateway包含许多内置的断言工厂:
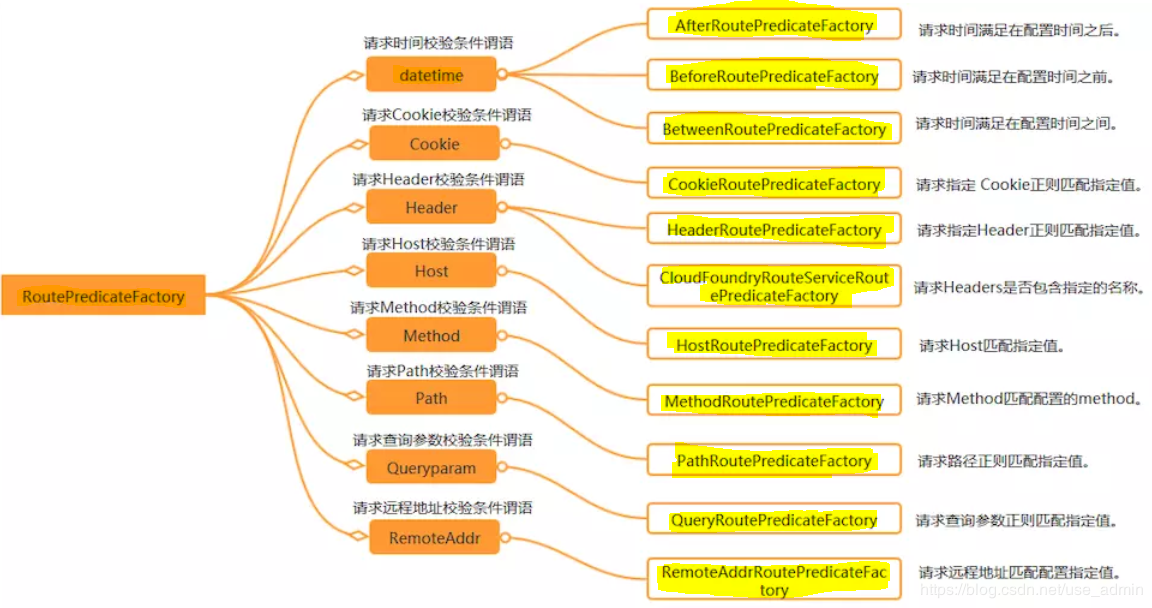
以下是一些常用且需要掌握的断言类型及其示例:
-
Path断言:根据请求的路径进行匹配。
1.简单的路径匹配: Path=/foo:匹配完整的路径为/foo的请求。 Path=/foo/**:匹配以/foo/开头的路径。 2.使用正则表达式进行路径匹配: Path=^/foo/\\d+$:匹配路径以/foo/开头,并且后面跟着一个或多个数字的请求。 3.使用Ant风格的路径匹配: Path=/foo/*:匹配以/foo/开头的任意一级路径。 Path=/foo/**/bar:匹配以/foo/开头,最后一级路径为/bar的请求。 4.使用路径变量进行匹配: Path=/foo/{id}:匹配以/foo/开头,并且后面跟着任意值的请求,将匹配的部分作为路径变量id传递给下游服务。 -
Method断言:根据请求的HTTP方法进行匹配。
predicates: - Method=GET 匹配所有使用GET方法的请求 -
Header断言:根据请求的头部信息进行匹配。
1.简单的Header匹配: Header=X-Custom-Header, custom-value: 匹配请求头X-Custom-Header的值为custom-value的请求。 2.使用正则表达式进行Header匹配: Header=Content-Type, application/json.*: 匹配请求头Content-Type的值以application/json开头的请求。 3.多个Header条件的匹配: Header=X-Custom-Header, custom-value && Authorization, Bearer .*: 同时匹配请求头X-Custom-Header的值为custom-value和Authorization的值以Bearer开头的请求。 4.忽略大小写的Header匹配: Header=X-Custom-Header, custom-value, true: 匹配请求头X-Custom-Header的值为custom-value,忽略大小写的请求 -
Query断言:根据请求的查询参数进行匹配。
1.简单的查询参数匹配: Query=param,value: 匹配查询参数param的值为value的请求。 2.使用正则表达式进行查询参数匹配: Query=param,^\d+$: 匹配查询参数param的值为一个或多个数字的请求。 3.多个查询参数条件的匹配: Query=param1,value1 Query=param2,value2 同时匹配查询参数param1的值为value1和param2的值为value2的请求。 4.忽略大小写的查询参数匹配: Query=param,value, case-insensitive,true: 匹配查询参数param的值为value,忽略大小写的请求。 5.查询参数存在性的匹配: Query=param-exists,true: 匹配包含名为param的查询参数的请求 -
Cookie断言:根据请求的Cookie信息进行匹配
1.简单的Cookie匹配: Cookie=cookieName,value: 匹配名为cookieName且值为value的Cookie。 2.使用正则表达式进行Cookie匹配: Cookie=cookieName, ^\d+$: 匹配名为cookieName且值为一个或多个数字的Cookie。 3.多个Cookie条件的匹配: Cookie=cookie1,value1 Cookie=cookie2,value2 同时匹配名为cookie1且值为value1以及名为cookie2且值为value2的Cookie。 4.忽略大小写的Cookie匹配: Cookie=cookieName,value, case-insensitive=true: 匹配名为cookieName且值为value,忽略大小写的Cookie。 5.Cookie存在性的匹配: Cookie=cookieName-exists,true: 匹配包含名为cookieName的Cookie的请求。
### 3.2)过滤器工厂
过滤器用于对请求和响应进行处理和修改。它们可以在路由前、路由后或者错误处理阶段执行各种操作,例如鉴权、请求转发、日志记录等;
Spring Cloud Gateway提供了两种类型的过滤器:全局过滤器和路由过滤器。
**全局过滤器(Global Filter)**: 全局过滤器适用于所有的路由规则,它们能够对所有进入网关的请求进行统一处理。可以通过实现GlobalFilter接口或使用GatewayFilterFactory来创建自定义的全局过滤器。
```java
@Component
public class CustomGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//从请求头中获取token
String token = exchange.getRequest().getHeaders().getFirst("token");
//如果请求头中没有token就返回权限不足
if(StringUtils.isEmpty(token)){
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}else{
return chain.filter(exchange);
}
}
@Override
public int getOrder() {
return 0; // 过滤器的执行顺序,值越小优先级越高
}
}
路由过滤器: 是指应用于特定路由规则的过滤器。这些过滤器只会对匹配该路由规则的请求进行处理。可以通过在路由配置中添加filters属性来为特定路由规则定义过滤器链。filters属性是一个列表,其中包含要应用于该路由规则的多个过滤器
Spring Cloud Gateway包含许多内置的过滤器工厂:
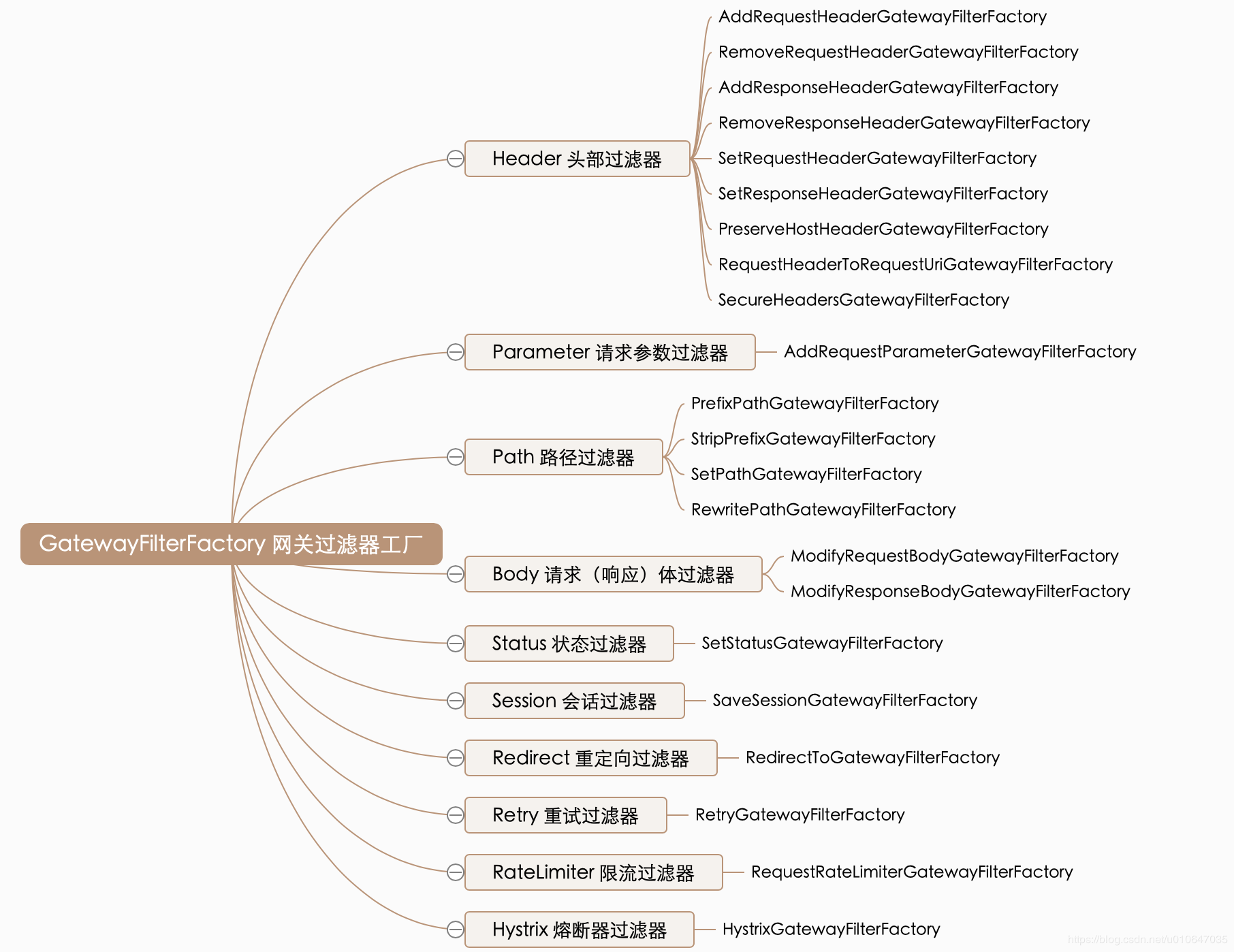
以下是一些常用且需要掌握的过滤工厂类型及其示例:
1.AddRequestHeader:用于向请求头部添加指定的头信息;
filters:
- AddRequestHeader=X-Custom-Header, foo
在请求中添加一个名为X-Custom-Header的头部,值为foo。
2.RewritePath:用于修改请求路径。
filters:
- RewritePath=/oldPath/(?<segment>.*), /newPath/$\{segment}
将匹配/oldPath/开头的请求路径,并将其中的/oldPath/替换为/newPath/。
3.SetRequestHeader:用于设置请求头部的值
filters:
- SetRequestHeader=X-Forwarded-Host, example.com
将请求头部中的X-Forwarded-Host设置为example.com
4.RewriteResponseHeader:用于修改响应头部
filters:
- RewriteResponseHeader=X-Original-Header, X-New-Header
将响应头部中的X-Original-Header替换为X-New-Header
5.RequestRateLimiter:用于实现请求速率限制
filters:
- RequestRateLimiter=redis-rate-limiter, key-resolver: "#{@userKeyResolver}"
使用Redis作为限流存储,使用自定义的Ke-Resolver来解析限流的键
3.3)负载均衡
spring:
cloud:
gateway:
routes:
- id: order-server
uri: http://127.0.0.1:9001
predicates:
- Path=/order/**
由于上述代码中, 将order-server的uri地址写死了, 所以每次访问order-server的时候, 都只会转发到指定写死的uri地址, 如果要做到负载均衡,则必须把网关工程注册到nacos注册中心,然后通过服务名访问;
将网关服务注册到nacos中, 使用nacos作为配置中心保存网关服务器的配置文件, 参见nacos章节;
修改网关服务的配置文件, 使用服务名称替换掉写死的uri地址.
spring:
cloud:
gateway:
routes:
- id: order-server
uri: lb://order-server
predicates:
- Path=/order/**
启动两个order-server, 端口号分别为 9001,和9002.
@RestController
public class OrderController {
@Value("${server.port}")
Integer port;
@GetMapping("/order/index")
public String index(){
return "hello:"+port;
}
}
通过官网访问order-server, 页面上轮流显示9001和9002.
7 Sentinel服务熔断和限流
1)Sentinel
随着微服务的流行,服务和服务之间的稳定性变得越来越重要, 一个服务如果不限流控制, 就会导至这个服务越来越拥堵, 甚至宕机, 当一个服务如果出现问题, 如果不加以处理, 那么就会逐渐蔓延到其他跟该服务相关的其他服务, 而Sentinel是一个开源的流量控制和熔断降级框架, 它就是在帮助开发人员解决分布式系统中的高并发、限流、熔断等问题, 以保证微服务的稳定运行.
Sentinel是由阿里巴巴开发和维护的开源项目, 它是阿里巴巴技术团队在处理大规模分布式系统中的流量控制和熔断降级等问题时所积累的经验的产物.
- 2012 年,Sentinel 诞生,主要功能为入口流量控制。
- 2013-2017 年,Sentinel 在阿里巴巴集团内部迅速发展,成为基础技术模块,覆盖了所有的核心场景。Sentinel 也因此积累了大量的流量归整场景以及生产实践。
- 2018 年,Sentinel 开源,并持续演进。
- 2019 年,Sentinel 朝着多语言扩展的方向不断探索,推出 C++ 原生版本,同时针对 Service Mesh 场景也推出了 Envoy 集群流量控制支持,以解决 Service Mesh 架构下多语言限流的问题。
- 2020 年,推出 Sentinel Go 版本,继续朝着云原生方向演进。
Sentinel 分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
Sentinel 可以简单的分为 Sentinel 核心库和 Dashboard。核心库不依赖 Dashboard,但是结合 Dashboard 可以取得最好的效果。
2)基本概念
资源:是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。在接下来的文档中,我们都会用资源来描述代码块。
只要通过 Sentinel API 定义的代码,就是资源,能够被 Sentinel 保护起来。大部分情况下,可以使用方法签名,URL,甚至服务名称作为资源名来标示资源。
规则:围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规则。所有规则可以动态实时调整。
主要作用:
- 流量控制
- 熔断降级
- 系统负载保护
使用 Sentinel 来进行资源保护,主要分为几个步骤:
- 定义资源
- 定义规则
- 检验规则是否生效
先把可能需要保护的资源定义好,之后再配置规则。也可以理解为,只要有了资源,我们就可以在任何时候灵活地定义各种流量控制规则。在编码的时候,只需要考虑这个代码是否需要保护,如果需要保护,就将之定义为一个资源。
3)基本使用
1)下载指定版本的控制台 jar 包。https://github.com/alibaba/Sentinel/releases
2)cmd跳转到该目录下: 使用指令运行:
java -Dserver.port=8888 -jar sentinel-dashboard-1.8.5.jar
默认端口为:8080, -Dserver.port=8888设置端口.
3)在浏览器中访问sentinel控制台,进入登录页面,管理页面用户名和密码:sentinel/sentinel


此时页面为空,这是因为还没有监控任何服务。另外,sentinel是懒加载的,如果服务没有被访问,也看不到该服务信息。
修改order-server服务
增加依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
配置文件:
spring.cloud.sentinel.eager=true
spring.cloud.sentinel.transport.port=8719
# dashboard 地址
spring.cloud.sentinel.transport.dashboard=127.0.0.1:8888
集群方式启动两个order-server, 9001和9002;
然后刷新访问几次该服务, 再进入到sentinel后台查看:

QPS: 每秒请求数,就是说服务器在一秒的时间内处理了多少个请求。
3.1)流控规则
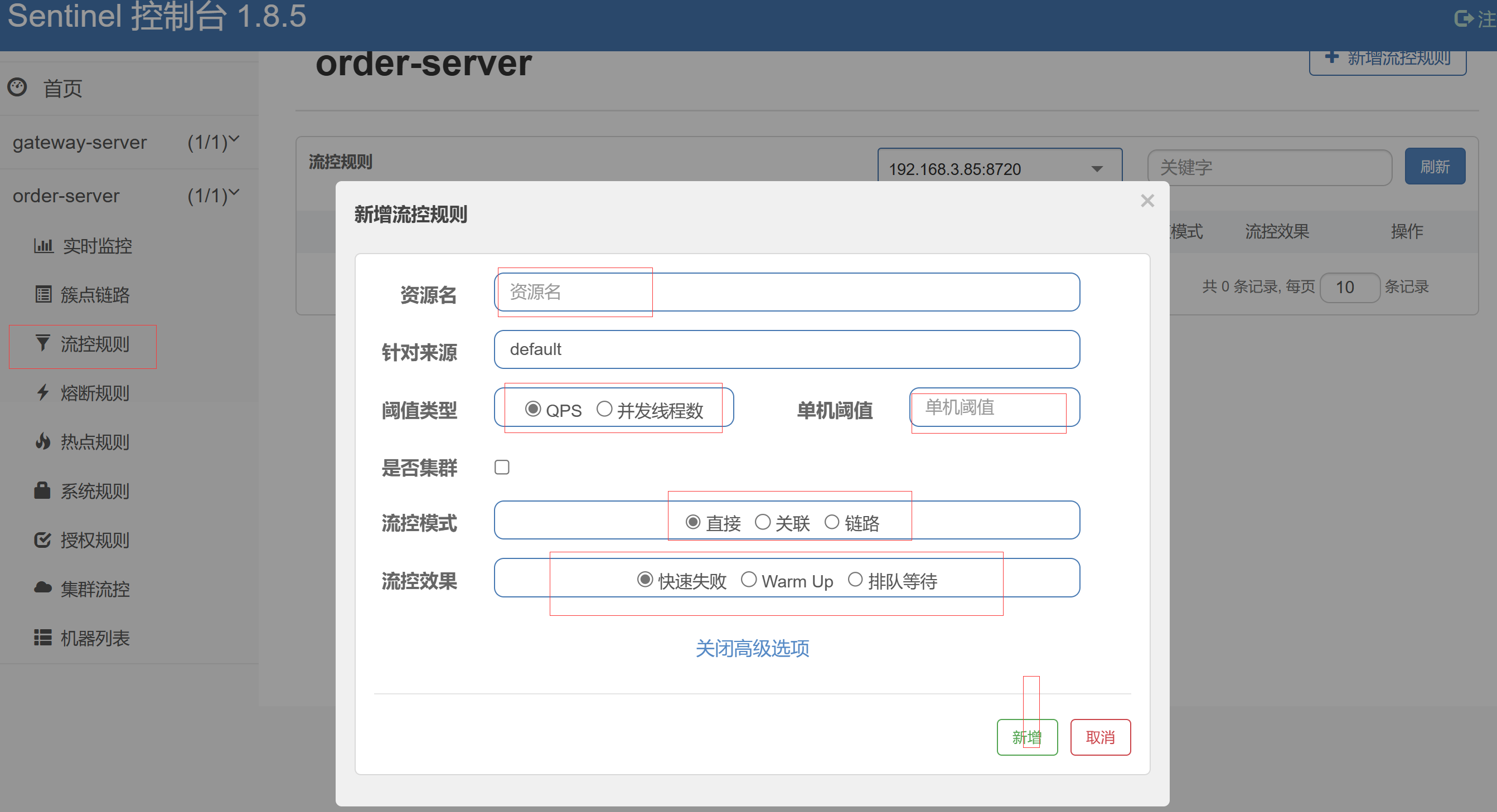
资源名: 当前服务需要显示访问的接口, 可以是controller中的某个方法也可以是service中的某个方法
阀值类型: QPS是控制每秒访问的次数, 并发线程数是限制同时访问的线程数;
单机阀值: 当选择的是QPS时, 阈值时1秒钟内访问的次数, 当选择的是并发线程数时, 阈值是同时访问的线程数
流控模式: 直接:接口达到限流条件时,直接限流, 就是单纯的对当前资源的流量控制. 关联:当关联的资源达到阈值时,就限流自己. 只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就可以限流)[api级别的针对来源]
流控效果: 快速失败,Sentinel会直接拒绝后续的请求,返回错误信息。这种模式适用于对系统资源要求较高、不希望超过一定限制的场景; 预热模式(Warm Up):预热模式在系统刚启动或流量突增时,允许请求的速率缓慢增加,以避免系统被突发流量压垮。这种模式适用于系统冷启动或者持续高流量的场景。排队等待模式(QPS/Thread Model):该模式通过队列来限制请求处理的并发数,当并发请求数达到设定的阈值时,多余的请求将会被放入队列中等待处理。这种模式适用于对系统并发数有限制需求的场景,可以平滑处理突发流量。
3.2)熔断降级规则
Sentinel除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。由于调用关系的复杂性,如果调用链路中的某个资源不稳定,最终会导致请求发生堆积。Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误, 最后造成微服务雪崩.
当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。
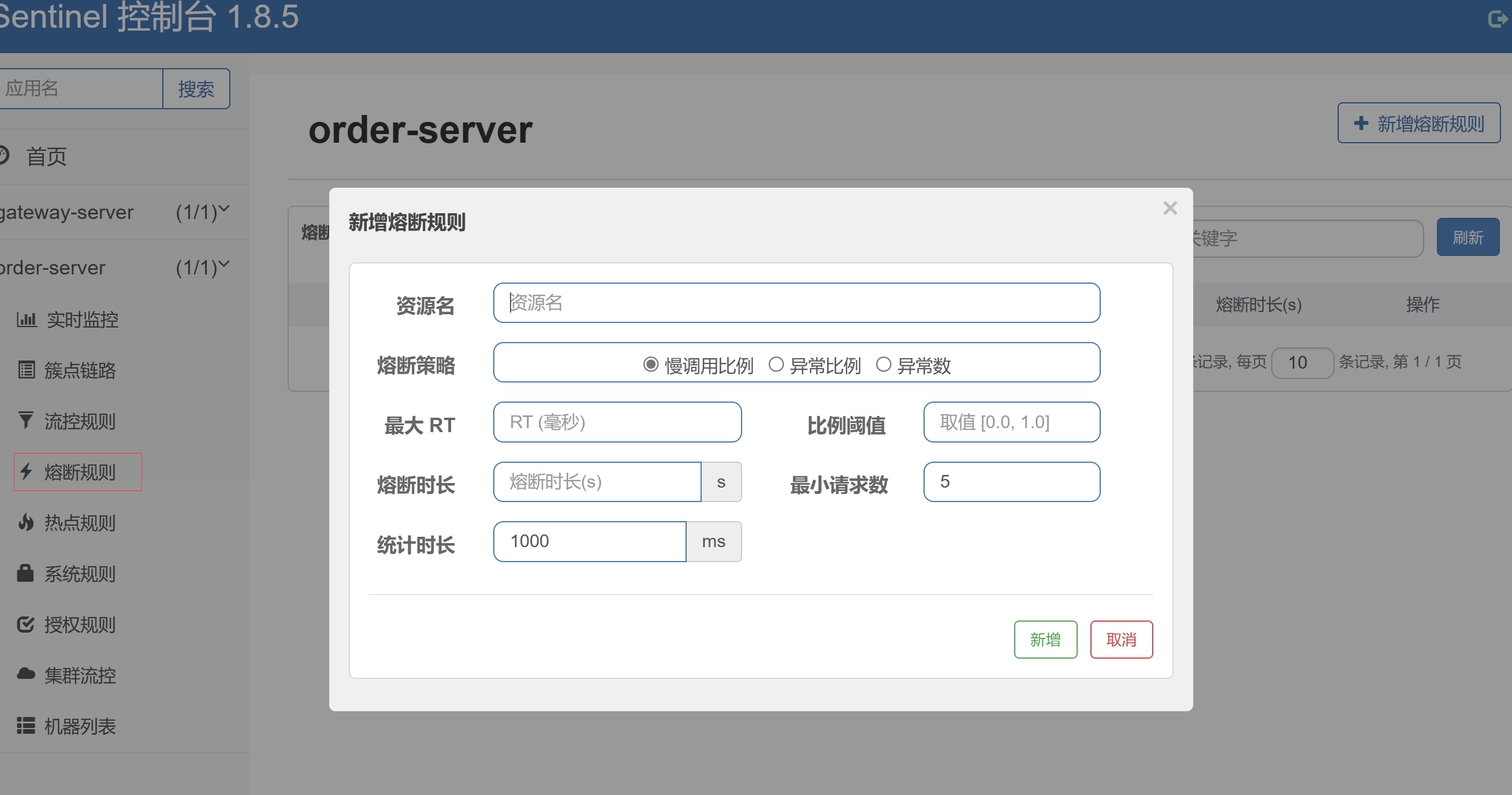
熔断策略:
慢调比: 就是调用使用该资源, 资源响应速度很慢; 最大RT意思是最大响应时间, 比例阈值: 这个最大响应时间的请求比例的最大值;
异常比例: 访问资源出现异常的比例; 比例阈值: 出现异常的比例最大值;
异常数: 当资源近 1 分钟的异常数目;
熔断时长: 限制该资源使用的时长, 超过这个时长后, 进入探测恢复状态(HALF-OPEN)阶段,即接下来的一个请求响应时间小于rt,则熔断结束,否则会再次被熔断。
最小请求数: 触发熔断的最小请求数;
统计时长: 设置多长时间作为一个统计周期, 判断是否进入熔断;
4)限流和熔断处理
@SentinelResource注解
可以灵活用该注解来定义需要控制的资源, 可以在类或者接口上, 也可以是在方法上;
value: 定义资源名称;
blockHandler / fallback: 指定当发生熔断或者限流时的处理函数
blockHandlerClass: 指定当发生熔断或者限流时的处理函数所在的类, 这样可以定义全局的限流熔断的处理方法;
@GetMapping("/order/index")
@SentinelResource(value = "byUrl", blockHandler = "handleException")
public String index(Integer num) throws InterruptedException {
if(num>3){
Thread.sleep(600);
}
return "hello:"+port;
}
public String handleException(Integer num,BlockException e){
return "拥堵了, 心里没数吗?";
}
fallback和blockHandler 作用相同, 但是blockHandler指定的方法形参和资源方法相同外, 还必须入参BlockException异常;
fallback值需要形参相同即可;
优先级上, 一开始几次是fallback,后面限流开始调用blockHandler。
5)配置持久化
1)下载sentinel-dashborad源码;
2)修改pom.xml文件
<!-- for Nacos rule publisher sample -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
<!--<scope>test</scope>-->
</dependency>
spring.cloud.sentinel.eager=true
spring.cloud.sentinel.transport.dashboard=127.0.0.1:8888
spring.cloud.sentinel.transport.port=8719
spring.cloud.sentinel.datasource.ds1.nacos.server-addr=127.0.0.1:8848
spring.cloud.sentinel.datasource.ds1.nacos.data-id=sentinel-service
spring.cloud.sentinel.datasource.ds1.nacos.group-id=DEFAULT_GROUP
spring.cloud.sentinel.datasource.ds1.nacos.data-type=json
spring.cloud.sentinel.datasource.ds1.nacos.rule-type=flow
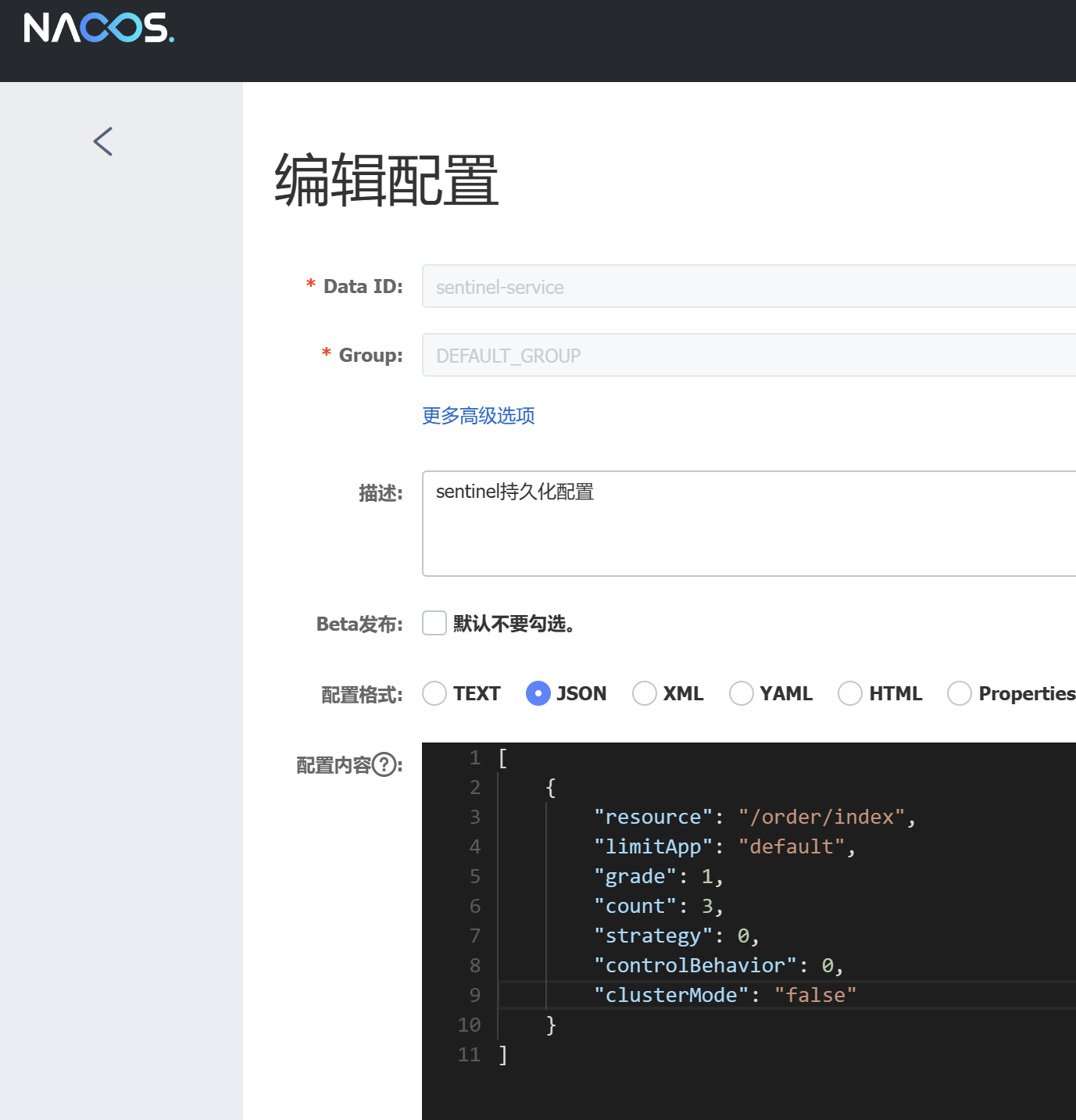
流控规则的写法:
[
{
// 资源名
"resource": "/test",
// 针对来源,若为 default 则不区分调用来源
"limitApp": "default",
// 限流阈值类型(1:QPS;0:并发线程数)
"grade": 1,
// 阈值
"count": 1,
// 是否是集群模式
"clusterMode": false,
// 流控效果(0:快速失败;1:Warm Up(预热模式);2:排队等待)
"controlBehavior": 0,
// 流控模式(0:直接;1:关联;2:链路)
"strategy": 0,
// 预热时间(秒,预热模式需要此参数)
"warmUpPeriodSec": 10,
// 超时时间(排队等待模式需要此参数)
"maxQueueingTimeMs": 500,
// 关联资源、入口资源(关联、链路模式)
"refResource": "rrr"
}
]
spring.cloud.sentinel.datasource.ds2.nacos.server-addr=127.0.0.1:8848
spring.cloud.sentinel.datasource.ds2.nacos.data-id=sentinel-order2-server
spring.cloud.sentinel.datasource.ds2.nacos.group-id=DEFAULT_GROUP
spring.cloud.sentinel.datasource.ds2.nacos.data-type=json
spring.cloud.sentinel.datasource.ds2.nacos.rule-type=degrade
熔断降级的写法:
[
{
// 资源名
"resource": "/test1",
"limitApp": "default",
// 熔断策略(0:慢调用比例,1:异常比率,2:异常计数)
"grade": 0,
// 最大RT、比例阈值、异常数
"count": 200,
// 慢调用比例阈值,仅慢调用比例模式有效(1.8.0 引入)
"slowRatioThreshold": 0.2,
// 最小请求数
"minRequestAmount": 5,
// 当单位统计时长(类中默认1000)
"statIntervalMs": 1000,
// 熔断时长
"timeWindow": 10
}
]
8 分布式CAP理论
1)CAP的介绍
分布式CAP理论是由计算机科学家Eric Brewer提出的,它描述了在分布式系统中三个重要属性之间的冲突。这三个属性是一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)。根据CAP理论,一个分布式系统最多只能同时满足其中的两个属性,无法同时满足全部三个。
**一致性(Consistency)**即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。对于一致性,可以分为从客户端和服务端两个不同的视角。
从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。一致性是因为有并发读写才有的问题,因此在理解一致性的问题时,一定要注意结合考虑并发读写的场景。
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
**可用性(Availability)**即服务一直可用,而且是正常响应时间。对于一个可用性的分布式系统,每一个非故障的节点必须对每一个请求作出响应。也就是,该系统使用的任何算法必须最终终止。当同时要求分区容忍性时,这是一个很强的定义:即使是严重的网络错误,每个请求必须终止。
好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。可用性通常情况下可用性和分布式数据冗余,负载均衡等有着很大的关联。
**分区容错性(Partition tolerance)**即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。分区容错性和扩展性紧密相关。在分布式应用中,可能因为一些分布式的原因导致系统无法正常运转。好的分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,或者是机器之间有网络异常,将分布式系统分隔未独立的几个部分,各个部分还能维持分布式系统的运作,这样就具有好的分区容错性。
2)CAP的证明
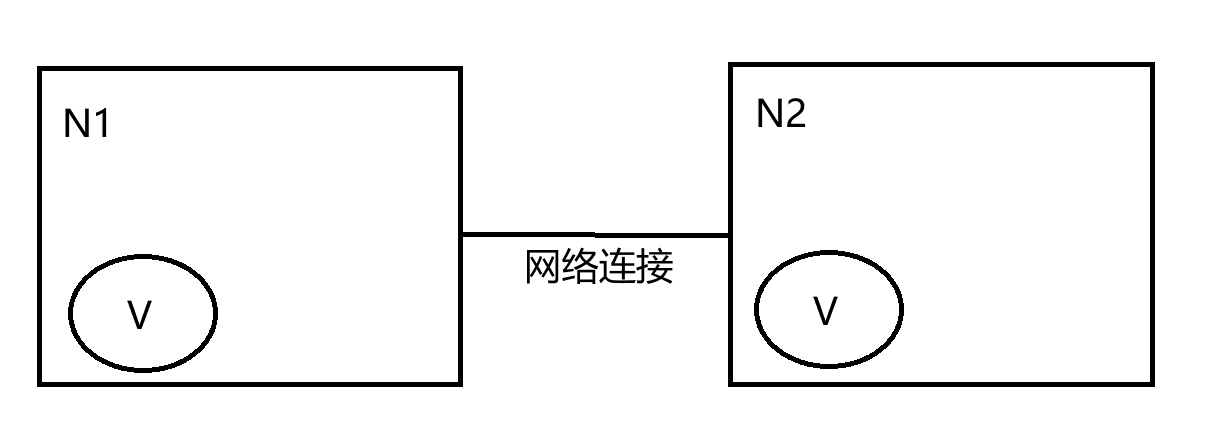
如上图,是我们证明CAP的基本场景,网络中有两个节点N1和N2,可以简单的理解N1和N2分别是两台计算机,他们之间网络可以连通,N1中有一个应用程序A,和一个数据库V,N2也有一个应用程序B2和一个数据库V。现在,A和B是分布式系统的两个部分,V是分布式系统的数据存储的两个子数据库。
在满足一致性的时候,N1和N2中的数据是一样的,V0=V0。在满足可用性的时候,用户不管是请求N1或者N2,都会得到立即响应。在满足分区容错性的情况下,N1和N2有任何一方宕机,或者网络不通的时候,都不会影响N1和N2彼此之间的正常运作。
如上图,是分布式系统正常运转的流程,用户向N1机器请求数据更新,程序A更新数据库Vo为V1,分布式系统将数据进行同步操作M,将V1同步的N2中V0,使得N2中的数据V0也更新为V1,N2中的数据再响应N2的请求。
这里,可以定义N1和N2的数据库V之间的数据是否一样为一致性;外部对N1和N2的请求响应为可用行;N1和N2之间的网络环境为分区容错性。这是正常运作的场景,也是理想的场景,然而现实是残酷的,当错误发生的时候,一致性和可用性还有分区容错性,是否能同时满足,还是说要进行取舍呢?
作为一个分布式系统,它和单机系统的最大区别,就在于网络,现在假设一种极端情况,N1和N2之间的网络断开了,我们要支持这种网络异常,相当于要满足分区容错性,能不能同时满足一致性和响应性呢?还是说要对他们进行取舍。
假设在N1和N2之间网络断开的时候,有用户向N1发送数据更新请求,那N1中的数据V0将被更新为V1,由于网络是断开的,所以分布式系统同步操作M,所以N2中的数据依旧是V0;这个时候,有用户向N2发送数据读取请求,由于数据还没有进行同步,应用程序没办法立即给用户返回最新的数据V1,怎么办呢?有二种选择,第一,牺牲数据一致性,响应旧的数据V0给用户;第二,牺牲可用性,阻塞等待,直到网络连接恢复,数据更新操作M完成之后,再给用户响应最新的数据V1。
这个过程,证明了要满足分区容错性的分布式系统,只能在一致性和可用性两者中,选择其中一个。
3)CAP的权衡
通过CAP理论,我们知道无法同时满足一致性、可用性和分区容错性这三个特性,那要舍弃哪个呢?
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是你想不想的问题,而是始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。
CP without A:如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到N个9,即保证P和A,舍弃C(退而求其次保证最终一致性)。虽然某些地方会影响客户体验,但没达到造成用户流程的严重程度。
对于涉及到钱财这样不能有一丝让步的场景,C必须保证。网络发生故障宁可停止服务,这是保证CA,舍弃P。貌似这几年国内银行业发生了不下10起事故,但影响面不大,报到也不多,广大群众知道的少。还有一种是保证CP,舍弃A。例如网络故障事只读不写。
孰优孰略,没有定论,只能根据场景定夺,适合的才是最好的。
9 分布式锁
1)介绍
随着技术快速发展,数据规模增大,分布式系统越来越普及,一个应用往往会部署在多台机器上(多节点),在有些场景中,为了保证数据不重复,要求在同一时刻,同一任务只在一个节点上运行,即保证某一方法同一时刻只能被一个线程执行。在单机环境中,应用是在同一进程下的,只需要保证单进程多线程环境中的线程安全性,通过 JAVA 提供的 volatile、ReentrantLock、synchronized 以及 concurrent 并发包下一些线程安全的类等就可以做到。而在多机部署环境中,不同机器不同进程,就需要在多进程下保证线程的安全性了。因此,分布式锁应运而生。
分布式锁需满足四个条件
首先,为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了,即不能误解锁。
- 具有容错性。只要大多数Redis节点正常运行,客户端就能够获取和释放锁。
常见的分布式的实现方式:
| 分类 | 方案 | 实现原理 | 优点 | 缺点 |
|---|---|---|---|---|
| 基于数据库 | 基于mysql 表唯一索引 | 1.表增加唯一索引 2.加锁:执行insert语句,若报错,则表明加锁失败 3.解锁:执行delete语句 | 完全利用DB现有能力,实现简单 | 1.锁无超时自动失效机制,有死锁风险 2.不支持锁重入,不支持阻塞等待 3.操作数据库开销大,性能不高 |
| 基于MongoDB findAndModify原子操作 | 1.加锁:执行findAndModify原子命令查找document,若不存在则新增 2.解锁:删除document | 实现也很容易,较基于MySQL唯一索引的方案,性能要好很多 | 1.大部分公司数据库用MySQL,可能缺乏相应的MongoDB运维、开发人员 2.锁无超时自动失效机制 | |
| 基于分布式协调系统 | 基于ZooKeeper | 1.加锁:在/lock目录下创建临时有序节点,判断创建的节点序号是否最小。若是,则表示获取到锁;否,则则watch /lock目录下序号比自身小的前一个节点 2.解锁:删除节点 | 1.由zk保障系统高可用 2.Curator框架已原生支持系列分布式锁命令,使用简单 | 需单独维护一套zk集群,维保成本高 |
| 基于缓存 | 基于redis命令 | 1. 加锁:执行setnx,若成功再执行expire添加过期时间 2. 解锁:执行delete命令 | 实现简单,相比数据库和分布式系统的实现,该方案最轻,性能最好 | 1.setnx和expire分2步执行,非原子操作;若setnx执行成功,但expire执行失败,就可能出现死锁 2.delete命令存在误删除非当前线程持有的锁的可能 3.不支持阻塞等待、不可重入 |
| 基于redis Lua脚本能力 | 1. 加锁:执行SET lock_name random_value EX seconds NX 命令 2. 解锁:执行Lua脚本,释放锁时验证random_value – ARGV[1]为random_value, KEYS[1]为lock_nameif redis.call(“get”, KEYS[1]) == ARGV[1] then return redis.call(“del”,KEYS[1])else return 0 end | 同上;实现逻辑上也更严谨,除了单点问题,生产环境采用用这种方案,问题也不大。 | 不支持锁重入,不支持阻塞等待 |
表格中对比了几种常见的方案,redis+lua基本可应付工作中分布式锁的需求。
2)基本使用
模拟:3台order-server服务器同时卖20个商品, 商品数量保存在redis中;
业务逻辑: order-server从redis中取出商品数量, 如果数量大于10, 那么就卖出一个商品, 然后讲redis中的数量-1, 如果取出的数量等于0, 代表商品卖完了, 返回商品抢购结束!
依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.17.1</version>
</dependency>
基本配置
spring:
redis:
host: 175.24.205.196
port: 6379
password: boge123123
database: 3
启动网关服务;
启动3个订单服务;
不加锁:
普通锁:
分布式锁:
redisson分布式锁流程:
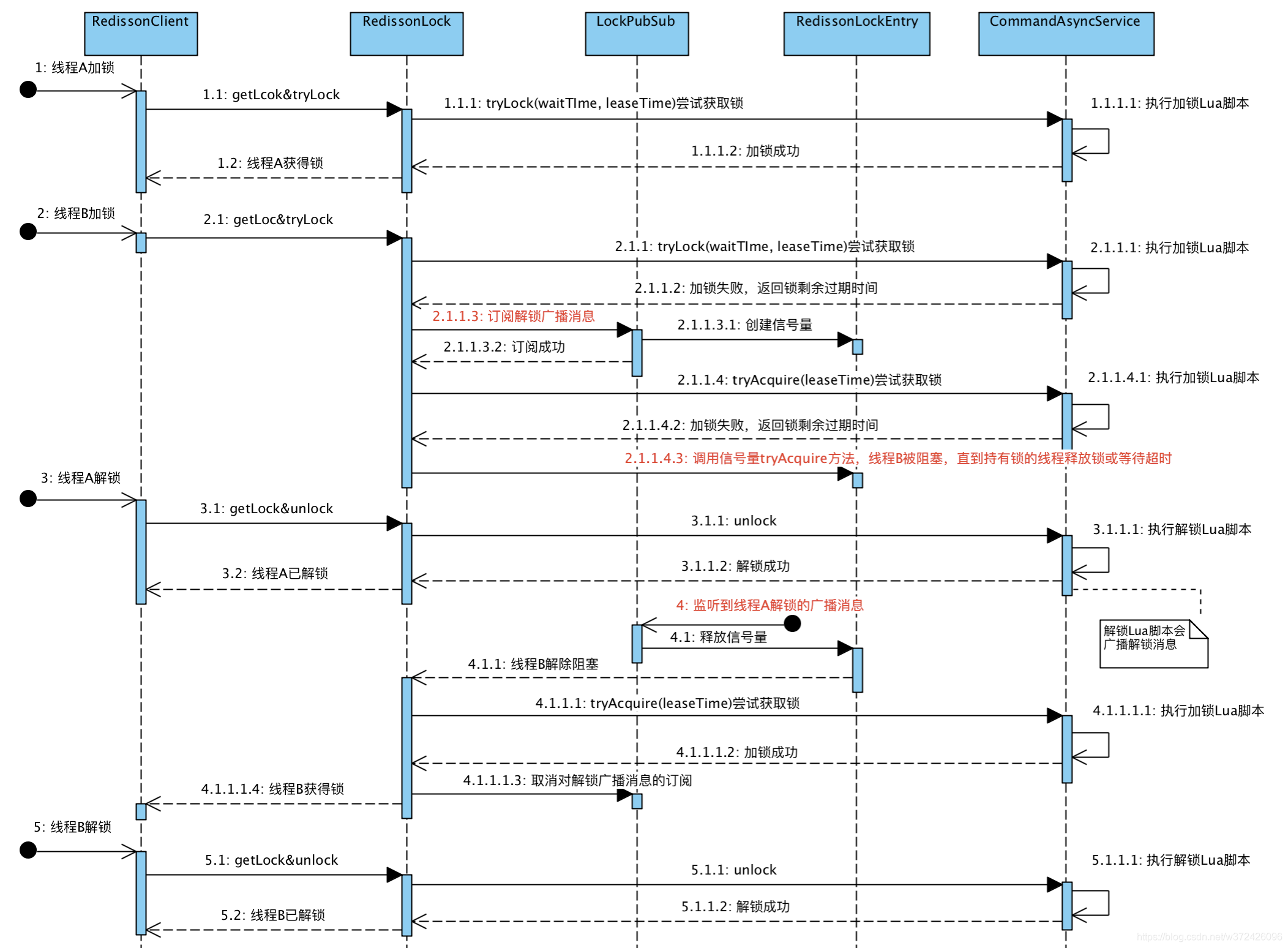
3)redisson中的锁
普通锁
RLock lock = redisson.getLock("myLock");
lock.lock();
lock.lock(10, TimeUnit.SECONDS);
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
公平锁
RLock lock = redisson.getFairLock("myLock");
lock.lock();
lock.lock(10, TimeUnit.SECONDS);
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
多重锁
RLock lock1 = redisson1.getLock("lock1");
RLock lock2 = redisson2.getLock("lock2");
RLock lock3 = redisson3.getLock("lock3");
RLock multiLock = anyRedisson.getMultiLock(lock1, lock2, lock3);
multiLock.lock();
multiLock.lock(10, TimeUnit.SECONDS);
boolean res = multiLock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
multiLock.unlock();
}
}
读写锁
RReadWriteLock rwlock = redisson.getReadWriteLock("myLock");
RLock lock = rwlock.readLock();
RLock lock = rwlock.writeLock();
lock.lock();
lock.lock(10, TimeUnit.SECONDS);
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
信号量
RSemaphore semaphore = redisson.getSemaphore("mySemaphore");
semaphore.acquire();
semaphore.acquire(10);
// or try to acquire permit
boolean res = semaphore.tryAcquire();
// or try to acquire permit or wait up to 15 seconds
boolean res = semaphore.tryAcquire(15, TimeUnit.SECONDS);
// or try to acquire 10 permit
boolean res = semaphore.tryAcquire(10);
// or try to acquire 10 permits or wait up to 15 seconds
boolean res = semaphore.tryAcquire(10, 15, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
semaphore.release();
}
}
10 分布式事务
1)事务的介绍
严格意义上的事务实现应该是具备原子性、一致性、隔离性和持久性,简称 ACID。
- 原子性(Atomicity),可以理解为一个事务内的所有操作要么都执行,要么都不执行。
- 一致性(Consistency),可以理解为数据是满足完整性约束的,也就是不会存在中间状态的数据,比如你账上有400,我账上有100,你给我打200块,此时你账上的钱应该是200,我账上的钱应该是300,不会存在我账上钱加了,你账上钱没扣的中间状态。
- 隔离性(Isolation),指的是多个事务并发执行的时候不会互相干扰,即一个事务内部的数据对于其他事务来说是隔离的。
- 持久性(Durability),指的是一个事务完成了之后数据就被永远保存下来,之后的其他操作或故障都不会对事务的结果产生影响。
分布式事务是指在分布式系统中涉及到多个独立的操作或数据更新时,保证这些操作要么全部成功要么全部失败的机制。它是为了解决分布式系统中数据一致性问题而提出的一种技术手段。
在传统的单体应用中,数据库事务能够确保操作的原子性、一致性、隔离性和持久性(ACID)特性。然而,在分布式系统中,由于存在多个数据库实例、服务节点或存储介质,事务的隔离性和一致性变得更加复杂。
为了解决这些挑战,有几种常见的分布式事务模型被提出,包括两阶段提交(2PC)、三阶段提交(3PC)、补偿事务等。这些模型都试图通过协调各参与节点的状态来达到全局一致性。
然而,分布式事务也带来了一些性能和可用性的问题。由于需要协调多个节点,会增加通信开销和延迟;同时,若一个节点失效,整个事务可能会被阻塞或回滚。因此,在设计分布式系统时,需要权衡事务一致性要求和性能可扩展性。
2)常用的分布式事务解决方案
a)XA 模式之两阶段提交
两阶段提交又称2PC(two-phase commit protocol),2pc是一个非常经典的强一致、中心化的原子提交协议。这里所说的中心化是指协议中有两类节点:一个是中心化协调者节点和N个参与者节点。
准备阶段: 事务协调者向所有事务参与者发送事务内容,询问是否可以提交事务,并等待参与者回复。事务参与者收到事务内容,开始执行事务操作,讲 undo 和 redo 信息记入事务日志中(但此时并不提交事务)。如果参与者执行成功,给协调者回复yes,表示可以进行事务提交。如果执行失败,给协调者回复no,表示不可提交。
提交阶段: 如果协调者收到了参与者的失败信息或超时信息,直接给所有参与者发送回滚(rollback)信息进行事务回滚,否则发送提交(commit)信息。参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。(注意:必须在最后阶段释放锁资源)
会遇到的一些问题
性能问题
从流程上我们可以看得出,其最大缺点就在于它的执行过程中间,节点都处于阻塞状态。各个操作数据库的节点此时都占用着数据库资源,只有当所有节点准备完毕,事务协调者才会通知进行全局提交,参与者进行本地事务提交后才会释放资源。这样的过程会比较漫长,对性能影响比较大。
协调者单点故障问题
事务协调者是整个XA模型的核心,一旦事务协调者节点挂掉,会导致参与者收不到提交或回滚的通知,从而导致参与者节点始终处于事务无法完成的中间状态。
丢失消息导致的数据不一致问题
在第二个阶段,如果发生局部网络问题,一部分事务参与者收到了提交消息,另一部分事务参与者没收到提交消息,那么就会导致节点间数据的不一致问题。
2PC 方案实现起来简单,基于上面提到的两阶段提交协议中会遇到的问题;
b)XA 模式之三阶段提交
三阶段提交又称3PC, 三阶段提交是在二阶段提交上的改进版本,其在两阶段提交的基础上增加了 CanCommit阶段,并加入了超时机制。同时在协调者和参与者中都引入超时机制。三阶段将二阶段的准备阶段拆分为2个阶段,插入了一个preCommit阶段,以此来处理原先二阶段,参与者准备后,参与者发生崩溃或错误,导致参与者无法知晓是否提交或回滚的不确定状态所引起的延时问题。
阶段一(canCommit): 协调者向所有参与者发出包含事务内容的 canCommit 请求,询问是否可以提交事务,并等待所有参与者答复。参与者收到 canCommit 请求后,如果认为可以执行事务操作,则反馈 yes 并进入预备状态,否则反馈 no
阶段二(PreCommit): 阶段一中,如果所有的参与者都返回Yes的话,那么就会进入PreCommit阶段进行事务预提交。此时分布式事务协调者会向所有的参与者节点发送PreCommit请求,参与者收到后开始执行事务操作,并将Undo和Redo信息记录到事务日志中。参与者执行完事务操作后(此时属于未提交事务的状态),就会向协调者反馈“Ack”表示我已经准备好提交了,并等待协调者的下一步指令。如果阶段一中有任何一个参与者节点返回的结果是No响应,或者协调者在等待参与者节点反馈的过程中因挂掉而超时(2PC中只有协调者可以超时,参与者没有超时机制)。整个分布式事务就会中断,协调者就会向所有的参与者发送“abort”请求。
阶段三(do Commit): 该阶段进行真正的事务提交,在阶段二中如果所有的参与者节点都可以进行PreCommit提交,那么协调者就会从“预提交状态” 转变为 “提交状态”。然后向所有的参与者节点发送"doCommit"请求,参与者节点在收到提交请求后就会各自执行事务提交操作,并向协调者节点反馈“Ack”消息,协调者收到所有参与者的Ack消息后完成事务。
相比较2PC而言,3PC对于协调者(Coordinator)和参与者(Partcipant)都设置了超时时间,而2PC只有协调者才拥有超时机制。这解决了一个什么问题呢?这个优化点,主要是避免了参与者在长时间无法与协调者节点通讯(协调者挂掉了)的情况下,无法释放资源的问题,因为参与者自身拥有超时机制会在超时后,自动进行本地commit从而进行释放资源。而这种机制也侧面降低了整个事务的阻塞时间和范围。
另外,通过CanCommit、PreCommit、DoCommit三个阶段的设计,相较于2PC而言,多设置了一个缓冲阶段保证了在最后提交阶段之前各参与节点的状态是一致的。
以上就是3PC相对于2PC的一个提高(相对缓解了2PC中的前两个问题),但是3PC依然没有完全解决数据不一致的问题。假如在 DoCommit 过程,参与者A无法接收协调者的通信,那么参与者A会自动提交,但是提交失败了,其他参与者成功了,此时数据就会不一致。
c) AT模式
AT 模式是一种无侵入的分布式事务解决方案。在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
把业务数据在更新前后的数据镜像组织成回滚日志,将业务数据的更新和回滚日志在同一个本地事务中提交,分别插入到业务表和 UNDO_LOG 表中。
二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可;
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理;
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。但AT模式存在的不足就是当操作的数据是共享型数据,会存在脏写的问题,所以如果是用户独有数据可以使用AT模式。
d)TCC模式
TCC方案其实是两阶段提交的一种改进。分成了Try、Confirm、Cancel三个操作。事务发起方在一阶段执行 Try 方式,在二阶段提交执行 Confirm 方法,二阶段回滚执行 Cancel 方法。
- Try部分完成业务的准备工作
- confirm部分完成业务的提交
- cancel部分完成事务的回滚
TCC 模式,不依赖于底层数据资源的事务支持:
一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
二阶段 commit 行为:调用 自定义 的 commit 逻辑。
二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
用户接入 TCC 模式,最重要的事情就是考虑如何将业务模型拆成 2 阶段,实现成 TCC 的 3 个方法,并且保证 Try 成功 Confirm 一定能成功。相对于 AT 模式,TCC 模式对业务代码有一定的侵入性,但是 TCC 模式无 AT 模式的全局行锁,TCC 性能会比 AT 模式高很多。
e)SAGA模式
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
分布式事务执行过程中,依次执行各参与者的正向操作,如果所有正向操作均执行成功,那么分布式事务提交。如果任何一个正向操作执行失败,那么分布式事务会退回去执行前面各参与者的逆向回滚操作,回滚已提交的参与者,使分布式事务回到初始状态。
Saga 正向服务与补偿服务也需要业务开发者实现。因此是业务入侵的。
Saga 模式下分布式事务通常是由事件驱动的,各个参与者之间是异步执行的,Saga 模式是一种长事务解决方案。
使用场景
Saga 模式适用于业务流程长且需要保证事务最终一致性的业务系统,Saga 模式一阶段就会提交本地事务,无锁、长流程情况下可以保证性能。
事务参与者可能是其它公司的服务或者是遗留系统的服务,无法进行改造和提供 TCC 要求的接口,可以使用 Saga 模式。
- 补偿事务(Compensating Transaction):补偿事务模式基于"撤销"操作来实现事务的回滚。当某个步骤发生错误时,可以通过执行逆向操作来恢复数据的一致性。
- Saga模式:Saga是一种基于微服务架构的分布式事务处理模式,通过一系列局部事务来完成分布式事务。每个局部事务都有一个补偿操作,用于回滚之前的操作。
- TCC模式(Try-Confirm-Cancel):TCC是一种基于业务逻辑的分布式事务解决方案。在TCC中,每个参与者需要实现Try、Confirm和Cancel三个操作,分别对应事务的尝试阶段、确认阶段和取消阶段。
f)总结
四种分布式事务模式,分别在不同的时间被提出,每种模式都有它的适用场景:
AT 模式是无侵入的分布式事务解决方案,适用于不希望对业务进行改造的场景,几乎0学习成本。
TCC 模式是高性能分布式事务解决方案,适用于核心系统等对性能有很高要求的场景。
Saga 模式是长事务解决方案,适用于业务流程长且需要保证事务最终一致性的业务系统,Saga 模式一阶段就会提交本地事务,无锁,长流程情况下可以保证性能,多用于渠道层、集成层业务系统。事务参与者可能是其它公司的服务或者是遗留系统的服务,无法进行改造和提供 TCC 要求的接口,也可以使用 Saga 模式。
XA模式是分布式强一致性的解决方案,但性能低而使用较少。
3)seata
a)介绍
seata是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
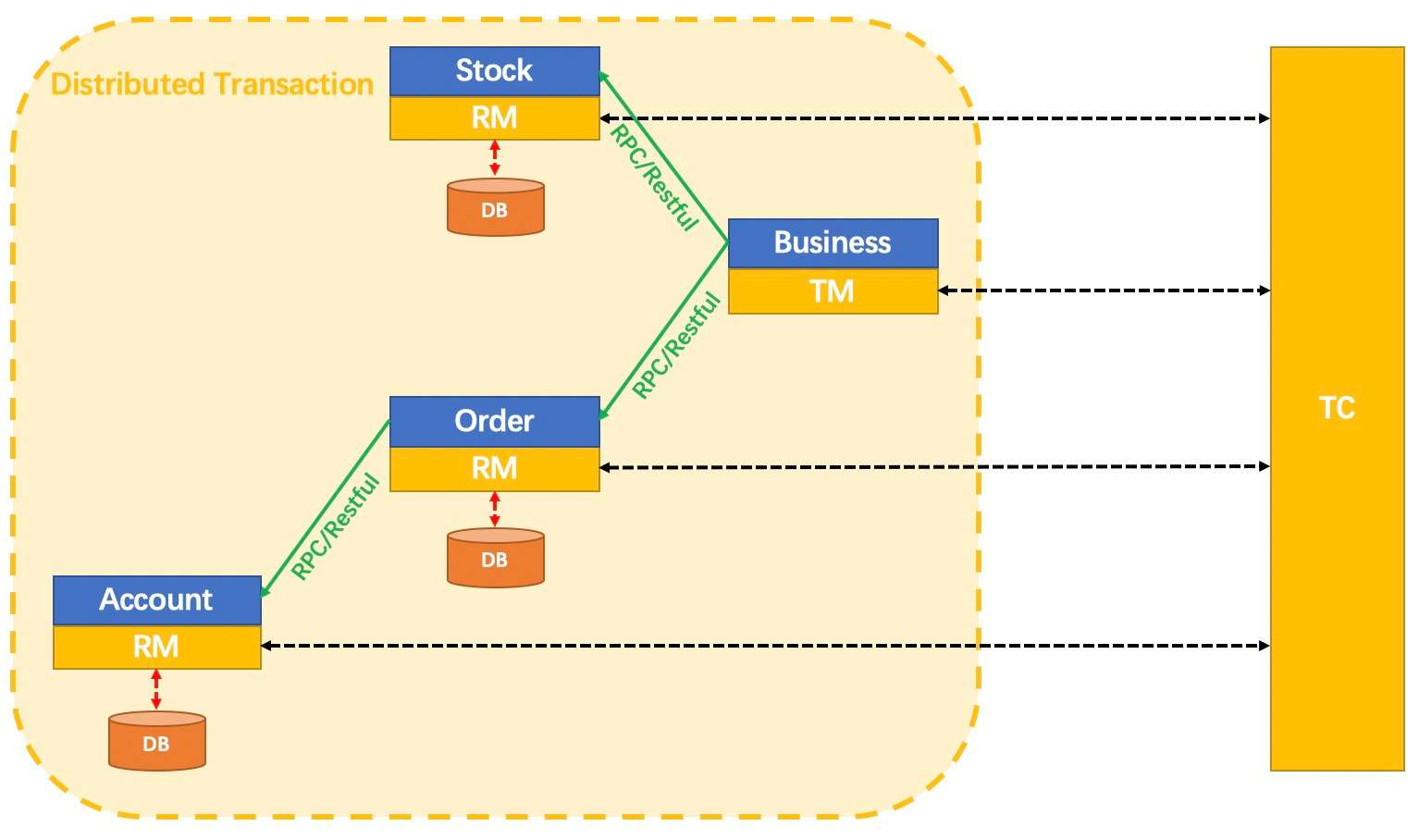
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚
b)数据库和业务层
seata_order.sql
DROP TABLE IF EXISTS `order_tbl`;
CREATE TABLE `order_tbl` (
`id` int NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`commodity_code` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`count` int NULL DEFAULT 0,
`money` int NULL DEFAULT 0,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 20 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `order_tbl` VALUES (1, '1', 'product-1', 1, 5);
INSERT INTO `order_tbl` VALUES (9, '1', 'product-1', 1, 5);
INSERT INTO `order_tbl` VALUES (10, '1', 'product-1', 1, 5);
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`id` bigint NOT NULL AUTO_INCREMENT,
`branch_id` bigint NOT NULL,
`xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
seata_stock.sql
DROP TABLE IF EXISTS `stock_tbl`;
CREATE TABLE `stock_tbl` (
`id` int NOT NULL AUTO_INCREMENT,
`commodity_code` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`count` int NULL DEFAULT 0,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `commodity_code`(`commodity_code`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `stock_tbl` VALUES (1, 'product-1', 100000);
INSERT INTO `stock_tbl` VALUES (2, 'product-2', 0);
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`id` bigint NOT NULL AUTO_INCREMENT,
`branch_id` bigint NOT NULL,
`xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
分别创建order-server, stock-server两个服务;
order-server: get请求 , /order/insert , 新增一条订单, 往数据库中新增一条数据, 同时远程调用stock-server中的/stock减库存,;
stock-server: put请求, /stock, 接收传入过来的对象信息, 减去库存;
业务逻辑代码省略
c)seata-server配置
脚本和配置准备:
nacos中创建seata的命名空间
执行脚本
使用git命令行打开,并且执行脚本:
sh nacos-config.sh -h 127.0.0.1 -p 8848 -g seata -t 命名空间的id -u nacos -w nacos
脚本执行完后, 配置的信息都导入到了nacos中:
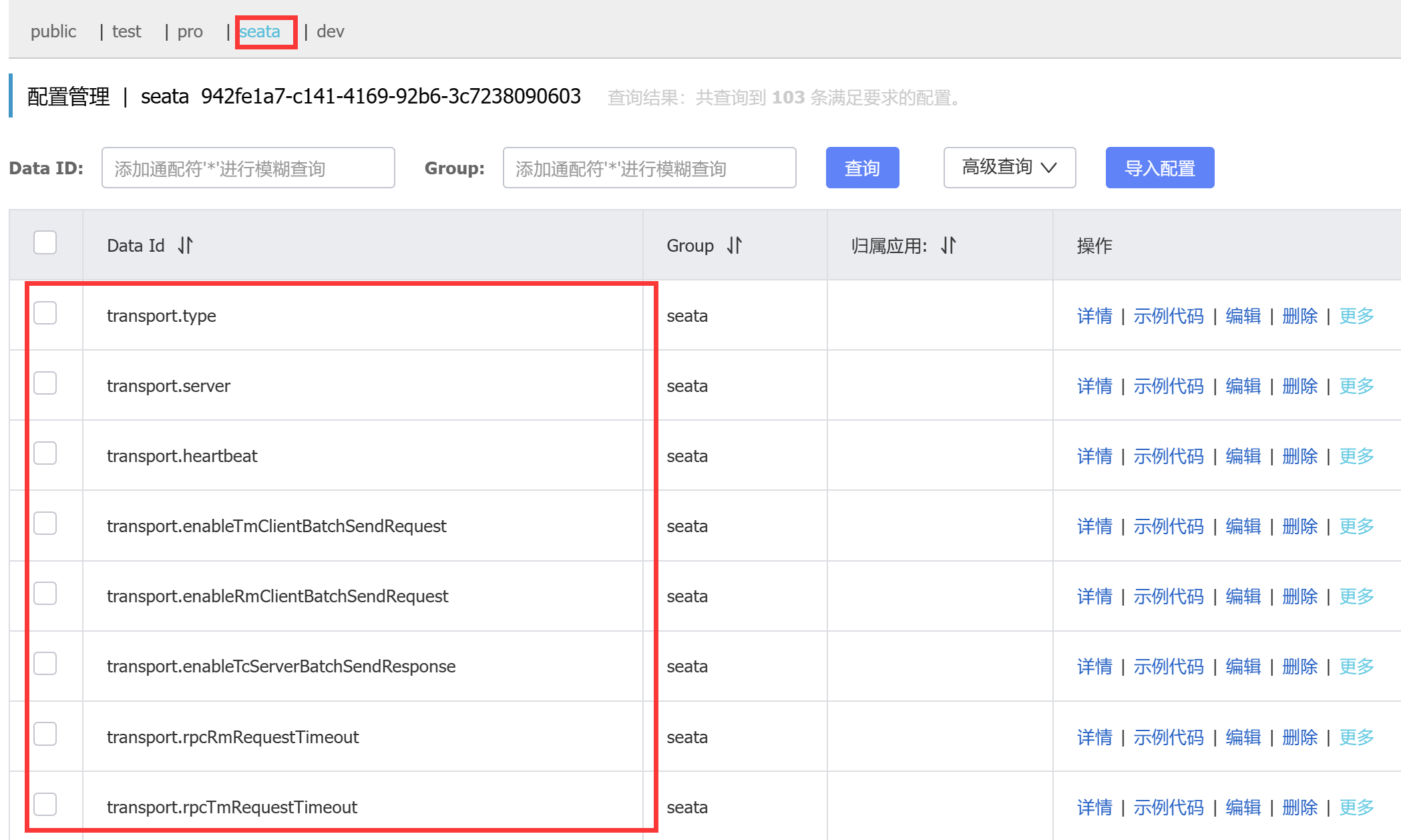
修改seata的配置文件
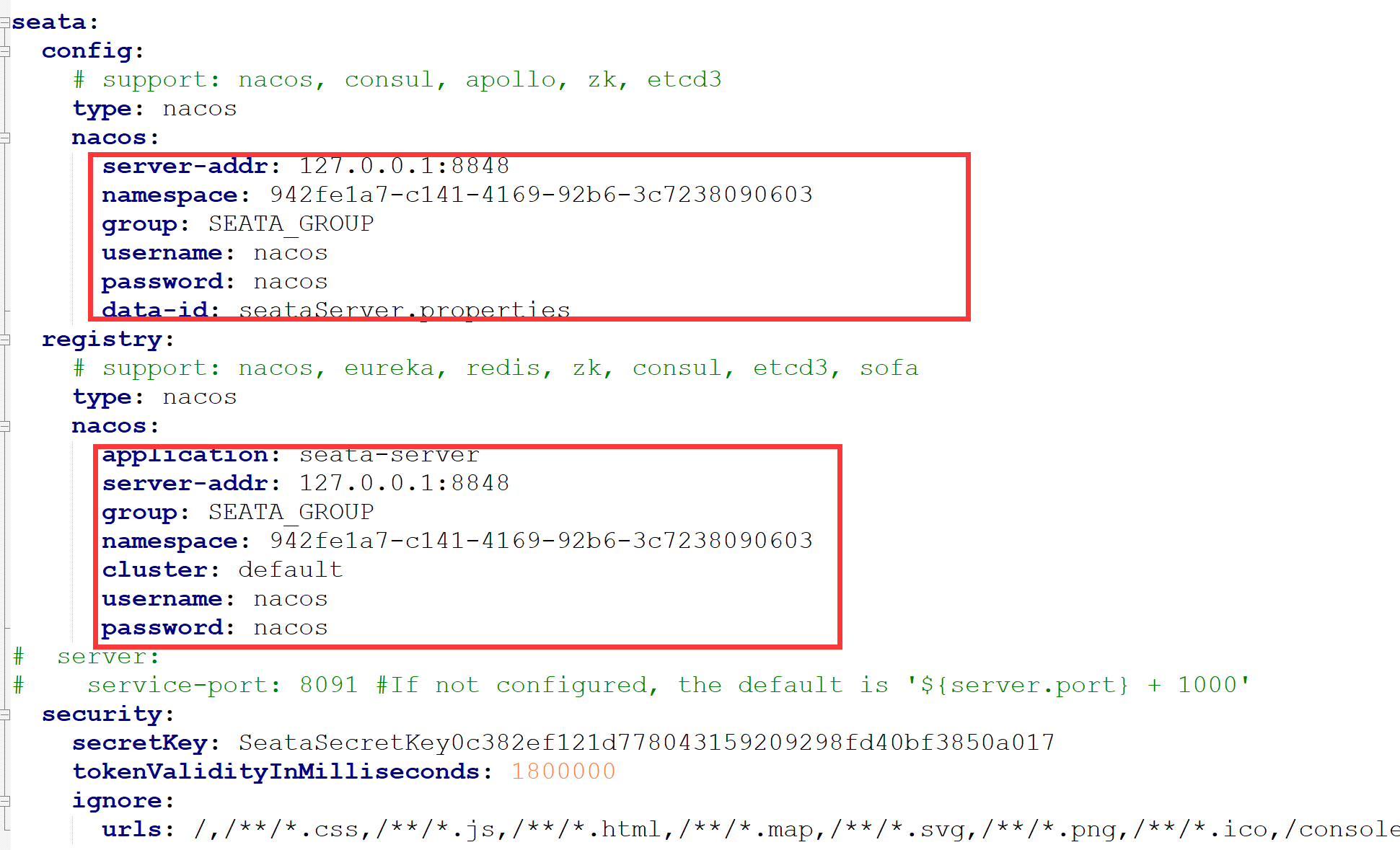
启动seata-server
d)业务服务的配置
导入依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
seata配置(***)
#配置当前事务的组名 必须和nacos中的service.vgroupMapping后面的值一直(下图)
seata.tx-service-group=my_test_tx_group
#配置分组服务的mapping的值, 必须和nacos中service.vgroupMapping.****的值一直
seata.service.vgroup-mapping.my_test_tx_group=default
#设置事务分组对应的seata服务地址 seata.service.grouplist后面的default和上面配置的值要相同
seata.service.grouplist.default=127.0.0.1:8091

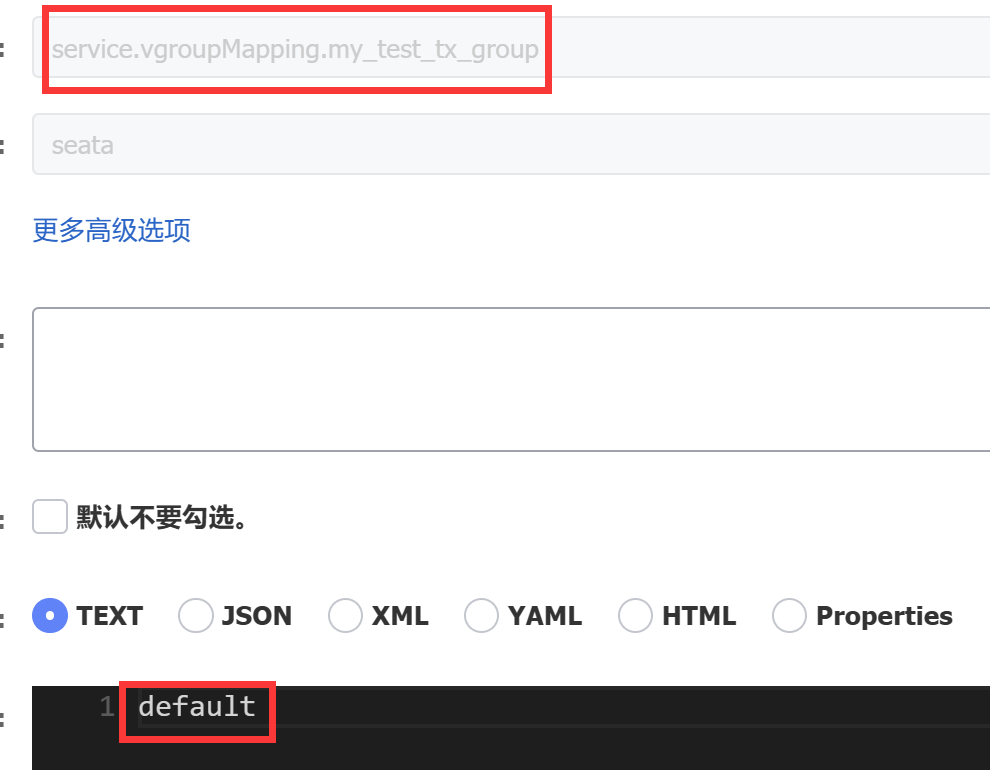
e)测试
在业务方法中手动添加异常, 观察事务的回滚过程;
11 微服务链路追踪
在微服务架构下,系统的功能是由大量的微服务协调组成的,例如:电商创建订单业务就需要订单服务、库存服务、支付服务、短信通知服务逐级调用才能完成。而每个服务可能是由不同的团队进行开发,部署在成百上千台服务器上。
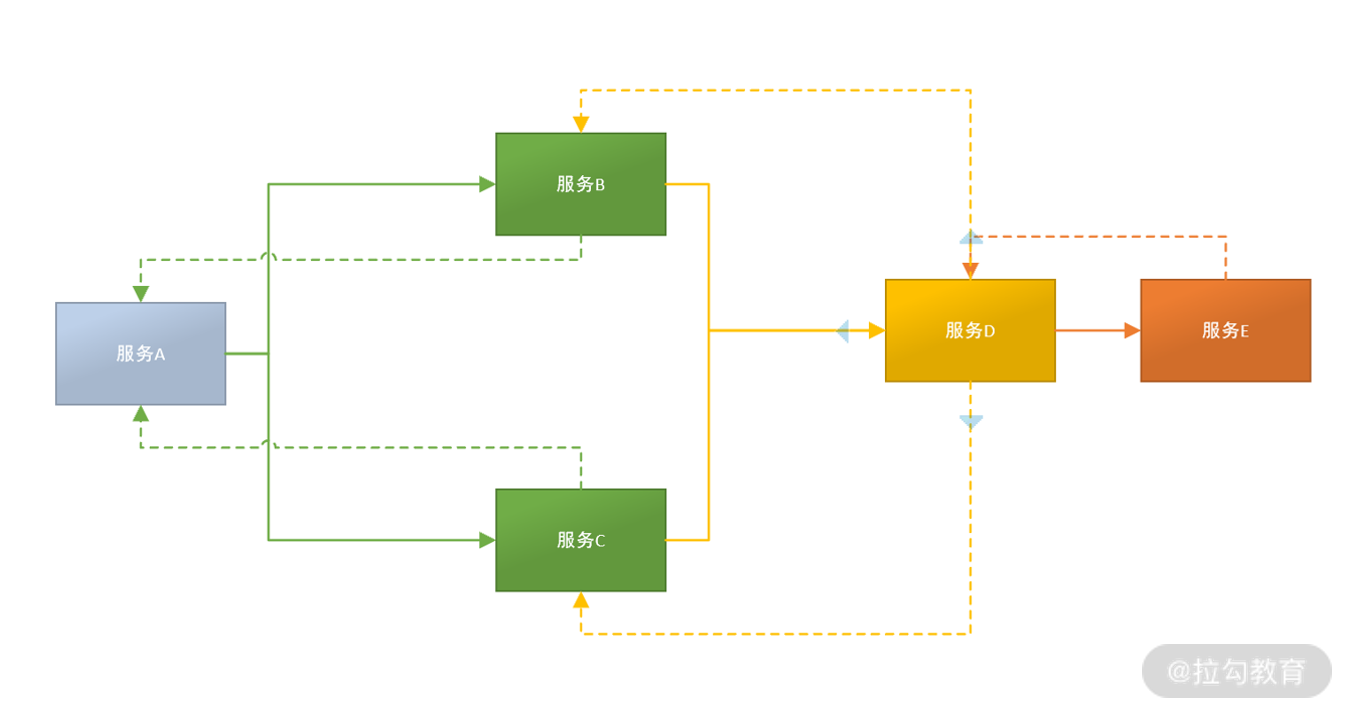
如此复杂的消息传递过程,当系统发生故障的时候,就需要一种机制对故障点进行快速定位,确认是哪个服务出了问题,链路追踪技术由此而生。所谓的链路追踪,就是运行时通过某种方式记录下服务之间的调用过程,在通过可视化的 UI 界面帮研发运维人员快速定位到出错点。引入链路追踪,是微服务架构运维的底层基础,没有它,运维人员就像盲人摸象一样,根本无法了解服务间通信过程。
1)Sleuth+Zipkin
在 Spring Cloud 标准生态下内置了 Sleuth 这个组件,它通过扩展 Logging 日志的方式实现微服务的链路追踪。说起来比较晦涩,咱们看一个实例就明白了,在标准的微服务下日志产生的格式是:
2021-01-12 17:00:33.441 INFO [nio-7000-exec-2] c.netflix.config.ChainedDynamicProperty : Flipping property: b-service.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647
但是当引入 Spring Cloud Sleuth 链路追踪组件后就会变成下面的格式:
2021-01-12 17:00:33.441 INFO [a-service,5f70945e0eefa832,5f70945e0eefa832,true] 18404 --- [nio-7000-exec-2] c.netflix.config.ChainedDynamicProperty : Flipping property: b-service.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647
//比较后会发现,在原有日志中额外附加了下面的文本
[a-service,5f70945e0eefa832,5f70945e0eefa832,true]
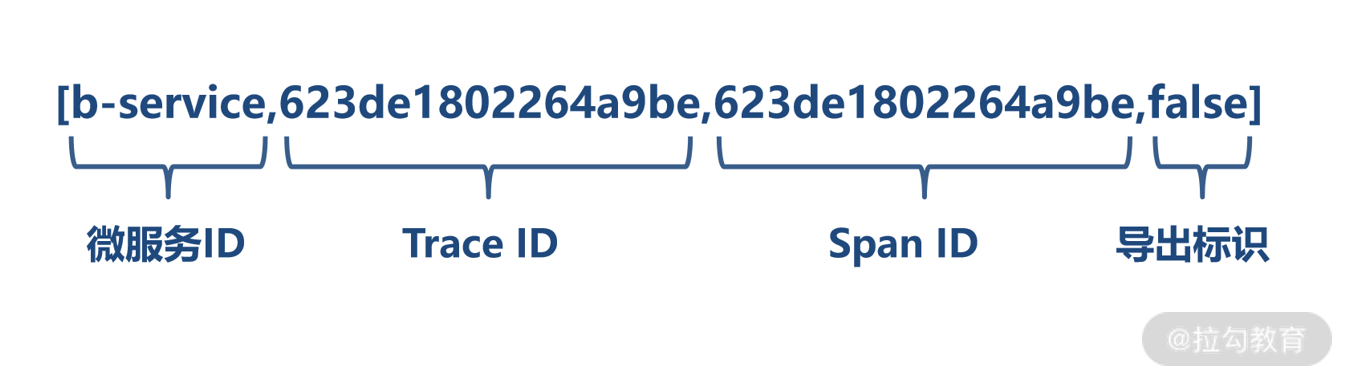
这段文本就是 Sleuth 在微服务日志中附加的链路调用数据,它的格式是固定的,包含以下四部分:
[微服务 Id,TraceId,SpanId,isExport]
链路追踪数据的组成
微服务 Id: 说明日志是由哪个微服务产生的。
TraceId: 轨迹编号。一次完整的业务处理过程被称为轨迹,例如:实现登录功能需要从服务 A 调用服务 B,服务B再调用服务 C,那这一次登录处理的过程就是一个轨迹,从前端应用发来请求到接收到响应,每一次完整的业务功能处理过程都对应唯一的 TraceId。
**SpanId,**步骤编号。刚才要实现登录功能需要从服务 A 到服务 C 涉及 3 个微服务处理,按处理前后顺序,每一个微服务处理时日志都被赋予不同的 SpanId。一个 TraceId 拥有多个 SpanId,而 SpanId 只能隶属于某一个 TraceId。
导出标识,当前这个日志是否被导出,该值为 true 的时候说明当前轨迹数据允许被其他链路追踪可视化服务收集展现。
下面我们看一个完整的追踪数据实例:
模拟了服务 A -> 服务 B -> 服务 C的调用链路,下面是分别产生的日志
#服务 A 应用控制台日志
2021-01-12 22:16:54.394 DEBUG [a-service,e8ca7047a782568b,e8ca7047a782568b,true] 21320 --- [nio-7000-exec-1] org.apache.tomcat.util.http.Parameters : ...
#服务 B 应用控制台日志
2021-01-12 22:16:54.402 DEBUG [b-service,e8ca7047a782568b,b6aa80fb33e71de6,true] 21968 --- [nio-8000-exec-2] org.apache.tomcat.util.http.Parameters : ...
#服务 C 应用控制台日志
2021-01-12 22:16:54.405 DEBUG [c-service,e8ca7047a782568b,537098c59827a242,true] 17184 --- [nio-9000-exec-2] org.apache.tomcat.util.http.Parameters : ...
可以发现,在 DEBUG 级别下链路追踪数据被打印出来,按调用时间先后顺序分别是 A 到 C 依次出现。因为是一次完整业务处理,TraceId 都是相同的,SpanId 却各不相同,这些日志都已经被 Sleuth 导出,可以被 ZipKin 收集展示。
Zipkin 是 推特的一个开源项目,它能收集各个服务实例上的链路追踪数据并可视化展现。刚才 ABC 服务控制台产生的日志在 ZipKin 的 UI 界面中会以链路追踪图表的形式展现。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
spring:
sleuth:
sampler:
probability: 1.0
rate: 100
zipkin:
base-url: http://localhost:9411

![[Unity] ShaderGraph实现不同贴图素材的同一材质球复用](https://i-blog.csdnimg.cn/direct/6b32e18f3d8f463084aef4dd4002440b.png)




![某数据泄露防护(DLP)系统NoticeAjax接口SQL注入漏洞复现 [附POC]](https://i-blog.csdnimg.cn/direct/b62a9b9d16c74d1f8be1620e3acf3b32.png)












