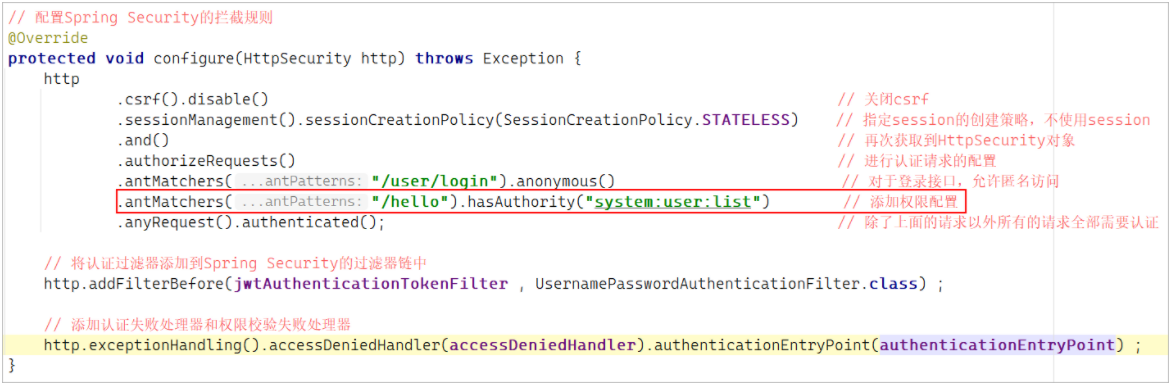
1 创建Vulkan instance
- 利用
CreateInfo结构体指定硬件驱动需要使用的程序信息,这些信息可能会被作为驱动程序的优化依据 - 指定程序需要使用的
全局扩展。比如和窗口系统交互的扩展(通过glfw库的接口获取)。可以通过vkEnumerateInstanceExtensionProperties()函数获取硬件所支持的扩展列表,用于判断需要的扩展是否被支持,以此可以决定接下来的行为是结束程序还是忽略它 - 指定程序需要使用的
全局校验层。与其一个个指定校验层列表,不如直接通过指定一个VK_LAYER_KHRONOS_validation来隐式的开启所有硬件支持的校验层 pNext成员变量指向未来可能扩展的参数信息
2 debug消息回调
- 如果确实要使用校验层,为了获取调试信息,不光需要在前面创建实例的CreateInfo中指定需要使用的校验层,还需要使用
VK_EXT_debug_utils这个全局扩展(额外push_back到扩展列表中,然后赋值给CreateInfo的校验层数组成员中) - 设置一个
回调函数用于接收调试信息。可以指定接收消息的级别、类型以及消息本身 - 设置一个
VkDebugUtilsMessengerEXT对象存储回调函数信息并提交给Vulkan完成回调函数的设置。这个对象的创建和设置需要调用vkCreateDebugUtilsMessangerEXT()来创建,这是一个扩展函数,不会被Vulkan自动加载,因此又需要调用vkGetInstanceProcAddr()来加载这个扩展函数
3 物理设备和队列族
物理设备适用性判断:调用接口vkEnumeratePhysicalDevices()请求获取显卡列表。设计一个函数isDeviceSuitable()来判断显卡是否满足程序需求。主要判断内容为:
- 是否支持我们需要的队列族
- 交换链的细节属性支持情况
队列族:Vulkan所有操作都必须提交给一个队列,然后才能执行。Vulkan有诸多不同类型的队列族,每个队列族的队列只允许存放特定的一部分指令(如图形指令、内存传输指令等)。
- 利用
VkQueueFamilyProperties()检测硬件支持的队列族,找出其中支持我们需要使用的指令的队列族。检查queueFlags & VK_QUEUE_GRAPHICS_BIT - 队列族的查找也应当加入
isDeviceSuitable()函数中,作为该硬件是否合适的评判条件之一
4 逻辑设备和队列
逻辑设备VkDevice对象是作为物理设备的接口。
- 1个物理设备可以创建n个逻辑设备
- 指定逻辑设备使用的队列需要指定使用的个数与其所属的队列族(索引值,索引的物理设备的队列族列表)
- 可以多个线程创建指令缓冲,然后在主线程一次性提交给队列
- 需要显式的指定队列的优先级(0~1.0)
- 指定需要启用的物理设备特性(
VkPhysicalDeviceFeatures),比如需要开启"VK_KHR_swapchain" - 指定校验层,与instance使用的校验层相同即可
获取队列句柄
- 通过
vkGetDeviceQueue()接口可以获取逻辑设备申请到的队列句柄
5 窗口表面
与窗口相关的全局扩展已经在创建Vulkan instance时,获取glfw所需扩展的时候就拿到并且指定了。
- 可以利用
glfwCrateWindowSurface直接创建窗口表面VkSurfaceKHR对象 - 不同平台的Vulkan对于特性的支持不同,因此需要检查GPU是否具备呈现图像到窗口表面的能力,通过调用
vkGetPhysicalDeviceSurfaceSupportKHR() - 支持绘制命令和呈现图像到窗口表面的队列族可能是不同的,因此还需要获取支持呈现图像到窗口表面的队列族的索引。大部分是相同,我们只需要获取一个队列族。
- 创建呈现队列VkQueue对象
6 交换链
Vulkan没有默认帧缓冲,所以通过交换链缓冲渲染操作
交换链的本质: 一个包含了若干等待呈现到窗口表面的图像的队列
用法: 应用程序从交换链获取一张图像 - > 渲染到图像上 -> 返还给交换链的队列
创建流程:
-
检查扩展支持情况(
VK_KHR_SWAPCHAIN_EXTENSION_NAME) -
在逻辑设备的CreateInfo中,启用交换链扩展
-
获取窗口表面的细节属性列表,为了与窗口表面兼容,交换链的三个属性应该在surface所支持的格式中进行选择
- 获取窗口表面支持的图像尺寸、数量等属性:
vkGetPhysicalDeviceSurfaceCapabilitiesKHR(device, surfafce ...), - 获取窗口表面支持的图像格式:通道格式、颜色空间等,
vkGetPhysicalDeviceSurfaceFormats() - 获取窗口表面支持的呈现模式:
vkGetPhysicalDeviceSurfcePresentMode()
- 获取窗口表面支持的图像尺寸、数量等属性:
-
指定交换链呈现模式: 决定在什么条件下,交换链会呈现图像到窗口表面,以下只有FIFO绝对支持,其他的都需要检测GPU是否支持,效果最好的是三重缓冲
- VK_PRESENT_MODE_
IMMEDIATE_KHR(次优先使用):应用程序提交给交换链的图像立即传输到屏幕上 FIFO(最次):交换链变为FIFO队列,程序提交的图像入队,队满后程序会等待,每一帧都从队首取出图像进行显示RELAXED:比FIFO呈现模式增加了一个特性:如果应用程序渲染图像过慢,队列在垂直回扫时为空,且又在下一次回扫之前提交了图像到队列中,则图像会立刻被显示,导致撕裂MAILBOX(优先使用):FIFO的变种,交换链满时不会阻塞程序,而是直接覆盖,可以实现三重缓冲。好处是:低延迟,避免撕裂
- VK_PRESENT_MODE_
-
指定交换链图像分辨率:依然是根据之前获取的窗口表面属性来设置
-
指定多个不同队列使用交换链图像的方式:
- VK_SHARING_MODE_
EXCLUSIVE:排外,同一时刻只能被一个队列拥有,另一个队列想用,必须显式切换使用权。性能最佳 - CONCURRENT:图像可被多个队列同时使用
- VK_SHARING_MODE_
-
调用
vkCreateSwapchainKHR()创建交换链之后,获取交换链的图像句柄vkGetSwapchainImagesKHR()
7 图像视图
任何VkImage对象都需要显式的对其绑定一个图像视图 来访问vkCreateImageView()。图像视图描述了访问该图像的作用、访问方式、访问区域等信息。对于交换链中的每个图像、渲染流程中的每个图象都应该绑定一个图像视图。
8 图形管线(Graphics Pipeline)
一个记录整个从输入数据到图像输出过程的一些状态信息的对象。Vulkan几乎不允许动态修改图形管线,这就要求我们必须提前创建好所有需要使用的图形管线。图形管线是以对象的形式使用的,通过结构体VkGraphicsPipelineCreateInfo指定信息,后面的8.1~8.3有详细说明
- input assembler:获取顶点数据
- vertex shader:对每个顶点进行MVP变换,然后传递给下个阶段
- tessellation shader:曲面细分阶段
- rasterization:光栅化阶段
- fragment shader:对每一个图元覆盖的片段进行处理,确定要写入的帧缓冲,使用vs阶段的插值数据
- color blending:对写入frame buffer同一位置的不同片段进行混合操作
8.1 渲染管线:着色器模块
Vulkan使用的着色器代码是SPIR-V格式的字节码,从字节码转换成类C代码的复杂度很低,并且不同GPU厂商的实现差异也不大,因此兼容性也更好。通过Vulkan SDK中提供的 glslangValidator.exe,可以将GLSL代码编译成SPIR-V字节码,因此我们并不需要用字节码写着色器。
- 读取字节码,调用
vkCreateShaderModule()创建VkShaderModule对象 - 这个对象仅仅是对字节码的包装,还需要指定在管线的哪个阶段使用这个着色器对象。这个操作可通过填写
createInfo.stage成员变量进行指定(VERTEX or FRAGMENT),pName成员可以指定入口函数名,由此可以实现一份着色器代码实现多个着色器,然后通过不同pName指定 - 在书内程序中shaderStage使用了两个,分别是VS,FS
- 每个着色器的createInfo创建完后,结束
8.2 渲染管线:固定功能
- 顶点输入:
VkPipelineVertexInputStateCreateInfo描述传递给顶点着色器的数据格式 - 输入装配:
VkPipelineAssemblyStateCreateInfo描述几何图元 - 视口与裁剪:
VkPipelineViewportCreateInfo描述视口大小和裁剪范围 - 光栅化:
VkPipelineRasterizationStateCreateInfo- 指定n/f平面之外的片段处理方式
- 几何图元生成片段的方式
polygonMode成员:FILL、LINE、POINT - 背面剔除等等功能
- 多重采样:
VkPipelineMultisampleStateCreateInfo - 深度/模板测试:
VkPipelineDepthStencilStateCreateInfo - 颜色混合:
VkPipelineColorBlendAttachmentStateorVkPipelineColorBlendStateCreateInfo - 动态状态:指定个别管线状态可以动态修改,通过
VkPipelineDynamicStateCreateInfo修改,比如视口大小、线宽、混合常量。一旦设置这些属性为动态修改,则前面对他们的设置就会失效。进行绘制时才能对这些属性进行设置 - Layout变量设置:shader阶段的layout设置,主要是用来动态设置
uniform变量,利用VkPipelineLayout对象来定义
8.3 渲染管线:渲染流程(Render Pass)
目前,还没有创建渲染管线,因为我们需要设置 render pass 对象。填写VkRenderPassCreateInfo结构体,指定用到的附件、子流程等
8.3.1 附件 Attachment
通过VkAttachmentDescription结构体描述该附件的格式、采样数、等属性。有多少个附件就要创建多少个Description,可以用数组存放
- 附件:颜色附件、深度缓冲附件、模板缓冲附件
- 帧缓冲:可以挂载多个附件,至少有1个颜色附件(见9)
成员变量loadOp和storeOp会对颜色附件、深度缓冲附件同时起作用。模板缓冲相较之下不那么常用,单独用stencilLoadOp 和 setncilStoreOp来控制。
loadOp:指定在渲染前,将要加载该附件之前,对该附件中的数据进行的操作- VK_ATTACHMENT_LOAD_OP_
LOAD:保持附件内的现有内容 - VK_ATTACHMENT_LOAD_OP_
CLEAR:用一个常量清除附着内容 - VK_ATTACHMENT_LOAD_OP_
DONT CARE:无所谓
- VK_ATTACHMENT_LOAD_OP_
storeOp:指定在渲染后,对该附件中的数据进行的操作- VK_ATTACHMENT_STORE_OP_
STORE:渲染结果存储在附件中,之后会用到 - VK_ATTACHMENT_STORE_OP_
DONT CARE:无所谓,渲染内容不会被使用
- VK_ATTACHMENT_STORE_OP_
指定附件在内存中的布局,Vulkan中的 texture 和 frame buffer 都是由 VkImage 来表示。而VkImage需要指定在内存中的布局,这取决于这个image对象到底被用来做什么。
-
initialLayout:指定渲染流程开始前的图像布局方式 -
finalLayout:指定渲染流程结束后的图像布局方式- VK_IMAGE_LAYOUT_
COLOR_ATTACHMENT_OPTIMAL:图像被用作颜色附着 - VK_IMAGE_LAYOUT_
PRESENT_SRC_KHR:图像可以被用在交换链中进行呈现操作 - VK_IMAGE_LAYOUT_
TRANSFER_DST_OPTIMAL:被用作复制操作的目标图像 - VK_IMAGE_LAYOUT_
UNDEFINED:无所谓
- VK_IMAGE_LAYOUT_
-
比如我们画三角形,每次绘制都清除一遍颜色附件的内容,因此
initialLayout指定为UNDEFINED,渲染结束后,会把该图像呈现到视口,因此finalLayout应该指定为PRESENT
8.3.2 子流程创建 和 附件引用
子流程subPass:渲染流程(render pass)可以包含多个子流程,可以简称为 pass。子流程依赖于上一个子流程处理后得frame buffer的内容。比如第一个pass渲染得到场景的法线信息、顶点信息等存在纹理中,第二个pass利用这些纹理做光照计算,得到最终图像。
附件引用:每个渲染流程都有若干附件,这些资源要被子流程使用,必须通过附件引用来使用他们。每个子流程可以引用1 or N个附件。通过VkAttachmentReference结构体指定,索引从0~N,对应于前面的附件数,还需要指定layout内存布局,Vulkan会在子流程开始时自动将引用的附件转换到layout成员指定的布局方式。
- 子流程通过
VkSubPassDescription来描述,由于未来可能会支持计算子流程,因此要求我们显式的指定这是什么类型,目前我们使用的是图形子流程VK_PIPELINE_BIND_POINT_GRAPHICS - 指定引用的颜色附件,如果是多个,可以传数组。这里指定的附件索引会在片段着色器中使用(
FS),对应于layout(location = 索引号) out vec4 outColor。还有一些其他类型的附件如:着色器读取附件、多重采样颜色附件、深度模板附件等,这些都是通过子流程的成员变量来赋值
8.3.3 子流程依赖
一个宏观的renderPass是由多个subPass组成的,subPass具有顺序性,前后依赖性,因此创建一个renderPass还需要指定其下属subPass之间的依赖关系。尽管我们目前的渲染流程仅包含1个subPass,但是依然需要指明它所依赖的前置操作和前置管线阶段,以及它将会执行什么类型的操作等信息,硬件需要根据这些信息来决定内存布局。具体请参考11.2.3节
8.4 创建图形管线
上面已经定义了图形管线的所有功能,现在可以填写VkGraphicsPipelineCreateInfo结构体来创建渲染管线对象了。把前面的各种state createInfo指定一遍即可。注意base前缀的成员变量是以一个基础管线衍生新的管线,相应的,flags要改为DERIVATIVE_BIT。通过VkCreateGraphicsPipeline创建对象,第二个参数可以实现将管线创建相关数据缓存到文件中,在多个程序间使用。
9 帧缓冲(Framebuffer)
每个frame butter是需要绑定颜色附件的,颜色附件就是交换链中的图像,而所有图像都必须通过该图像对应的image view 来访问,因此是把imageview 绑定到 framebuffer上。
10 指令缓冲与指令池
指令缓冲:可以记录多个指令的一块内存区域。对于绘制指令,由于必须绘制到 frame buffer上,并且所有的绘制结果又必须放入交换链,因此要为交换链中的每个图像创键一个指令缓冲,且绑定一个frame buffer。指令缓冲记录的所有指令,就是对该framebuffer所绑定的swapchain中的图像所进行的操作
指令池:用于管理指令缓冲的内存和分配,每个指令池分配的指令缓冲只能提交给特定的队列族,这个对列族在创建该指令池的时候就已经指定
指令队列:存放所有待执行的指令缓冲对像
分配指令缓冲
- 填写
VkCommandBufferAllocateInfo结构体指定需要分配的缓冲信息 - 指定的信息包括:
command pool对象- 分配的个数(可以一次性为多个交换链像创建指令缓冲)
- 缓冲的级别,
PRIMARY或SCONDARY,分别表示主指令缓冲或辅助指令缓冲。主缓冲可以提交给队列,辅助缓冲只能被主缓冲使用,辅助指令缓冲主要用来记录一些常用的指令,便于复用 - 调用
vkAllocateCommandBuffers进行创建
记录指令到指令缓冲
- 调用
vkBeginCommandBuffer()表示开始指令的记录(每次调用都会重置该指令缓冲),需通过形参传入VkCommandBufferBeginInfo对象指明这个缓冲的一些细节属性

- 往后的所有cmd开头的函数都是一个个指令,被记录到缓冲中
vkCmdBeginRenderPass(),开始一个pass。 需要使用vkRenderPassBeginInfo指定相关信息(使用哪个renderpass对像等)vkCmdBindPipeline(),绑定图形管线对象vkCmdDraw(),绘制操作vkEndRenderPass(),结束该pass
- 调用
vkEndCommandBuffer(),表示本次指令缓冲记录结束
11 渲染和呈现
主循环中调用drawFrame(),在屏幕中绘制一个三角形。主要流程为:
- 从交换链获取一张图像
- 对帧缓冲的附着执行指令缓冲的渲染指令
- 返回渲染后的图像到交换链中,进行呈现操作
11.1 同步
上面的每个操作都是一个函数调用,虽然代码从上至下,但实际上是异步执行的。我们需要让他所有操作有先后顺序,因此需要同步操作。
- 栅栏(fence):CPU端与GPU端进行同步操作,可调用
vkWaitForFences()查询栅栏状态 - 信号量(semaphore):对一个指令队列内的操作,或多个不同指令队列的操作进行同步
在drawFrame()中,我们需要同步指令队列中的绘制操作和呈现操作,因此使用信号量。
我们需要两个信号量
- 信号量1:发出图像已经被获取,可以开始渲染的信号
- 信号量2:一个信号量发出渲染结束,可以开始呈现的信号
11.2 drawFrame()具体流程
11.2.1 获取交换链图像
- 调用
vkAcquireNextImageKHR() - 参数4,5:用于指定当图像可用后,要通知的同步对象,即信号量和栅栏对象
- 参数6:用于接收返回的图像索引,我们需要用这个索引来引用swapChainImage数组中的VkImage对象,以及确定应该记录指令到哪一个指令缓冲
KHR后缀是因为交换链是一个扩展特性,所有与该扩展相关的操作都会带这个后缀
11.2.2 提交指令缓冲
- 通过
VkSubmitInfo结构体,提交本指令缓冲的详细信息给指令队列 waitSemaphoreCount、pWaitSemaphores、pWaitDstStageMask用于指定队列开始执行前需要等待的信号量、管线阶段(因为要执行绘制操作,因此需要等待管线执行到 可以写入颜色附着VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT)- 注意,等待的管线阶段和信号量可以是多个,用数组存储,并且相对应的管线阶段和信号量的索引必须一致
- 指定被提交的指令缓冲对象
- 指定指令缓冲执行结束后要通知的信号量对象
- 最后通过
vkQueueSubmit()将指令缓冲提交给指令队列。它可以同时提交多个指令缓冲,传入提交信息结构体数组即可。最后一个参数是可选填的栅栏对象,我们用的信号量,没用栅栏,因此为VK_NULL_HANDLE
11.2.3 指定子流程依赖
-
这要在创建renderpass时,即
createRenderPass()中进行设置。通过填写VkSubpassDependency。子流程有依赖关系,这种依赖包括子流程之间的内存和执行关系的依赖,这种关系会影响到它本身的内存布局,尽管只使用1个子流程,但它执行前后的操作也被当做是隐藏子流程。渲染流程开始和结束会自动进行图形布局变换。但这样不符合我们需求,因为渲染开始时,有可能还没获取到交换链图像,这里也需要做同步操作。- 方式1:设置成员变量
imageAvailableSemaphores信号量的waitStages为VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT,确保渲染流程在获取到交换链图像之后才能开始 - 方式2:设置直接在
dependency结构体的成员中,指定本subpass需要等待VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT管线阶段
- 方式1:设置成员变量
-
VkSubpassDependency结构体填充srcSubpass:前一个子流程的索引,若为VK_SUBPASS_EXTERNAL,则表示为隐藏子流程dstSubpass:目标子流程,即本流程的索引,我们只有一个,因此为0srcStageMask:需要等待的前一个子流程的管线阶段。需要等待交换链图像读取成功,才能进行图像访问、写入的操作,因此需要等待VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BITsrcAccessMask:需要等待的子流程的操作类型,本例赋值0,应该是读取操作吧?dstStageMask:本流程所位于的管线阶段,也是VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BITdstAccessMask:本流程需要进行的操作类型,VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT颜色附件写入操作
-
搞定子流程之间的依赖后,便可正常创建renderPass对象了,填写
VkRenderPassCreateInfo,并在成员中指定其依赖信息
11.2.4 呈现操作
通过VkPresentInfoKHR配置呈现信息
- 呈现操作需要等待的信号量
signalSemaphore(记录图形操作的指令缓冲执行完发出的) - 指定用于呈现的交换链,目前就一个
- 指定需要呈现的图像在交换链中的索引
然后调用vkQueuePresentKHR 将呈现操作提交给呈现队列(其实就是图形队列,他们索引的同一个队列)。
11.4 多帧并行渲染
在mainLoop中,因为其调用的drawFrame()函数是异步执行,当我们点击关闭窗口时,有可能绘制和呈现等操作还在继续执行,此时再执行清理操作就会冲突。因此在mainLoop()函数的最后,需添加 vkDeviceWaitIdle(device) 函数,等待该逻辑设备的所有操作执行结束。
如果不做CPU GPU同步,drawFrame()无限制地快速提交指令队列给GPU,但却没有在下一次指令提交时检查上一次提交的指令是否已经执行结束,也就是说CPU提交指令速度比GPU处理速度更快,造成GPU端大量指令堆积。
单帧渲染:使用 vkQueueWaitIdle(presentQueue) 来等待上一次提交的指令缓冲执行结束,再提交下一次的指令。
多帧并行渲染
- 由于CPU指令提交 与 GPU处理该指令之间的同步操作的存在,并且GPU并行能力极为突出,一次指令提交,如果只渲染一帧图片,GPU的利用不够充分,因此应该提供CPU提交多个指令缓冲,GPU同时渲染多帧的能力
- 并行计算的每帧所使用的同步对象应该区分开。添加
currentFrame全局变量,用以表示当前帧,以此来选择当前帧应该使用的同步对象。在drawFrame()函数每执行一次提交指令后,同步进行更新 - 我们设定GPU最多并行计算2帧的内容,其中一帧计算完毕后,CPU才能提交新一帧的指令缓冲。因此需要同步操作,并行计算一帧结束发出同步信号通知CPU可以继续提交。这里因为是CPU与GPU之间的同步,所以使用栅栏(fence) 。
vkQueueSubmit函数有一个可选的参数可以用来指定在指令缓冲执行结束后需要通知的fence对象 - 最后
drawFrame()函数的开头,即提交指令缓冲之前,要做同步操作,即等待在currentFrame为某值时提交的指令缓冲执行完后,才能继续提交 - 注意:由于
drawFrame()最前面的等待同步操作,因此fence的初始状态都要设为激活态,否则drawFrame()不会往下执行