资料
位置编码:https://zhuanlan.zhihu.com/p/454482273
自注意力:https://zhuanlan.zhihu.com/p/455399791
LN:https://zhuanlan.zhihu.com/p/456863215
ResNet:https://zhuanlan.zhihu.com/p/459065530
Subword Tokenization:https://zhuanlan.zhihu.com/p/460678461
长文概述:https://zhuanlan.zhihu.com/p/630356292
缓存和效果的拉扯(MHA、MQA、GQA、MLA):https://spaces.ac.cn/archives/10091
为什么Pre Norm不如Post Norm? https://kexue.fm/archives/9009
RoPE:https://zhuanlan.zhihu.com/p/359502624
经典问题:https://github.com/kebijuelun/Awesome-LLM-Learning/blob/main/1.%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/1.Transformer%E5%9F%BA%E7%A1%80.md
位置编码
为什么要位置编码:因为self-attention是无向的。而实际上模型需要知道token之间的距离信息。
位置编码的要求:
(1)能够表示token的绝对位置
(2)序列长度不同时,不同序列中token的相对距离要保持一致
(3)预测阶段,可以表示模型在训练阶段没有见过的句子长度
位置编码的迭代经验、找到一个函数符合以下条件:
(1)有界
(2)连续、且不同
(3)不同位置的向量可以通过线性变换得到
最终Transformer的位置编码的性质:
(1)两个位置编码的点积(dot product)仅取决于偏移量 ,也即两个位置编码的点积可以反应出两个位置编码间的距离。
(2)位置编码的点积是无向的
attention
除以根号dk的原因:

Normalization
常用的标准化方法有Batch Normalization,Layer Normalization,Group Normalization,Instance Normalization等
ICS(Internal Covariate Shift):前一层的数据分布变化 加大后一层的训练难度。
在BN提出之前,有几种用于解决ICS的常规办法:
(1)采用非饱和激活函数
(2)更小的学习速率
(3)更细致的参数初始化办法
(4)数据白化(whitening):在每一层输入时增加线性变化,使得输入的特征具有相同的均值和方差,从而去掉特征的相关性。
更优雅的解决方案:BN
训练

BN的缺点无法很好地处理文本数据长度不一的问题。 可能不止是“长短不一”这一个,也可能和数据本身在某一维度分布上的差异性有关(想一下,对不同句子之间的第一个词做BN,求出来的mean和variance几乎是没有意义的)
在图像问题中,LN是指对一整张图片进行标准化处理,即在一张图片所有channel的pixel范围内计算均值和方差。
而在NLP的问题中,LN是指在一个句子的一个token的范围内进行标准化。即 层归一化(Layer Normalization)的对象是同一个样本中一个token的所有维度。
Pre-LN
在残差连接和MHA计算之前进行LN操作。
好处:能和Post-LN达到相同甚至更好的训练结果,同时规避了在训练Post-LN中产生的种种问题
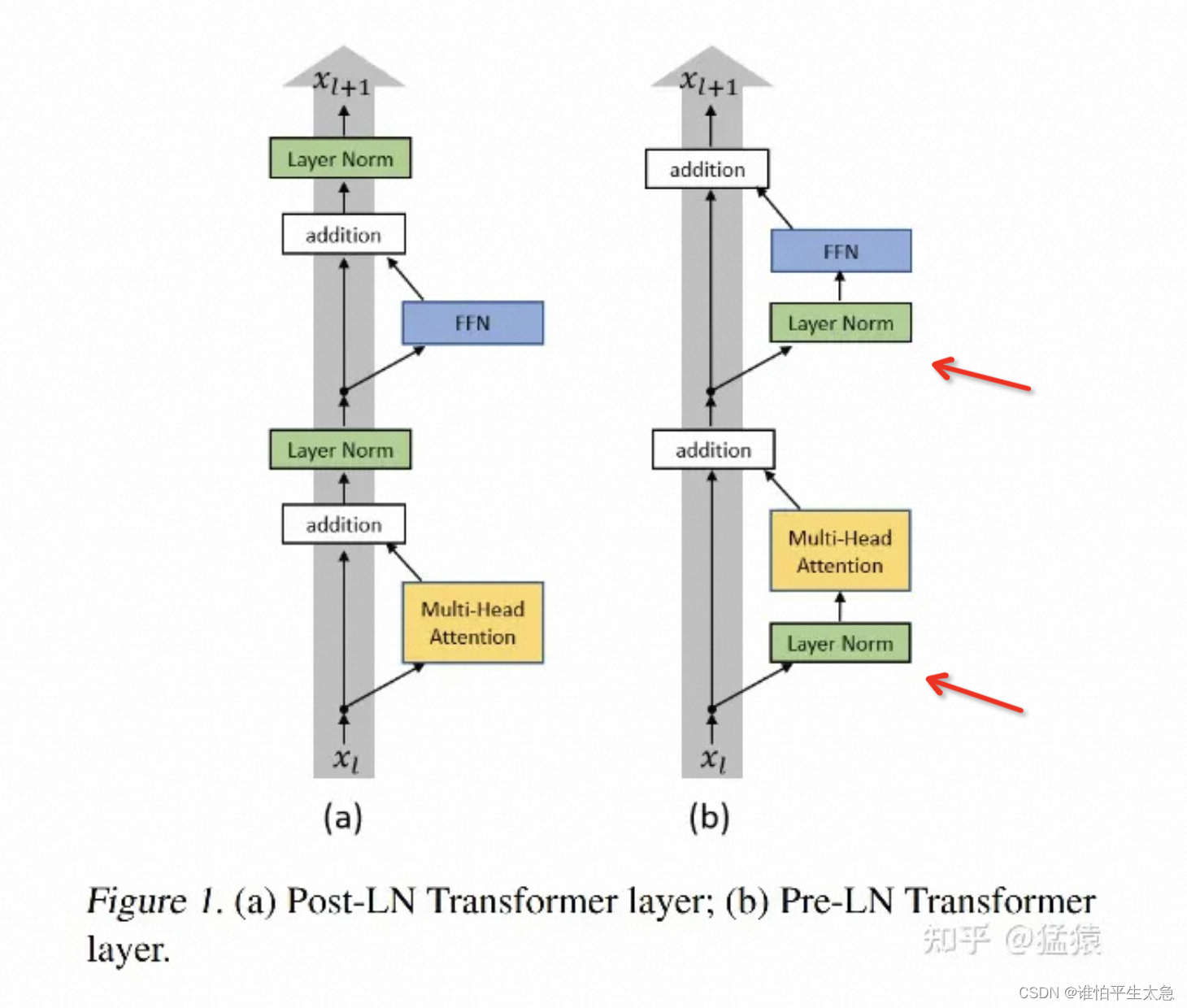


残差网络
normal的引入 解决了 因为 导数的阶乘导致梯度消失或者梯度爆炸。
因为希望通过增加网络深度,来提高非线性拟合能力、使得每一层学到不同的模式。
而网络深度的增加,产生了网络退化的问题。
所以用残差模块来解决。这么设计的 原因是 尽可能让 深层次的网络不比浅层网络表现弱(保证了更多层的神经网络至少能取到更浅的神经网络的最优解)。 类似牵引绳或者KL散度的意思。
恒等映射:深层网络的结果既能学习到极端情况、又能逼近输入。