本系列文章介绍
在和社区小伙伴们交流的过程中,我们发现大家最关心的问题从来不是某个具体的功能如何使用,而是面对一个具体的实战场景时,如何选择合适的向量数据库解决方案或最优的功能组合。在 “Milvus 向量数据库进阶” 这个系列文章中,我们会聚焦回答这一类问题,如 “在 AI 应用开发的不同阶段,向量数据库应该如何选型”,“如何正确的构建 RAG 多租系统” 等。虽然这个系列名为进阶,但内容同时适用于初级和进阶用户。我们希望通过这些内容的介绍,帮助大家在向量数据库应用的过程中少走弯路。

Milvus 是目前发展最成熟的开源向量数据库项目。和 Qdrant、Weaviate、Chroma 这些近两年的新项目不同,Milvus 为开发者提供了多种部署形态。当然,更多的选择有时候也会带来一些困扰,经常会有同学问怎么选合适的部署形态,今天这篇文章就来和大家详细聊聊这个话题。
现在官方一共提供了三种 Milvus 部署形态:Milvus Lite,Milvus Standalone,Milvus Distributed:
Milvus Lite 可以认为是一个 library 级别的超小型 Milvus。主要面向 python/notebook 环境的快速原型构建、或一些本地的小规模实验。
Milvus Lite 原生集成在 pymilvus 包里,直接 pip install pymilvus,你就在本地完成了 Milvus Lite 的安装。用的时候不需要额外启动服务端,插入数据的持久化都是走的本地文件。
Milvus Standalone 是 Client-Server 模式,是 Milvus 的单机部署形态。Milvus Lite 和 Milvus Standalone 的关系,类似 SQLite 和 MySQL 的关系。Milvus Standalone 的所有组件都打在一个 Docker 镜像里,服务端部署也比较方便。
如果你不是在支持一个大型项目,一般搞一台内存大点儿的机器,部署一套 Milvus Standalone 就够用了。值得提的一点是,Milvus Standalone 支持主备模式高可用,生产环境是可以上的。
Milvus Distributed 是 Milvus 的分布式部署模式。企业用户搭大规模向量数据库系统(或向量数据平台、中台),一般首选这种模式。Milvus Distribute 采用云原生架构,读写分离,关键组件都支持冗余,在三种部署模式中提供最高的扩展性能力和高可用级别,以及组件级的弹性能力(如根据业务负载特征单独扩缩 Proxy、查询节点、索引节点等)。
01.
不同场景下的部署形态选型
一般说选型肯定离不开阶段。用到向量数据库的应用基本有这么几个阶段:
AI 应用的快速原型构建。比如你在做一个 AI 个人助手、一个小的搜索引擎原型、一个端到端的 RAG 原型,这类项目的迭代速度是很关键的,而且原型构建期不需要关心性能或者稳定性这样的指标。因此 Milvus Lite,或 Milvus Lite + Milvus Standalone 会是比较合适的选择。你可以在 notebook 结合 Milvus Lite 快速实现端到端功能搭建,以及面向效果的轻量化实验。
如果你同时也需要在规模大一些的数据集上验证效果,那再起一套 Milvus Standalone 是合适的。注意这里 Milvus Lite 和 Milvus Standalone 并不是独立的两部分,它们支持了一个简单的从笔记本到服务器的工作流:由于 Milvus Lite、Standalone、Distributed 共享一套客户端接口,同样的业务侧代码既可以使用本地数据进行原型开发,也可以链接到服务端进行大规模数据验证。同时 Standalone 支持多用户,一个敏捷开发小组可以使用一套 Milvus Standalone 服务进行协作或共享数据。
早期的生产部署。这里早期指的是项目上线早期,业务访问请求和数据还没有上量、项目还在寻找 Product-market-fit 的阶段。这个阶段你需要关心的仍然是业务效果和业务竞争力,而不是基础设施。因此 Milvus Standalone 是最合适的选择。对于在线业务,需要部署一套主备模式的 Milvus 来保证高可用。对于测试环境,单节点部署即可。
需要注意的是,Milvus Standalone 并不提供表间物理资源隔离。因此如果你有两个业务都很关键且性能敏感,最好把它们的数据通过两套 Milvus Standalone 进行隔离。这可能会带来一些物理资源的浪费,但仍然会比运维 Milvus Distributed 的综合成本低很多。还是那句话,这个阶段你需要聚焦的是业务效果和业务竞争力,而不是基础设施。
当然,这个阶段你仍然可以结合 Milvus Lite 进行一些效果调试工作,特别是面向一些具体用户需求的效果调试。这部分工作不建议在部署 Milvus Standalone 的生产环境进行,这有可能会带来一些潜在的性能和稳定性风险。
大规模生产部署。在这个阶段,你的数据已经超过了单台服务器所能容纳的规模;或数据每天都在快速增长,你需要为后续的业务增长提前做好基础设施的准备。这个时候就需要 Milvus Distributed 登场了。前期会是 Milvus Standalone 和 Milvus Distributed 两套实例并存,我们需要把流量逐步从 Standalone 切换至 Milvus Distributed。并观察至少一个月保证 Milvus Distributed 运行稳定。
这个阶段你也需要逐步完善你的运维系统。Milvus Distributed 原生支持 Prometheus,同时也提供了 Attu 等管理工具。需要注意的是,尽管 Milvus 官方提供了一系列专用运维工具,以及尽可能丰富的生态工具对接,运维一套大型分布式系统并非容事,在这期间你可能会需要比较多的社区帮助。Milvus 社区非常开放,一些主要的社区交流入口我都留在了文末。
02.
不同开源向量数据库的适用数据规模
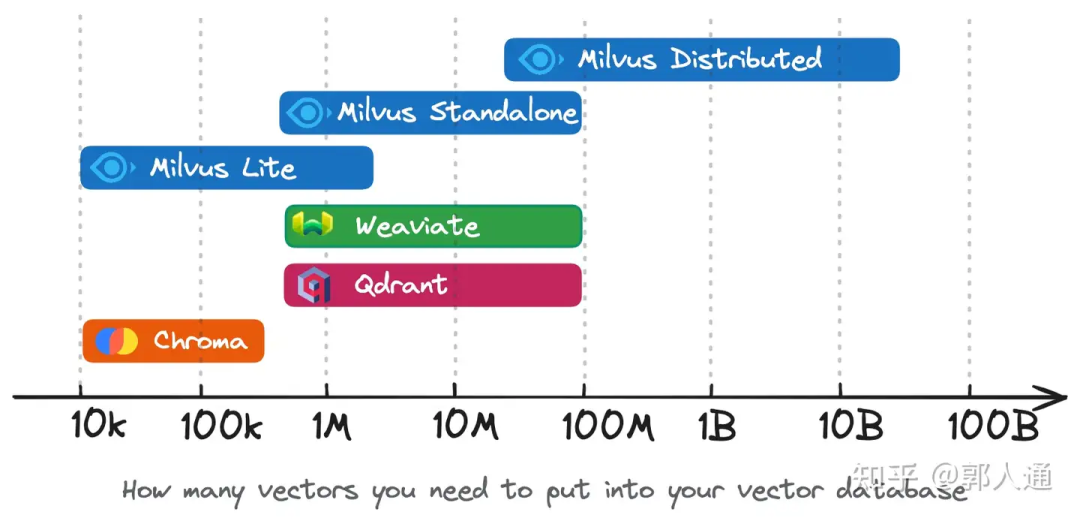
图1. 开源向量数据库适用的数据规模
咱们前面主要说的都是 Milvus,这里把其他几个受欢迎的开源向量数据库也拿过来做一个比较。
去年,Chroma 在 AI 个人开发者圈子里比较火。这个项目的特点是聚焦小数据规模,并提供向量数据库功能的最小功能集。如果你的应用只有不到几十万的向量,而且只需要使用数据插入和查询这样的最基本功能,Chroma 可以提供非常轻便的体验。需要注意的是,即便和 Milvus Lite 相比,Chroma 也仅提供了一个功能子集,且并不面向生产。
Weaviate 和 Qdrant 这两个项目更加的 Production Ready。其中,Weaviate 更聚焦 AI 应用对向量数据库的集成,原生提供了一些上游模型的支持。Qdrant 更聚焦向量数据库本身,关注向量查询能力以及性能。(Qdrant 是所有向量数据库项目中,在性能上跟随 Milvus 最紧的一个项目,详见 VectorDB Benchmark)
图1 对这几个向量数据库的数据规模适用范围进行了比较:
-
Milvus Lite 和 Chroma 都适合不超过百万的数据,这个区间的设计考量主要是系统能力和易用性之间的tradeoff,且更偏向易用性。
-
Milvus Standalone、Weaviate、Qdrant 合适的数据规模是百万至小几千万这个范围。在系统能力和易用性之间的设计考量比较平衡。
-
Milvus Distributed 合适的数据规模在千万及以上。目前社区已经广泛验证了十亿级规模的场景支持,今年也陆续有百亿级规模的场景落地。
和 Milvus 相比,其他几个项目暂未提供长跨度的部署支持。因此在项目演进的不同阶段会有向量数据库选型切换的成本。对于不同数据规模下的混合工作流的支持也没有 Milvus 灵活。
03.
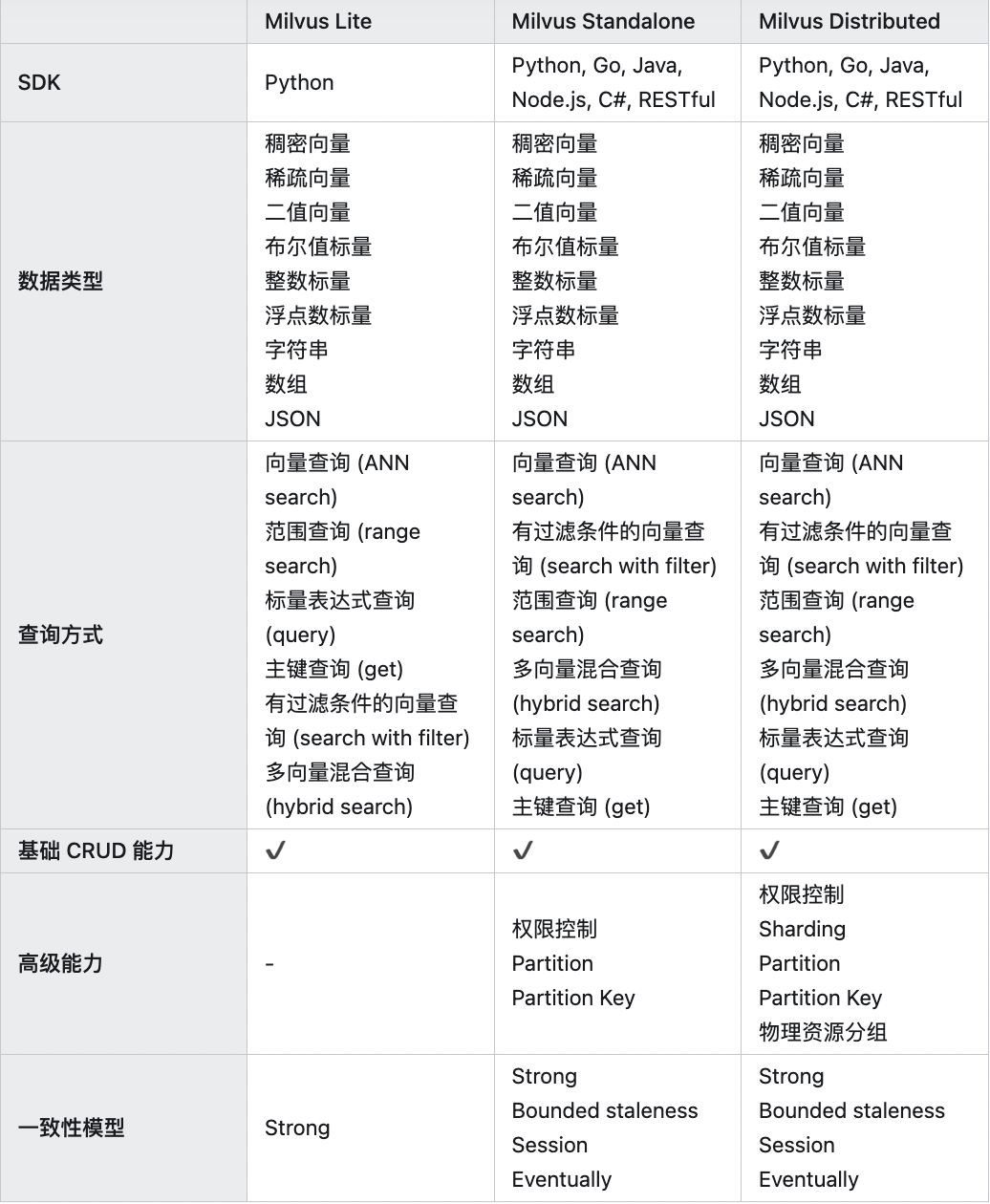
Milvus Lite,Standalone,Distributed的能力对比
04.
Milvus Lite,Standalone,Distributed的组件功能关系
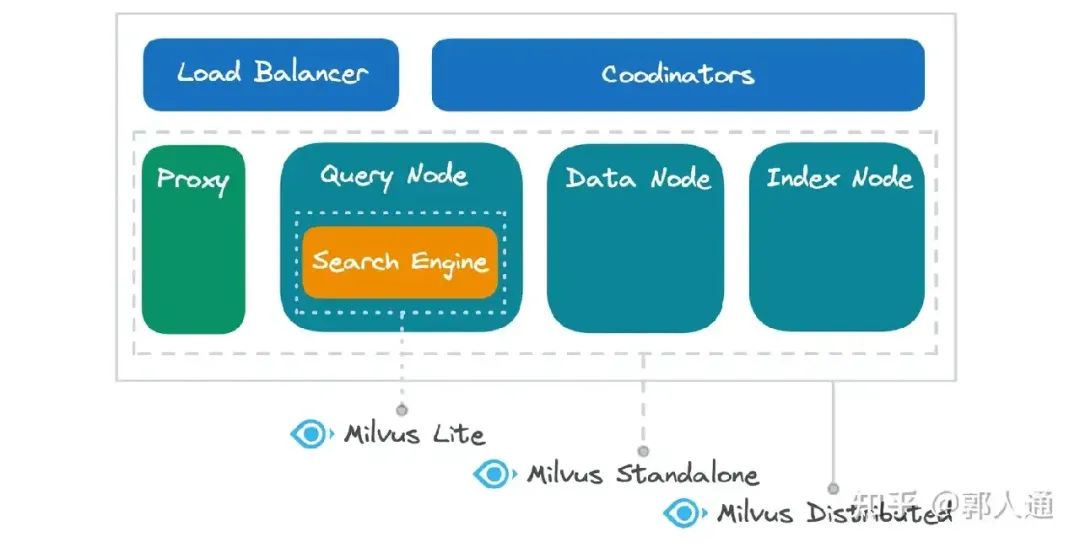
图2. Lite, Standalone, Distributed 包含的功能组件
Milvus Lite,Standalone,Distributed 之所以能提供一致的使用体验, 并保持相同的演进速度,主要得益于这三种部署模式对底层组件的共享。
上图给出了这三种形态各自覆盖的 Milvus 功能组件:
Milvus Lite 主要是对 Search Engine 的封装,同时对数据写入、持久化、索引构建、元信息管理等必备能力提供了本地实现。这也是为什么 Milvus Lite 可以被视为一个 library 的主要原因。但相比 Chroma 这样具有简易实现的 library,Milvus 的 search engine 无论在性能还是查询能力上都要强悍很多,且更适合嵌入。如果你只是在寻找一个 Faiss 或者 HNWSLib 的替代,Milvus Lite 也是相当合适的。Milvus 查询引擎原生集成了这些主流的向量搜索算法库,整合社区也投入了大量工作进行深度的性能和功能优化。
Milvus Standalone 包含了除负载均衡 (load balancer)、多节点管理 (coordinators) 以外的所有功能组件。这些组件运行在同一个 Docker 环境中,因为所有组件间都是本地通信,因此可以获得很好的服务端延迟。
Milvus Distributed 包含所有功能组件。需要注意的是,Standalone 和 Distributed 虽然都包含 Proxy、Query Node、Data Node、Index Node,且功能相同,但 Distributed 提供更加灵活的部署方式。从数量上看,每一种功能组件都可以部署多个,从而支持更高的负载;从物理资源映射的层面看,不同功能的组件可以被部署到相同物理节点以实现资源共享,或部署到不同物理节点以实现组件间资源隔离;从组件间解耦的层面看,每一种组件都可以进行独立的扩缩容,以适应多样化的负载特征,并有效提高资源利用率。
Milvus 向量数据库进阶系列下期预告
现在市面上的 RAG 系统不管是 to B 的还是to C 的,基本都需要考虑多租。下一篇我们将结合Milvus,讲一讲如何构建 RAG 多租户/多用户系统。
作者介绍

郭人通,Zilliz 合伙人和产品总监,CCF 分布式计算与系统专委会执行委员。专注于开发面向 AI 的高效并可扩展的数据分析系统。郭人通拥有华中科技大学计算机软件与理论博士学位。



















