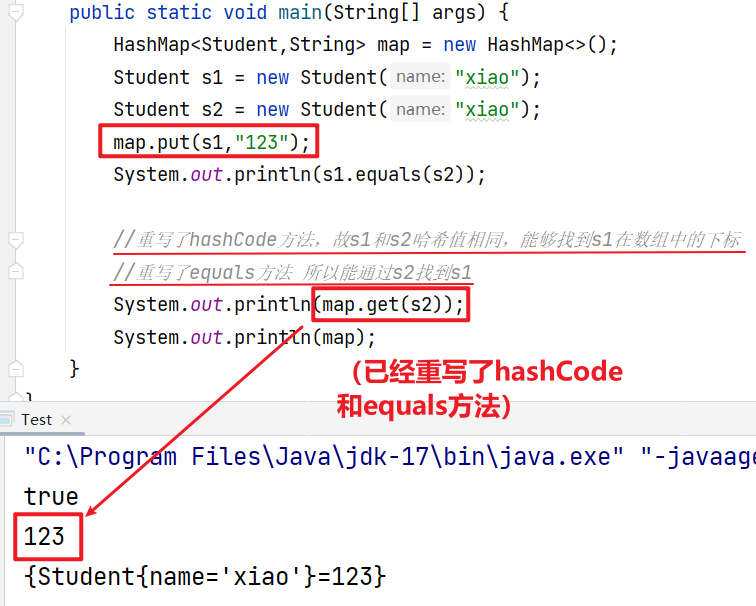
selenium 是一个自动化测试工具,利用它可以驱动浏览器完成特定的操作,例如点击,下拉等,还可以获取浏览器当前呈现的页面的源代码,做到所见即所爬,对于一些 JavaScript 动态渲染的界面来说,这种爬取方法非常有效
准备工作:
1. Chrome 浏览器
2. 在Chrome 浏览器上配置好 ChromeDriver
3. 需要安装好 python 的 Selenium 库
基本用法
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
input = browser.find_element(by=By.ID, value='kw')
input.send_keys('python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()
输出结果一部分
m:4px solid #626675;position:absolute;left:50%;top:-8px;margin-left:-4px}.head_wrapper .sam_search .sam_search_rec_hover{right:29px}.head_wrapper .sam_search .sam_search_soutu_hover{display:none;right:-12px}.c-frame{margin-bottom:18px}.c-offset{padding-left:10px}.c-gray{color:#666}.c-gap-top-small{margin-top:5px}.c-gap-top{margin-top:10px}.c-gap-bottom-small{margin-bottom:5px}.c-gap-bottom{margin-bottom:10px}.c-gap-left{margin-left:12px}.c-gap-left-small{margin-left:6px}.c-gap-right{margin-right:12px}
运行代码后,会弹出一个 Chrome 浏览器。浏览器会自动跳到百度页面,然后在搜索框中输入 python ,就会跳转到搜索结果页面,并且输出了浏览器可以看到的真实内容
初始化浏览器对象
Selenium 支持的浏览器非常多, 既有 Chrome , Firefox, Edge, Safari 等电脑端的浏览器, 也有 Aadroid , BlackBerry 等手机端的浏览器
我们可以用如下方式初始化浏览器
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.Safari()
这样就完成浏览器的初始化,并将其赋值给了 browser。
访问页面
我们可以使用 get 方法请求页面,其参数传入要请求网页的 URL 即可
例如访问 淘宝
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://taobao.com')
print(browser.page_source)
browser.close()
查找节点
Selenium 可以驱动浏览器完成各种操作,比如填充表单,模拟点击等。 比如想要往某个输入框中输入文字,总得知道输入框在哪? 对此, Selenium 为我们提供了一系列用来查找节点的方法,我们可以使用这些方法获取想要的节点,以便执行下一步操作或提取信息
单个节点
例如我们想要从淘宝页面提取搜素框这个节点,首先要观察这个页面的源代码 如:

可以发现,淘宝页面的 id 属性值是 q name 的属性值也是 q , 此外还有许多其他属性,我们可以用多种方式获取它们。 例如 find_element, 此外还有根据 XPaht , CSS 选择器等的获取方式
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(by=By.ID, value='q')
input_second = browser.find_element(by=By.CSS_SELECTOR, value='#q')
input_third = browser.find_element(by=By.XPATH, value='//*[@id="q"]')
print(input_first)
print(input_second)
print(input_third)
browser.close()
<selenium.webdriver.remote.webelement.WebElement (session="c5c118afb490f60e84bed2b2f4611e42", element="f.C53AC604CB64324F54B40B7E43A6D38B.d.1C93D5A409EEB94B333BC42260C5A292.e.76")>
<selenium.webdriver.remote.webelement.WebElement (session="c5c118afb490f60e84bed2b2f4611e42", element="f.C53AC604CB64324F54B40B7E43A6D38B.d.1C93D5A409EEB94B333BC42260C5A292.e.76")>
<selenium.webdriver.remote.webelement.WebElement (session="c5c118afb490f60e84bed2b2f4611e42", element="f.C53AC604CB64324F54B40B7E43A6D38B.d.1C93D5A409EEB94B333BC42260C5A292.e.76")>
可以看到三种返回的结果完全一致
find_element 接收两个参数, 分别是 查找方式, 方式的值,
多个节点
如果查找单个节点, find_element 方法完全可以了,如果是多个值则需要用到 find_elements ,如果目标包含多个,再用 find_element 就只能得到第一个节点了
’
from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.get('https://www.taobao.com') lis = browser.find_elements(by=By.CSS_SELECTOR,value='.service-bd li') print(lis) browser.close()
结果的一部分
[<selenium.webdriver.remote.webelement.WebElement (session="804653dd16ca3dbb0201b350a6329d0d", element="f.429C48601A80CCAAF703BB10CB090BC9.d.6DF9DEBC64815721F7B71806DF4182E6.e.2749")>, <selenium.webdriver.remote.webelement.WebElement (session="804653dd16ca3dbb0201b350a6329d0d", element="f.429C48601A80CCAAF703BB10CB090BC9.d.6DF9DEBC64815721F7B71806DF4182E6.e.2933")>, element="f.429C48601A80CCAAF703BB10CB090BC9.d.6DF9DEBC64815721F7B71806DF4182E6.e.4787")>]
这里简化了输出的结果,可以看到内容变成了列表类型, 列表中的每个节点都属于 WebElement 类型。
节点交互
Selenium 可以驱动浏览器执行一些操作。比较常见的有: 用 send_keys 方法输入文字, 用 clear 方法清空文字, 用 click 方法点击按钮
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element(by=By.ID, value='q')
input.send_keys('iPhone')
time.sleep(1)
input.clear()
input.send_keys('iPad')
button = browser.find_element(by=By.CLASS_NAME, value='btn-search')
button.click()
browser.close()
动作链
在上面的实例中,交互操作都是针对某个节点执行的。例如输入框, 调用它的输入文字方法 send_keys 和清空文字方法 clear, 对于搜索按钮,调用了它的点击方法 click , 其实还有一些操作,它们没有特定的执行对象,比如鼠标拖拽, 键盘按键等,这些操作需要另一中方式执行,那就是操作链
例如拖拽
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
soure = browser.find_element(by=By.CSS_SELECTOR, value='#draggable')
target = browser.find_element(by=By.CSS_SELECTOR, value='#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(soure, target)
actions.perform()
这里首先打开网页中的一个拖拽实例, 然后以此选中要拖拽的节点和拖拽至的目标点,接着声明一个 ActionChains 对象并赋值给 actions 的变量, 再后调用 actions 变量的 drag_and_drop 方法声明拖拽对象和拖拽目标, 最后调用 perform 方法执行动作, 就完成了拖拽操作
更多动作链参考: http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
运行 JavaScript
还有一些操作, Selenium 没有提供 API ,例如下拉进度条,面对这种情况可以模拟运行 JavaScript 此时使用 execute_script 方法即可实现
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
获取属性信息
前面我们已经通过 page_source 属性获取了网页源代码, 下面就可以说使用解析库如正则, Beautiful Soup 等来直接提取节点信息了,
不过既然 Selenium 已经提供了选择节点的方法, 返回的结果是 WebElement 类型,那么它肯定也有相关的方法和属性来直接提取节点信息,例如属性,文本值等
获取属性
可以用 get_attribute 方法获取节点的属性,但前提是的先选中这个节点
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
url = 'https://spa2.scrape.center/'
browser.get(url)
logo = browser.find_element(by=By.CLASS_NAME, value='logo-image')
print(logo)
print(logo.get_attribute('src'))
<selenium.webdriver.remote.webelement.WebElement (session="9efa96a5c4b7c383a14bcc90510e469d", element="f.A62ECDF1059CBBEEB80C6FE1F3D9718E.d.1BFFD3C28B378C45F85177DC773F9A08.e.11")>
https://spa2.scrape.center/img/logo.a508a8f0.png
向 get_attribute 方法的参数传入想要获取的属性名,就可以得到该属性的值了
获取文本值
每个 webElement 节点都有 text 属性, 直接调用这个属性就可以得到节点内部的文本信息
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://spa2.scrape.center/')
input = browser.find_element(by=By.CLASS_NAME, value='logo-title')
print(input.text)
Scrape
获取ID ,位置, 标签名和大小
id 属性获取节点 ID , location 属性获取节点在页面中的相对位置,tag_name 属性用于获取标签名称, size 属性获取节点的大小,也就是宽高
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://spa2.scrape.center/')
input = browser.find_element(by=By.CLASS_NAME, value='logo-title')
print(input.id)
print(input.location)
print(input.tag_name)
print(input.size)
f.316EC4AAC7943F0D609F3E843A7C31C7.d.43965F4D937A16BDC6D13509A61B3948.e.13
{'x': 211, 'y': 13}
span
{'height': 40, 'width': 77}
切换Frame
我们知道网页中有一种节点叫做 iframe , 也就是子 Frame, 相当于页面的子页面,它的结构和外部网页的结构完全一致, Selenium 打开一个页面后,默认实在父 Frame 里操作, 此时这个页面如果还有子 Frame , 它是不能获取子 Frame 里的节点的, 这时就需要用到 switch_to.frame 方法切换 Frame
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element(by=By.CLASS_NAME, value='logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element(by=By.CLASS_NAME, value='logo')
print(logo)
print(logo.text)
NO LOGO
<selenium.webdriver.remote.webelement.WebElement (session="7aa6a87f145168d7f4421d65f1362c6d", element="f.8F10A1ECDF6EAF6BE779BC6F0E41584C.d.51D4DDAA62F2FB4E3CD2E3B57E996B4F.e.12")>
首先通过 switch_to.frame 方法切换到子 Frame 里,然后尝试获取其中的 logo 节点(子Frame 里并没有 logo 节点),如果找不到, 就会抛出NoSuchElementException 异常,异常被捕捉后, 会输出 NO LOGO ,接着切回父 Frame ,重新获取 logo节点, 发现此时可以获取成功了
所以当页面中包含子 Frame 时,如果想获取子 Frame 中的节点,需要首先调用 switch_to.frame 方法,切换到对应的 Frame 中,再进行操作
这里的 logo.text 并没有内容,教程里是有内容的
延时等待
在 Selenium 中, get 方法在网页框架加载结束后才会结束执行,如果我们尝试在 get 反复执行完毕时获取网页源代码,其结果可能并不是浏览器完全加载完成的页面,因为某些页面有额外的 Ajax 请求,页面还会经由 JavaScript 渲染。 所以在必要的时候,我们需要设置浏览器延时等待一定的时间,确保节点已经加载出来
隐式等待
使用隐式等待进行测试时, 如果 Selenium 没有在 DOM 上找到节点, 将继续等待,在超出设定时间后,抛出找不到节点的异常。换句话说,在查找节点而节点没有立即出现时,隐式等待会先等一会再查找MOD , 默认的等待时间是 9
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get('https://spa2.scrape.center/')
input = browser.find_element(by=By.CLASS_NAME, value='logo-image')
print(input)
显示等待
隐式等待并不好,因为我们只规定了一个固定时间, 而页面的加载时间会受网络条件的影响。
还有一种更合适的等待方式----显示等待, 这种方式会指定要查找的节点和最长等待时间, 如果在规定时间加载出了要查找的节点,就返回这个节点,如果到了规定时间依然没有加载出节点,就抛出超时异常
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input)
print(button)
<selenium.webdriver.remote.webelement.WebElement (session="865015d53af99060b436be643a8cd6d3", element="f.C06F497BF8676D64692A5EAC4C119D26.d.7FC8C51621189FF01A23489903B4288A.e.76")>
<selenium.webdriver.remote.webelement.WebElement (session="865015d53af99060b436be643a8cd6d3", element="f.C06F497BF8676D64692A5EAC4C119D26.d.7FC8C51621189FF01A23489903B4288A.e.68")>
这里首先引入 WebDriverWait 对象, 指定最长等待时间为 10 , 并赋值个 wait 变量,然后调用 wait 的 until 方法,传入等待条件
这里传入了 presence_of_element_located 这个条件代表节点出现,其参数是节点的定位元组 (By.ID, 'q') , 表示节点 ID 为 q 的节点 (即搜索框)。这样做达到的效果是如果节点 ID 为 q 的节点在 10秒内成功加载出来了,就返会改节点,如果超过10秒还没有加载出来,就抛出异常
然后传入等待的条件是 element_to_be_clickable, 代表按钮可点击,所以查找按钮是要查找 CSS 选择器为 .btn-search 的按钮,如果 10 秒内它是可点击的,也就是按钮节点成功加载出来了,就返回该节点,如果超过 10 还是不可点击,也就是节点按钮没有加载出来,就爬出异常
如果没有加载出来
selenium.common.exceptions.TimeoutException: Message:
等待条件有很多,具体参考:
http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
前进和后退
平常使用浏览器时,都有前进和后退的功能, Selenium 也可以完成这个操作, 它使用 forward 方法实现前进, 使用 back 方法实现后退
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
time.sleep(2)
browser.get('https://www.taobao.com')
time.sleep(2)
browser.get('https://www.python.org')
time.sleep(2)
browser.back()
time.sleep(2)
browser.forward()
time.sleep(2)
browser.close()
Cookie
使用 Selenium 还可以方便对 Cookie 进行操作,如获取, 添加,删除等
from selenium import webdriver
browser = webdriver.Edge()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'})
print(browser.get_cookies())
browser.delete_all_cookies()
print('最后一个:', browser.get_cookies())
I:\ANACONDA\python.exe I:\githubCode\mycode\JavaScript动态渲染\Cookie_.py
[{'domain': '.zhihu.com', 'expiry': 1756542886, 'httpOnly': False, 'name': 'd_c0', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': 'ASCSgRSf-xiPTtTRFO8DRJeM7Ee1uaEY6Pw=|1721982887'}, {'domain': '.zhihu.com', 'httpOnly': '6c4a08c3-8e65-4e80-be84-742c02f9b491'}]
[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'HMACCOUNT', 'path': '/', 'sameSite': 'Lax',value': 'germey ': 'Lax', 'secure': False, 'value': '6c4a08c3-8e65-4e80-be84-742c02f9b491'}]
最后一个: []
输出的内容太多,删掉了一部分
这里我们先访问了知乎,知乎页面加载完成后,浏览器其实已经生成 Cookie 了,然后,调用浏览器对象的 get_cookies 方法获取所有的 Cookie , 接着,添加一个 Cookie , 这里传入了一个字典,包含 name , domain 和 value 等键值, 之后,再次获取所有 cookie 会发现结果中多了一项,就是我们新加的 cookie ,最后调用 delete_all_cookies 方法删除所有的 Cookie 并再次获取,会发现此时结果为空
选项卡管理
访问网页时,会开启一个个选项卡,在 Selenium 中, 我们可以对选项卡做操作
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://www.python.org')
['7CC91CF864EF7BCCB720CFA05C53C539', 'BD5AF3B6A876C676AC3FDEA01C7AD7AE']
这里首先访问百度,然后调用 execue_script 方法, 向其参数传入 window.open() 这个 javaScript 语句,表示开启一个新选项卡, 返回值是选项卡的代号列表。要想切换选项卡,只需要调用 switch_to.window 方法即可, 其中参数是目的选项卡的代号,这里我们将新开选项卡的代号传入,就切换到了第 2 个选项卡,然后在这个选项卡下打开一个新页面,再重新调用 switch_to.window 方法切回第 1 个选项卡。
异常处理
使用 Selenium 时难免会遇到一些异常, 例如超时,节点未找到等,一旦出现此类异常,程序便不会再运行了,此时我们可以使用 try except 语句捕获异常
节点未找到异常
from selenium import webdriver
from selenium.webdriver.common.by import By
# 节点未找到异常
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.find_element(by=By.ID, value='hello')
selenium.common.exceptions.NoSuchElementException: Message: no such element
捕获异常
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException, NoSuchElementException
# 异常捕获
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element(by=By.ID, value='hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()
No Element
关于更多异常类参考官方文档:
http://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions
反屏蔽
现在很多网站增加了对 selenium 的检测, 防止一些爬虫恶意爬取,如果检测到有人使用 Selenium 打开浏览器,就直接屏蔽
在大多数情况下,检测的基本原理是检测当前浏览器窗口下的window.navigator 对象是否包含 webdriver 属性, 因为在正常使用浏览器的时候,这个属性是 undefind, 一旦使用了 Selenium ,一旦使用了 Selenium ,它就会给 window.navigator 设置 webdriver 属性。 很多网站通过 JavaScript 语句判断是否存在 webdriver 属性,如果存在就直接屏蔽
一个典型的案例网站 https://antispider1.scrape.center/ 就是使用上述原理, 检测是否存在 webdriver 属性, 如果我们直接使用 Selenium 直接爬取该网站的数据, 就不能得到任何数据
这时会有人说直接使用 JavaScript 语句把 webdriver 属性置空不就行了,例如调用 execute_script 方法执行这行代码
Object.defineProperty(navigator, "webdriver", {get: () => undefined})
这行代码确实可以把 webdriver 属性置空, 但 execute_script 方法是在页面加载完成之后才调用这行 JavaScript 语句,太晚了, 网站早在页面渲染执勤啊就已经检测 webdriver 属性了,所以上述方法并不能达到预期的效果
在 Selenium 中, 可以调用 CDP (即 Chrome Devtools Protocol, Chrome 开发工具协议)解决这个问题,利用它可以实现在每个页面刚加载的时候就执行 JavaScript 语句, 将 webdriber 属性置空。这里执行的 CDP 方法叫做 Page.addScriptToEvaluateOnNewDocument, 将上面的 JavaScript 语句传入其中即可,另外还可以加入几个选项来 隐藏 WebDriver 提示条和自动化信息
正常访问
from selenium import webdriver
import time
# 正常访问
browser = webdriver.Chrome()
browser.get('https://antispider1.scrape.center/')
time.sleep(5)
print(1111)

隐藏 webdriver
from selenium import webdriver
from selenium.webdriver import ChromeOptions
import time
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',
{'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'})
browser.get('https://antispider1.scrape.center/')
time.sleep(3)

在大多数情况下,以上方法可以实现 Selenium 的反屏蔽。 但也存在一些特殊的网站会对 WebDriver 属性设置更多的检测, 这种情况,就需要进行具体排查
无头模式
在上面的案例中,每次爬取都会有窗口弹来弹去,虽然有助于观察爬取状况, 但是也会造成一些干扰
Chrome 浏览器从 60 版本开始,就已经开启了对无头模式的支持, 即 Headless 。 无头模式下,在网站运行的时候不会弹出窗口, 从而减少了干扰, 同时还减少了一些资源(如图片)的加载,所以无头模式在一定程度上节省了资源加载的时间和网络带宽
from selenium import webdriver
from selenium.webdriver import ChromeOptions
options = ChromeOptions()
options.add_argument('--headless')
browser = webdriver.Chrome()
browser.set_window_size(1366, 768)
browser.get('https://www.baidu.com')
browser.get_screenshot_as_file('preview.png')

这里利用 ChromeOptions 对象的 add_argument 方法添加了一个参数 --headless , 从而开启了无头模式,在无头模式下, 最好设置一下窗口大小, 因此这里调用了 set_window_size 方法, 之后打开页面, 并调用 get_screenshot_as_file 方法输出了页面截图