结构体大小
【题目名称】
在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是( C ) 对齐数是取其较小值
struct A
{
int a;
short b;
int c;
char d;
};
struct B
{
int a;
short b;
char c;
int d;
};
【题目内容】
A. 16,16
B. 13,12
C. 16,12
D. 11,16
下面是A
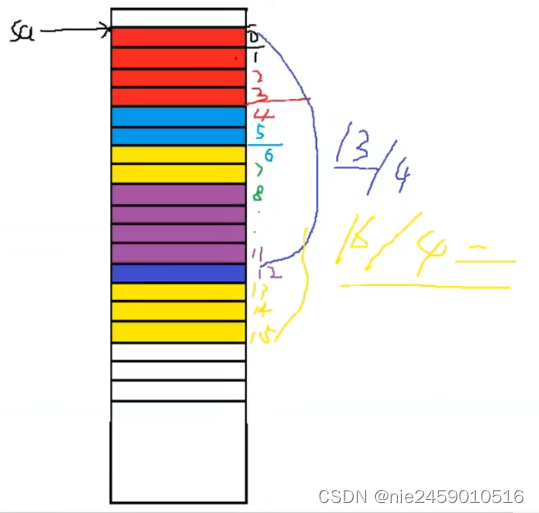
下面是B 黄色的是浪费的因为7不是默认对齐数的整数倍

最后在求出总体最大整数倍与刚刚的12对比 4是12整数倍
#include <stdio.h>
#pragma pack(4) //设置对齐数
struct A
{
int a;
short b;
int c;
char d;
};
struct B
{
int a;
short b;
char c;
int d;
};
#pragma pack()
int main()
{
struct A sa = {0};
struct B sb = { 0 };
printf("%d\n", sizeof(sa));
printf("%d\n", sizeof(sb));
return 0;
}
输出结果为16 12
【题目名称】
下面代码的结果是:( A )
#pragma pack(4)/*编译选项,表示4字节对齐 平台:VS2013。语言:C语言*/
int main(int argc, char* argv[])
{
struct tagTest1
{
short a;
char d;
long b;
long c;
};
struct tagTest2
{
long b;
short c;
char d;
long a;
};
struct tagTest3
{
short c;
long b;
char d;
long a;
};
struct tagTest1 stT1;
struct tagTest2 stT2;
struct tagTest3 stT3;
printf("%d %d %d", sizeof(stT1), sizeof(stT2), sizeof(stT3));
return 0;
}
#pragma pack()
【题目内容】
A. 12 12 16
B. 11 11 11
C. 12 11 16
D. 11 11 16
tagTest1

Test2
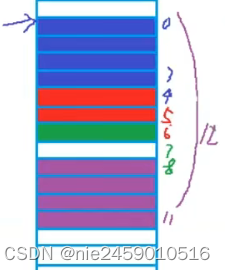
Test3
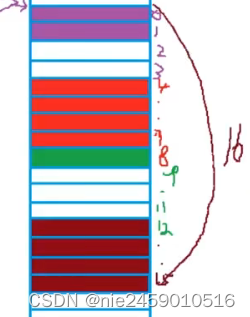
【题目名称】
有如下宏定义和结构定义
#define MAX_SIZE A+B
struct _Record_Struct
{
unsigned char Env_Alarm_ID : 4;
unsigned char Para1 : 2;
unsigned char state;
unsigned char avail : 1;
}*Env_Alarm_Record;
struct _Record_Struct *pointer = (struct _Record_Struct*)malloc
(sizeof(struct _Record_Struct) * MAX_SIZE);
当A=2, B=3时,pointer分配( D)个字节的空间。
【题目内容】
A. 20
B. 15
C. 11
D. 9
以上分析如下
#define MAX_SIZE A+B
struct _Record_Struct
{
unsigned char Env_Alarm_ID : 4;//位段 char是一个字节 一个字节8bit位 他用了四个还剩4个
unsigned char Para1 : 2;//剩下的4个他用两个
unsigned char state;//不是位段成员所以直接但一个字节
unsigned char avail : 1;//再开辟一个字节用一个bit位。
//所以上面的这个位段结构体大小为三个字节
}*Env_Alarm_Record;
struct _Record_Struct* pointer = (struct _Record_Struct*)malloc
(sizeof(struct _Record_Struct) * 2+3);//6乘2加3 所以这题结果为9
【题目名称】
下面代码的结果是( )
int main()
{
unsigned char puc[4];
struct tagPIM
{
unsigned char ucPim1;
unsigned char ucData0 : 1;
unsigned char ucData1 : 2;
unsigned char ucData2 : 3;
}*pstPimData;
pstPimData = (struct tagPIM*)puc; //puc数组名表示数组首元素地址 把他强制类型转换指针 这个指针相当于指向数组puc
memset(puc,0,4);//把这四个字节全部设置为0 相当于32个0 如下图
pstPimData->ucPim1 = 2;
pstPimData->ucData0 = 3;
pstPimData->ucData1 = 4;
pstPimData->ucData2 = 5;
printf("%02x %02x %02x %02x\n",puc[0], puc[1], puc[2], puc[3]);
return 0;
}
【题目内容】
A. 02 03 04 05
B. 02 29 00 00
C. 02 25 00 00
D. 02 29 04 00

pstPimData->ucPim1 = 2; 放进去一个2 他的二进制序列是00000010
** unsigned char ucData0 : 1;
unsigned char ucData1 : 2;
unsigned char ucData2 : 3;**
这是一个位段成员 8个bit位 相当于在上图第二个框框里,占用6个所以,后面两个是用不到的
注意 !!! 位段使用的空间的时候是从低位到高位开始使用的
第一步放3 3是00000011 但是他只能占一个bit位 所以3放完后第二个框框变成00000001
第二步放4 他是00000100 占两个bit位所以放2个0 框框变成00000001
第三步放5 他的二进制序列0000101 占3个bit位所以放101 框框变成00101001
pstPimData->ucData0 = 3;
pstPimData->ucData1 = 4;
pstPimData->ucData2 = 5;
unsigned char ucData0 : 1;
unsigned char ucData1 : 2;
unsigned char ucData2 : 3;
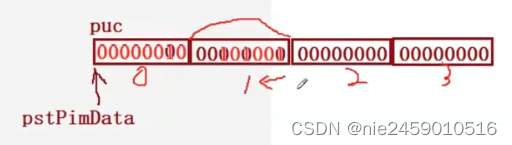
printf("%02x %02x %02x %02x\n",puc[0], puc[1], puc[2], puc[3]); 上图对应这个代码
%02x 以16进制输出只输出两位
2进制位转换为16进制位 4个二进制位是一个16进制位
0000 0010
0 2 上面2进制转化为2进制就是02
0010 1001
2 9
【题目名称】 本题考查联合体大小
下面代码的结果是:(c )
#include <stdio.h>
union Un
{
short s[7];//14 联合体最小也是那个最大值的大小 联合体存在对齐 s对齐数是2 因为就算对齐数是8也是2
int n;//4 自身大小为4 默认对齐数为8 所以对齐数是4.
所以以上两个对其实2 和4 最大对齐数是4
联合体总大小必须是最大对齐数的整数倍 14不是4的 所以浪费两个字节变16
};
int main()
{
printf("%d\n", sizeof(union Un));
return 0;
}
【题目内容】
A. 14
B. 4
C. 16
D. 18
【题目名称】
在X86下,有下列程序
#include<stdio.h>
int main()
{
union
{
short k;
char i[2];
}*s, a;
s = &a;
s->i[0] = 0x39;
s->i[1] = 0x38;
printf(“%x\n”,a.k);
return 0;
}
输出结果是( A)
【题目内容】
A. 3839
B. 3938
C. 380039
D. 不确定

当前题目存在大小端问题
vs是小端存储 低位数据放在低地址处
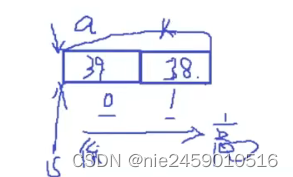
i[0] 39是低地址 i[1]是高地址,低地址放在低位字节序,高地址放在高位字节序,所以是 38 39
【题目名称】
下面代码的结果是:( B)
enum ENUM_A//枚举类型
{
X1,//0
Y1,//1
Z1 = 255,
A1,//256
B1,//257
};
enum ENUM_A enumA = Y1;
enum ENUM_A enumB = B1;
printf("%d %d\n", enumA, enumB);
【题目内容】
A. 1, 4
B. 1, 257
C. 2, 257
D. 2, 5
【题目名称】
在VS2013下,这个结构体所占的空间大小是(c )字节
typedef struct{
int a;
char b;
short c;
short d;
}AA_t;
【题目内容】
A. 16
B. 9
C. 12
D. 8
typedef struct {
int a;//0-3
char b;//4
//5 - 浪费
short c;//6-7
short d;//8-9
//10-11
//12字节
}AA_t;
int main()
{
printf("%d\n", sizeof(AA_t));
return 0;
}
动态内存
【题目名称】
关于动态内存函数的说法错误的是:( CD)
【题目内容】
A. malloc函数向内存申请一块连续的空间,并返回起始地址
B. malloc申请空间失败,返回NULL指针
C. malloc可以向内存申请0字节的空间
D. malloc申请的内存空间,不进行释放也不会对程序有影响
【题目名称】
动态申请的内存在内存的那个区域?( B)
【题目内容】
A. 栈区
B. 堆区
C. 静态区
D. 文字常量区
【题目名称】
关于动态内存相关函数说法错误的是:( D )
【题目内容】
A. malloc函数和calloc函数的功能是相似的,都是申请一块连续的空间。
B. malloc函数申请的空间不初始化,calloc函数申请的空间会被初始化为0
C. realloc函数可以调整动态申请内存的大小,可大可小
D. free函数不可以释放realloc调整后的空间
动态内存管理
【题目名称】
关于下面代码描述正确的是(C )
char *GetMemory(void)
{
char p[] = "hello world";
return p;
}
void Test(void)
{
char *str = NULL;
str = GetMemory();
printf(str);
}
【题目内容】
A. printf函数使用有问题
B. 程序正常打印hello world
C. GetMemory函数返回的地址无法正常使用 因为数组除了当前函数就会销毁
D. 程序存在内存泄露 只有申请了malloc后才会存在内存泄漏
【题目名称】
关于下面代码描述不正确的是:A
void GetMemory(char *p)
{
p = (char *)malloc(100);
}
void Test(void)
{
char *str = NULL;
GetMemory(str);
strcpy(str, "hello world");
printf(str);
}
【题目内容】
A. 上面代码没问题
B. 上面代码存在内存泄露 因为malloc没有free
C. 上面代码可能会崩溃,即使GetMemory函数返回,str依然为NULL
D. GetMemory函数无法把malloc开辟的100个字节带回来
【题目名称】
以下哪个不是动态内存的错误( A)
【题目内容】
A. free参数为NULL
B. 对非动态内存的free释放
C. 对动态内存的多次释放
D. 对动态内存的越界访问
【题目名称】
模拟实现atoi 把一个字符串转化为一个整形的函数
【题目内容】
模拟实现atoi
#include <stdlib.h>
int main()
{
char* p = "1234";
int ret = atoi(p);
printf("%d\n", ret);
return 0;
}//打印结果为1234
以上是库里边的原理 接下来模拟实现
#include <stdlib.h>
#include <stdio.h>
#include <assert.h>
#include <ctype.h>
#include <limits.h>
enum State
{
INVALID,//0 非法
VALID //1 合法
};
state 记录的是my_atoi 返回的值是合法转化的值,还是非法的状态
enum State state = INVALID;
int my_atoi(const char* s)
{
int flag = 1;
//assert(NULL != s);
//
//空指针
if (NULL == s)
{
return 0;
}
//空字符
if (*s == '\0')
{
return 0;
}
//跳过空白字符
while (isspace(*s))//判断一个值是不是空白字符
{
s++;
}
//+/-
if (*s == '+')
{
flag = 1;
s++;
}
else if (*s == '-')
{
flag = -1;
s++;
}
//处理数字字符的转换
long long n = 0;
while (isdigit(*s))//判断是不是数字字符
{
n = n * 10 + flag*(*s - '0'); //字符减去字符的到数字
if (n > INT_MAX || n < INT_MIN)//这两个是整形最大值和整形最小值
{
return 0;
}
s++;
}
if (*s == '\0')
{
state = VALID;
return (int)n;
}
else
{
//state = VALID;
//非数字字符的情况
return (int)n;
}
}
int main()
{
//1. 空指针
//2. 空字符串
//3. 遇到了非数字字符 比如abc
//4. 超出范围 比如int大小是4 结果多了很多
//const char* p = "-123111111111111111111111111111111111111";
//"0"
//int ret = my_atoi(p);
const char* p = " -123a";
int ret = my_atoi(p);
if (state == VALID)
printf("正常的转换:%d\n", ret);
else
printf("非法的转换:%d\n", ret);
return 0;
}
【题目名称】
找单身狗
【题目内容】
一个数组中只有两个数字是出现一次,其他所有数字都出现了两次。
编写一个函数找出这两个只出现一次的数字。
//一个数组中只有两个数字是出现一次,其他所有数字都出现了两次。
//编写一个函数找出这两个只出现一次的数字。
//1 2 3 4 5 6 1 2 3 4
//
void Find(int arr[], int sz, int *px, int* py)
{
//1. 要把所有数字异或
int i = 0;
int ret = 0;
for (i = 0; i < sz; i++)
{
ret ^= arr[i];
}
//2. 计算ret的哪一位为1
//ret = 3
//011
int pos = 0;
for (i = 0; i < 32; i++)
{
if (((ret >> i) & 1) == 1)
{
pos = i;
break;
}
}
//把从低位向高的第pos位为1放一个组,为0的放在另外一个组。
int num1 = 0;
int num2 = 0;
for (i = 0; i < sz; i++)
{
if (((arr[i] >> pos) & 1) == 1)
{
num1 ^= arr[i];
}
else
{
num2 ^= arr[i];
}
}
*px = num1;
*py = num2;
}
//
int main()
{
//1 3 5 1 3 5 和6的二进制序列 101 110得出来的这4行。前两行是2禁止序列最后一位为1和0的 第3 4数0 和1的
//2 2 4 4 6
//
//1 4 1 4 5
//2 2 3 3 6
int arr[] = { 1,2,3,4,5,6,1,2,3,4 };
//101 5的二进制序列
//110 6的
//011
//1^2^3^4^5^6^1^2^3^4 = 5^6 = 3 != 0 相同两个数字异或结果为0 0和任意一个数字异或还是他自己
//
//1 3 1 3 5
//2 4 2 4 6
//1. 分组
//2. 分组的要点:5和6必须在不同的组
//
//找出这两个只出现一次的数字
int sz = sizeof(arr) / sizeof(arr[0]);
int x = 0;
int y = 0;
//传进去x,y的地址
//返回型参数
Find(arr, sz, &x, &y);
printf("%d %d\n", x, y);
return 0;
}
文件操作
【题目名称】
C语言以二进制方式打开一个文件的方法是?( C )
【题目内容】
A. FILE *f = fwrite( “test.bin”, “b” ); b是二进制但是不知道是读还是写
B. FILE *f = fopenb( “test.bin”, “w” ); w是文本形式
C. FILE *f = fopen( “test.bin”, “wb” );二进制写
D. FILE *f = fwriteb( “test.bin” );
【题目名称】
关于fopen函数说法不正确的是:( C )
【题目内容】
A. fopen打开文件的方式是"r",如果文件不存在,则打开文件失败
B. fopen打开文件的方式是"w",如果文件不存在,则创建该文件,打开成功
C. fopen函数的返回值无需判断
D. fopen打开的文件需要fclose来关闭
【题目名称】
下列关于文件名及路径的说法中错误的是:( B )
【题目内容】
A. 文件名中有一些禁止使用的字符
B. 文件名中一定包含后缀名
C. 文件的后缀名决定了一个文件的默认打开方式
D. 文件路径指的是从盘符到该文件所经历的路径中各符号名的集合
【题目名称】
C语言中关于文件读写函数说法不正确的是:( B )
【题目内容】
A. fgetc是适用于所有输入流字符输入函数
B. getchar也是适用于所有流的字符输入函数
C. fputs是适用于所有输出流的文本行输出函数
D. fread是适用于文件输入流的二进制输入函数
【题目名称】
下面程序的功能是什么? (B )
int main()
{
long num=0;
FILE *fp = NULL;
if((fp=fopen("fname.dat","r"))==NULL)
{
printf("Can’t open the file! ");
exit(0);退出意思
}
while(fgetc(fp) != EOF)
{
num++;
}
printf("num=%d\n",num);
fclose(fp);
return 0;
}
【题目内容】
A. 拷贝文件
B. 统计文件的字符数
C. 统计文件的单词数
D. 统计文件的行数
程序编译和链接
【题目名称】
下面说法不正确的是:(D )
【题目内容】
A. scanf和printf是针对标准输入、输出流的格式化输入、输出语句
B. fscanf和fprintf是针对所有输入、输出流的格式化输入、输出语句
C. sscanf是从字符串中读取格式化的数据
D. sprintf是把格式化的数据写到输出流中 写到一个字符串里
【题目名称】
( A ) 的作用是将源程序文件进行处理,生成一个中间文件,编译系统将对此中间文件进行编译并生成目标代码。
【题目内容】
A. 编译预处理 将源程序文件进行处理
B. 汇编
C. 生成安装文件
D. 编译
【题目名称】
由多个源文件组成的C程序,经过编辑、预处理、编译、链接等阶段会生成最终的可执行程序。下面哪个阶段可以发现被调用的函数未定义?(C )
【题目内容】
A. 预处理
B. 编译
C. 链接
D. 执行
【题目名称】
test.c文件中包括如下语句:
#define INT_PTR int* //这句的意思是凡是遇到INT_PTR替换成 int*
typedef int*int_ptr;
INT_PTR a,b; // int*a,b; b是整形变量
int_ptr c,d; //但是下面这个只是把int*从新起了个名字交int_ptr。他是独立的 一个类型 拿这个类型所创建的c d变量类型一样的。他就像float double一样
文件中定义的四个变量,哪个变量不是指针类型?( B )
【题目内容】
A. a
B. b
C. c
D. d
【题目名称】
关于feof函数描述不正确的是:( A)
【题目内容】
A. feof函数是用来判断文件是否读取结束的 结束后判断什么原因结束的
B. feof函数是在文件读取结束的时候,检测是否是因为遇到了文件结束标志EOF,而读取结束
C. 读取文本判断是否结束时,fgetc看返回值是否为EOF, fgets看返回值是否为NULL
D. 二进制文件判断读取结束,看实际读取个数是否小于要求读取个数
预处理
【题目名称】
下面哪个不是预处理指令:( D )
【题目内容】
A. #define
B. #if
C. #undef
D. #end #endif才是
【题目名称】
下面哪个不是预定义符号?(D )
【题目内容】
A. FILE
B. TIME
C. DATE
D. MAIN
【题目名称】
C语言头文件中的 ifndef/define/endif 的作用?( A )
【题目内容】
A. 防止头文件重复引用
B. 规范化代码
C. 标志被引用文件内容中可以被共享的代码
D. 以上都不正确
【题目名称】
设有以下宏定义:
#define N 4
#define Y(n) ((N+2)*n) /这种定义在编程规范中是严格禁止的/
则执行语句:z = 2 * (N + Y(5+1));后,z的值为( D)
【题目内容】
A. 出错
B. 60
C. 48
D. 70
#define N 4
#define Y(n) ((N+2)*n) /*这种定义在编程规范中是严格禁止的*/
int main()
{
int z = 2 * (N + Y(5 + 1));
printf("%d\n", z);
return 0;
}
【题目名称】
下面代码执行的结果是:( B)
#define A 2+2
#define B 3+3
#define C A*B
int main()
{
printf("%d\n", C);
return 0;
}
【题目内容】
A. 24
B. 11
C. 10
D. 23
【题目名称】
下面哪个不是宏和函数的区别?( C )
【题目内容】
A. 函数可以递归,宏不能递归
B. 函数参数有类型检查,宏参数无类型检查
C. 函数的执行速度更快,宏的执行速度慢相反了
D. 由于宏是通过替换完成的,所以操作符的优先级会影响宏的求值,应该尽量使用括号明确优先级
【题目名称】
下面哪个是条件编译指令( B)
【题目内容】
A. #define
B. #ifdef
C. #pragma
D. #error
【题目名称】
以下关于头文件,说法正确的是( D)
【题目内容】
A. #include,编译器寻找头文件时,会从当前编译的源文件所在的目录去找
B. #include“filename.h”,编译器寻找头文件时,会从通过编译选项指定的库目录去找
C. 多个源文件同时用到的全局整数变量,它的声明和定义都放在头文件中,是好的编程习惯
D. 在大型项目开发中,把所有自定义的数据类型、函数声明都放在一个头文件中,各个源文件都只需要包含这个头文件即可,省去了要写很多#include语句的麻烦,是好的编程习惯。
【题目名称】
交换奇偶位
【题目内容】
写一个宏,可以将一个整数的二进制位的奇数位和偶数位交换。
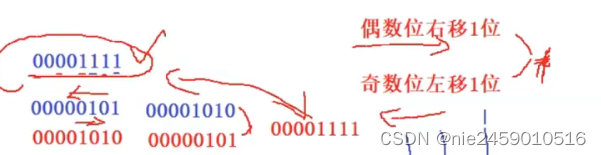
//写一个宏,可以将一个整数的二进制位的奇数位和偶数位交换。
#define SWAP(N) ((N & 0xaaaaaaaa)>>1) + ((N & 0x55555555) << 1)
int main()
{
//10
//00000000000000000000000000001010
int num = 10;
int ret = SWAP(num);
//int ret = ((num & 0xaaaaaaaa)>>1) + ((num & 0x55555555) << 1);
printf("%d\n", ret);
return 0;
}
【题目名称】
offsetof宏
【题目内容】
写一个宏,计算结构体中某变量相对于首地址的偏移,并给出说明
考察:offsetof宏的实现
写一个宏,计算结构体中某变量相对于首地址的偏移,并给出说明
#include <stddef.h>
struct A
{
int a;
short b;
int c;
char d;
};
#define OFFSETOF(struct_name, mem_name) (int)&(((struct_name*)0)->mem_name)
int main()
{
printf("%d\n", OFFSETOF(struct A, a));
printf("%d\n", OFFSETOF(struct A, b));
printf("%d\n", OFFSETOF(struct A, c));
printf("%d\n", OFFSETOF(struct A, d));
return 0;
}