【万字长文】
还没写完!!还没写完!!!还在码字中,只是先放上,防止又写着没了,自己文件没了…
最近,可以说的上自己博客停更大约有一两个月了,一直在忙于公司中的项目和业务,典型的牛马看了都流泪
今天,自己刚刚优化了一个查询耗时的BUG,在这里我就引入的
hashmap作为我存储队列的优选我啪啪码完,突然有人问我,
HASHMAP有啥好处啊!我本想装逼的,但是好像话到嘴边,又没了说白了,还是停留在只会用的阶段,现在我们来一起精通它!!!
你说为啥啊!不为别的,就为自己心里那点优越感!哈哈哈!!!
(这里我结合问题的方式来探讨,目的理解更加深刻!!!)
本文总纲:
1.HashMAP的底层实现原理
重点是1.8,先别纠结1.7的,它懂了,就拿下半壁江山了~嘿嘿
2.Hashmap的数据结构(拿来的图哈)
图:
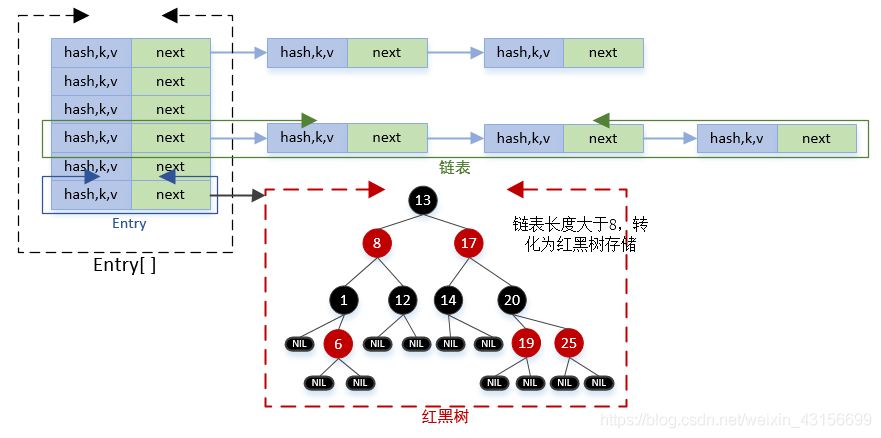
在JDK1.8中,Hashmap的数据结构是数据+链表+红黑树
在链表的长度超过阈值8时,数据结构由链表转换为红黑树,这样的作用就是大大减少查询的时间
可能有的小伙伴会问,为啥要采用这种组合的数据结构啊?我还是不怎么云里雾里!哈哈哈,别急,我来解释噻
说之前,我们先看下数组和链表
众所周知:
- 数组的特点是查询效率高,但是插入和删除的效率低
- 链表就刚好反过来,删插6的不行,但是读查的效率低
那么我们有没有一种鱼和熊掌可兼得的数据结构来将数组和链表的优点结合呢?
不卖关子,有地! 哈希表,(就是大学期末考试最喜欢考的,喵的)
可能有的小伙伴忘记了,我在这里解释下哈希表:(懂的,可以不看)
哈希表介绍:
哈希表(Hash Table),也称为散列表,是一种数据结构,它实现了关联数组的概念,即通过键值对(key-value pairs)存储和检索数据。哈希表使用哈希函数将键映射到数组的一个位置上,从而能够快速地访问所存储的值。
哈希表的主要优点是其查找、插入和删除操作可以在常数时间内完成,即O(1)的时间复杂度,但这在理想情况下才能实现,即没有或很少发生哈希冲突的情况下。哈希冲突是指不同的键通过哈希函数映射到了同一个数组索引位置上。
为了处理哈希冲突,通常有以下几种方法:
- 链地址法(Separate Chaining):在每个数组位置存储一个链表,当多个键映射到同一位置时,这些键值对被链接在一起。
- 开放定址法(Open Addressing):当发生冲突时,寻找下一个可用的数组位置来存储元素,如线性探测(Linear Probing)、二次探测(Quadratic Probing)或双散列(Double Hashing)。
哈希表的性能取决于以下几个关键因素:
- 哈希函数的质量:应该均匀分布键值,减少冲突。
- 负载因子(Load Factor):是表中元素数量与表大小的比值。高负载因子会增加冲突的概率。
- 解决冲突的方法:不同的策略影响查找效率和存储空间。
在实际应用中,哈希表广泛用于数据库索引、缓存机制、编译器符号表、字符串查找算法等场景。
接下来分析下JDK1.8源码中涉及到的数据结构,也解释下为什么链表长度为8时要转换为红黑树的
我们看代码里面的
transient Node<K,V>[] table; //数组
链表
我们看到数组元素
Node<K,V>实现了Entry接口,是单项链表
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
红黑树
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
jdk1.8使用红黑树改进
我们进行源码的阅读时,在JDK1.8中,HashMAP处理碰撞增加了红黑树这种数据结构,当碰撞节点较少时,采用链表存储,当较大时(也就是大于8个),我们采用红黑树
这里我们提一下:链表的时间复杂度为o(n),但红黑树为o(logn),这样一看就知道为啥要优化了吧
为什么HASHMAP不直接使用红黑树呢?
正如上面我们看到的,从时间复杂度来看:
红黑树的平均查找长度(
ASL)是log(n),若查找长度是8,平均查找长度为log(8)=3链表的平均查找长度为n/2,当长度为8时,
ASL=4时,这个时候转换为树就有必要了
- 但是: 若
ASL=6,对于链表的o(n)=3,红黑树的o(n)=log(6)=2.6- 这边区别是不大,但是考虑到转换为树结构和生成树的也是要时间的且不短
你可能说,我就是还是不怎么信服,总感觉还差点意思啊,我们直接看源码的解释
从这段源码的注释,我们看到:
- 树节点所占的空间是普通节点的两倍,从而只有当节点足够多的情况下,才会使用树节点
- 反之:节点少的时候,尽管红黑树的时间复杂度优于链表,但是红黑树的所占的空间比较大(这个缺点大于优点了),采用链表反而更好
- 其实就是权衡利弊,为了在时间和空间上两者综合上达到最优
/*
*主要看这段=================================================================
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
*==================================================================
*/
为什么达到阈值8才会选择使用红黑树呢?
我们知道我们采用HASH表
- 当
hashCode的离散型很好时,树型bin用到的概率很小(可以看上面的源码注释)- 因为数据均匀的分布在每个
bin中,几乎不会有bin中链表长度会达到阈值 - 又在随机的
hashcode下,离散性可能会变差,然而JDK又不能阻止用户实现这种不好的HASH算法,就可能导致不均匀的数据分布 - 但是在理想情况下:随机的
hashcode算法下所有的bin中节点分布频率会遵循泊松分布,且根据统计,一个bin的链表长度会达到8个元素的概率为0.00000006(上面我们看到),几率相当于是不可能事件 - 而这时链表的性能已经很差了,在这种糟糕的环境下,链表才会转换为红黑树,来提高性能
- 因为数据均匀的分布在每个
- 而在大部分的情况下,我们使用的就是链表,如果理想的均匀分布的情况下,节点数不到8,
Hashmap就会自动扩容,具体我们看下面的源码: - 所以通常的情况下,我们用的都是链表,只有哈希表容量很大,链表长度=8,此时链表性能够很差了,我们要提高性能,就采用红黑树了
- 综上所述:就是链表长度为8转为红黑树的原因
翻译下: 除非
hash表太小,我们调整大小,否则就替换给定的哈希值索引出bin中所有链接的节点
//满足节点变成树的另一个条件,就是存放node的数组长度要达到64
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//数组长度小于MIN_TREEIFY_CAPACITY,就会扩容,而不是直接转变为红黑树
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
那hashmap的扩容问题呢?
Hashmap的构造函数
参数:
initialCapacity:初始容量
loadFactor:填充比
主要就四种:
//构造函数1(带有初始容量和加载因子的有参构造函数)
public HashMap(int initialCapacity, float loadFactor) {
//指定的初始容量非负
if (initialCapacity < 0)
throw new IllegalArgumentException(Illegal initial capacity: +
initialCapacity);
//如果指定的初始容量大于最大容量,置为最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//填充比为正
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException(Illegal load factor: +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);//新的扩容临界值
}
//构造函数2(只带有初始容量的构造函数)
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//构造函数3(无参构造函数)
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
//构造函数4(用m的元素初始化散列映射)
public HashMap(Map<!--? extends K, ? extends V--> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
Hashmap的存取原理
1.put的实现原理
1.判断
key对数组table[]是否为空或null,否则默认大小resize()2.根据
key计算hash值插入到数组索引i,若table[i]==null,直接新建节点添加,否则下一步3.判断当前数组中处理
hash冲突的方式为链表还是红黑树(check第一个节点类型),分别处理
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/*如果table的在(n-1)&hash的值是空,就新建一个节点插入在该位置*/
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
/*表示有冲突,开始处理冲突*/
else {
Node<K,V> e;
K k;
/*检查第一个Node,p是不是要找的值*/
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
/*指针为空就挂在后面*/
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果冲突的节点数已经达到8个,看是否需要改变冲突节点的存储结构,
//treeifyBin首先判断当前hashMap的长度,如果不足64,只进行
//resize,扩容table,如果达到64,那么将冲突的存储结构为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
/*如果有相同的key值就结束遍历*/
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
/*就是链表上有相同的key值*/
if (e != null) { // existing mapping for key,就是key的Value存在
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;//返回存在的Value值
}
}
++modCount;
/*如果当前大小大于门限,门限原本是初始容量*0.75*/
if (++size > threshold)
resize();//扩容两倍
afterNodeInsertion(evict);
return null;
}
Hashmap的get()方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab;//Entry对象数组
Node<K,V> first,e; //在tab数组中经过散列的第一个位置
int n;
K k;
/*找到插入的第一个Node,方法是hash值和n-1相与,tab[(n - 1) & hash]*/
//也就是说在一条链上的hash值相同的
if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {
/*检查第一个Node是不是要找的Node*/
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))//判断条件是hash值要相同,key值要相同
return first;
/*检查first后面的node*/
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
/*遍历后面的链表,找到key值和hash值都相同的Node*/
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
}
HashMAP的扩容机制:
HashMap 在 Java 中是一个常用的集合类,它基于哈希表实现,提供键值对的存储和检索。HashMap 的扩容机制是确保其性能的关键部分,因为随着元素的增加,哈希碰撞的可能性也会增加,这可能导致性能下降。因此,HashMap 设计了动态扩容机制以保持其效率。
在 Java 8 及以后的版本中,HashMap 的主要结构包括一个节点数组 Node<K,V>[] table 和一些内部节点类(如 Node 或 TreeNode)。HashMap 的初始容量通常是16,并且要求容量始终是2的幂。每次扩容都会使容量翻倍。
以下是 HashMap 扩容机制的主要步骤:
-
判断条件:当
HashMap中的元素数量超过了当前容量乘以负载因子(默认是0.75)时,就会触发扩容操作。也就是说,当size > capacity * loadFactor时,HashMap将进行扩容。 -
创建新数组:扩容时,
HashMap会创建一个新的节点数组,其长度是原数组长度的两倍。 -
重新哈希:所有旧数组中的元素必须重新计算它们在新数组中的位置。这是因为哈希值与数组大小相关,而数组大小已经改变。这个过程被称为“再哈希”(rehashing)。
-
迁移元素:每个元素从旧数组中移除并插入到新数组中适当的位置。这涉及到遍历旧数组中的每个桶,并根据新的哈希值和新数组的大小确定每个元素的新位置。
-
更新引用:一旦所有元素都已重新定位,
HashMap的内部引用将指向新数组,而旧数组会被垃圾回收。
需要注意的是,扩容操作是昂贵的,因为它涉及到遍历和再哈希整个哈希表。因此,选择合适的初始容量和负载因子可以减少扩容的频率,从而提高性能。此外,在高并发环境下,HashMap 的扩容操作可能会导致数据不一致,因此在多线程环境中使用时需要特别注意线程安全问题,或者考虑使用 ConcurrentHashMap 这样的线程安全替代品。