WebRTC 同时使用基于丢包的带宽估计算法和基于延迟的带宽估计算法那,能够实现更加全面和准确的带宽评估和控制。基于丢包的带宽估计算法主要依据网络中的丢包情况来动态调整带宽估计,以适应网络状况的变化。本文主要讲解最新 LossBasedBweV2 的实现。
1. 静态结构
LossBasedBweV2 的静态结构比较简单,如下图所示。LossBasedBweV2 被包含在 SendSideBandwidthEstimation 之中,GoogCcNetworkController 不直接与 LossBasedBweV2 打交道,而是通过 SendSideBandwidthEstimation 获取最终带宽估计值。LossBasedBweV2 静态结构虽然简单,但其内部实现一点都不简单,做好心理准备。
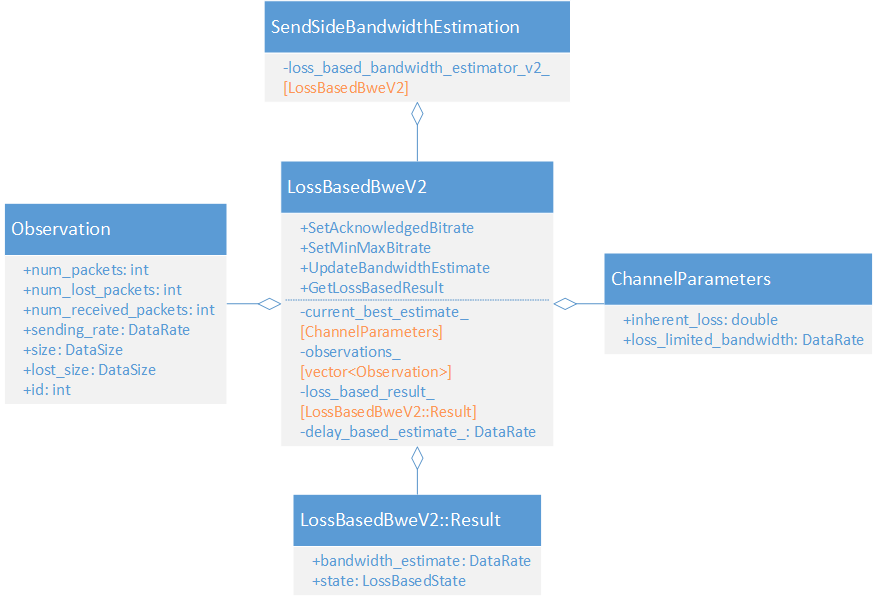
2. 重要属性
1)current_best_estimate_
从候选估计值中选择的当前最佳估计值,包含带宽估计值和链路固有丢包率。
struct ChannelParameters {
// 链路固有丢包率(非带宽受限导致的丢包率)
double inherent_loss = 0.0;
// 丢包限制下的带宽
DataRate loss_limited_bandwidth = DataRate::MinusInfinity();
};2)observations_
历史观测值集合。一个 Observation 代表一个观测值:发送码率和丢包率,估计算法中会用到。
struct Observation {
bool IsInitialized() const { return id != -1; }
// 报文总数
int num_packets = 0;
// 丢包数量
int num_lost_packets = 0;
// 接收数量
int num_received_packets = 0;
// 根据观察时间计算
DataRate sending_rate = DataRate::MinusInfinity();
// 报文总大小
DataSize size = DataSize::Zero();
// 丢包总大小
DataSize lost_size = DataSize::Zero();
int id = -1;
};3)loss_based_result_
基于丢包的带宽估计值和状态。
struct Result {
// 估算的带宽
DataRate bandwidth_estimate = DataRate::Zero();
// 如果处于kIncreasing状态,则需要做带宽探测
LossBasedState state = LossBasedState::kDelayBasedEstimate;
};
enum class LossBasedState {
// 使用丢包估计带宽,正在增加码率
kIncreasing = 0,
// 使用丢包估计带宽,正在使用padding增加带宽(探测)
kIncreaseUsingPadding = 1,
// 使用丢包估计带宽,由于丢包增大,正在降低码率
kDecreasing = 2,
// 使用延迟估计带宽
kDelayBasedEstimate = 3
};3. 重要方法
1)SetAcknowledgedBitrate
设置 ACK 码率,ACK 码率在很多地方都会被用到,比如计算基于丢包带宽估计值的上限和下限,生成候选者带宽,
2)SetMinMaxBitrate
设置基于丢包带宽估计的上限值和下限值。
3)UpdateBandwidthEstimate
SendSideBandwidthEstimation 调用此接口,传入 TransportFeedback、延迟估计带宽和 ALR 状态等参数。
4)GetLossBasedResult
获取基于丢包带宽估计结果。
4. 源码分析
4.1. UpdateBandwidthEstimate
UpdateBandwidthEstimate 是丢包估计的主函数,代码非常多,其主体流程如下图所示:
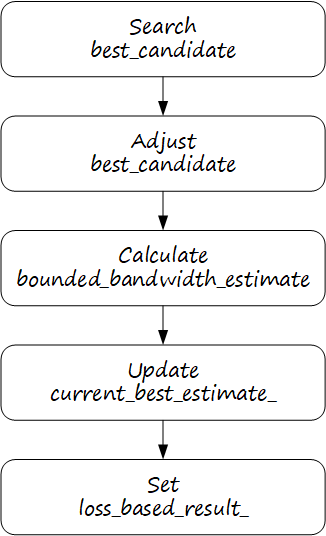
4.1.1. 搜索最佳候选者
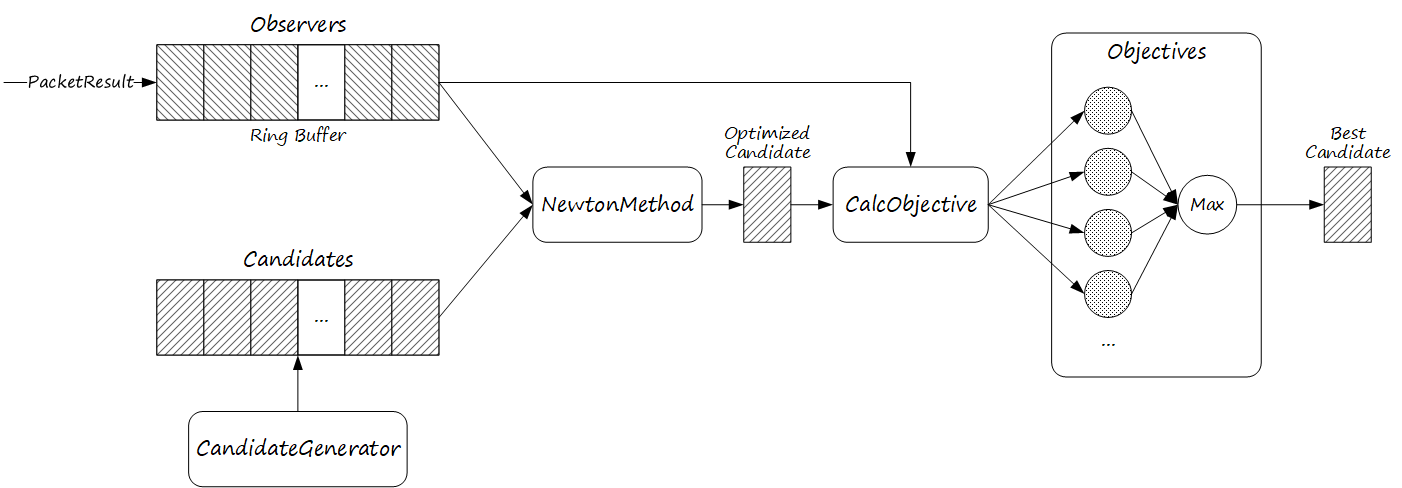
搜索最佳候选者的逻辑如下图所示,解释如下:
1)基于 TransportFeedback 构建观测值,每一组观测值设置了最小观测时长。如果产生了新的观测值,则进人新一轮的带宽估计。
2)使用一定算法生成一系列候选者(candidate),只需确定候选者带宽即可。
3)基于观测数据,使用牛顿方法计算候选者的最优固有丢包率。
4)基于观测数据,对每个候选者计算目标函数值,取目标函数值最大者为最佳候选者。
// 尝试将新的观测数据加入到历史数据中,如果没有产生新的observation则返回
if (!PushBackObservation(packet_results)) {
return;
}
// 初始化最佳带宽估计,如果没有有效的丢包限制带宽估计,则使用基于延迟的估计
if (!IsValid(current_best_estimate_.loss_limited_bandwidth)) {
if (!IsValid(delay_based_estimate)) {
return;
}
current_best_estimate_.loss_limited_bandwidth = delay_based_estimate;
loss_based_result_ = {.bandwidth_estimate = delay_based_estimate,
.state = LossBasedState::kDelayBasedEstimate};
}
ChannelParameters best_candidate = current_best_estimate_;
double objective_max = std::numeric_limits<double>::lowest();
// 生成并遍历所有candidate,找到最优candidate
for (ChannelParameters candidate : GetCandidates(in_alr)) {
// 使用牛顿法搜索最优固有丢包率
NewtonsMethodUpdate(candidate);
// 基于带宽和固有丢包率计算收益值
const double candidate_objective = GetObjective(candidate);
// 找到收益值最大的Candidate
if (candidate_objective > objective_max) {
objective_max = candidate_objective;
best_candidate = candidate;
}
}4.1.2. 调整丢包限制带宽
通过算法计算得到的最佳候选者还不可靠,需要进行调整。 在丢包限制状态下,如果带宽增加过快则限制带宽增长,并使用爬坡因子来调整带宽估计。增加带宽过快可能会再次引发丢包。
// best_candidate 的估计带宽与其固有丢包率是匹配的,如果 best_candidate 的估计带宽大于
// 上一次的估计带宽,但真实丢包率大于 best_candidate 的固有丢包率,那么有理由认为
// best_candidate 的估计带宽是不可靠的。
if (GetAverageReportedLossRatio() > best_candidate.inherent_loss &&
config_->not_increase_if_inherent_loss_less_than_average_loss &&
current_best_estimate_.loss_limited_bandwidth <
best_candidate.loss_limited_bandwidth) {
best_candidate.loss_limited_bandwidth =
current_best_estimate_.loss_limited_bandwidth;
}
// 下面这一坨都是在调整best_candidate.loss_limited_bandwidth
if (IsInLossLimitedState()) {
if (recovering_after_loss_timestamp_.IsFinite() &&
recovering_after_loss_timestamp_ + config_->delayed_increase_window >
last_send_time_most_recent_observation_ &&
best_candidate.loss_limited_bandwidth > bandwidth_limit_in_current_window_) {
best_candidate.loss_limited_bandwidth = bandwidth_limit_in_current_window_;
}
bool increasing_when_loss_limited = IsEstimateIncreasingWhenLossLimited(
/*old_estimate=*/current_best_estimate_.loss_limited_bandwidth,
/*new_estimate=*/best_candidate.loss_limited_bandwidth);
// Bound the best candidate by the acked bitrate.
if (increasing_when_loss_limited && IsValid(acknowledged_bitrate_)) {
// 爬坡因子
double rampup_factor = config_->bandwidth_rampup_upper_bound_factor;
// 使用更保守的爬坡因子
if (IsValid(last_hold_info_.rate) &&
acknowledged_bitrate_ <
config_->bandwidth_rampup_hold_threshold * last_hold_info_.rate) {
rampup_factor = config_->bandwidth_rampup_upper_bound_factor_in_hold;
}
// 保证带宽估计值不会低于当前的最佳估计值。
// 同时,限制在不超过新计算的候选值和基于 ACK 码率计算的增长上限之间的较小值。
best_candidate.loss_limited_bandwidth =
std::max(current_best_estimate_.loss_limited_bandwidth,
std::min(best_candidate.loss_limited_bandwidth,
rampup_factor * (*acknowledged_bitrate_)));
// 为了避免估计值长时间停滞导致算法无法切换到kIncreasing,这里将带宽估计增加1kbps。
if (loss_based_result_.state == LossBasedState::kDecreasing &&
best_candidate.loss_limited_bandwidth ==
current_best_estimate_.loss_limited_bandwidth) {
best_candidate.loss_limited_bandwidth =
current_best_estimate_.loss_limited_bandwidth +
DataRate::BitsPerSec(1);
}
}
}
4.1.3. 计算有界带宽估计
取丢包估计带宽和延迟估计带宽的较小者,并将估计值限制在合理范围,获得 bounded_bandwidth_estimate。
// 施加了范围限制的带宽估计值
DataRate bounded_bandwidth_estimate = DataRate::PlusInfinity();
if (IsValid(delay_based_estimate_)) {
// 取丢包估计带宽和延迟估计带宽中的较小者
bounded_bandwidth_estimate =
std::max(GetInstantLowerBound(),
std::min({best_candidate.loss_limited_bandwidth,
GetInstantUpperBound(), delay_based_estimate_}));
} else {
// 没有延迟估计值,则使用丢包估计值
bounded_bandwidth_estimate = std::max(GetInstantLowerBound(),
std::min(best_candidate.loss_limited_bandwidth, GetInstantUpperBound()));
}4.1.4. 更新当前最佳估计
根据配置和估计结果更新当前最佳估计值。
if (config_->bound_best_candidate &&
bounded_bandwidth_estimate < best_candidate.loss_limited_bandwidth) {
// 如果配置了对 best_candidate 进行约束,则限制
// best_candidate.loss_limited_bandwidth 不能大于 bounded_bandwidth_estimate
current_best_estimate_.loss_limited_bandwidth = bounded_bandwidth_estimate;
current_best_estimate_.inherent_loss = 0;
} else {
// 没有配置就等于筛选出来的最优值
current_best_estimate_ = best_candidate;
}4.1.5. 设置带宽估计结果
获取 bounded_bandwidth_estimate 后,接下来需要更新 loss_based_result.state,并设置估计带宽。以下代码逻辑异常复杂,条件一大堆,是 LossBasedBweV2 最难理解的部分。
// 当前是在 kDecreasing 状态,此次丢包估计带宽低于延迟估计带宽,不允许估计带宽
// 立即上升到可能引起丢包的水平。
if (loss_based_result_.state == LossBasedState::kDecreasing &&
last_hold_info_.timestamp > last_send_time_most_recent_observation_ &&
bounded_bandwidth_estimate < delay_based_estimate_) {
loss_based_result_.bandwidth_estimate =
std::min(last_hold_info_.rate, bounded_bandwidth_estimate);
return; // 直接返回,状态保持LossBasedState::kDecreasing
}
// 带宽增加
if (IsEstimateIncreasingWhenLossLimited(
/*old_estimate=*/loss_based_result_.bandwidth_estimate,
/*new_estimate=*/bounded_bandwidth_estimate) &&
CanKeepIncreasingState(bounded_bandwidth_estimate) &&
bounded_bandwidth_estimate < delay_based_estimate_ &&
bounded_bandwidth_estimate < max_bitrate_) {
if (config_->padding_duration > TimeDelta::Zero() &&
bounded_bandwidth_estimate > last_padding_info_.padding_rate) {
// 开启一个新的填充周期
last_padding_info_.padding_rate = bounded_bandwidth_estimate;
last_padding_info_.padding_timestamp =
last_send_time_most_recent_observation_;
}
loss_based_result_.state = config_->padding_duration > TimeDelta::Zero()
? LossBasedState::kIncreaseUsingPadding
: LossBasedState::kIncreasing;
}
// 带宽减少
else if (bounded_bandwidth_estimate < delay_based_estimate_ &&
bounded_bandwidth_estimate < max_bitrate_) {
if (loss_based_result_.state != LossBasedState::kDecreasing &&
config_->hold_duration_factor > 0) {
last_hold_info_ = {
.timestamp = last_send_time_most_recent_observation_ +
last_hold_info_.duration,
.duration =
std::min(kMaxHoldDuration, last_hold_info_.duration *
config_->hold_duration_factor),
.rate = bounded_bandwidth_estimate};
}
last_padding_info_ = PaddingInfo();
loss_based_result_.state = LossBasedState::kDecreasing;
} else {
// 如果以上条件都不满足,表明基于延迟的估计应该被采纳,
// 或者当前状态需要重置以避免带宽被错误地限制在低水平。
last_hold_info_ = {.timestamp = Timestamp::MinusInfinity(),
.duration = kInitHoldDuration,
.rate = DataRate::PlusInfinity()};
last_padding_info_ = PaddingInfo();
loss_based_result_.state = LossBasedState::kDelayBasedEstimate;
}
// 更新丢包限制的评估带宽
loss_based_result_.bandwidth_estimate = bounded_bandwidth_estimate;4.2. 相关算法
基于丢包带宽估计的核心问题可以表述为:带宽和固有丢包率是链路的两个属性,现在我们有一组观测值,每个观测值记录了码率和丢包率,如何通过这些观测值反推链路的带宽和固有丢包率?
WebRTC 假定链路丢包符合二项分布,先生成一组候选者(candidate),根据经验设置候选者的带宽,然后用牛顿方法在观测值上搜索候选者的最优固有丢包率,最后用候选者带宽和固有丢包率计算一个收益函数,取收益函数最大的候选者作为最佳估计。
4.2.1. 搜集观测值
Observation 基于 TransportFeedback 生成,收集足够时长报文成为一个观测值。
bool LossBasedBweV2::PushBackObservation(
rtc::ArrayView<const PacketResult> packet_results) {
if (packet_results.empty()) {
return false;
}
// 获取报文数组的统计信息
PacketResultsSummary packet_results_summary =
GetPacketResultsSummary(packet_results);
// 累加报文数量
partial_observation_.num_packets += packet_results_summary.num_packets;
// 累加丢包数量
partial_observation_.num_lost_packets +=
packet_results_summary.num_lost_packets;
// 累加报文大小
partial_observation_.size += packet_results_summary.total_size;
// 累加丢包大小
partial_observation_.lost_size += packet_results_summary.lost_size;
// This is the first packet report we have received.
if (!IsValid(last_send_time_most_recent_observation_)) {
last_send_time_most_recent_observation_ =
packet_results_summary.first_send_time;
}
// 报文组中最晚发包时间
const Timestamp last_send_time = packet_results_summary.last_send_time;
// 距离上一组 last_send_time 时间差
const TimeDelta observation_duration =
last_send_time - last_send_time_most_recent_observation_;
// 两组报文时间差要达到阈值才能创建一个完整的 observation
if (observation_duration <= TimeDelta::Zero() ||
observation_duration < config_->observation_duration_lower_bound) {
return false;
}
// 更新
last_send_time_most_recent_observation_ = last_send_time;
// 创建 oberservation
Observation observation;
observation.num_packets = partial_observation_.num_packets;
observation.num_lost_packets = partial_observation_.num_lost_packets;
observation.num_received_packets =
observation.num_packets - observation.num_lost_packets;
observation.sending_rate =
GetSendingRate(partial_observation_.size / observation_duration);
observation.lost_size = partial_observation_.lost_size;
observation.size = partial_observation_.size;
observation.id = num_observations_++;
// 保存 observation
observations_[observation.id % config_->observation_window_size] =
observation;
// 重置 partial
partial_observation_ = PartialObservation();
CalculateInstantUpperBound();
return true;
}4.2.2. 生成候选者
搜索最佳后选择之前,需要生成一系列候选者。由于是有限集合搜索,候选者带宽的选取要考虑上界、下界以及分布的合理性,以形成一个有效的搜索空间,获得准确的搜索结果。
std::vector<LossBasedBweV2::ChannelParameters> LossBasedBweV2::GetCandidates(
bool in_alr) const {
// 当前的最佳带宽估计中提取信息
ChannelParameters best_estimate = current_best_estimate_;
// 用于存储即将生成的候选带宽
std::vector<DataRate> bandwidths;
// 基于当前最佳估计带宽和生成因子生成一系列候选带宽值: 1.02, 1.0, 0.95
// 新的带宽在当前最佳估计带宽左右的概率比较高(带宽不会瞬变)
for (double candidate_factor : config_->candidate_factors) {
bandwidths.push_back(candidate_factor *
best_estimate.loss_limited_bandwidth);
}
// ACK码率是链路容量的一个真实测量值,添加一个基于ACK码率但进行了回退因子调整的候选带宽
if (acknowledged_bitrate_.has_value() &&
config_->append_acknowledged_rate_candidate) {
if (!(config_->not_use_acked_rate_in_alr && in_alr) ||
(config_->padding_duration > TimeDelta::Zero() &&
last_padding_info_.padding_timestamp + config_->padding_duration >=
last_send_time_most_recent_observation_)) {
bandwidths.push_back(*acknowledged_bitrate_ *
config_->bandwidth_backoff_lower_bound_factor);
}
}
// 满足以下条件,延迟估计带宽也作为带宽候选者之一
// 1)延迟估计带宽有效
// 2)配置允许
// 3)延迟估计带宽高于当前最佳估计丢包限制带宽
if (IsValid(delay_based_estimate_) &&
config_->append_delay_based_estimate_candidate) {
if (delay_based_estimate_ > best_estimate.loss_limited_bandwidth) {
bandwidths.push_back(delay_based_estimate_);
}
}
// 满足以下条件,当前带宽上界也作为带宽候选者之一
// 1)处于ALR状态
// 2)配置允许时
// 3)最佳估计丢包限制带宽大于当前带宽上界
if (in_alr && config_->append_upper_bound_candidate_in_alr &&
best_estimate.loss_limited_bandwidth > GetInstantUpperBound()) {
bandwidths.push_back(GetInstantUpperBound());
}
// 计算一个候选带宽的上界,用于限制生成的候选带宽值不超过这个上界。
const DataRate candidate_bandwidth_upper_bound =
GetCandidateBandwidthUpperBound();
std::vector<ChannelParameters> candidates;
candidates.resize(bandwidths.size());
for (size_t i = 0; i < bandwidths.size(); ++i) {
ChannelParameters candidate = best_estimate;
// 丢包限制带宽设置为当前最佳估计的丢包限制带宽与候选带宽值、上界之间的最小值
candidate.loss_limited_bandwidth =
std::min(bandwidths[i], std::max(best_estimate.loss_limited_bandwidth,
candidate_bandwidth_upper_bound));
// 使用最佳估计的丢包率
candidate.inherent_loss = GetFeasibleInherentLoss(candidate);
candidates[i] = candidate;
}
return candidates;
}4.2.3. 牛顿方法
牛顿方法要解决的问题是,在候选者的估计带宽下,基于当前观测值,求最大似然概率下的固有丢包率。可以这么理解,已知当前链路的带宽,测得一组观测值,观测值描述了收发数据和丢包情况,现在需要计算一个最优的固定丢包率,使得当前观测值出现的联合概率最大。
观测数据可以简化描述为:在一段时间内统计,丢失了 n 个报文,接收到 m 个报文。假设链路的固有丢包率为p,由于观测结果属于二项分布,其概率密度函数可以表示为:
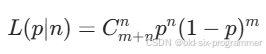
现在测得一组观测数据,要求链路固有丢包率的最大似然概率。我们可以将 k 次观测数据的似然函数相乘,得到联合似然函数,因为每次实验是独立的:
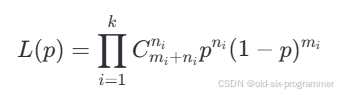
直接最大化上述似然函数可能比较复杂,可以先对似然函数取自然对数,转换为对数似然函数,方便计算:
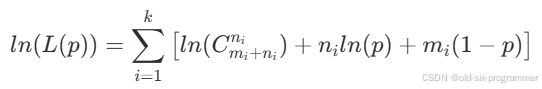
由于 不依赖于
,在求导时会消失,因此在最大化对数似然函数时可以忽略这一项。对
关于
求导,并令导数等于0,可以找到
的最大似然估计值
。
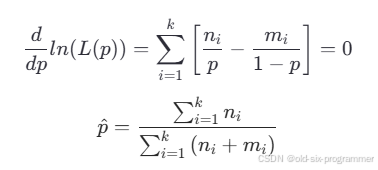
理论上,代入观测数据就可以求得最优固有丢包率。但这里不能这么计算,原因有两个:
1)这里的丢包率并不是固有丢包率 inherent_loss,而是丢包概率 loss_probability,loss_probability 除 inherent_loss 之外,还包括发送速率超出链路带宽导致的丢包。
2)即使计算得到 loss_probability 的最大似然估计值,仍然不能直接求得 inherent_loss 的最大似然估计值,因为 inherent_loss 与 loss_probability 之间并不是简单的线性关系,如下所示。
double GetLossProbability(double inherent_loss, DataRate loss_limited_bandwidth,
DataRate sending_rate) {
if (inherent_loss < 0.0 || inherent_loss > 1.0) {
inherent_loss = std::min(std::max(inherent_loss, 0.0), 1.0);
}
double loss_probability = inherent_loss;
// 如果发送速率大于丢包限制带宽,真实丢包率会更高
if (IsValid(sending_rate) && IsValid(loss_limited_bandwidth)
&& (sending_rate > loss_limited_bandwidth)) {
loss_probability += (1 - inherent_loss) *
(sending_rate - loss_limited_bandwidth) / sending_rate;
}
// 限制范围[1.0e-6, 1.0 - 1.0e-6]
return std::min(std::max(loss_probability, 1.0e-6), 1.0 - 1.0e-6);
}既然如此,WebRTC 就通过计算似然函数的一阶导数和二阶导数,然后使用牛顿方法来搜索 inherent_loss 的最优值。代码如下所示,标准的牛顿方法。
void LossBasedBweV2::NewtonsMethodUpdate(ChannelParameters& channel_parameters) const {
// 没有可用的观测值
if (num_observations_ <= 0) {
return;
}
// 指定带宽下,根据观测值,求得最大似然丢包率
for (int i = 0; i < config_->newton_iterations; ++i) {
// 计算一阶导数和二阶导数
const Derivatives derivatives = GetDerivatives(channel_parameters);
// 基于一阶导数和二阶导数进行迭代搜索,newton_step_size = 0.75
channel_parameters.inherent_loss -=
config_->newton_step_size * derivatives.first / derivatives.second;
// 固有丢包率的界限约束
channel_parameters.inherent_loss = GetFeasibleInherentLoss(channel_parameters);
}
}一阶导数和二阶导数的计算如下所示,不过这里有两个需要注意的点:
1)这里计算的并不是 inherent_loss 而是 loss_probability 的最大似然函数的导数,由于 loss_probability 是 inherent_loss 的函数,根据链式法则,使用 loss_probability 的导数来计算 inherent_loss 的最优值是有效的。
2)这里的一阶导数和二阶导数是多个观测值计算的累加值,由于多个观测值之间是独立同分布的,所以,这也是没问题的。
LossBasedBweV2::Derivatives LossBasedBweV2::GetDerivatives(
const ChannelParameters& channel_parameters) const {
Derivatives derivatives;
for (const Observation& observation : observations_) {
// 无效的观测值
if (!observation.IsInitialized()) {
continue;
}
// 计算在给定通道参数下的丢包概率,如果发送速率超过丢包限制带宽,
// 则很可能会产生链路拥塞,从而导致真实丢包率高于链路固有丢包率
double loss_probability = GetLossProbability(
channel_parameters.inherent_loss,
channel_parameters.loss_limited_bandwidth, observation.sending_rate);
// 施加一个时间权重,距当前时间越近,数据越“新鲜”,权重越高
double temporal_weight =
temporal_weights_[(num_observations_ - 1) - observation.id];
// 基于丢失和接收到的数据量分别计算一阶导数和二阶导数的累加项
if (config_->use_byte_loss_rate) {
// derivatives.first += w*((lost/p) - (total-lost)/(1-p))
derivatives.first +=
temporal_weight *
((ToKiloBytes(observation.lost_size) / loss_probability) -
(ToKiloBytes(observation.size - observation.lost_size) /
(1.0 - loss_probability)));
// derivatives.second -= w*((lost/p^2) + (total-lost)/(1-p)^2)
derivatives.second -=
temporal_weight *
((ToKiloBytes(observation.lost_size) /
std::pow(loss_probability, 2)) +
(ToKiloBytes(observation.size - observation.lost_size) /
std::pow(1.0 - loss_probability, 2)));
// 基于丢失和接收到的数据包数量分别计算一阶导数和二阶导数的累加项
} else {
derivatives.first +=
temporal_weight *
((observation.num_lost_packets / loss_probability) -
(observation.num_received_packets / (1.0 - loss_probability)));
derivatives.second -=
temporal_weight *
((observation.num_lost_packets / std::pow(loss_probability, 2)) +
(observation.num_received_packets /
std::pow(1.0 - loss_probability, 2)));
}
}
// 理论上,二阶导数应为负(表示带宽估计函数的凸性),
// 若出现非预期的正值,进行校正,以避免数学异常或不合理的进一步计算。
if (derivatives.second >= 0.0) {
derivatives.second = -1.0e-6;
}
return derivatives;
}4.2.4. 目标函数
经牛顿方法搜索后的固有丢包率,加上链路带宽,带入目标函数进行计算,目标值越大则结果越可信。
目标函数分为两部分,第一部分是似然概率,代表了模型对观测数据的解释能力,其中 是时间权重因子,数据越“新鲜”权重越高。
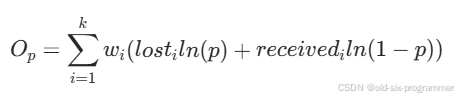
目标函数的第二部分是高带宽偏置,鼓励算法探索更高带宽的潜在收益,其他项相同的前提下,带宽越高越受青睐。其中 是时间权重因子,数据越“新鲜”权重越高。
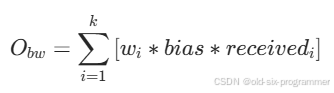
double LossBasedBweV2::GetObjective(
const ChannelParameters& channel_parameters) const {
double objective = 0.0;
// 计算高带宽偏置,鼓励探索更高带宽
const double high_bandwidth_bias =
GetHighBandwidthBias(channel_parameters.loss_limited_bandwidth);
for (const Observation& observation : observations_) {
if (!observation.IsInitialized()) {
continue;
}
// 考虑发送码率高于限制码率情况导致的拥塞丢包
double loss_probability = GetLossProbability(
channel_parameters.inherent_loss,
channel_parameters.loss_limited_bandwidth, observation.sending_rate);
// 应用一个时间权重给每个观测,新近的观测通常会有更大的影响
double temporal_weight =
temporal_weights_[(num_observations_ - 1) - observation.id];
if (config_->use_byte_loss_rate) {
// 固有丢包率收益
objective +=
temporal_weight *
((ToKiloBytes(observation.lost_size) * std::log(loss_probability)) +
(ToKiloBytes(observation.size - observation.lost_size) *
std::log(1.0 - loss_probability)));
// 带宽收益
objective +=
temporal_weight * high_bandwidth_bias * ToKiloBytes(observation.size);
} else {
objective +=
temporal_weight *
((observation.num_lost_packets * std::log(loss_probability)) +
(observation.num_received_packets *
std::log(1.0 - loss_probability)));
objective +=
temporal_weight * high_bandwidth_bias * observation.num_packets;
}
}
return objective;
}5. 总结
与带宽一样,固有丢包率(inherent loss)也是网路链路的一个属性,而且是动态变化的。当观察到丢包的时候,我们如何判断这是由于链路固有丢包率导致的丢包还是由于网络拥塞导致的丢包?除非我们知道链路的固有丢包率和带宽,但显然这是无法办到的。WebRTC 为解决这个问题打开了一扇窗,其思路是建立网络丢包的二项式分布模型,通过搜集足够多的观测值,构造目标函数,使用牛顿方法去搜索链路带宽和固有丢包率的最佳组合。然后对这个最佳组合进行必要的校正与调整。不过,从 WebRTC 的实现来看,调整算法太过复杂,有理由相信通过算法得到的估计值可靠性不是非常高,如何优化和简化这一部分的实现逻辑是一个挑战。