目录
- 初学EMR
- EMR是什么?
- 我的EMR学习故事
- 糙快猛学习法则
- 代码示例: 你的第一个EMR任务
- 学习EMR的深入步骤
- EMR进阶技巧
- 实用资源推荐
- 常见挑战和解决方案
- EMR生态
- EMR生态系统深度探索
- 1. EMR上的Hadoop生态系统
- 2. EMR Studio
- 3. EMR on EKS
- 高级EMR配置和优化
- 1. EMR实例集策略
- 2. 动态资源分配
- 3. 数据压缩
- 实际应用场景
- 1. 日志分析
- 2. 推荐系统
- 3. 实时流处理
- 持续学习与发展
- EMR故障排除与性能优化
- EMR故障排除与性能优化
- 常见问题及解决方案
- 性能优化技巧
- 实际项目案例
- 案例1:电商平台用户行为分析
- 案例2:实时股票市场分析
- EMR最佳实践
- EMR集成
- EMR的最新发展趋势
- 1. EMR Serverless
- 2. 与机器学习的深度集成
- 3. 容器化和Kubernetes支持
- 与其他AWS服务的高级集成
- 1. EMR与AWS Glue的集成
- 2. EMR与Amazon Athena的集成
- 3. EMR与Apache Kafka的集成
- 4. EMR与Apache Flink的集成
- 5. EMR与Apache Airflow的集成
- 高级应用场景
- 1. 实时数据处理管道
- 2. 机器学习模型训练和部署
- EMR 运维
- EMR运维实战经验
- 1. 集群规划与成本优化
- 2. 监控与告警
- 3. 日志管理
- 常见陷阱及解决方案
- 1. 数据倾斜问题
- 2. 内存溢出
- 3. 小文件问题
- 高级调优技巧
- 1. Spark调优
- 2. YARN调优
- 3. 存储优化
- EMR安全最佳实践
- 1. 网络安全
- 2. 数据安全
- 3. 访问控制
- EMR实际案例研究
- 案例1:大规模日志分析系统
- 案例2:大规模机器学习模型训练
- 未来趋势和技能发展建议
- 结语
- 思维导图
- 同系列文章
初学EMR
EMR是什么?

EMR是Amazon Web Services(AWS)提供的一个云大数据平台,它让我们能够轻松地运行大规模分布式数据处理框架(如Apache Hadoop和Apache Spark)。简单来说,EMR就是一个让你不用自己搭建复杂的大数据集群,就能进行海量数据处理的强大工具。
我的EMR学习故事
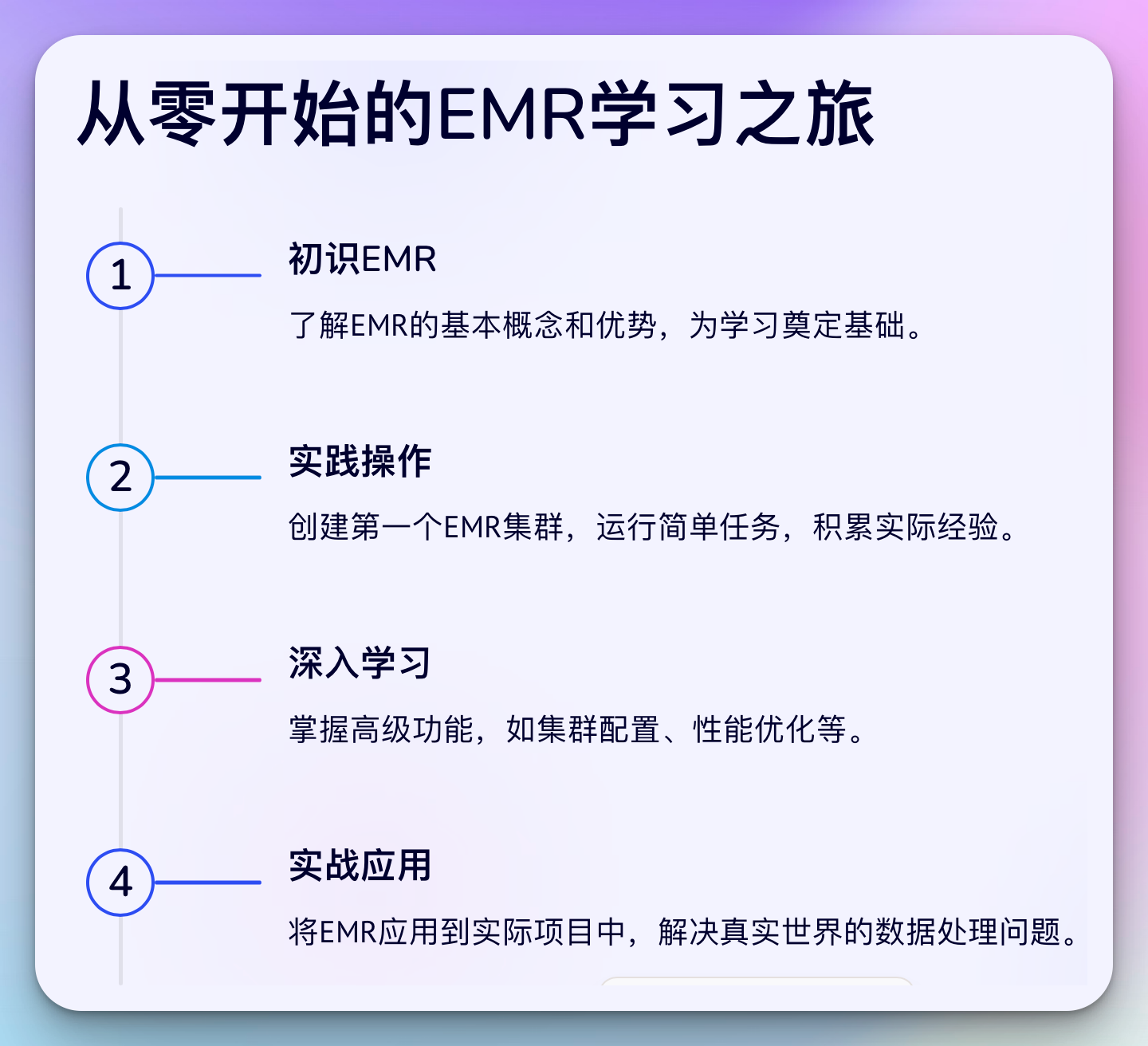
作为一个从0基础跨行到大数据的开发者,我深知学习EMR的挑战。记得刚开始时,我就像一个初出茅庐的水手,面对着EMR这艘庞大的航母,不知所措。
但是,我很快意识到:与其在岸上纠结如何驾驶航母的每个细节,不如先登船,边航行边学习。这就是我所说的"糙快猛"学习法。
糙快猛学习法则

- 快速上手: 不要等到你完全理解EMR的每个细节再开始。创建你的第一个EMR集群,运行一个简单的任务。
- 边做边学: 在实践中学习。每次遇到问题,解决它,你就掌握了新知识。
- 不怕犯错: 错误是最好的老师。在EMR中,你可以轻松地创建和销毁集群,所以大胆尝试!
- 善用工具: 利用AWS提供的文档、教程和社区资源。现在我们还有了强大的AI助手,比如ChatGPT,可以24小时回答你的问题。
代码示例: 你的第一个EMR任务
让我们通过一个简单的例子来开始我们的EMR之旅。假设我们要统计一个大文本文件中每个单词的出现次数。

from pyspark import SparkContext
# 初始化SparkContext
sc = SparkContext(appName="WordCount")
# 读取文件
text = sc.textFile("s3://your-bucket/your-file.txt")
# 单词计数
word_counts = text.flatMap(lambda line: line.split()) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
# 保存结果
word_counts.saveAsTextFile("s3://your-bucket/output")
# 关闭SparkContext
sc.stop()
这段代码看起来简单,但它利用了EMR的分布式计算能力,可以处理大规模的数据。
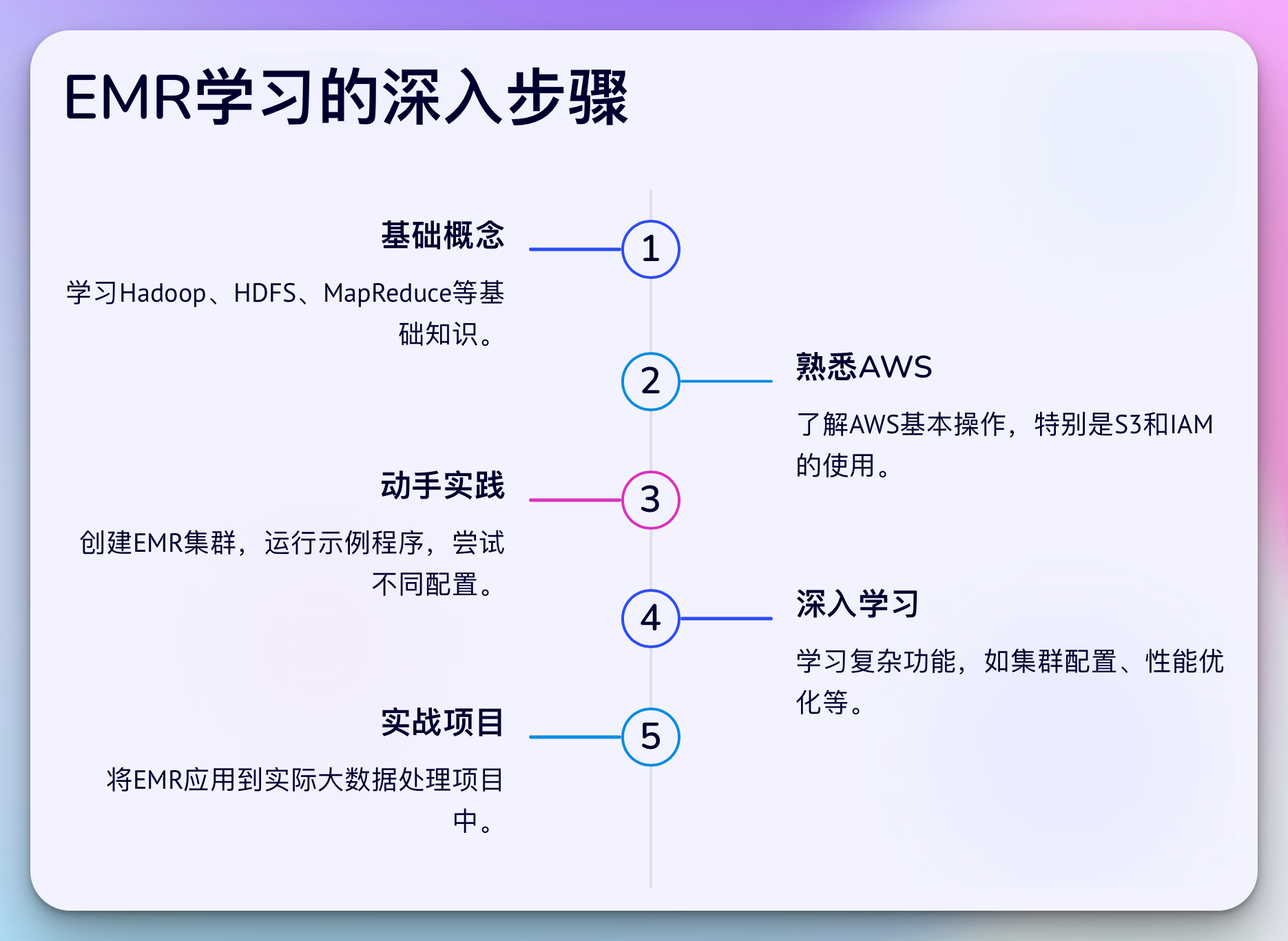
学习EMR的深入步骤
-
了解基础概念:
- 学习Hadoop、HDFS、MapReduce等基础知识。
- 理解分布式计算的原理和优势。
-
熟悉AWS:
- 了解AWS的基本操作,特别是S3的使用。
- 学习AWS IAM,管理你的访问权限。
-
动手实践:
- 创建你的第一个EMR集群,运行示例程序。
- 尝试不同的集群配置,观察性能变化。
-
深入学习:
- 逐步学习更复杂的EMR功能,如集群配置、性能优化等。
- 探索EMR支持的各种大数据工具,如Hive、Presto等。
-
实战项目:
- 将EMR应用到实际的大数据处理项目中。
- 尝试解决真实世界的数据处理问题。
EMR进阶技巧

-
优化成本:
- 学习使用Spot实例来降低成本。
- 合理设置自动扩缩容策略。
-
性能调优:
- 掌握Spark性能调优技巧。
- 学会分析和优化数据倾斜问题。
-
安全性:
- 了解EMR的安全功能,如加密和VPC配置。
- 实践最佳安全实践,保护你的数据和集群。
-
监控和日志:
- 使用CloudWatch监控你的EMR集群。
- 学会分析EMR日志,快速定位问题。
实用资源推荐

- AWS官方文档:https://docs.aws.amazon.com/emr/
- GitHub上的EMR示例:https://github.com/aws-samples/aws-emr-samples
- Udemy上的EMR课程
- EMR相关的技术博客和论坛
常见挑战和解决方案

-
集群启动失败:
- 检查IAM角色和权限设置
- 确保VPC和子网配置正确
-
作业运行缓慢:
- 检查数据倾斜问题
- 优化Spark参数设置
-
成本控制:
- 使用EMR实例集管理多种实例类型
- 合理设置自动终止空闲集群的策略
EMR生态
EMR生态系统深度探索
在掌握了EMR的基础之后,是时候深入探索EMR生态系统了。这个部分将帮助你更全面地了解EMR的强大功能。
1. EMR上的Hadoop生态系统
EMR不仅仅是Hadoop和Spark,它还支持许多其他的开源项目:

- Hive: 用于数据仓库和SQL查询
- Presto: 用于快速交互式查询
- HBase: 用于大规模分布式数据存储
- Flink: 用于流处理和批处理
- Pig: 用于数据流处理和转换
每个工具都有其特定的用途,学习它们将极大地扩展你的大数据处理能力。
2. EMR Studio
EMR Studio是AWS最新推出的一个强大工具,它提供了一个集成开发环境(IDE),可以更方便地开发、可视化和调试大数据应用。学习使用EMR Studio可以大大提高你的开发效率。

3. EMR on EKS
随着Kubernetes的普及,AWS推出了EMR on EKS,允许你在Kubernetes集群上运行EMR应用。这为大数据处理提供了更大的灵活性和可扩展性。

高级EMR配置和优化
掌握了基础知识后,让我们深入一些更高级的配置和优化技巧。
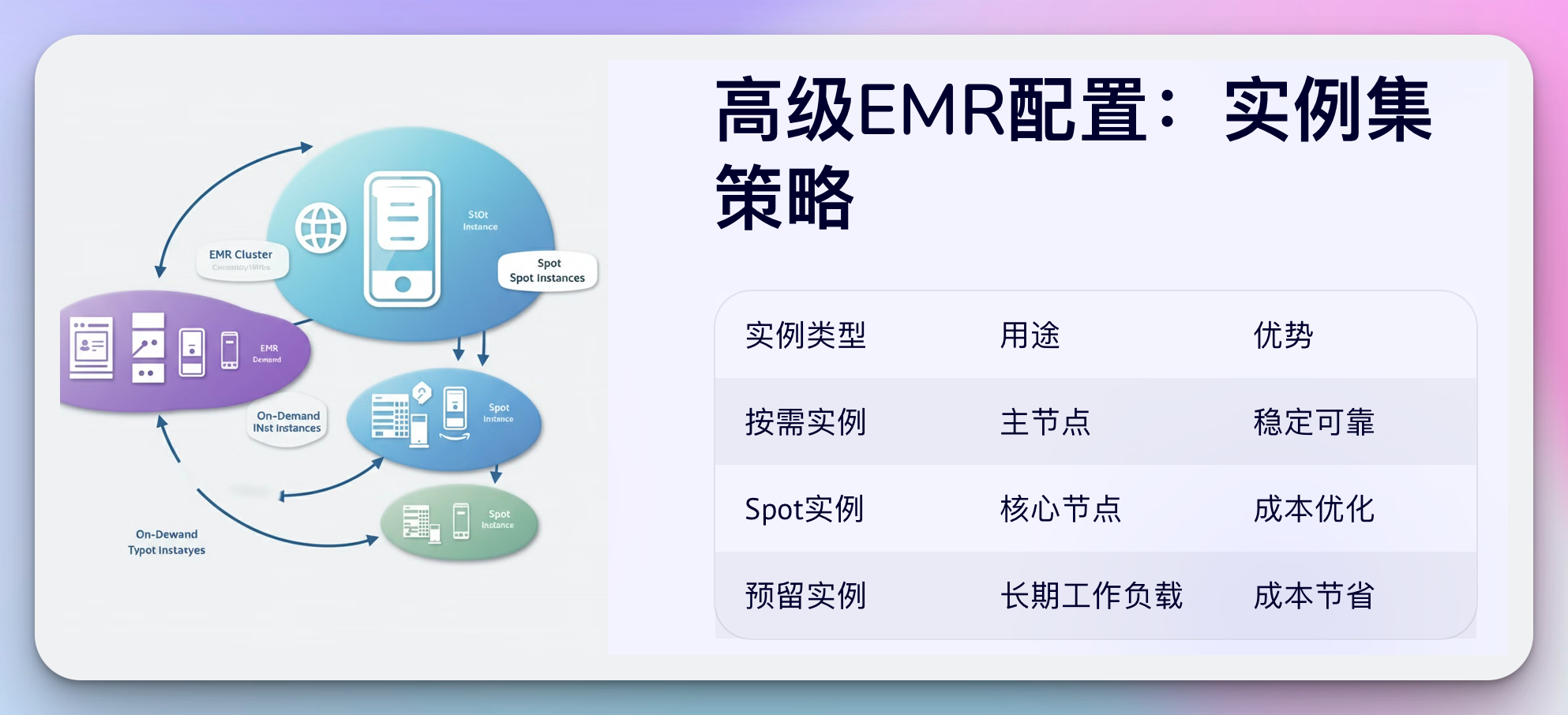
1. EMR实例集策略
EMR实例集允许你在一个集群中混合使用不同类型的EC2实例,包括按需实例、预留实例和Spot实例。这里有一个示例配置:
{
"InstanceFleets": [
{
"Name": "MASTER",
"InstanceFleetType": "MASTER",
"TargetOnDemandCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m5.xlarge"
}
]
},
{
"Name": "CORE",
"InstanceFleetType": "CORE",
"TargetOnDemandCapacity": 2,
"TargetSpotCapacity": 2,
"InstanceTypeConfigs": [
{
"InstanceType": "r5.2xlarge",
"WeightedCapacity": 2
},
{
"InstanceType": "r4.2xlarge",
"WeightedCapacity": 2
}
]
}
]
}
这个配置创建了一个具有1个按需主节点和4个核心节点(2个按需,2个Spot)的集群。
2. 动态资源分配

对于长时间运行的集群,启用动态资源分配可以提高资源利用率:
<property>
<name>yarn.resourcemanager.scheduler.monitor.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.monitor.policies</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.monitor.capacity.ProportionalCapacityPreemptionPolicy</value>
</property>
3. 数据压缩

在处理大量数据时,使用适当的压缩算法可以显著提高性能:
val conf = new SparkConf().setAppName("CompressedDataProcessing")
conf.set("spark.sql.parquet.compression.codec", "snappy")
val sc = new SparkContext(conf)
实际应用场景
让我们看几个EMR的实际应用场景,这将帮助你理解EMR如何在现实世界中发挥作用。
1. 日志分析

假设你需要分析大量的Web服务器日志,以了解用户行为。这里有一个简单的Spark作业来实现这一目标:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, hour
spark = SparkSession.builder.appName("LogAnalysis").getOrCreate()
# 读取日志文件
logs = spark.read.csv("s3://your-bucket/logs/", header=True)
# 提取小时并计算每小时的访问量
hourly_traffic = logs.withColumn("hour", hour("timestamp")) \
.groupBy("hour") \
.count() \
.orderBy("hour")
# 保存结果
hourly_traffic.write.parquet("s3://your-bucket/hourly_traffic/")
2. 推荐系统
EMR也常用于构建推荐系统。这里是一个使用ALS(交替最小二乘法)实现的简单推荐系统:
from pyspark.ml.recommendation import ALS
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("RecommendationSystem").getOrCreate()
# 读取用户-商品评分数据
ratings = spark.read.csv("s3://your-bucket/ratings/", header=True)
# 构建ALS模型
als = ALS(maxIter=5, regParam=0.01, userCol="userId", itemCol="productId", ratingCol="rating")
model = als.fit(ratings)
# 为所有用户生成Top 10推荐
userRecs = model.recommendForAllUsers(10)
# 保存推荐结果
userRecs.write.parquet("s3://your-bucket/recommendations/")
3. 实时流处理
EMR也支持实时流处理。这里是一个使用Spark Streaming处理实时数据的例子:
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kinesis import KinesisUtils, InitialPositionInStream
sc = SparkContext(appName="StreamProcessing")
ssc = StreamingContext(sc, 60) # 60秒的批处理间隔
# 从Kinesis流中读取数据
stream = KinesisUtils.createStream(
ssc, "MySparkStreaming", "myStreamName", "https://kinesis.us-east-1.amazonaws.com",
"us-east-1", InitialPositionInStream.LATEST, 60)
# 处理数据
processed = stream.map(lambda x: process_data(x))
# 保存结果到S3
processed.saveAsTextFiles("s3://your-bucket/streaming-output/")
ssc.start()
ssc.awaitTermination()
持续学习与发展

EMR和大数据领域的技术在不断发展,保持学习的心态至关重要。这里有一些建议:
-
关注AWS的更新:EMR经常会发布新特性,及时了解这些更新可以帮助你更好地利用EMR。
-
参与社区:加入AWS和Hadoop的社区,参与讨论,分享你的经验。
-
实践,实践,再实践:不断尝试新的项目和挑战,这是提升技能的最好方式。
-
探索相关技术:了解周边技术如Docker、Kubernetes等,它们often与EMR结合使用。
-
考虑认证:AWS提供了大数据专业认证,这可以验证你的技能并增加职业机会。
记住,在"糙快猛"学习的同时,也要注意积累深度。每解决一个问题,都要思考背后的原理;每掌握一个工具,都要了解它的适用场景和局限性。
EMR故障排除与性能优化
EMR故障排除与性能优化
在使用EMR的过程中,你可能会遇到各种问题。这里我们列出一些常见问题及其解决方案,以及一些性能优化的技巧。
常见问题及解决方案
-
集群启动失败
- 检查IAM角色权限
- 验证VPC和子网配置
- 查看EC2容量是否足够
# 使用AWS CLI检查集群状态 aws emr describe-cluster --cluster-id j-XXXXXXXXXX -
作业运行缓慢
- 检查数据倾斜
- 优化分区
- 调整executor数量和内存
// Spark作业配置优化示例 spark.conf.set("spark.sql.shuffle.partitions", 200) spark.conf.set("spark.executor.memory", "6g") spark.conf.set("spark.executor.cores", 3) -
YARN资源分配问题
- 调整YARN容器大小
- 优化ApplicationMaster资源分配
<!-- yarn-site.xml 配置示例 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>122880</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>122880</value> </property>
性能优化技巧
-
数据存储格式优化
使用列式存储格式如Parquet可以显著提高查询性能:# 将数据保存为Parquet格式 df.write.parquet("s3://your-bucket/data-parquet/") # 读取Parquet数据 df = spark.read.parquet("s3://your-bucket/data-parquet/") -
分区优化
合理的分区可以提高查询效率:# 按日期分区保存数据 df.write.partitionBy("date").parquet("s3://your-bucket/partitioned-data/") -
缓存和持久化
对频繁使用的数据进行缓存:# 缓存数据 df.cache() # 或者使用更细粒度的持久化控制 from pyspark import StorageLevel df.persist(StorageLevel.MEMORY_AND_DISK) -
广播变量
使用广播变量可以减少数据传输:# 广播一个大的查找表 lookup_table = spark.sparkContext.broadcast(big_lookup_table) # 在作业中使用广播变量 def lookup_function(key): return lookup_table.value.get(key) result = df.rdd.map(lambda x: lookup_function(x.key)).collect()
实际项目案例
让我们通过几个实际的项目案例来看看EMR如何在真实世界中发挥作用。
案例1:电商平台用户行为分析
假设你在一个大型电商平台工作,需要分析用户的购物行为。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum, count
spark = SparkSession.builder.appName("ECommerceAnalysis").getOrCreate()
# 读取用户行为数据
user_behaviors = spark.read.parquet("s3://your-bucket/user-behaviors/")
# 分析用户购买模式
purchase_patterns = user_behaviors.groupBy("user_id", "product_category") \
.agg(count("*").alias("purchase_count"), sum("price").alias("total_spend")) \
.orderBy(col("total_spend").desc())
# 保存分析结果
purchase_patterns.write.parquet("s3://your-bucket/purchase-patterns/")
# 计算产品类别的受欢迎程度
category_popularity = user_behaviors.groupBy("product_category") \
.agg(count("*").alias("view_count")) \
.orderBy(col("view_count").desc())
# 保存分析结果
category_popularity.write.parquet("s3://your-bucket/category-popularity/")
这个案例展示了如何使用EMR和Spark来分析大规模的用户行为数据,从而得出有价值的商业洞察。
案例2:实时股票市场分析
假设你需要构建一个实时股票市场分析系统,处理流式的股票价格数据。
from pyspark.sql import SparkSession
from pyspark.sql.functions import window, avg
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, TimestampType
spark = SparkSession.builder.appName("StockMarketAnalysis").getOrCreate()
# 定义股票数据的schema
schema = StructType([
StructField("symbol", StringType(), True),
StructField("price", DoubleType(), True),
StructField("timestamp", TimestampType(), True)
])
# 从Kinesis读取流数据
stock_prices = spark \
.readStream \
.format("kinesis") \
.option("streamName", "stock-prices") \
.option("endpointUrl", "https://kinesis.us-east-1.amazonaws.com") \
.option("awsAccessKeyId", "YOUR_ACCESS_KEY") \
.option("awsSecretKey", "YOUR_SECRET_KEY") \
.option("startingPosition", "latest") \
.load()
# 计算每5分钟的平均股价
avg_prices = stock_prices \
.groupBy(
window(stock_prices.timestamp, "5 minutes"),
stock_prices.symbol
) \
.agg(avg("price").alias("avg_price"))
# 将结果写入到S3
query = avg_prices \
.writeStream \
.outputMode("append") \
.format("parquet") \
.option("path", "s3://your-bucket/avg-stock-prices/") \
.option("checkpointLocation", "s3://your-bucket/checkpoints/") \
.start()
query.awaitTermination()
这个案例展示了如何使用EMR和Spark Streaming来处理实时数据流,进行实时分析。
EMR最佳实践
在使用EMR的过程中,遵循一些最佳实践可以帮助你更好地利用这个强大的工具:
-
合理规划集群大小:根据数据量和处理需求来确定集群的大小,避免资源浪费。
-
使用实例集:混合使用按需实例和Spot实例可以优化成本。
-
数据分区:合理的数据分区策略可以显著提高查询性能。
-
监控和告警:设置适当的监控和告警,及时发现和解决问题。
-
安全性:使用VPC、安全组和IAM角色来保护你的EMR集群和数据。
-
成本优化:利用EMR的自动扩缩容功能,在需要时增加资源,在空闲时释放资源。
-
版本选择:除非有特殊需求,通常应该选择最新的EMR版本以获得最新的功能和修复。
-
使用EMR Notebooks:对于交互式分析,EMR Notebooks提供了一个方便的环境。
-
数据生命周期管理:使用S3生命周期策略管理数据,将不常用的数据转移到更便宜的存储类别。
-
持续优化:定期审查你的EMR使用情况,寻找优化的机会。
EMR集成
EMR的最新发展趋势
EMR作为AWS的核心大数据服务之一,一直在不断发展和创新。了解这些最新趋势可以帮助你更好地规划学习路径和职业发展。
1. EMR Serverless
EMR Serverless是AWS最新推出的无服务器选项,它允许你运行大数据应用程序而无需配置、管理和扩展集群。这大大简化了EMR的使用流程。
# 使用 Boto3 创建 EMR Serverless 应用
import boto3
client = boto3.client('emr-serverless')
response = client.create_application(
name='MyServerlessApp',
releaseLabel='emr-6.6.0',
type='SPARK'
)
# 获取应用 ID
application_id = response['applicationId']
# 启动作业运行
job_run_response = client.start_job_run(
applicationId=application_id,
executionRoleArn='arn:aws:iam::123456789012:role/EMRServerlessS3AccessRole',
jobDriver={
'sparkSubmit': {
'entryPoint': 's3://mybucket/myapp.py',
'sparkSubmitParameters': '--conf spark.executor.cores=1 --conf spark.executor.memory=4g'
}
}
)
2. 与机器学习的深度集成
EMR现在与SageMaker等AWS机器学习服务有了更深入的集成,使得在大规模数据上进行机器学习变得更加容易。
from pyspark.ml.feature import VectorAssembler
from pyspark.sql import SparkSession
import sagemaker
from sagemaker.spark.preprocessing import SparkMLSageMakerEstimator
# 创建 Spark session
spark = SparkSession.builder.appName("SageMakerIntegration").getOrCreate()
# 准备数据
data = spark.read.parquet("s3://your-bucket/your-data.parquet")
assembler = VectorAssembler(inputCols=["feature1", "feature2", "feature3"], outputCol="features")
data = assembler.transform(data)
# 创建 SageMaker 估算器
estimator = sagemaker.estimator.Estimator(
"your-sagemaker-container-image-uri",
sagemaker.get_execution_role(),
instance_count=1,
instance_type="ml.m4.xlarge"
)
# 使用 SparkMLSageMakerEstimator 训练模型
spark_estimator = SparkMLSageMakerEstimator(
estimator=estimator,
instance_count=1,
instance_type="ml.m4.xlarge"
)
model = spark_estimator.fit(data)
3. 容器化和Kubernetes支持
EMR on EKS的推出使得在Kubernetes环境中运行EMR变得可能,这为大数据处理提供了更大的灵活性和可移植性。
# EMR on EKS 作业规范示例
apiVersion: batch.k8s.amazonaws.com/v1alpha1
kind: Job
metadata:
name: spark-pi
namespace: default
spec:
template:
metadata:
labels:
app-name: spark-pi
spec:
restartPolicy: Never
containers:
- name: spark-pi
image: 123456789012.dkr.ecr.us-east-1.amazonaws.com/spark-pi:latest
imagePullPolicy: Always
command:
- "sh"
- "-c"
- "/opt/spark/bin/spark-submit --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=1 --conf spark.driver.cores=1 local:///opt/spark/examples/jars/spark-examples_2.12-3.1.1.jar 100"
与其他AWS服务的高级集成
EMR的强大之处不仅在于其自身的功能,还在于它与其他AWS服务的无缝集成。这些集成可以帮助你构建更复杂、更强大的数据处理管道。
1. EMR与AWS Glue的集成
AWS Glue是一个全托管的ETL(提取、转换、加载)服务,可以与EMR配合使用,简化数据准备和加载过程。
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
# 创建 Glue context
glueContext = GlueContext(SparkContext.getOrCreate())
# 从 Glue Data Catalog 中读取数据
datasource = glueContext.create_dynamic_frame.from_catalog(
database = "your_glue_database",
table_name = "your_glue_table"
)
# 进行数据转换
transformed = datasource.apply_mapping([("old_col1", "string", "new_col1", "string"),
("old_col2", "int", "new_col2", "int")])
# 将结果写回 S3
glueContext.write_dynamic_frame.from_options(
frame = transformed,
connection_type = "s3",
connection_options = {"path": "s3://your-bucket/output-path/"},
format = "parquet"
)
2. EMR与Amazon Athena的集成
Amazon Athena是一种交互式查询服务,可以直接查询存储在S3中的数据。EMR可以与Athena配合使用,实现更复杂的数据分析流程。
import boto3
# 创建 Athena 客户端
athena_client = boto3.client('athena')
# 执行查询
query = "SELECT * FROM your_table WHERE condition"
response = athena_client.start_query_execution(
QueryString=query,
QueryExecutionContext={
'Database': 'your_database'
},
ResultConfiguration={
'OutputLocation': 's3://your-bucket/athena-results/'
}
)
# 获取查询结果
query_execution_id = response['QueryExecutionId']
result = athena_client.get_query_results(QueryExecutionId=query_execution_id)
# 在 EMR 中处理 Athena 查询结果
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("AthenaResultProcessing").getOrCreate()
df = spark.read.parquet("s3://your-bucket/athena-results/" + query_execution_id + ".csv")
# 进行进一步处理...
3. EMR与Apache Kafka的集成
Apache Kafka是一个高吞吐量的分布式发布订阅消息系统,常用于构建实时数据管道。EMR可以与Kafka无缝集成,实现实时数据处理。
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col
from pyspark.sql.types import StructType, StringType
# 创建SparkSession
spark = SparkSession.builder \
.appName("EMRKafkaIntegration") \
.getOrCreate()
# 定义schema
schema = StructType().add("id", StringType()).add("value", StringType())
# 从Kafka读取数据
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "broker1:9092,broker2:9092") \
.option("subscribe", "test-topic") \
.load()
# 解析JSON数据
parsed_df = df.select(
from_json(col("value").cast("string"), schema).alias("parsed_value")
)
# 处理数据
result = parsed_df.select(col("parsed_value.id"), col("parsed_value.value"))
# 将结果写入S3
query = result \
.writeStream \
.outputMode("append") \
.format("parquet") \
.option("path", "s3://your-bucket/kafka-output/") \
.option("checkpointLocation", "s3://your-bucket/checkpoints/") \
.start()
query.awaitTermination()
4. EMR与Apache Flink的集成
Apache Flink是一个强大的流处理框架,EMR 6.4.0及以上版本支持Flink作为托管应用程序。这使得在EMR上运行Flink作业变得非常简单。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
public class EMRFlinkJob {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile("s3://your-bucket/input-data/");
DataStream<String> filtered = text.filter(new FilterFunction<String>() {
public boolean filter(String value) {
return value.contains("EMR");
}
});
filtered.writeAsText("s3://your-bucket/output-data/");
env.execute("Flink job on EMR");
}
}
5. EMR与Apache Airflow的集成
Apache Airflow是一个强大的工作流管理平台,可以用来调度和管理EMR作业。
from airflow import DAG
from airflow.providers.amazon.aws.operators.emr_create_job_flow import EmrCreateJobFlowOperator
from airflow.providers.amazon.aws.sensors.emr_job_flow import EmrJobFlowSensor
from airflow.utils.dates import days_ago
DEFAULT_ARGS = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': days_ago(1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1
}
JOB_FLOW_OVERRIDES = {
'Name': 'EMR-Airflow-Job',
'ReleaseLabel': 'emr-6.3.0',
'Applications': [{'Name': 'Spark'}],
'Instances': {
'InstanceGroups': [
{
'Name': 'Master node',
'Market': 'ON_DEMAND',
'InstanceRole': 'MASTER',
'InstanceType': 'm5.xlarge',
'InstanceCount': 1,
}
],
'KeepJobFlowAliveWhenNoSteps': False,
'TerminationProtected': False,
},
'Steps': [
{
'Name': 'Run Spark job',
'ActionOnFailure': 'TERMINATE_CLUSTER',
'HadoopJarStep': {
'Jar': 'command-runner.jar',
'Args': ['spark-submit', '--deploy-mode', 'cluster', 's3://your-bucket/your-job.py'],
},
}
],
}
with DAG(
'emr_job_flow_dag',
default_args=DEFAULT_ARGS,
description='A simple EMR job DAG',
schedule_interval=None,
) as dag:
create_job_flow = EmrCreateJobFlowOperator(
task_id='create_job_flow',
job_flow_overrides=JOB_FLOW_OVERRIDES,
aws_conn_id='aws_default',
emr_conn_id='emr_default',
)
check_job_flow = EmrJobFlowSensor(
task_id='check_job_flow',
job_flow_id="{{ task_instance.xcom_pull(task_ids='create_job_flow', key='return_value') }}",
aws_conn_id='aws_default',
)
create_job_flow >> check_job_flow
高级应用场景
随着你对EMR的深入了解,你可以开始尝试一些更加复杂和高级的应用场景。这些场景通常涉及多个AWS服务的协同工作,以及更复杂的数据处理逻辑。
1. 实时数据处理管道
构建一个实时数据处理管道,包括数据摄取、处理和存储的全过程。
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col
from pyspark.sql.types import StructType, StructField, StringType, TimestampType
# 创建 Spark Session
spark = SparkSession.builder \
.appName("RealTimeDataPipeline") \
.getOrCreate()
# 定义 schema
schema = StructType([
StructField("id", StringType()),
StructField("timestamp", TimestampType()),
StructField("data", StringType())
])
# 从 Kinesis 读取流数据
kinesis_stream = spark \
.readStream \
.format("kinesis") \
.option("streamName", "your-stream-name") \
.option("endpointUrl", "https://kinesis.us-east-1.amazonaws.com") \
.option("startingPosition", "latest") \
.load()
# 解析 JSON 数据
parsed_stream = kinesis_stream \
.select(from_json(col("data").cast("string"), schema).alias("parsed_data")) \
.select("parsed_data.*")
# 进行一些转换
processed_stream = parsed_stream \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(col("timestamp"), "5 minutes"),
col("id")
) \
.count()
# 将结果写入 S3
query = processed_stream \
.writeStream \
.outputMode("append") \
.format("parquet") \
.option("path", "s3://your-bucket/stream-output/") \
.option("checkpointLocation", "s3://your-bucket/checkpoints/") \
.start()
query.awaitTermination()
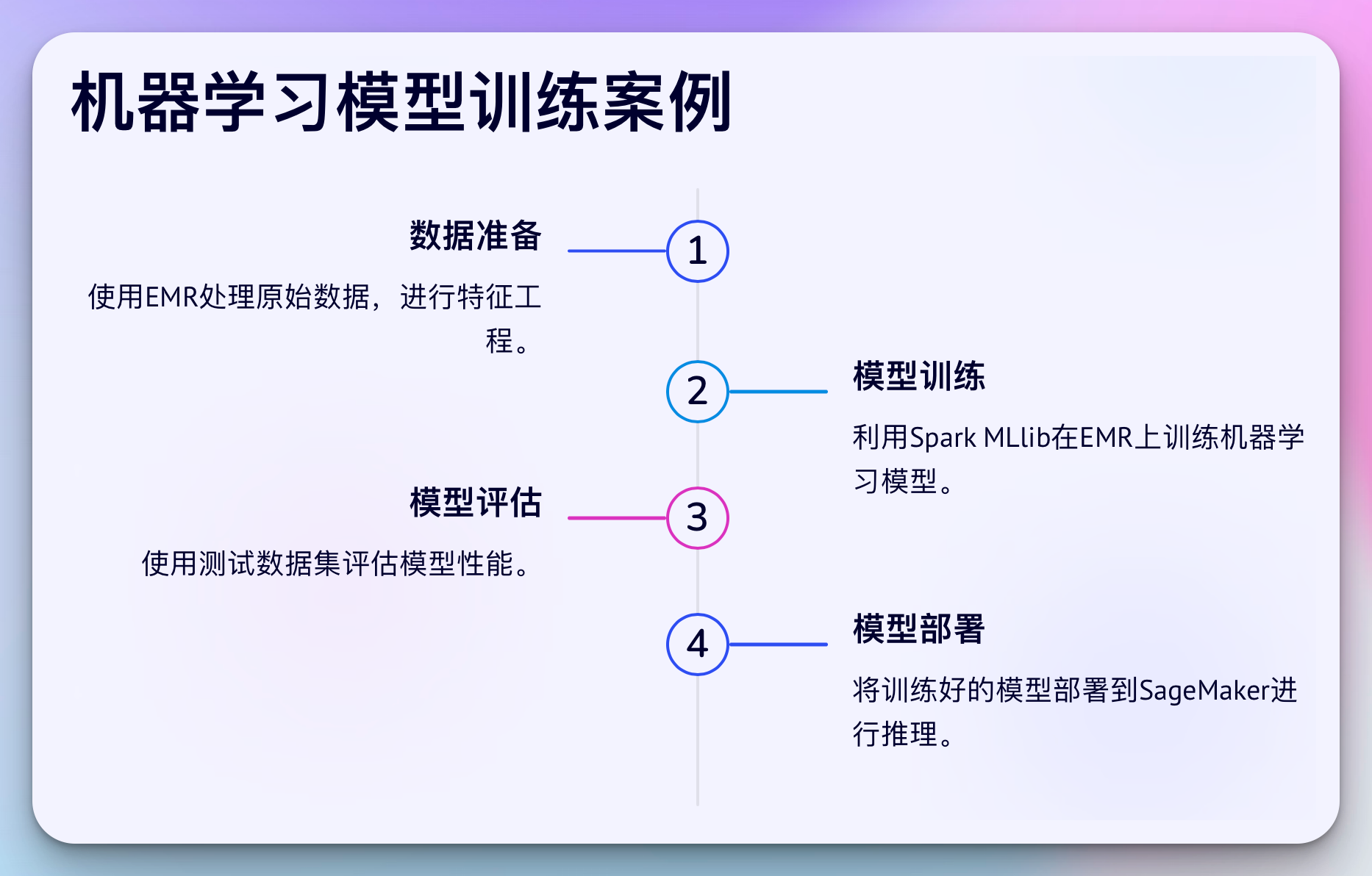
2. 机器学习模型训练和部署
使用EMR处理大规模数据,训练机器学习模型,然后将模型部署到SageMaker进行推理。
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml import Pipeline
import sagemaker
from sagemaker.spark.preprocessing import SparkMLSageMakerEstimator
# 准备数据
data = spark.read.parquet("s3://your-bucket/training-data/")
assembler = VectorAssembler(inputCols=["feature1", "feature2", "feature3"], outputCol="features")
rf = RandomForestClassifier(labelCol="label", featuresCol="features")
pipeline = Pipeline(stages=[assembler, rf])
# 训练模型
model = pipeline.fit(data)
# 将模型保存到 S3
model.save("s3://your-bucket/model/")
# 创建 SageMaker 估算器
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
spark_model = SparkMLSageMakerEstimator(
sagemaker_session=sagemaker_session,
role=role,
framework_version='2.4',
instance_type='ml.m4.xlarge',
instance_count=1
)
# 将 Spark ML 模型转换为 SageMaker 模型
sagemaker_model = spark_model.fit(model)
# 部署模型
predictor = sagemaker_model.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
# 现在你可以使用 predictor 进行预测
EMR 运维
EMR运维实战经验
在实际工作中,运维EMR集群可能会遇到各种挑战。以下是一些实际运维经验和最佳实践:
1. 集群规划与成本优化
- 合理规划集群大小:根据工作负载动态调整集群大小,避免资源浪费。
- 使用实例集:混合使用按需实例和Spot实例可以显著降低成本。
# 使用AWS CLI创建使用实例集的EMR集群
aws emr create-cluster \
--name "MySpotCluster" \
--release-label emr-6.3.0 \
--instance-fleets file://instance-fleets.json \
--ec2-attributes file://ec2-attributes.json \
--service-role EMR_DefaultRole \
--applications Name=Spark Name=Hive Name=Pig
instance-fleets.json 文件示例:
[
{
"InstanceFleetType": "MASTER",
"TargetOnDemandCapacity": 1,
"InstanceTypeConfigs": [
{"InstanceType": "m5.xlarge"}
]
},
{
"InstanceFleetType": "CORE",
"TargetOnDemandCapacity": 1,
"TargetSpotCapacity": 1,
"InstanceTypeConfigs": [
{"InstanceType": "r5.2xlarge", "WeightedCapacity": 1},
{"InstanceType": "r4.2xlarge", "WeightedCapacity": 1}
]
}
]
2. 监控与告警
设置全面的监控和告警系统,及时发现和解决问题:
- 使用CloudWatch监控EMR集群的关键指标
- 设置SNS通知,在关键事件发生时及时通知运维人员
# 使用AWS CLI创建CloudWatch告警
aws cloudwatch put-metric-alarm \
--alarm-name "EMR_ClusterStatus" \
--metric-name "IsIdle" \
--namespace "AWS/ElasticMapReduce" \
--statistic "Average" \
--period 300 \
--threshold 1 \
--comparison-operator "GreaterThanOrEqualToThreshold" \
--evaluation-periods 3 \
--alarm-actions arn:aws:sns:us-east-1:123456789012:EMR-Alerts \
--dimensions Name=JobFlowId,Value=j-XXXXXXXXXXXXX
3. 日志管理
合理管理和分析日志对于问题排查至关重要:
- 将EMR日志持久化到S3
- 使用EMR Log Analysis工具或Elasticsearch进行日志分析
# 配置EMR将日志写入S3
aws emr create-cluster \
--name "LoggingCluster" \
--release-label emr-6.3.0 \
--log-uri s3://my-bucket/logs/ \
# 其他参数...
常见陷阱及解决方案
在使用EMR的过程中,有一些常见的陷阱需要注意。以下是一些典型问题及其解决方案:
1. 数据倾斜问题
症状:某些任务执行时间远长于其他任务,导致整体作业延迟。
解决方案:
- 使用Salting技术重新分区数据
- 使用Spark的
repartition或coalesce函数重新分布数据
// Spark中处理数据倾斜的示例
val skewedRDD = sc.parallelize(List((1, "a"), (1, "b"), (1, "c"), (2, "d"), (3, "e")))
val saltedRDD = skewedRDD.map(x => (x._1 + "_" + Random.nextInt(3), x._2))
val result = saltedRDD.reduceByKey(_ + _).map(x => (x._1.split("_")(0), x._2))
2. 内存溢出
症状:任务失败,日志中出现OutOfMemoryError。
解决方案:
- 增加执行器内存
- 优化代码以减少内存使用
# 设置Spark执行器内存
--conf spark.executor.memory=8g
3. 小文件问题
症状:大量小文件导致性能下降。
解决方案:
- 使用合并小文件的技术
- 使用Spark的
coalesce或repartition函数
// Spark中合并小文件的示例
val data = spark.read.parquet("s3://my-bucket/small-files/")
val mergedData = data.coalesce(10)
mergedData.write.parquet("s3://my-bucket/merged-files/")
高级调优技巧
要充分发挥EMR的性能,需要进行一些高级调优。以下是一些技巧:
1. Spark调优
- 合理设置分区数:分区数通常设置为集群总核心数的2-3倍
- 优化shuffle操作:使用适当的join策略,如broadcast join
// Spark调优示例
spark.conf.set("spark.sql.shuffle.partitions", 200)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 10*1024*1024) // 10MB
2. YARN调优
- 合理分配内存:设置合适的
yarn.nodemanager.resource.memory-mb和yarn.scheduler.maximum-allocation-mb - 优化容器分配:调整
yarn.scheduler.capacity.maximum-am-resource-percent
<!-- yarn-site.xml 配置示例 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>122880</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>122880</value>
</property>
3. 存储优化
- 使用列式存储格式:如Parquet或ORC
- 合理设置压缩:选择适当的压缩算法,如Snappy
// Spark中使用Parquet格式和Snappy压缩
df.write.option("compression", "snappy").parquet("s3://my-bucket/output/")
EMR安全最佳实践
在使用EMR时,安全性是一个不容忽视的问题。以下是一些安全最佳实践:
1. 网络安全
- 使用VPC和安全组限制网络访问
- 启用传输加密(in-transit encryption)
# 创建启用加密的EMR集群
aws emr create-cluster \
--security-configuration MySecurityConfiguration \
# 其他参数...
2. 数据安全
- 启用S3服务器端加密
- 使用AWS KMS管理密钥
// EMR安全配置示例
{
"EncryptionConfiguration": {
"AtRestEncryptionConfiguration": {
"S3EncryptionConfiguration": {
"EncryptionMode": "SSE-S3"
}
},
"InTransitEncryptionConfiguration": {
"TLSCertificateConfiguration": {
"CertificateProviderType": "PEM",
"S3Object": "s3://MyConfigStore/artifacts/MyCerts.zip"
}
}
}
}
3. 访问控制
- 使用IAM角色进行细粒度的权限控制
- 启用Kerberos认证
# 创建启用Kerberos的EMR集群
aws emr create-cluster \
--kerberos-attributes file://kerberos-attributes.json \
# 其他参数...
EMR实际案例研究
让我们通过一些实际的案例研究来看看EMR如何在真实世界中解决问题。
案例1:大规模日志分析系统
背景:一家大型电商公司需要分析其网站的访问日志,以优化用户体验和提高转化率。
挑战:
- 每天产生数TB的日志数据
- 需要实时处理和分析
- 需要灵活的查询能力
解决方案:
- 使用Kinesis Firehose将日志实时传输到S3
- 使用EMR运行Spark Streaming作业,从S3读取数据并进行实时处理
- 将处理后的数据存储在Amazon Redshift中,用于进一步分析
- 使用Amazon QuickSight创建仪表板,实现数据可视化
关键代码片段:
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col, window
spark = SparkSession.builder.appName("LogAnalysis").getOrCreate()
# 读取S3数据
logs = spark \
.readStream \
.format("json") \
.option("path", "s3://your-bucket/logs/") \
.load()
# 处理数据
processed_logs = logs \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(col("timestamp"), "5 minutes"),
col("page")
) \
.count()
# 写入Redshift
query = processed_logs \
.writeStream \
.outputMode("append") \
.format("jdbc") \
.option("url", "jdbc:redshift://your-cluster.redshift.amazonaws.com:5439/dev") \
.option("dbtable", "processed_logs") \
.option("user", "username") \
.option("password", "password") \
.start()
query.awaitTermination()
结果:
- 实现了近实时的日志分析,延迟降低到分钟级
- 显著提高了数据分析的灵活性
- 通过数据驱动的决策,提高了网站转化率5%
案例2:大规模机器学习模型训练
背景:一家金融科技公司需要训练一个复杂的机器学习模型来预测信用风险。
挑战:
- 海量的历史交易数据(数百TB)
- 复杂的特征工程过程
- 需要频繁更新模型
解决方案:
- 使用EMR处理和转换原始数据,进行特征工程
- 使用EMR上的Spark MLlib训练机器学习模型
- 将训练好的模型部署到SageMaker进行推理
- 使用Step Functions编排整个工作流
关键代码片段:
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.evaluation import BinaryClassificationEvaluator
spark = SparkSession.builder.appName("CreditRiskPrediction").getOrCreate()
# 读取数据
data = spark.read.parquet("s3://your-bucket/credit-data/")
# 特征工程
assembler = VectorAssembler(inputCols=["age", "income", "credit_score"], outputCol="features")
data = assembler.transform(data)
# 分割数据
train, test = data.randomSplit([0.8, 0.2], seed=12345)
# 训练模型
rf = RandomForestClassifier(labelCol="risk", featuresCol="features", numTrees=100)
model = rf.fit(train)
# 评估模型
predictions = model.transform(test)
evaluator = BinaryClassificationEvaluator(labelCol="risk")
auc = evaluator.evaluate(predictions)
print(f"AUC: {auc}")
# 保存模型
model.save("s3://your-bucket/models/credit-risk-model")
结果:
- 模型训练时间从原来的一周缩短到了几个小时
- 模型精度提高了10%
- 能够每天更新模型,显著提高了风险预测的准确性
未来趋势和技能发展建议
随着大数据和云计算技术的快速发展,EMR也在不断演进。以下是一些值得关注的趋势和相应的技能发展建议:
-
无服务器和容器化
- 趋势:EMR Serverless和EKS on EMR的发展表明,无服务器和容器化是未来的趋势。
- 建议:深入学习Docker和Kubernetes,了解无服务器架构的概念和最佳实践。
-
机器学习和AI的深度集成
- 趋势:EMR与SageMaker的集成越来越紧密,大规模机器学习将成为EMR的一个重要应用场景。
- 建议:学习机器学习和深度学习的基础知识,掌握Spark MLlib和TensorFlow等框架的使用。
-
实时处理的需求增加
- 趋势:越来越多的应用场景要求实时或近实时的数据处理能力。
- 建议:深入学习Spark Streaming、Flink等流处理技术,了解Lambda架构和Kappa架构。
-
多云和混合云
- 趋势:企业越来越倾向于采用多云或混合云策略,以避免厂商锁定。
- 建议:了解不同云平台的大数据服务,学习如何在多云环境中构建和管理数据管道。
-
数据治理和安全
- 趋势:随着数据规模的增长和法规的收紧,数据治理和安全变得越来越重要。
- 建议:学习数据治理的最佳实践,了解GDPR等数据保护法规,掌握加密、访问控制等安全技术。
-
GraphX和图数据处理
- 趋势:图数据处理在社交网络分析、推荐系统等领域的应用越来越广泛。
- 建议:学习图论基础,掌握Spark GraphX等图处理框架的使用。
-
自动化和DataOps
- 趋势:自动化和DataOps实践将大大提高数据工程的效率。
- 建议:学习CI/CD、基础设施即代码(IaC)等概念和工具,如Jenkins、Terraform等。
-
数据湖和数据网格
- 趋势:数据湖和数据网格架构正在改变企业的数据管理方式。
- 建议:了解数据湖和数据网格的概念和最佳实践,学习相关技术如Delta Lake、Hudi等。
要跟上这些趋势,建议采取以下学习策略:
- 持续学习:定期阅读AWS的博客和文档,关注大数据社区的最新动态。
- 动手实践:不断尝试新的服务和功能,通过实际项目来巩固所学知识。
- 参与社区:加入相关的开源项目,参与讨论,贡献代码。
- 考取认证:考取AWS的相关认证,如AWS Certified Big Data - Specialty。
- 跨领域学习:除了技术知识,还要学习一些领域知识,如金融、医疗等,以便更好地

结语
通过这篇全面而深入的指南,我们不仅探索了EMR的理论知识,还深入讨论了实际运维经验、常见陷阱及其解决方案,以及高级调优技巧。这个学习之旅展示了EMR的复杂性和强大功能,同时也体现了"糙快猛"学习方法在面对实际工作挑战时的实用性。
作为一名大数据开发者,掌握EMR不仅需要了解其基本概念和使用方法,还需要在实践中不断积累经验,学会解决各种复杂问题。记住,每一个你遇到并解决的问题,都是你宝贵的学习经验。
在这个数据驱动的时代,EMR为我们提供了强大的工具来处理和分析海量数据。但工具终究是工具,真正的价值在于你如何使用它来解决实际问题,创造商业价值。
希望这篇博客不仅能成为你学习EMR的指南,还能成为你在实际工作中的参考手册。无论你是刚开始接触大数据,还是已经是经验丰富的开发者,我相信你都能在这里找到有价值的信息。
让我们继续在这个数据的海洋中探索,用EMR这艘强大的航母去征服更多的挑战,创造更多的可能!记住,在大数据的世界里,学习永无止境,而你,已经踏上了一个激动人心的旅程!
思维导图
同系列文章
用粗快猛 + 大模型问答 + 讲故事学习方式快速掌握大数据技术知识,每篇都有上万字,如果觉得太长,看开始的20%,有所收获就够了,剩下的其他内容可以收藏后再看~
-
Hadoop
-
Spark
-
MySQL
-
Kafka
-
Flink
-
Airflow
-
Hbase
-
Linux





![MySql性能调优05-[sql实战演练]](https://i-blog.csdnimg.cn/direct/e748cd8471fc40deb406961389e82973.png)