酒店预订订单的分析与建模【决策树、xgboost】
本项目包含
1.数据处理
2.数据探索性分析
3.网格搜索对决策树、xgboost进行模型参数调优
4.基于五折交叉验证的决策树、xgboost模型预测
专栏和往期项目
👉往期文章可以关注我的专栏
下巴同学的数据加油小站
会不定期分享数据挖掘、机器学习、风控模型、深度学习、NLP等方向的学习项目,关注不一定能学到你想学的东西,但是可以学到我想学和正在学的东西😀
往期项目-数据分析建模方向
1.基于线性回归对男性体脂率的预测
2.大五人格测试数据集的探索【可视化+k-means聚类分析】
3.使用线性回归、LGBM对二手车价格进行预测
本文代码、数据点击下方链接可获取:
4.关于酒店预订数据集的探索【EDA+五折交叉验证决策树、xgboost预测】
目录
- 酒店预订订单的分析与建模【决策树、xgboost】
- 本项目包含
- 专栏和往期项目
- 数据与背景描述
- 背景描述
- 数据说明
- 导入并检查数据
- 导入数据
- 检查数据
- EDA
- 数据含义与分析目的
- 数据含义
- 明确目的
- 成人、儿童数目的分析
- 顾客预定天数的分布
- 顾客需求类数据分析
- 日期、时间类型数据分析
- 其他数据分析
- 相关性热力图
- 模型预测
- 特征编码
- 数据处理
- 模型构建
- 五折交叉验证的决策树
- 五折交叉验证的xgboost
数据与背景描述
背景描述
在线酒店预订渠道已经极大地改变了预订的可能性和客户的行为。
酒店预订取消的典型原因包括计划的改变、日程安排的冲突等,对酒店客人来说,因为可以选择免费或最好是低价从而更容易取消预订,但对酒店来说,这是一个不太理想的、可能会减少收入的因素,需要解决的问题。
数据说明
column 列名
Booking_ID 每个预订的唯一标识符
no_of_adults 成人的数量
no_of_children 儿童的数量
no_of_weekend_nights 客人入住或预订入住酒店的周末晚数(周六或周日)
no_of_week_nights 客人在酒店住宿或预订住宿的周晚数(周一至周五)
type_of_meal_plan 客户预订的膳食计划的类型
required_car_parking_space 顾客是否需要一个停车位?(0-不,1-是)
room_type_reserved 顾客预订的房间类型。这些值是由INN酒店集团加密(编码)的
lead_time 预订日期和抵达日期之间的天数
arrival_year 抵达日期的年份
arrival_month 抵达日期的月份
arrival_date 该月的日期
market_segment_type 市场部分的指定
repeated_guest 该客户是否为重复客人?(0 - 否, 1- 是)
no_of_previous_cancellations 在当前预订之前,客户取消的先前预订的数量
no_of_previous_bookings_not_canceled 在当前预订前未被客户取消的先前预订的数量
avg_price_per_room 每天预订的平均价格;房间的价格是动态的。(单位:欧元)
no_of_special_requests 客户提出的特殊要求的总数(例如,高楼层,从房间看风景等)
booking_status 表示预订是否被取消的标志
导入并检查数据
导入数据
import pandas as pd
df = pd.read_csv('/home/mw/input/data9304/Hotel Reservations.csv')
df.head()
检查数据
数据无缺失,无重复
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 36275 entries, 0 to 36274
Data columns (total 19 columns):
Booking_ID 36275 non-null object
no_of_adults 36275 non-null int64
no_of_children 36275 non-null int64
no_of_weekend_nights 36275 non-null int64
no_of_week_nights 36275 non-null int64
type_of_meal_plan 36275 non-null object
required_car_parking_space 36275 non-null int64
room_type_reserved 36275 non-null object
lead_time 36275 non-null int64
arrival_year 36275 non-null int64
arrival_month 36275 non-null int64
arrival_date 36275 non-null int64
market_segment_type 36275 non-null object
repeated_guest 36275 non-null int64
no_of_previous_cancellations 36275 non-null int64
no_of_previous_bookings_not_canceled 36275 non-null int64
avg_price_per_room 36275 non-null float64
no_of_special_requests 36275 non-null int64
booking_status 36275 non-null object
dtypes: float64(1), int64(13), object(5)
memory usage: 5.3+ MB
df.duplicated().sum()
0
EDA
数据含义与分析目的
数据含义
首先看看数据都有哪些
数据一共19列
预定ID,是唯一标识符,仅用于区分数据
顾客数量有两列:成人数量和儿童数量两列
顾客预定天数:分为工作日和周末两列
顾客需求类数据:用餐类型,停车位,房间类型,顾客特殊要求数量四列
日期、时间类型数据:预定与抵达日间隔天数,抵达日期年份、月份,抵达日期四列
预定方法(在线、离线)
是否为历史用户
本次前客户是否取消数目:取消数目、未取消数目两列
预定房价的平均价格
是否被取消(目标变量)
明确目的
然后明确数据探索性分析的目的:我们想找出是否取消预定与上述其他特征是否存在一定的关系。
所以我们可以进行对比分析,这里只进行简单的分析,变量间关系暂不分析
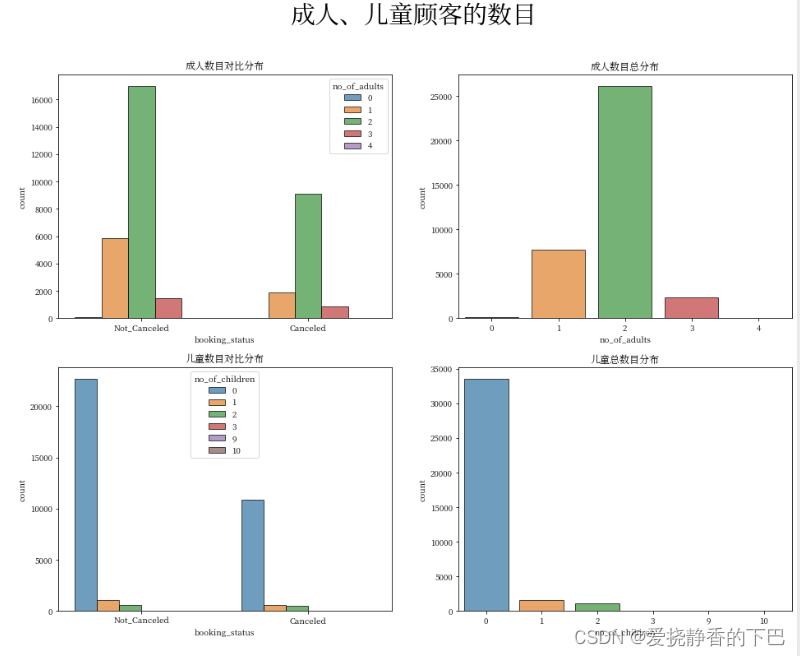
成人、儿童数目的分析
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.figure(figsize = (16, 12))
plt.suptitle("成人、儿童顾客的数目",fontweight="bold", fontsize=30)
plt.subplot(2,2,1)
plt.gca().set_title('成人数目对比分布')
sns.countplot(x = 'booking_status', hue = 'no_of_adults', edgecolor="black", alpha=0.7, data = df)
plt.subplot(2,2,2)
plt.gca().set_title('成人数目总分布')
sns.countplot(x = 'no_of_adults', edgecolor="black", alpha=0.7,data = df)
plt.subplot(2,2,3)
plt.gca().set_title('儿童数目对比分布')
sns.countplot(x = 'booking_status', hue = 'no_of_children', edgecolor="black", alpha=0.7, data = df)
plt.subplot(2,2,4)
plt.gca().set_title('儿童总数目分布')
sns.countplot(x = 'no_of_children', edgecolor="black", alpha=0.7,data = df)
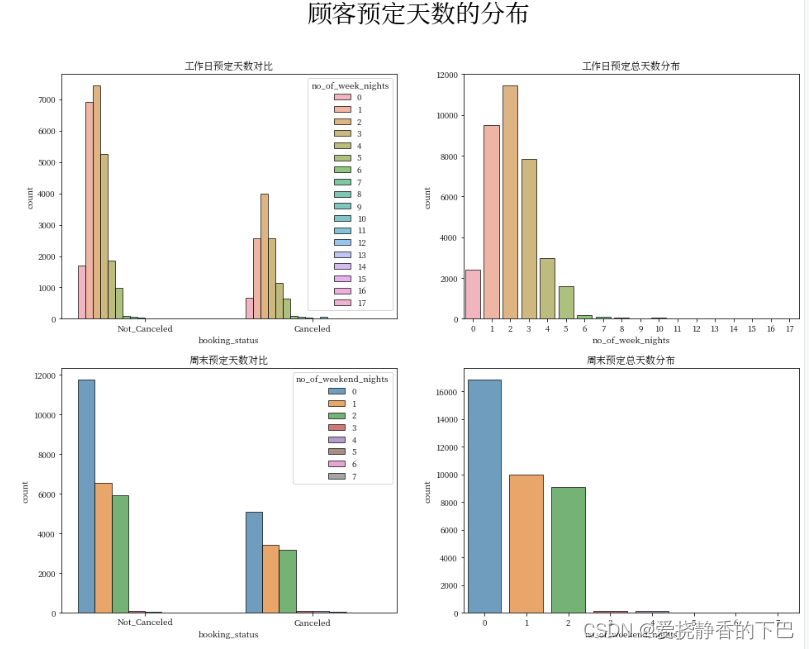
顾客预定天数的分布
plt.figure(figsize = (16, 12))
plt.suptitle("顾客预定天数的分布",fontweight="bold", fontsize=30)
plt.subplot(2,2,1)
plt.gca().set_title('工作日预定天数对比')
sns.countplot(x = 'booking_status', hue = 'no_of_week_nights', edgecolor="black", alpha=0.7, data = df)
plt.subplot(2,2,2)
plt.gca().set_title('工作日预定总天数分布')
sns.countplot(x = 'no_of_week_nights', edgecolor="black", alpha=0.7,data = df)
plt.subplot(2,2,3)
plt.gca().set_title('周末预定天数对比')
sns.countplot(x = 'booking_status', hue = 'no_of_weekend_nights', edgecolor="black", alpha=0.7, data = df)
plt.subplot(2,2,4)
plt.gca().set_title('周末预定总天数分布')
sns.countplot(x = 'no_of_weekend_nights', edgecolor="black", alpha=0.7,data = df)
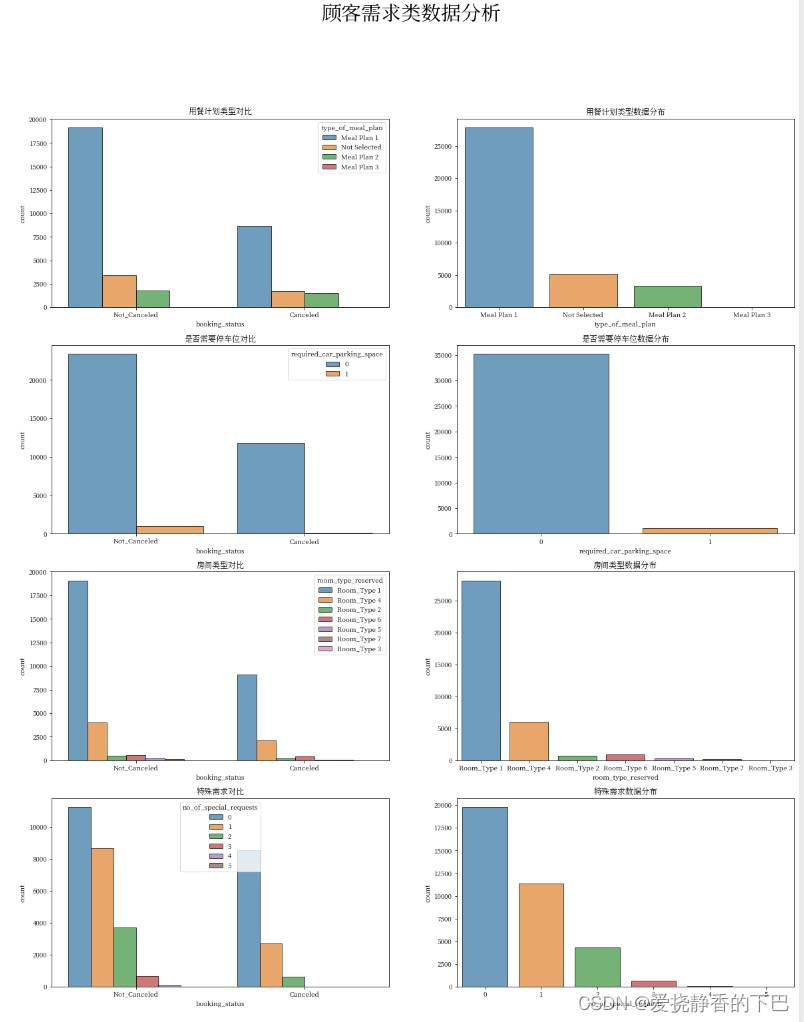
顾客需求类数据分析
plt.figure(figsize = (20, 24))
plt.suptitle("顾客需求类数据分析",fontweight="bold", fontsize=30)
plt.subplot(4,2,1)
plt.gca().set_title('用餐计划类型对比')
sns.countplot(x = 'booking_status', hue = 'type_of_meal_plan', edgecolor="black", alpha=0.7, data = df)
plt.subplot(4,2,2)
plt.gca().set_title('用餐计划类型数据分布')
sns.countplot(x = 'type_of_meal_plan', edgecolor="black", alpha=0.7,data = df)
plt.subplot(4,2,3)
plt.gca().set_title('是否需要停车位对比')
sns.countplot(x = 'booking_status', hue = 'required_car_parking_space', edgecolor="black", alpha=0.7, data = df)
plt.subplot(4,2,4)
plt.gca().set_title('是否需要停车位数据分布')
sns.countplot(x = 'required_car_parking_space', edgecolor="black", alpha=0.7,data = df)
plt.subplot(4,2,5)
plt.gca().set_title('房间类型对比')
sns.countplot(x = 'booking_status', hue = 'room_type_reserved', edgecolor="black", alpha=0.7, data = df)
plt.subplot(4,2,6)
plt.gca().set_title('房间类型数据分布')
sns.countplot(x = 'room_type_reserved', edgecolor="black", alpha=0.7,data = df)
plt.subplot(4,2,7)
plt.gca().set_title('特殊需求对比')
sns.countplot(x = 'booking_status', hue = 'no_of_special_requests', edgecolor="black", alpha=0.7, data = df)
plt.subplot(4,2,8)
plt.gca().set_title('特殊需求数据分布')
sns.countplot(x = 'no_of_special_requests', edgecolor="black", alpha=0.7,data = df)
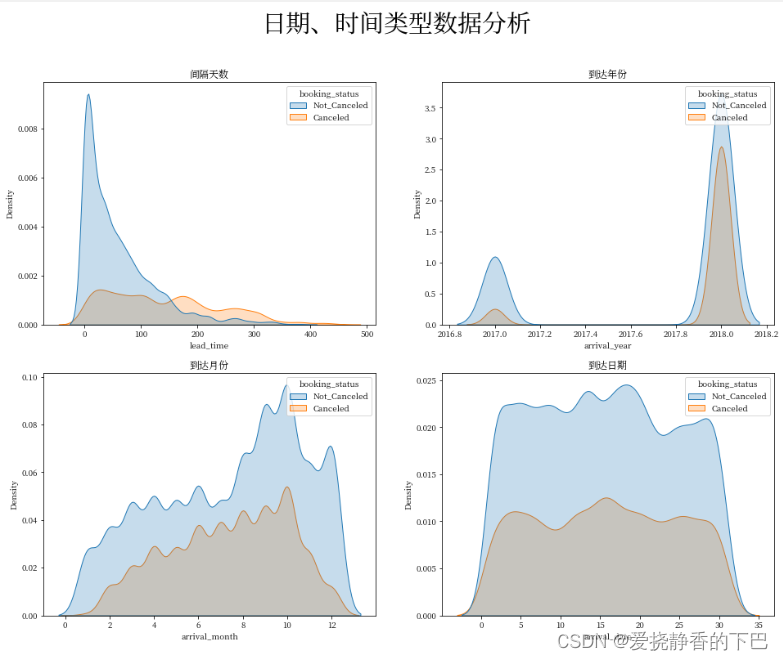
日期、时间类型数据分析
日期、时间类型数据:预定与抵达日间隔天数,抵达日期年份、月份,抵达日期四列
lead_time arrival_year arrival_month arrival_date
plt.figure(figsize = (16, 12))
plt.suptitle("日期、时间类型数据分析",fontweight="bold", fontsize=30)
plt.subplot(2,2,1)
plt.gca().set_title('间隔天数')
sns.kdeplot(x='lead_time', hue='booking_status', shade=True, data=df)
# sns.kdeplot( data=df.lead_time,shade=True)
plt.subplot(2,2,2)
plt.gca().set_title('到达年份')
sns.kdeplot(x='arrival_year', hue='booking_status', shade=True, data=df)
plt.subplot(2,2,3)
plt.gca().set_title('到达月份')
sns.kdeplot(x='arrival_month', hue='booking_status', shade=True, data=df)
plt.subplot(2,2,4)
plt.gca().set_title('到达日期')
sns.kdeplot(x='arrival_date', hue='booking_status', shade=True, data=df)
其他数据分析
预定方法(在线、离线等)market_segment_type
是否为历史用户repeated_guest
本次前客户是否取消数目:取消数目、未取消数目两列no_of_previous_cancellations、no_of_previous_bookings_not_canceled
预定房价的平均价格avg_price_per_room
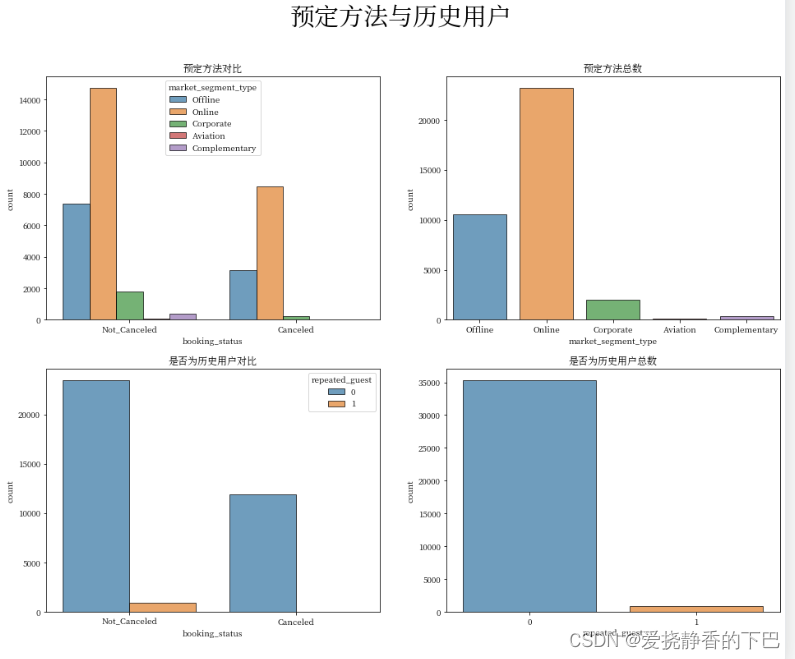
plt.figure(figsize = (16, 12))
plt.suptitle("预定方法与历史用户",fontweight="bold", fontsize=30)
plt.subplot(2,2,1)
plt.gca().set_title('预定方法对比')
sns.countplot(x = 'booking_status', hue = 'market_segment_type', edgecolor="black", alpha=0.7, data = df)
plt.subplot(2,2,2)
plt.gca().set_title('预定方法总数')
sns.countplot(x = 'market_segment_type', edgecolor="black", alpha=0.7,data = df)
plt.subplot(2,2,3)
plt.gca().set_title('是否为历史用户对比')
sns.countplot(x = 'booking_status', hue = 'repeated_guest', edgecolor="black", alpha=0.7,data = df)
plt.subplot(2,2,4)
plt.gca().set_title('是否为历史用户总数')
sns.countplot(x = 'repeated_guest', edgecolor="black", alpha=0.7,data = df)
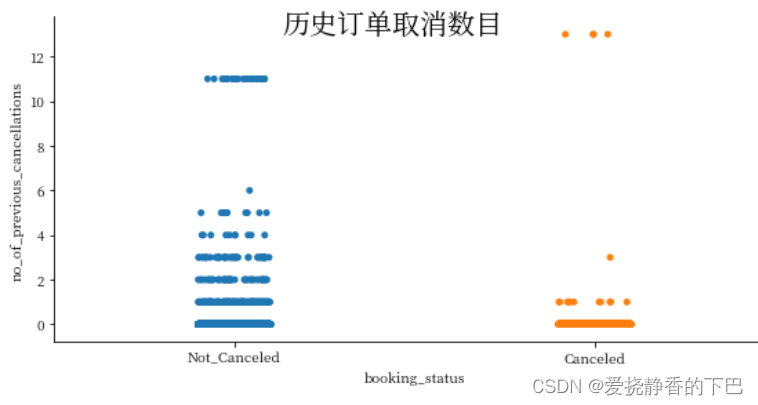
ax = sns.catplot('booking_status', 'no_of_previous_cancellations',height=4, aspect=2, data=df)
ax.fig.suptitle("历史订单取消数目",
fontsize=20, fontdict={"weight": "bold"})
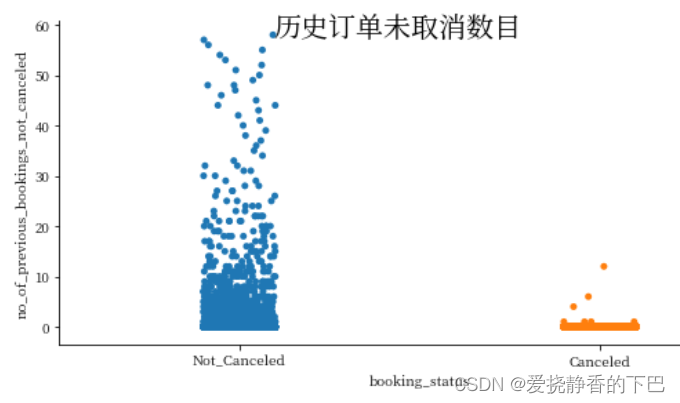
ax2 = sns.catplot('booking_status', 'no_of_previous_bookings_not_canceled',height=4, aspect=2, data=df)
ax2.fig.suptitle("历史订单未取消数目",
fontsize=20, fontdict={"weight": "bold"})
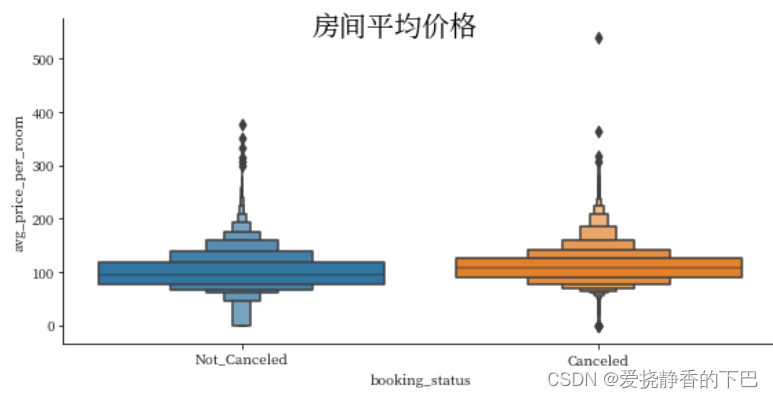
ax3 = sns.catplot('booking_status', 'avg_price_per_room', kind="boxen",height=4, aspect=2, data=df)
ax3.fig.suptitle("房间平均价格",
fontsize=20, fontdict={"weight": "bold"})
相关性热力图
plt.figure(figsize=(24,16))
ax = sns.heatmap(df.corr(), square=True, annot=True, fmt='.2f')
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
bottom, top = ax.get_ylim()
ax.set_ylim(bottom + 0.5, top - 0.5)
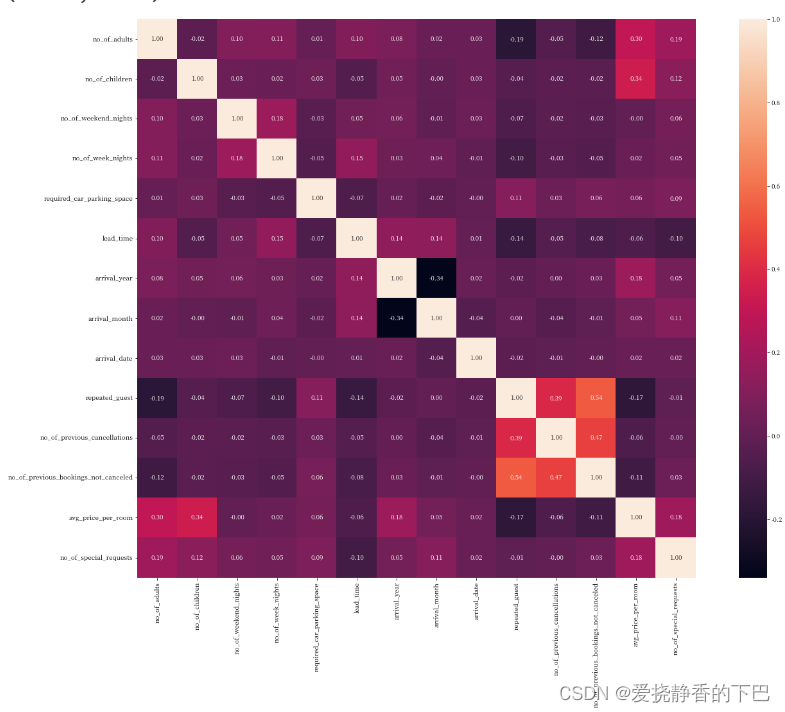
模型预测
特征编码
df = df.drop('Booking_ID', axis = 1)
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
for feat in ['type_of_meal_plan', 'room_type_reserved','market_segment_type','booking_status']:
lbl = LabelEncoder()
lbl.fit(df[feat])
df[feat] = lbl.transform(df[feat])
df.head()
数据处理
X = df.drop('booking_status', axis = 1)
X = X.values
y = df['booking_status']
y.sum()/len(y)
0.6723638869745003
模型构建
五折交叉验证的决策树
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold,RepeatedKFold
import numpy as np
from sklearn.metrics import confusion_matrix,classification_report
from sklearn.metrics import roc_curve,roc_auc_score
from sklearn.tree import DecisionTreeClassifier
param = {'criterion':['gini', 'entropy'],
'splitter':['best', 'random'],
'max_depth': range(1,10,2),
'min_samples_leaf': range(1,10,2)
}
gs = GridSearchCV(estimator=DecisionTreeClassifier(), param_grid=param, cv=5, scoring="roc_auc", n_jobs=-1, verbose=10)
gs.fit(X,y)
print(gs.best_params_)
Fitting 5 folds for each of 100 candidates, totalling 500 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 2 concurrent
workers. [Parallel(n_jobs=-1)]: Done 1 tasks | elapsed: 1.6s
[Parallel(n_jobs=-1)]: Done 4 tasks | elapsed: 1.7s
[Parallel(n_jobs=-1)]: Done 9 tasks | elapsed: 1.7s
[Parallel(n_jobs=-1)]: Done 14 tasks | elapsed: 1.8s
[Parallel(n_jobs=-1)]: Batch computation too fast (0.1818s.) Setting
batch_size=2. [Parallel(n_jobs=-1)]: Batch computation too fast
(0.0935s.) Setting batch_size=8. [Parallel(n_jobs=-1)]: Done 23 tasks
| elapsed: 2.0s [Parallel(n_jobs=-1)]: Done 67 tasks |
elapsed: 3.0s [Parallel(n_jobs=-1)]: Done 139 tasks | elapsed:
5.1s [Parallel(n_jobs=-1)]: Done 211 tasks | elapsed: 7.7s [Parallel(n_jobs=-1)]: Done 299 tasks | elapsed: 10.1s
[Parallel(n_jobs=-1)]: Done 387 tasks | elapsed: 12.7s
{‘criterion’: ‘gini’, ‘max_depth’: 9, ‘min_samples_leaf’: 7,
‘splitter’: ‘best’} [Parallel(n_jobs=-1)]: Done 500 out of 500 |
elapsed: 17.2s finished
n_fold = 5
folds = KFold(n_splits=n_fold, shuffle=True, random_state=2022)
oof_dt = np.zeros(len(X))
for fold_n, (train_index, valid_index) in enumerate(folds.split(X)):
X_train, X_valid = pd.DataFrame(X).iloc[train_index], pd.DataFrame(X).iloc[valid_index]
y_train, y_valid = y[train_index], y[valid_index]
eval_set = [(X_valid, y_valid)]
model_dt= DecisionTreeClassifier(
max_depth=9,criterion='gini',splitter='best',min_samples_leaf = 7,random_state=2022
).fit(X_train,y_train)
y_pred_valid = model_dt.predict(X_valid)
oof_dt[valid_index] = y_pred_valid.reshape(-1, )
print(roc_auc_score(y, oof_dt))
0.8417716385830245
print(classification_report(y, oof_dt))
precision recall f1-score support
0 0.82 0.76 0.79 11885
1 0.89 0.92 0.90 24390
accuracy 0.87 36275
macro avg 0.86 0.84 0.85 36275
weighted avg 0.87 0.87 0.87 36275
五折交叉验证的xgboost
from xgboost import XGBClassifier
param = {'max_depth': [9,12,15],
'learning_rate': [0.05,0.1],
'n_estimators': [500,700,900]
}
gs = GridSearchCV(estimator=XGBClassifier(), param_grid=param, cv=3, scoring="roc_auc", n_jobs=-1, verbose=10)
gs.fit(X,y)
print(gs.best_params_)
Fitting 3 folds for each of 18 candidates, totalling 54 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 2 concurrent workers.
[Parallel(n_jobs=-1)]: Done 1 tasks | elapsed: 26.1s
[Parallel(n_jobs=-1)]: Done 4 tasks | elapsed: 1.0min
[Parallel(n_jobs=-1)]: Done 9 tasks | elapsed: 3.0min
[Parallel(n_jobs=-1)]: Done 14 tasks | elapsed: 4.5min
[Parallel(n_jobs=-1)]: Done 21 tasks | elapsed: 8.0min
[Parallel(n_jobs=-1)]: Done 28 tasks | elapsed: 12.0min
[Parallel(n_jobs=-1)]: Done 37 tasks | elapsed: 14.6min
[Parallel(n_jobs=-1)]: Done 46 tasks | elapsed: 18.7min
[Parallel(n_jobs=-1)]: Done 54 out of 54 | elapsed: 23.1min finished
{'learning_rate': 0.05, 'max_depth': 12, 'n_estimators': 500}
n_fold = 5
folds = KFold(n_splits=n_fold, shuffle=True, random_state=2022)
oof_xgb = np.zeros(len(X))
for fold_n, (train_index, valid_index) in enumerate(folds.split(X)):
X_train, X_valid = pd.DataFrame(X).iloc[train_index], pd.DataFrame(X).iloc[valid_index]
y_train, y_valid = y[train_index], y[valid_index]
eval_set = [(X_valid, y_valid)]
model_xgb = XGBClassifier(
max_depth=12,learning_rate=0.05,n_estimators=500,random_state=2022
).fit(X_train,y_train,early_stopping_rounds=100, eval_metric="auc",eval_set=eval_set, verbose=True)
y_pred_valid = model_xgb.predict(X_valid)
oof_xgb[valid_index] = y_pred_valid.reshape(-1, )
print(roc_auc_score(y, oof_xgb))
0.8807500918930099
print(classification_report(y, oof_xgb))
precision recall f1-score support
0 0.87 0.82 0.85 11885
1 0.92 0.94 0.93 24390
accuracy 0.90 36275
macro avg 0.89 0.88 0.89 36275
weighted avg 0.90 0.90 0.90 36275