LLama 3.1
先来看看LLama 3.1 405B的效果,例如输入生成上海印象的四连图,然后一键再生成短视频,整体还是可圈可点。

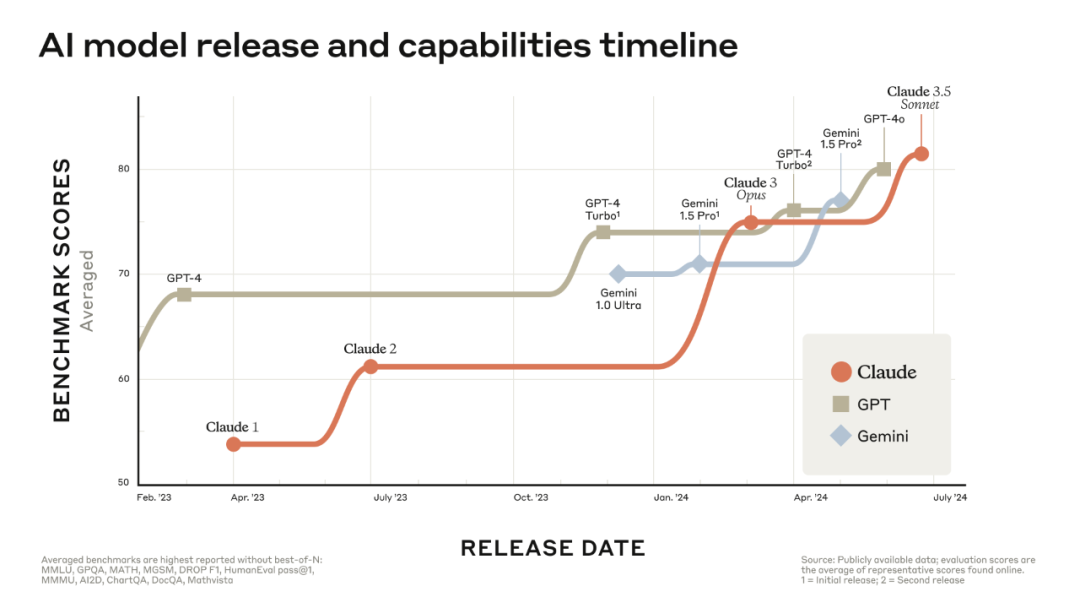
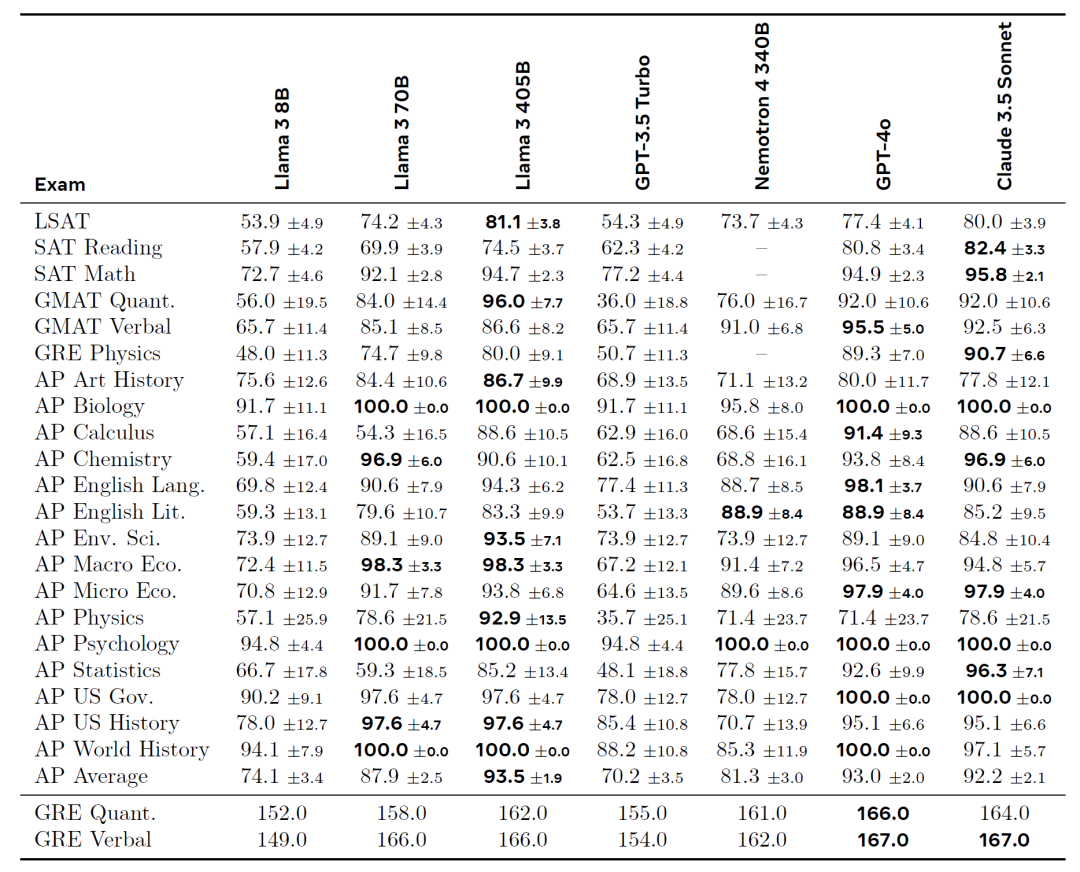
从下面的各项基准而言,LLama3.1系列在同等量级中均有不俗的表现,尤其是405B已经和闭源的GPT-4o不分伯仲,甚至略压一头。
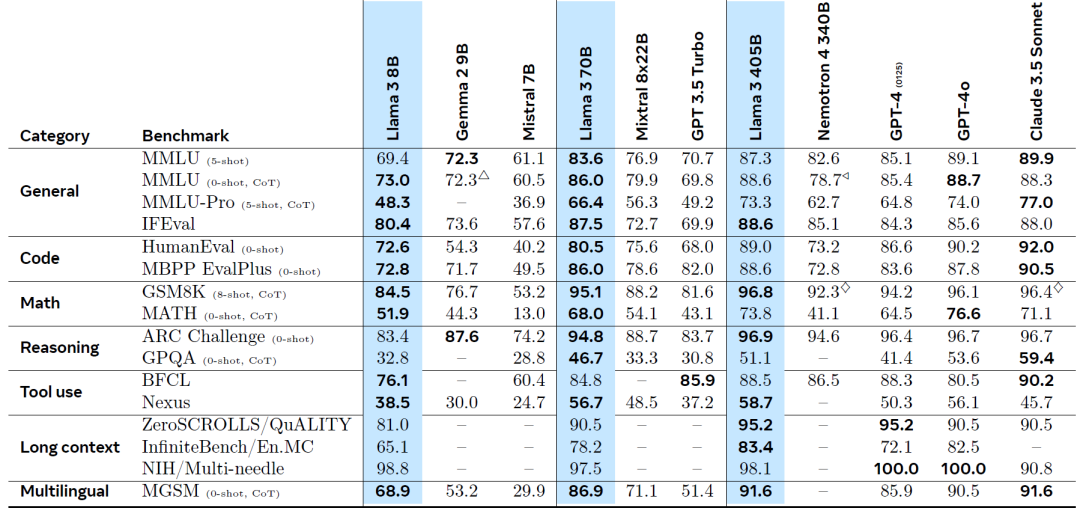
从各种考试成绩来看也是妥妥的优等生:
<405B的对手主要是GPT-4o和Claude3.5 Sonet>
来关注下最强的Llama 3 405B,它是一个密集的Transformer,具405B个参数和一个最多 128K个 token 的上下文窗口。同时Meta还留了一个伏笔,它们目前通过组合方法将图像、视频和语音功能集成到Llama 3,这种方法在图像、视频和语音识别任务上的表现与最先进的方法不相上下。由于仍在开发中,因此这个生成模型尚未广泛发布。
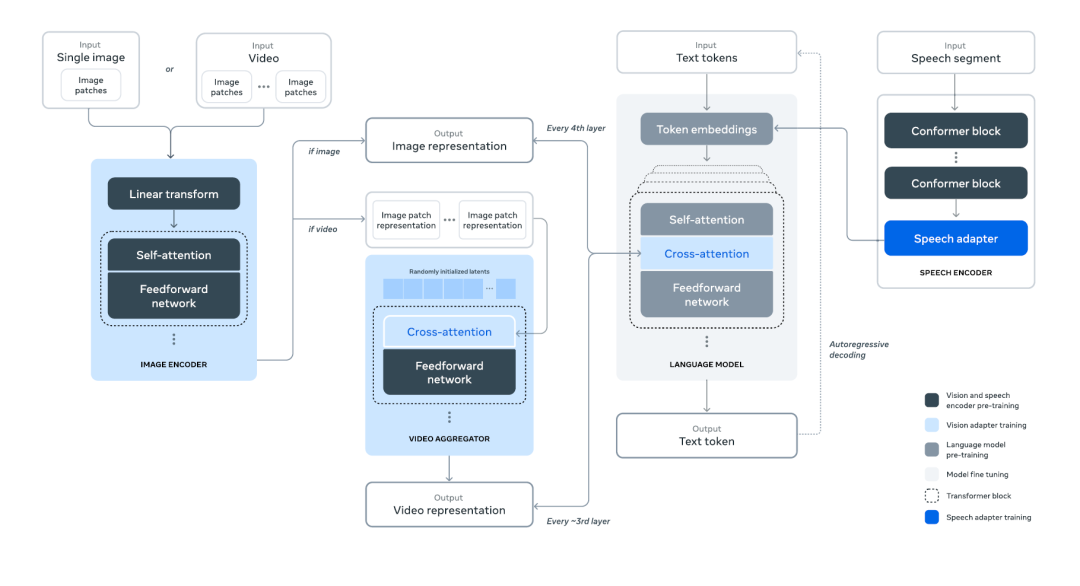
Meta认为,开发高质量基础模型有三个关键杠杆:数据、规模和管理复杂性。因此在本次系列模型中,针对这三个方面进行创新:
• 数据:与 Llama 的先前版本相比,提高了用于预训练和后训练的数据的数量和质量。这些改进包括为预训练数据开发更仔细的预处理和管理管道,以及为后训练数据开发更严格的质量保证和过滤方法。在大约15T多语言标记的语料库上对Llama 3进行了预训练,而Llama 2的语料库只有 1.8T。
• 规模:旗舰语言模型使用3.8× 10^25FLOP 进行预训练,几乎是Llama 2 最大版本的50倍。具体来说在 15.6T文本标记上预训练了一个具有405B可训练参数的旗舰模型。
• 管理复杂性:选择标准密集 Transformer模型架构并进行了一些小的调整,而不是混合专家模型 (MoE),以最大限度地提高训练稳定性。同样,采用基于监督微调 (SFT)、拒绝采样 (RS) 和直接偏好优化 (DPO) 等相对简单的训方法练后阶段,而不是更复杂的强化学习算法,这些算法往往不太稳定且更难扩展。
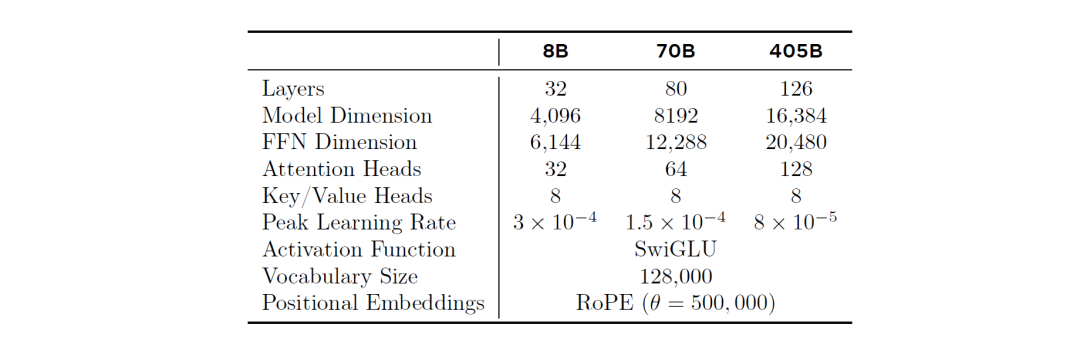
上表为本次系列模型的具体参数细节,更多的技术侧解析将在后续推出~

孟菲斯超级集群
埃隆·马斯克和xAI推出了孟菲斯超级集群,被吹捧为“世界上最强大的人工智能训练集群”。同时宣布在12月之前发布Grok 3.0。
该集群拥有100,000个Nvidia H100 GPU。Grok 2.0已经完成了其训练阶段,并计划即将发布。xAI的目标是到 2024年底,通过Grok 3.0创建“世界上在各个评估基准上最强大的 AI”。它每小时可以消耗高达150兆瓦的电力,相当于为100,000个家庭供电,设施每天至少需要100万加仑的水进行冷却。专家预测它的能力可能会超过目前顶级超级计算机(如Frontier和Aurora)的两倍以上。

计算能力的大规模投资遵循了人工智能模型“越大越好”的行业趋势。更好的人工智能模型需要更多的计算能力,从理论上讲,孟菲斯集群可以在短短一周内训练出GPT-4的模型,而最初估计需要三个月的时间。