Review Policy Gradient

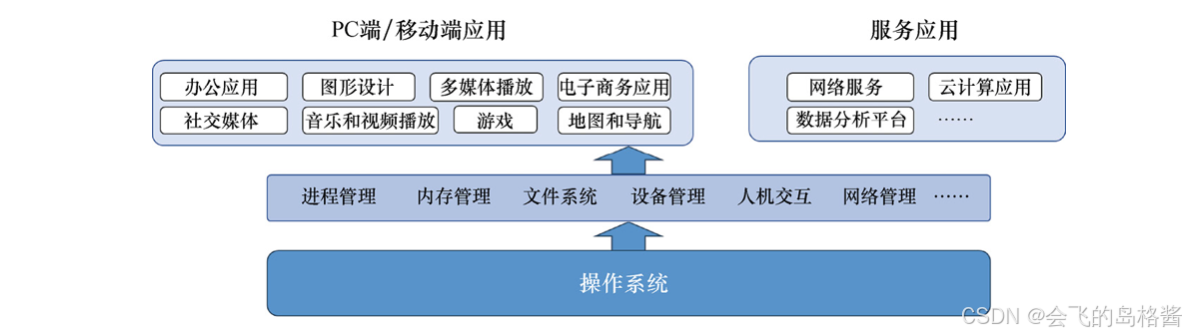
上面的公式是Policy Gradient的更新函数,这个式子是指在 s t s_t st时刻采取了 a t a_t at,计算出对应发生的概率 p θ p_\theta pθ,然后计算在采取了这个 a t a_t at之后,所得到的reward有多大。但这里需要减去一个baseline,不能让reward都大于0,这样会降低没有sample到的action的概率。同时还需要加上衰减因子,保证后期得到的reward不会过大,从而影响了一开始的action概率。最后把所有时刻的reward求和。
我们将画蓝色横线的式子记作 G t n G_t^n Gtn,它虽然没有偏差,但因为方差大,数值波动比较大。波动大的原因也很好理解, G t n G_t^n Gtn从执行了这个action之后到episode结束得到的所有reward总和,由于sample的概率不相同,所以中间会遇到各种不同的state。
如果我们收集数据的数量足够多,这个波动会被平均掉。但实际收集数据是比较耗时,所以也不会有太多数据。如果说能用期望值(平均)替代 G t n G_t^n Gtn,那可以让训练过程更稳定。这里就需要引入Value-Based的方法。
Review Q-Learning

Value-Based的方法有两种:
- V π ( s ) V^{\pi}(s) Vπ(s)输入state,输出可能会得到reward的期望值
- Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a)输入state和会采取的action,输出可能会得到reward的期望值
以上两个方法都可以用TD或MC的方法更新,用TD比较稳定,用MC更精确。
Actor Critic

刚刚说到,如果能用期望值(平均)替代
G
t
n
G_t^n
Gtn,训练会更加稳定。那
G
t
n
G_t^n
Gtn的期望值是什么?它是希望在
s
t
s_t
st时刻,用
π
\pi
π这个策略得到
a
t
a_t
at,执行了
a
t
a_t
at之后所得到的reward总和的期望值,那这个其实就是
Q
π
θ
(
s
t
n
,
a
t
n
)
Q^{\pi_\theta}(s^n_t,a^n_t)
Qπθ(stn,atn)的定义。所以有:
E
[
G
t
n
]
=
Q
π
θ
(
s
t
n
,
a
t
n
)
E[G_t^n] = Q^{\pi_\theta}(s^n_t,a^n_t)
E[Gtn]=Qπθ(stn,atn)
那么我们用
Q
π
θ
(
s
t
n
,
a
t
n
)
Q^{\pi_\theta}(s^n_t,a^n_t)
Qπθ(stn,atn)替代
G
t
n
G_t^n
Gtn这一项即可。还有一项baseline,正常是自己设置,但这里我们可以用Value Function替代,
V
(
s
)
V(s)
V(s)是不包含action的,
Q
(
s
,
a
)
Q(s,a)
Q(s,a)是包含action的,
V
(
s
)
V(s)
V(s)是
Q
(
s
,
a
)
Q(s,a)
Q(s,a)的期望值,为什么这么说呢?原因是这样的:
- 在 s t s_t st下,价值函数 V π ( s ) V^\pi(s) Vπ(s)表示从状态 s t s_t st开始,遵循策略 π \pi π的期望回报。
- 由于策略 π \pi π定义了在 s t s_t st下采取各个action的概率分布,因此,价值函数 V π ( s ) V^\pi(s) Vπ(s)可以看作是动作价值函数 Q ( s , a ) Q(s,a) Q(s,a)在所有可能动作上的加权平均,即期望值。
所以上图红框内的式子就可以被Value-Based的两个方法给替换掉,这样就可以将Actor和Critic的两个方法给结合起来。
Advantage Actor Critic

这样结合的缺点就是需要训练两个网络,有办法可以只训练一个网络用来预测两个值吗?可以,事实上可以只训练 V ( s ) V(s) V(s),用 V ( s ) V(s) V(s)替代 Q ( s , a ) Q(s,a) Q(s,a)。回到 Q ( s , a ) Q(s,a) Q(s,a)的定义,因为 r t r_t rt本身是一个随机值,只有我们取了期望值之后才是 Q ( s , a ) Q(s,a) Q(s,a)的定义。现在为了简化Actor-Critic的训练,直接将求期望值去掉。这样就可以用 V ( s ) V(s) V(s)替代 Q ( s , a ) Q(s,a) Q(s,a)。
但这样做的坏处也显而易见,是引入了一个随机的变量。但不过相较于 G t n G_t^n Gtn来说还好, r t r_t rt只是某一个step会有的随机变量,方差会比 G t n G_t^n Gtn小的多。所以整体上还是能接受的。

红框里面是原来的Advantage项,已经用Value-Based的方法替代了。那么Advantage Actor-Critic完整流程如上图:
- 有一个Policy π \pi π 和环境做互动收集训练数据。(Policy Gradient中是用这些训练数据直接优化Policy)
- 用TD或MC优化 V ( s ) V(s) V(s)
- 套用上面的公式更新Policy π \pi π
- 重复1-3直至收敛
Tips

backbone shared
和很多CV任务一样,前面的特征提取都是可以共享的。然后预测action和预测value分成两个分支,这部分和Dueling DQN很像,只是最后没有合并成一个 Q ( s , a ) Q(s,a) Q(s,a)
large entropy
我们可以设置一些限制,使得action的entropy会大一点,不同的action被采用的概率平均一些,才会有几率探索更多state,得到比较好的结果。
asynchronous
强化学习通常花时间都是在收集训练数据过程中。开多个线程与环境做互动收集数据可以有效缩短训练时间。
Asynchronous Advantage Actor-Critic

Asynchronous Advantage Actor-Critic简称为A3C,具体如何实现?
首先有一个初始的global network
- 复制N个network
- 让它们都和环境做互动,收集数据
- 计算梯度
- 更新模型
这里值得注意的是,所有的actor都是并行去收集,训练,更新的。可能有人问,如果复制出来的参数是 θ 1 \theta^1 θ1,但是要更新的时候已经被别覆盖成 θ 2 \theta^2 θ2了呢?这个没关系,直接覆盖就行。
Pathwise Derivative Policy Gradient

之前说到Q-Learning在连续的问题上表现不好。我们完全可以利用Actor预测action的能力,为 Q π Q^\pi Qπ提供action,使得 Q π Q^\pi Qπ的值越大越好。在训练的时候会直接将两个网络连起来,并且freeze Q π Q^\pi Qπ的参数,只训练Actor,这个思路和CV任务里的GAN很像,用生成器生成一个图片,用判别器去判断是好是坏。

算法的流程也很简单,有一个 π \pi π去和环境交互,收集数据,训练 Q π Q^\pi Qπ,然后将 Q π Q^\pi Qπ固定,只训练actor使得 Q π Q^\pi Qπ输出的值越大越好。在Q-Learning中能用到的trick,这里也能用上,比如replay buffer等。

相较于之前的Q-Learning算法,改动四个地方就行:
- 之前使用 Q π Q^\pi Qπ决定用什么action,现在改用 π \pi π来预测action
- 用 π ^ \hat{\pi} π^预测的action代入到 Q π Q^\pi Qπ中,不再解 a r g max a Q π ( s , a ) arg \max\limits_{a} \ Q^\pi(s,a) argamax Qπ(s,a)(会有两个 π \pi π,其中一个是固定的,和训练DQN是一样的)
- 训练 π \pi π(其优化目标是让 Q π Q^\pi Qπ越大越好)
- 更新 π \pi π的参数