ICML 2024最近也放榜啦!今年共有10篇论文夺得最佳论文奖,包括火爆的Stable Diffusion 3、谷歌VideoPoet以及世界模型Genie。

ICML是国际机器学习顶会,也是CCF-A类学术会议。今年这届顶会一共收到了9473篇论文,其中2610篇被录用,录用率27.55%,和去年相差不大。
从录用论文的主题来看,今年的热门方向主要有大模型、强化学习、GNN等,如果有同学想发paper,可以参考一下。
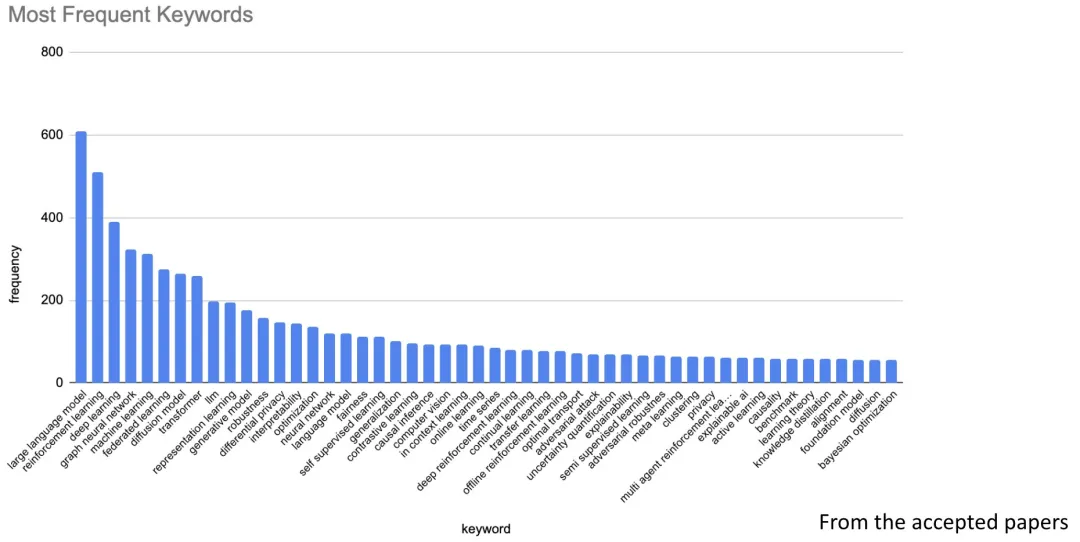
为助力想要冲顶会的同学,我整理好了ICML 这些热门方向的录用论文65篇供大家学习,当然也包括ICML 2024获奖论文,已经开源的代码也一并整理了。
论文原文+开源代码需要的同学看文末
下面让我们来看看最佳论文都有哪些吧,时间原因只介绍部分,不过可参考的创新点我做了提炼,方便同学们学习~
ICML 2024 最佳论文
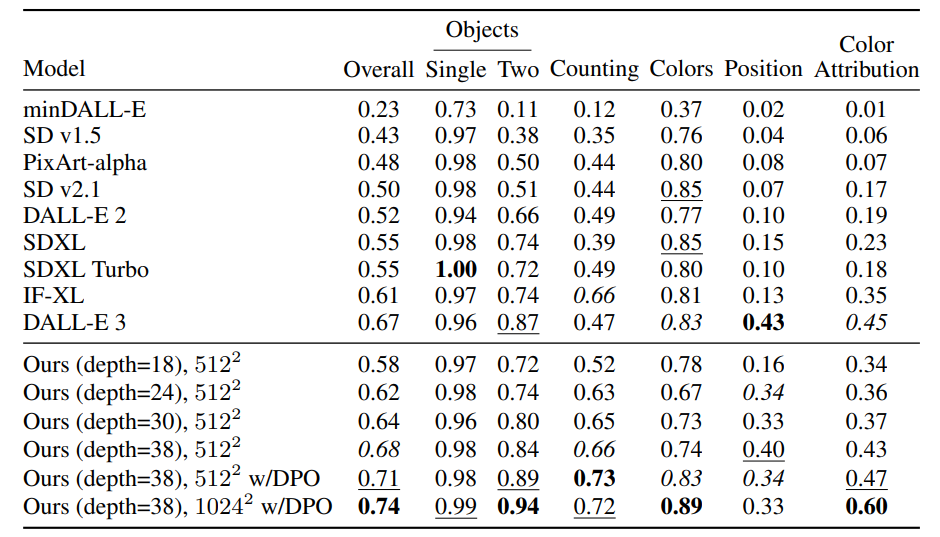
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
方法:Stable Diffusion 3的论文。作者通过对比已有扩散公式,展示了本方法在高分辨率文本到图像合成上的优越性,此外,提出了一种基于Transformer的文本到图像生成架构,使用两个模态的独立权重,实现了图像和文本之间的双向信息流,提高了文本理解、排版和人类偏好评分。
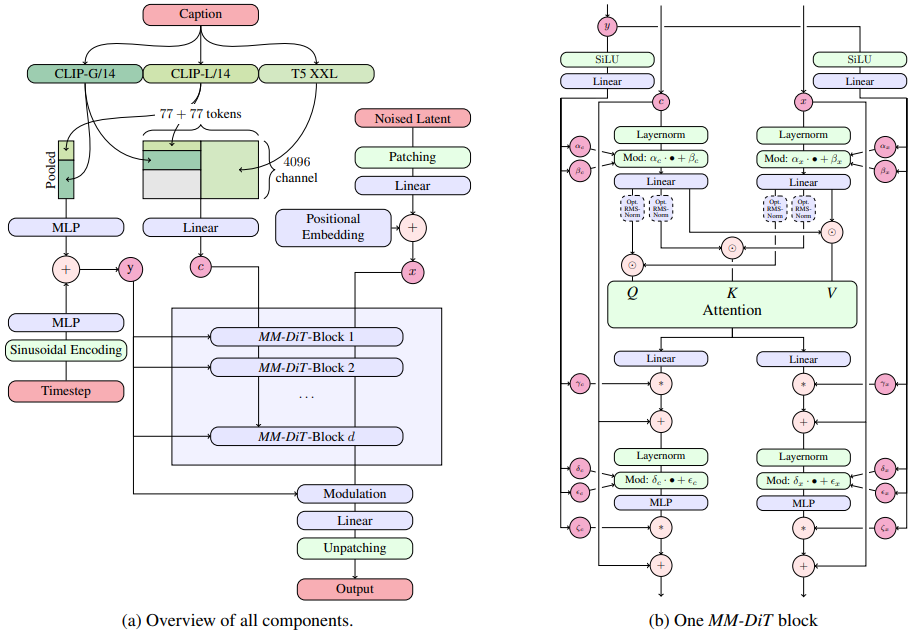
创新点:
-
提出了一种改进的Rectified Flow模型,通过新的噪声采样方法提高了模型性能,并与其他扩散模型进行了比较,表明其优势。
-
提出了一种新的文本到图像合成的架构,通过双向信息流实现了图像和文本之间的混合,提高了文本理解、排版和人工评估的性能。
-
进行了一系列的规模化研究,验证了模型的可扩展性,并发现验证损失的降低与改进的文本到图像性能之间存在强相关性。
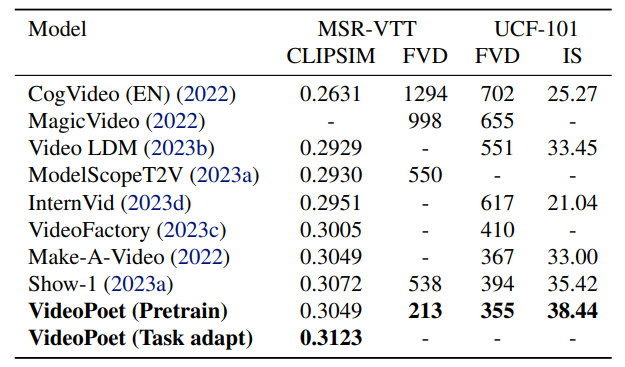
VideoPoet: A Large Language Model for Zero-Shot Video Generation
方法:论文介绍了一种使用大型语言模型(LLM)进行视频生成的方法。该模型名为VideoPoet,采用了仅有解码器的Transformer架构,可以处理多模态输入,包括图像、视频、文本和音频,并在生成质量和任务适应性方面取得了竞争性的结果。
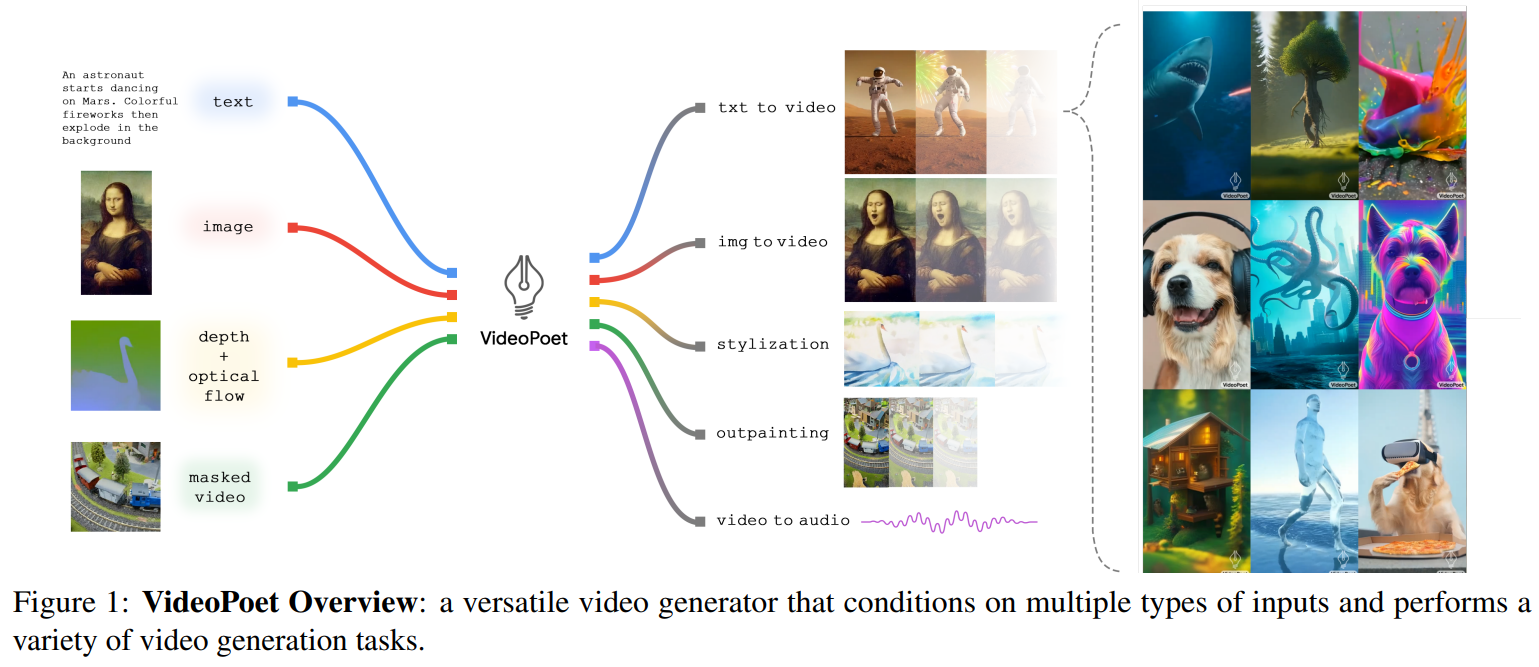
创新点:
-
通过使用大型语言模型进行视频生成,提出了一种有效的视频生成和相关任务的方法。
-
模型由三个组件组成:模态特定的tokenizer、语言模型骨干和超分辨率模块。
-
模型具有零样本生成能力,可以处理与训练数据分布不同的新输入。
-
模型可以执行多个任务,包括文本到视频生成、图像到视频生成和视频编辑等。
Genie: Generative Interactive Environments
方法:论文的研究目标是提出一种新的生成式人工智能模型Genie,通过从互联网视频中学习生成交互式环境,使用户能够创建和探索虚拟世界,为生成模型提供更多的交互性和参与度。
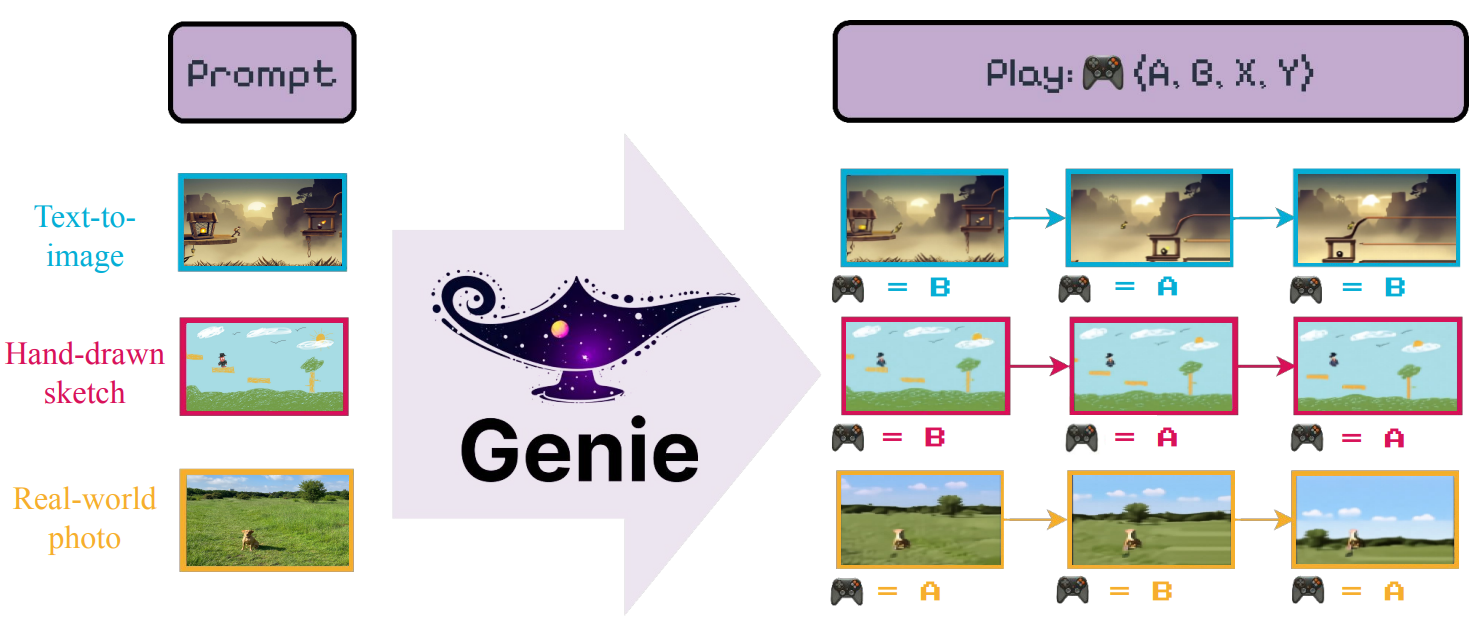
创新点:
-
Genie是第一个在无监督方式下,从无标签的互联网视频中训练生成的交互式环境。它能够根据文本、图像、草图和其他提示生成可操作的虚拟世界。
-
Genie使用了一个潜在动作模型,该模型推断出每一对帧之间潜在的动作,允许逐帧控制生成的环境。
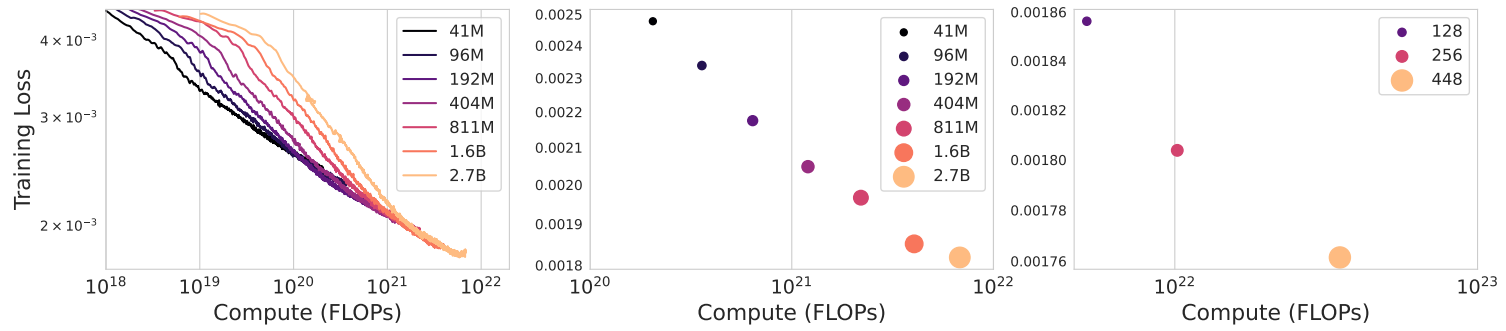
Debating with More Persuasive LLMs Leads to More Truthful Answers
方法:论文探讨了辩论作为一种方法,如何使大型语言模型(LLMs)在缺乏真实标注数据的情况下,通过较弱模型(非专家)评估较强模型(专家)的输出来达到更准确的答案。研究者们通过在QuALITY阅读理解任务中实施辩论,发现这种方法能够有效帮助非专家模型和人类回答者提高答案的准确性。
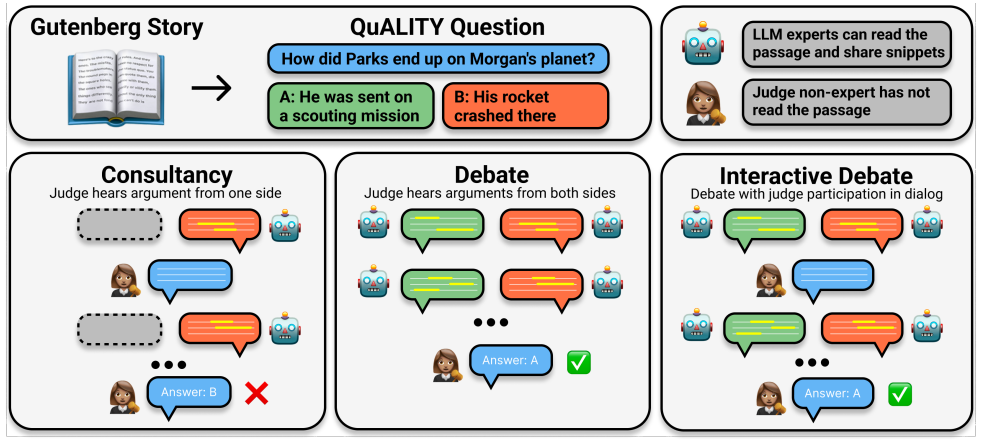
创新点:
-
提出了一种新的方法,使用辩论来评估和提高大型语言模型(LLMs)的输出质量,特别是在没有真实标注数据的情况下。
-
研究了非专家(较弱的模型)如何通过辩论机制有效地监督和评估专家(较强的模型)的答案,即使非专家本身不具备访问问题上下文的能力。
-
提供了一种无监督的方法来评估辩论者的表现,不需要依赖于地面真实标签,这对于评估模型输出的准确性是创新的。
另外几篇最佳论文就不一一介绍了,我都整理在了ICML 热门方向录用论文合集中,希望能给各位的论文加把劲!
关注下方《学姐带你玩AI》🚀🚀🚀
回复“ICML奖”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏




![MySql性能调优05-[sql实战演练]](https://i-blog.csdnimg.cn/direct/e748cd8471fc40deb406961389e82973.png)