摘要:
本文将手把手教你,从零开始构建一个简易的Python爬虫管理系统,无需编程基础,轻松掌握数据抓取技巧。通过实战演练,你将学会设置项目、编写基本爬虫代码、管理爬取任务与数据,为个人研究或企业需求奠定坚实基础。
一、前言:数据之海,从何舀水?
在这个信息爆炸的时代,数据如同海洋,而爬虫则是那把能够精准捕捞信息的网。对于初学者而言,构建一个自己的爬虫管理系统听起来或许遥不可及,但事实并非如此。本文旨在帮助你迈出这看似艰难实则充满乐趣的第一步,探索数据世界的奥秘。
二、Python爬虫:为何选择它?
Python,以其简洁的语法和强大的库支持,成为了数据抓取领域的首选语言。requests和BeautifulSoup等库的组合,让网页内容的获取与解析变得轻而易举,即便是编程小白也能快速上手。
三、基础准备:环境搭建与工具介绍
3.1 Python环境配置
首先,确保你的电脑上安装了Python。推荐使用Anaconda发行版,它内置了许多数据分析与科学计算的常用包,一键安装,省时省力。
3.2 编辑器的选择
VS Code或是PyCharm,都是学习Python的优质伴侣。它们不仅提供了丰富的代码补全功能,还有利于调试和项目管理。
四、动手实践:编写你的第一个爬虫
4.1 Hello, World! 的爬虫版本
我们从最简单的开始,比如抓取一个网页的标题。这一步骤将教会你如何使用requests发送HTTP请求,以及利用BeautifulSoup解析HTML。
import requests
from bs4 import BeautifulSoup
url = 'https://www.example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text
print(title)4.2 数据的存储
学会抓取数据后,下一步是如何保存这些宝贵的信息。这里,我们将使用pandas库来处理和存储数据到CSV文件中。
五、进阶:管理你的爬虫任务
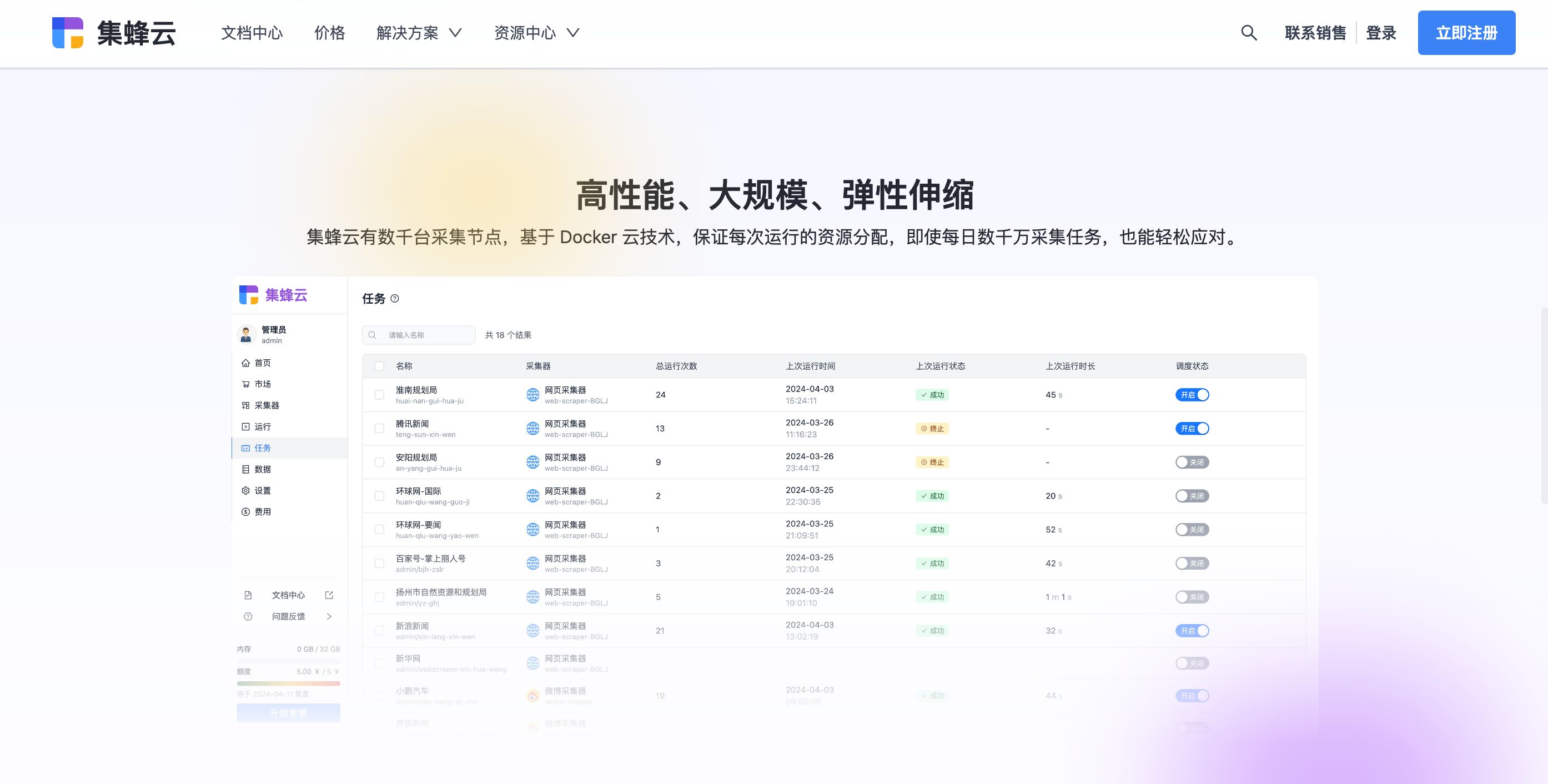
随着项目复杂度增加,手动执行每个爬虫脚本变得低效。引入task调度工具(如Airflow或Celery)可以自动化管理你的爬虫任务,实现定时抓取、错误重试等功能。
六、监控与日志:确保系统健康运行
Scrapy框架自带的监控与日志功能,让你能实时查看爬虫状态、追踪错误源头。同时,考虑使用第三方服务如Sentry来进一步加强错误报告机制。
七、合规与道德:尊重网络规则
在享受数据抓取带来的便利时,切勿忘记网络爬虫的法律边界与道德规范。确保遵守robots.txt协议,尊重网站的抓取规则。
八、问答环节:解决你的疑惑
-
问:没有编程基础能学吗?
-
答:当然,本文就是为零基础读者设计的,逐步指导你上手。
-
-
问:爬虫会被封IP吗?
-
答:有可能,合理设置延时、使用代理池可有效避免。
-
-
问:如何处理动态加载的内容?
-
答:学习使用Selenium或Scrapy搭配Splash,模拟浏览器行为抓取动态数据。
-
-
问:数据如何清洗和分析?
-
答:利用pandas进行数据清洗,结合numpy、matplotlib进行简单分析。
-
-
问:如何保证数据的安全存储?
-
答:选择加密数据库存储,定期备份,使用HTTPS传输等措施。
-
九、结语:数据之旅的启航
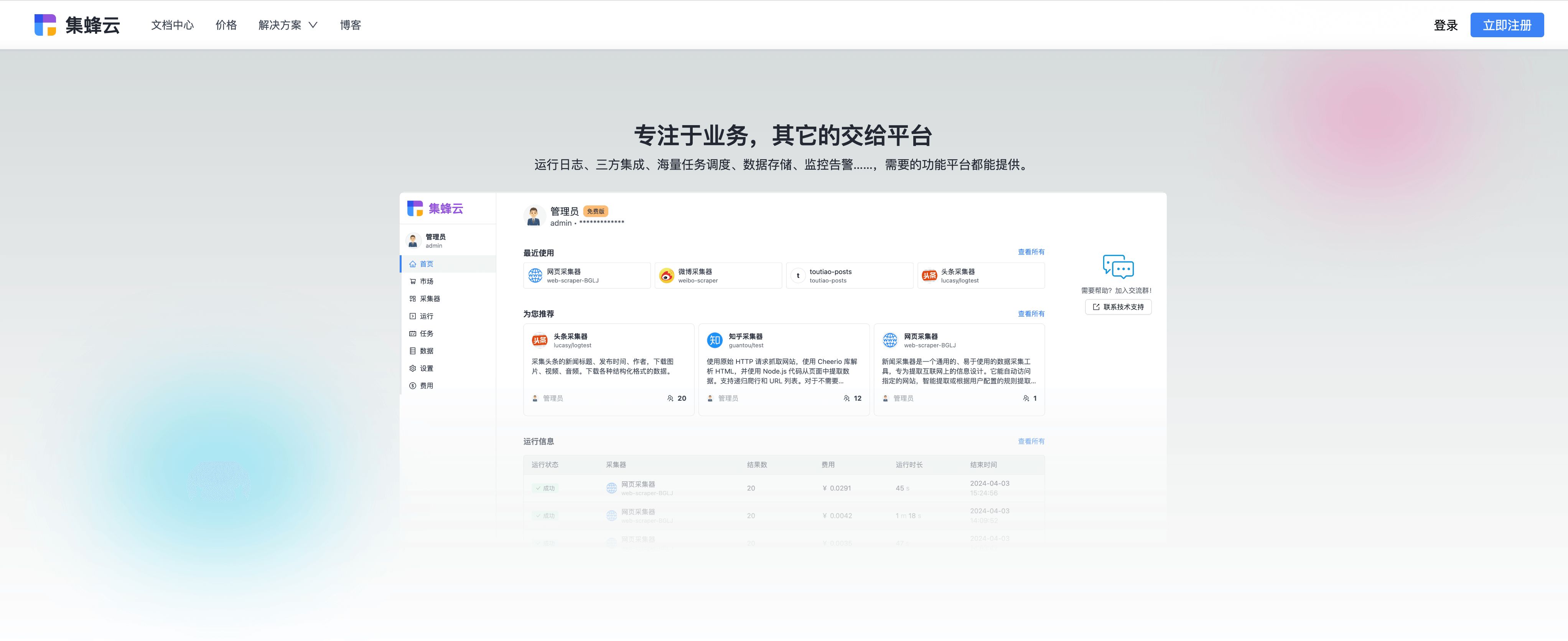
至此,你已掌握了构建基础Python爬虫管理系统的门道。未来,无论是个人兴趣驱动的小项目,还是服务于企业的复杂数据采集需求,你都拥有了开启探索的钥匙。对于更高阶的需求,推荐使用集蜂云平台,其提供的海量任务调度、三方应用集成、数据存储与监控告警等功能,能为你带来更高效、稳定的解决方案。