目录
一、线性回归实现
1.1 数据加载与查看绘图
1.2 模型建立、训练与预测
二、神经网络实现
2.1 数据加载与查看绘图
2.2 模型建立、训练与预测
三、逻辑回归实现
3.1 数据加载与查看绘图
3.2 模型建立、训练与预测
四、softmax分类
4.1 数据加载
4.2 数据归一化
4.3 模型建立、训练与预测
4.4 独热编码(onehot)
4.5 优化函数、学习率、反向传播算法
4.5.1 学习率
4.5.2 优化函数
4.5.3 反向传播
五、网络优化、超参数与Dropout
5.1 网络容量
5.2 超参数
5.3 网络优化
5.4 softmax优化
5.5 Dropout(抑制过拟合)
六、基本操作
6.1 查看 tensorflow 版本
6.2 数据加载与查看
七、其他
7.1 激活函数
7.1.1 relu : 非负输出
7.1.2 sigmoid:输出(0, 1)
7.1.3 Sigmoid:适用二分类,设定阈值
7.1.4 softmax:输出 (0, 1),适用多分类,输出概率
7.1.5 tanh:输出[-1, 1]
7.1.6 Leak relu:将负值信号传递一点点出来,一般用在深层网络里
7.2 损失函数
7.2.1 交叉熵损失函数
7.3 优化函数
7.3.1 SGD
7.3.2 RMSprop
7.3.3 Adam
八、API解释
8.1 keras.layers.Dense
一、线性回归实现
1.1 数据加载与查看绘图
import pandas as pd
data = pd.read_csv('./tensorflow入门与实战-基础部分数据集/Income1.csv')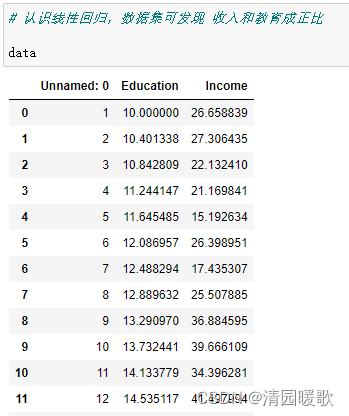
# 绘图认识一下
import matplotlib.pyplot as plt
%matplotlib inline
# % 的是使用魔术方法,直接显示出来
plt.scatter(data.Education, data.Income) # 绘制散点图,plt.scatter(x轴, y轴) 
1.2 模型建立、训练与预测
x = data.Education
y = data.Income
model = tf.keras.Sequential() # 按Tab可以补全名称,Sequential顺序模型
model.add(tf.keras.layers.Dense(1, input_shape=(1,))) # 输出维度是1,输入数据的维度=(1,) 输入只有一个变量,逗号代表一个元组
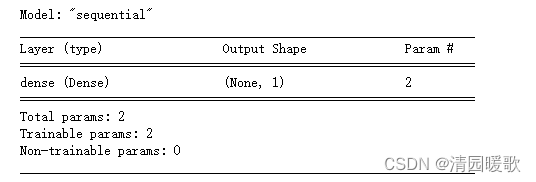
model.summary() # 反应模型形状, ax + b
# None的第一个维度代表样本的个数,第二个代表输出的维度
# 如Output Shape(50, 1)代表输出的是50个1维度的数据
# Param = 2表示有2个参数
# 编译, optimizer :优化方法; loss:损失函数; mse:均方差
model.compile(optimizer = 'adam',
loss = 'mse'
)
# 训练模型,用fit方法,用history记录下来
# epochs :迭代次数
history = model.fit(x, y, epochs=5000)
model.predict(x)

model.predict(pd.Series([20])) # Series是一维数组![]()
二、神经网络实现
2.1 数据加载与查看绘图
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv('./tensorflow入门与实战-基础部分数据集/Advertising.csv')
plt.scatter(data.TV, data.sales)
plt.scatter(data.radio, data.sales)
2.2 模型建立、训练与预测
x = data.iloc[:, 1:-1] # [:, 1:-1]是 第一个冒号是所有的行、1,-1是出去第一列和最后一列
y = data.iloc[:, -1]
model = tf.keras.Sequential([tf.keras.layers.Dense(10, input_shape=(3, ), activation='relu'),
tf.keras.layers.Dense(1)] # 两层,第一层输出10个数据,太大容易过拟合,激活函数为:relu
)
model.summary()
model.compile(optimizer='adam',
loss='mse'
)
# 输出是一个连续的值,所以也可以用均方差作为损失函数
model.fit(x, y, epochs=100)
test = data.iloc[:10, 1:-1]
model.predict(test)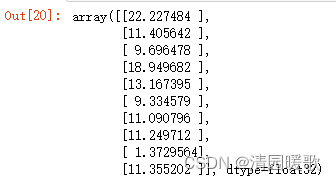
origin = data.iloc[:10, -1]
origin
三、逻辑回归实现
3.1 数据加载与查看绘图
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv('./tensorflow入门与实战-基础部分数据集/credit-a.csv')
data.head() # head默认显示前5行,可以发现这数据集没有表头,所以要加上 header = None
data = pd.read_csv('./tensorflow入门与实战-基础部分数据集/credit-a.csv', header = None)
data.head()
# 查看最后一列中 1,-1 的个数
data.iloc[:, -1].value_counts()
3.2 模型建立、训练与预测
x = data.iloc[:, :-1] # 所有的行,最后一列之前的
y = data.iloc[:, -1].replace(-1, 0) # replace将 -1 替换为 0
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(4, input_shape=(15,),activation='relu')) # 自己设置规定 第一层有4个单元数
model.add(tf.keras.layers.Dense(4, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
# metrics 用来测量,这里用来测量 准确性(正确率)
history = model.fit(x, y, epochs=100)
history.history.keys() # history.keys() 看有哪些字典,看到有loss和keys的变化
四、softmax分类
4.1 数据加载
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
(train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data()
# 下载的数据集在 C:\Users\name\keras\datasets\fashion-mnist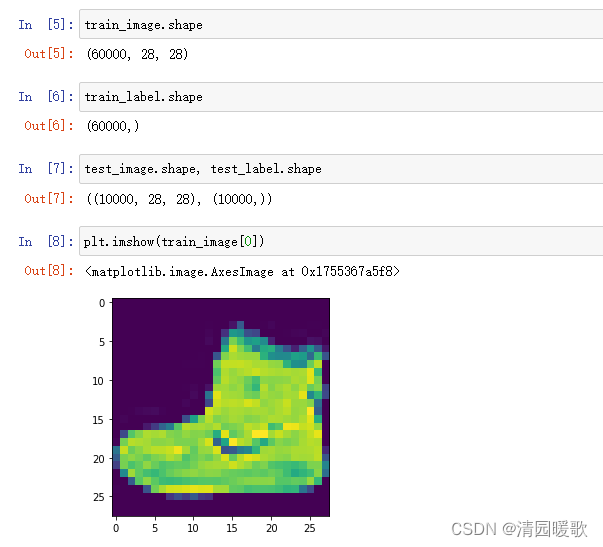

4.2 数据归一化
train_image = train_image/255
test_image = test_image/255
4.3 模型建立、训练与预测
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28))) # 28*28的向量
model.add(tf.keras.layers.Dense(128, activation='relu')) # 128个隐藏单元,不能太小因为数据挺大,不过太大会过拟合
model.add(tf.keras.layers.Dense(10, activation='softmax'))
# Dense 是把一维映射到另一个一维中
# 而这里图片是 28×28 的,所以要把这个二维的变为一维,用Flatten
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc']
)
model.fit(train_image, train_label, epochs=5)
model.evaluate(test_image, test_label)

4.4 独热编码(onehot)
独热编码是数值化的一种方法,比如说有3个城市,北京、上海、南京,将其编码成0、1、2
也可以编码成维度一样的,如北京就是 [1, 0, 0] , 其他 [0, 1, 0] ,[0, 0, 1]
train_label_onehot = tf.keras.utils.to_categorical(train_label)
test_label_onehot = tf.keras.utils.to_categorical(test_label)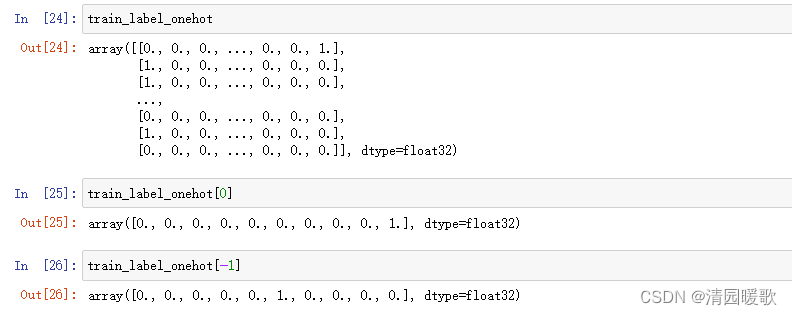
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc']
)
model.fit(train_image, train_label_onehot, epochs=5)
predict = model.predict(test_image)
4.5 优化函数、学习率、反向传播算法
4.5.1 学习率


4.5.2 优化函数

4.5.3 反向传播
参考:
深度学习——反向传播(Backpropagation)_南方惆怅客的博客-CSDN博客_反向传播
反向传播是什么?通俗易懂的解释!!!_一个小呆苗的博客-CSDN博客_反向传播


model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='categorical_crossentropy',
metrics=['acc']
)
# shift + Tab 显示函数的参数五、网络优化、超参数与Dropout
5.1 网络容量

5.2 超参数

5.3 网络优化


5.4 softmax优化
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
(train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data()
train_image = train_image/255
test_image = test_image/255
train_label_onehot = tf.keras.utils.to_categorical(train_label)
test_label_onehot = tf.keras.utils.to_categorical(test_label)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28))) # 28*28的向量
model.add(tf.keras.layers.Dense(128, activation='relu')) # 128个隐藏单元,不能太小因为数据挺大,不过太大会过拟合
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['acc']
)
history = model.fit(train_image, train_label_onehot, epochs=10,
validation_data=(test_image, test_label_onehot)
) # 用 validation_data 就不仅可以看到在 训练集 上的准确率,还可以看大在 测试集 上的准确率
history.history.keys()
plt.plot(history.epoch, history.history.get('loss'), label='loss')
plt.plot(history.epoch, history.history.get('val_loss'), label='val_loss')
plt.legend()
plt.plot(history.epoch, history.history.get('acc'), label='acc')
plt.plot(history.epoch, history.history.get('val_acc'), label='val_acc')
plt.legend()
5.5 Dropout(抑制过拟合)
dropout本质上随机丢弃一些单元,训练的时候丢弃,测试的时候使用全部的
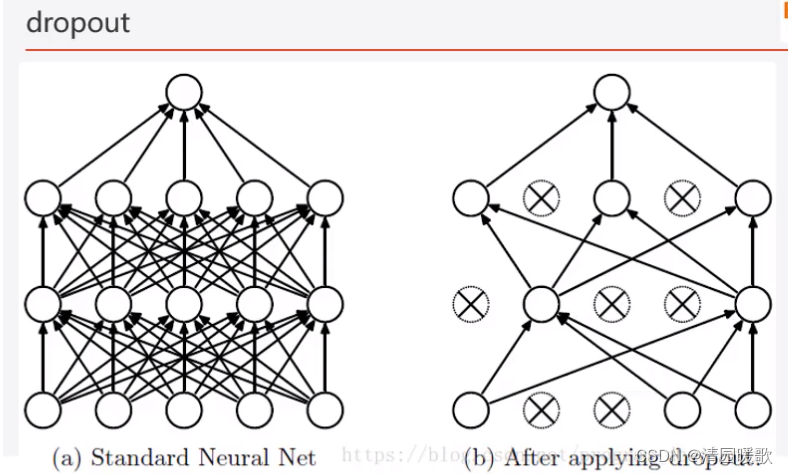
为什么说Dropout可以解决过拟合?


类似于生物学里面的适者生存理论,打破神经元之间的联合依赖性,迫使每个神经元学习到不同的信息,这样一来,网络即可以减小过拟合,也可以在一定程度上增强模型的鲁棒性
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28))) # 28*28的向量
model.add(tf.keras.layers.Dense(128, activation='relu')) # 128个隐藏单元,不能太小因为数据挺大,不过太大会过拟合
model.add(tf.keras.layers.Dropout(0.5)) # 这里是 rate 参数,每次激活 0.5也就是50%
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
六、基本操作
6.1 查看 tensorflow 版本
print('TensorFlow Version:{}'.format(tf.__version__))TensorFlow Version:2.1.0
6.2 数据加载与查看
data = pd.read_csv('./tensorflow入门与实战-基础部分数据集/Income1.csv')查看前5行数据
data.head()
七、其他
7.1 激活函数
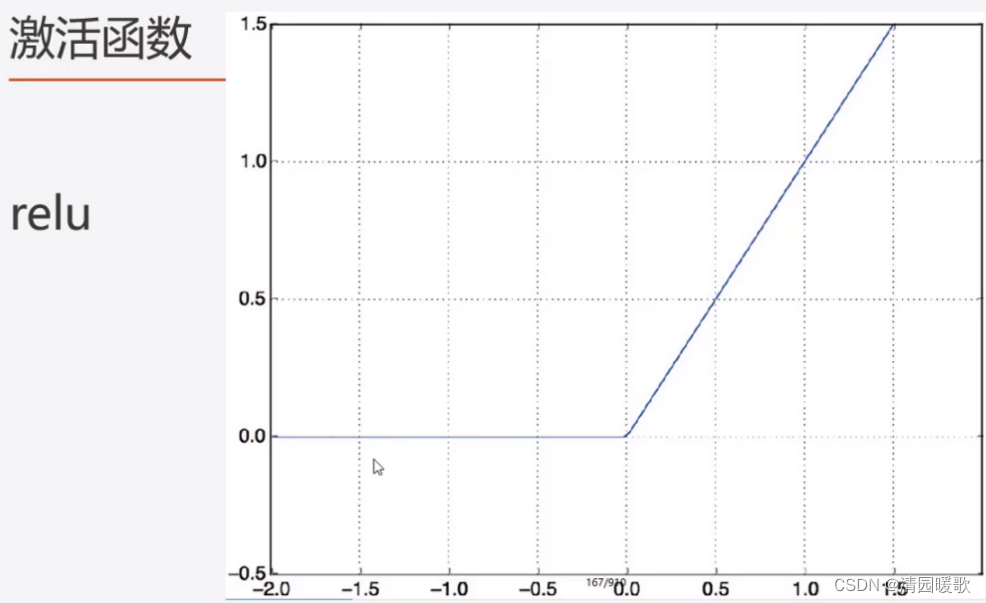
7.1.1 relu : 非负输出
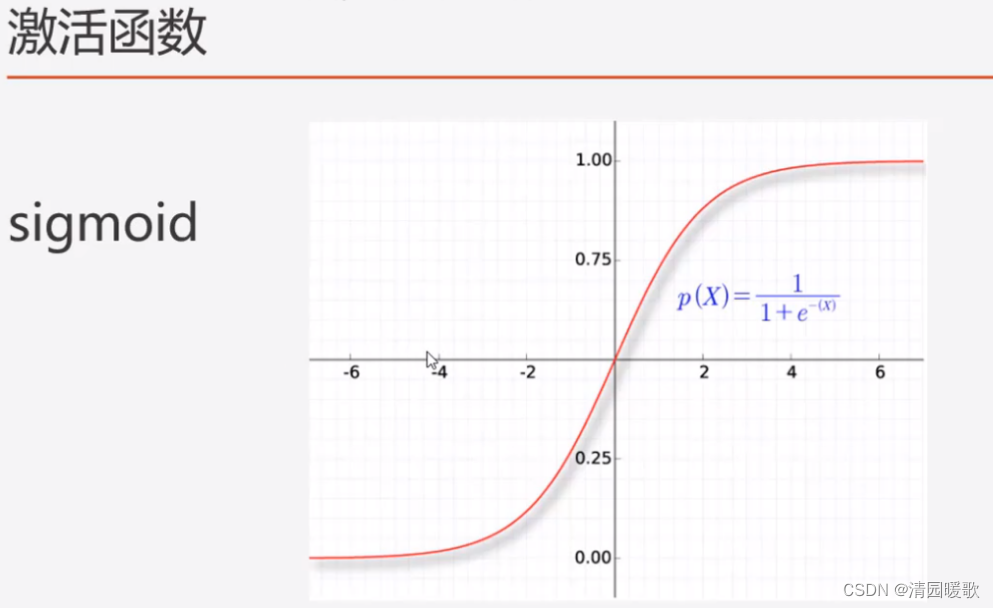
7.1.2 sigmoid:输出(0, 1)
7.1.3 Sigmoid:适用二分类,设定阈值
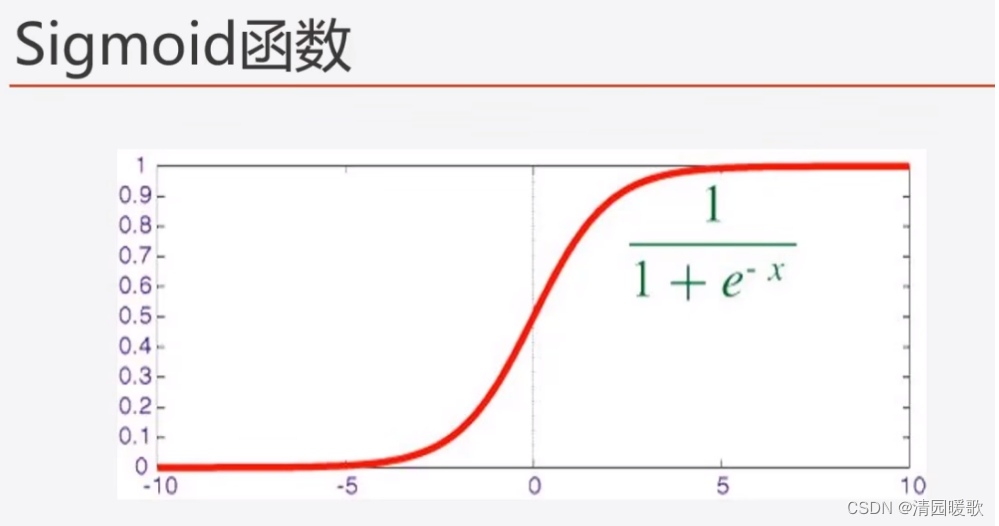
7.1.4 softmax:输出 (0, 1),适用多分类,输出概率

7.1.5 tanh:输出[-1, 1]

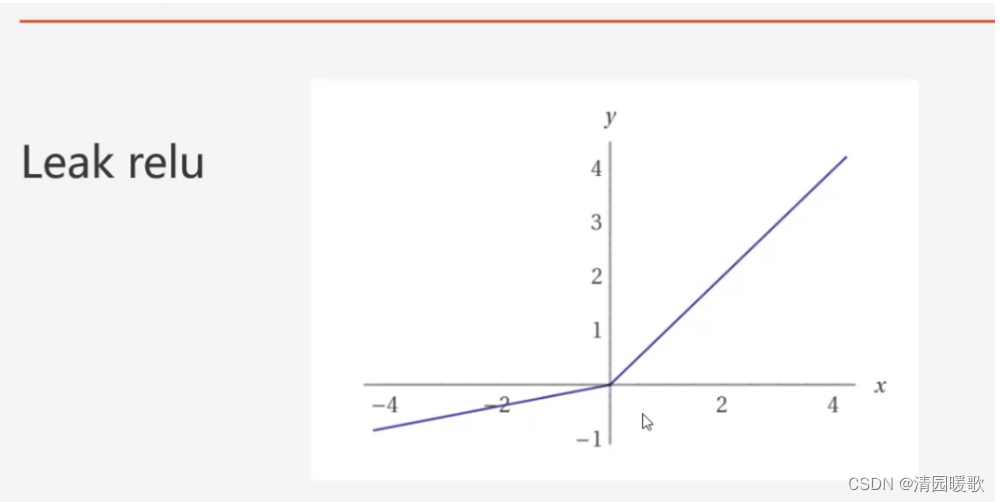
7.1.6 Leak relu:将负值信号传递一点点出来,一般用在深层网络里
7.2 损失函数
7.2.1 交叉熵损失函数




当label使用数字编码时,损失函数用sparse_categorical_crossentropy
label用独热编码时,用categorical_crossentropy
7.3 优化函数
7.3.1 SGD

参数:

7.3.2 RMSprop

参数:

RMSprop 处理序列问题会比较好

7.3.3 Adam


参数:

lr: learning rate(学习速率)
八、API解释
8.1 keras.layers.Dense
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
参数解释如下(黑体为常用参数):
units :代表该层的输出维度或神经元个数, units解释为神经元个数为了方便计算参数量,解释为输出维度为了方便计算维度
activation=None:激活函数.但是默认 liner (详见API的activation)
use_bias=True:布尔值,该层是否使用偏置向量b
kernel_initializer:初始化w权重 (详见API的initializers)
bias_initializer:初始化b权重 (详见API的initializers)
kernel_regularizer:施加在权重w上的正则项 (详见API的regularizer)
bias_regularizer:施加在偏置向量b上的正则项 (详见API的regularizer)
activity_regularizer:施加在输出上的正则项 (详见API的regularizer)
kernel_constraint:施加在权重w上的约束项 (详见API的constraints)
bias_constraint:施加在偏置b上的约束项 (详见API的constraints)
Keras中dense层原理及用法解释_66Kevin的博客-CSDN博客_dense层
未完,自用