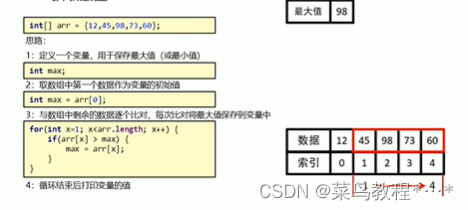
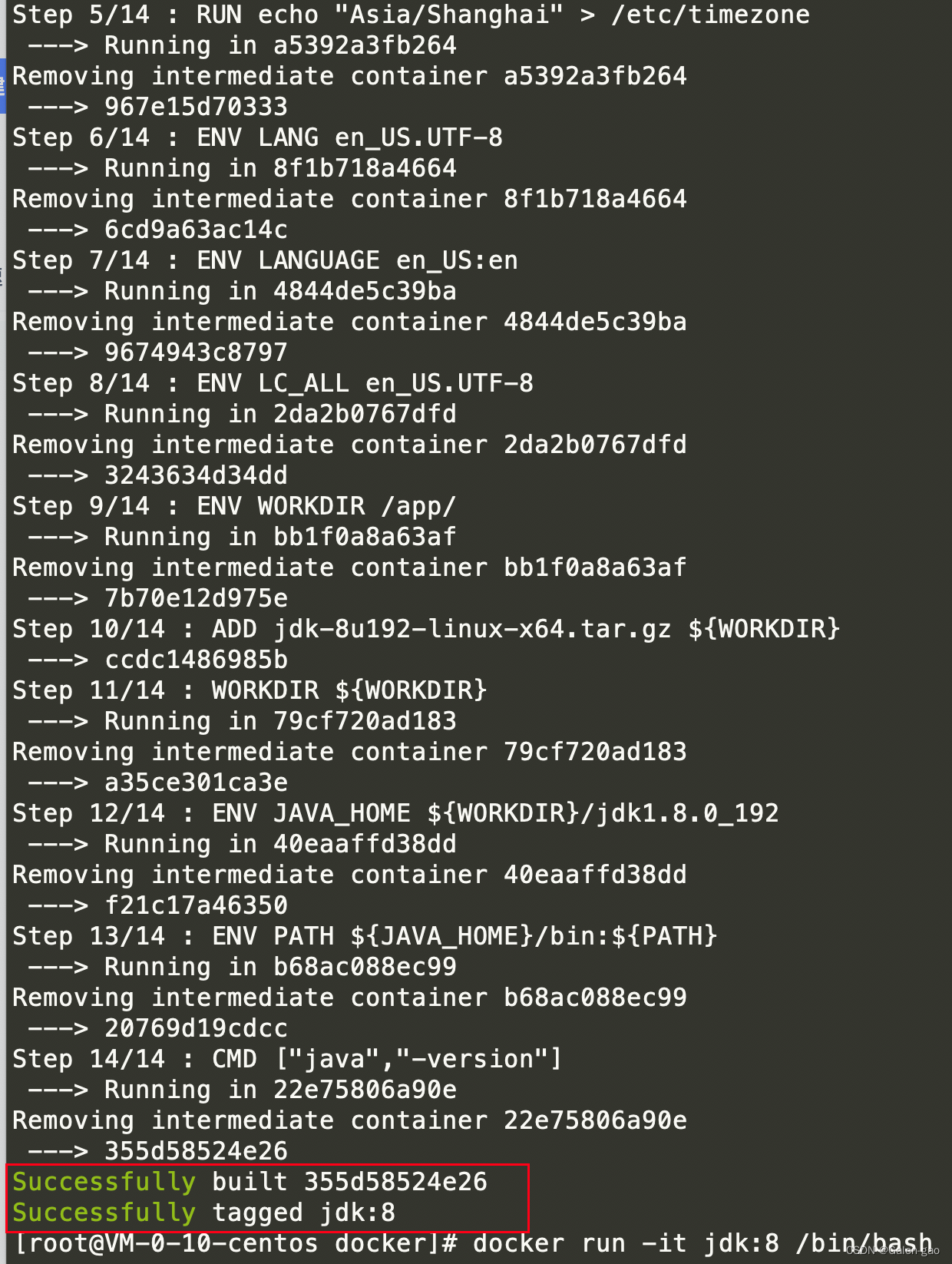
This way
题意:
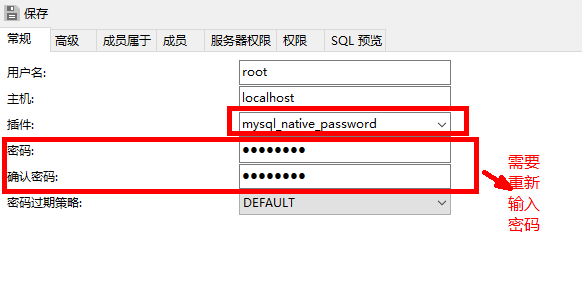
奶牛 Bessie 最近在学习字符串操作,它用如下的规则逐一的构造出新的字符串:
S
(
0
)
=
S(0) =
S(0)= moo
S
(
1
)
=
S
(
0
)
+
S(1) = S(0) +
S(1)=S(0)+ m
+
+
+ ooo
+
S
(
0
)
=
+ S(0) =
+S(0)= moo
+
+
+ m
+
+
+ ooo
+
+
+ moo
=
=
= moomooomoo
S
(
2
)
=
S
(
1
)
+
S(2) = S(1) +
S(2)=S(1)+ m
+
+
+ oooo
+
S
(
1
)
=
+ S(1) =
+S(1)= moomooomoo
+
+
+ m
+
+
+ oooo
+
+
+ moomooomoo
=
=
= moomooomoomoooomoomooomoo
… \dots …
Bessie 就这样产生字符串,直到最后产生的那个字符串长度不小于读入的整数 N N N 才停止。
通过上面观察,可以发现第
k
k
k 个字符串是由:第
k
−
1
k-1
k−1 个字符串
+
+
+ m
+
+
+
(
k
+
2
(k+2
(k+2 个
o
)
+
o) +
o)+ 第
k
−
1
k-1
k−1 个字符串连接起来的。
现在的问题是:给出一个整数
N
(
1
≤
N
≤
1
0
9
)
N (1 \leq N \leq 10^9)
N(1≤N≤109),问第
N
N
N 个字符是字母 m 还是 o?
题解:
可以发现的是,它其实就像一个分治的模型。对于每一层来说,都可以分为左中右结构,左右是下一层的东西,中间才是这层的主体。
那么我们想要找到N这个位置是什么,其实也就是看N是落在哪一层的。然后在对于那一层看N是否是第一个位置即可。
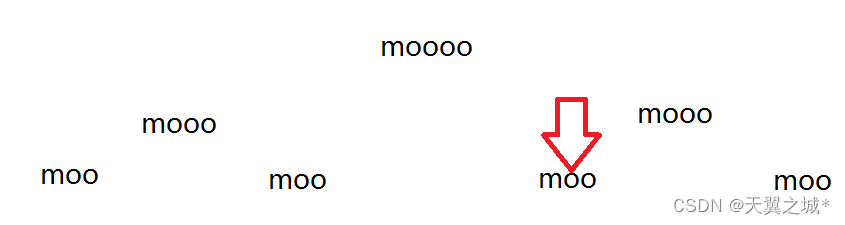
于是我们dfs搜索就是去定位到对应的层而已,可以先预处理len表示每一层的字符数量
#include<bits/stdc++.h>
using namespace std;
#define ll long long
const int N = 35;
ll len[N];
int mx;
void dfs(int x,int now){
while(len[now-1]>=x)now--;
if(len[now-1]+1==x)
printf("m\n");
else if(len[now-1]+now+2>=x)
printf("o\n");
else
dfs(x-len[now-1]-now-2,now-1);
}
int main()
{
int n;
scanf("%d",&n);
len[1]=3;
for(int i=1;len[i]<n;i++)
len[i+1]=len[i]*2+i+3,mx=i+1;
dfs(n,mx);
}