这里只会写Java相关的问题,包括Java基础问题、JVM问题、线程问题等。全文所使用图片,部分是自己画的,部分是自己百度的。如果发现雷同图片,联系作者,侵权立删。
- 1 基础问题
- 1.1 什么是并发,什么是并行?区别在哪?
- 1.2 同步和异步解释下?
- 1.3 常见的高并发场景有哪些?
- 1.4 面对高并发,常见的架构设计有哪些?
- 1.5 并发三要素了解吗?
- 1 锁相关问题
- 1.1 什么是死锁?
- 1.2 如何解决死锁?
- 1.3 java 如何检测死锁?
- 1.4 如何避免死锁?
- 1.5 什么是悲观锁?
- 1.6 Java中常见的悲观锁实现方式有哪些?
- 1.7 悲观锁有哪些特点?
- 1.8 乐观锁
- 1.8.1 什么是乐观锁?
- 1.8.2 怎么实现一个乐观锁?
- 1.8.3 什么是CAS算法?
- 1.8.4 CAS有什么问题?
- 1.8.5 乐观锁有什么特点?
- 1.8.6 乐观锁和悲观锁有什么区别?
- 1.9 synchronized
- 1.9.1 synchronized 是什么?
- 1.9.2 `synchronized`的基本作用是什么?
- 1.9.3 `synchronized`可以应用于哪些范围?
- 1.9.4 `synchronized`是如何实现线程同步的?
- 1.9.5 `synchronized`的锁是可重入的吗?
- 1.10 `volatile`
- 1.10.1 `volatile`是什么?
- 1.10.2 `volatile`作用是什么?
- 1.10.3 `volatile`怎么保证变量多线程之间可见?
- 1.10.4 `synchronized`与`volatile`的区别是什么?
- 1.11 冷门问题——`synchronized`在JDK 6及以后的版本中进行了哪些优化?
- 1.12 排他(X)锁和共享(S)锁了解吗?
- 1.13 公平锁和非公平锁了解吗?
- 1.14 ReentrantLock
- 1.14.1 ReentrantLock了解吗?
- 1.14.2 `ReentrantLock` 和 `synchronized` 的区别?
- 1.14.3 `ReentrantLock`实现`Condition`接口有什么用?
- 1.15 什么是可中断锁,什么是不可中断锁?
- 1.16 ReentrantReadWriteLock
- 1.16.1 介绍一下`ReentrantReadWriteLock`?
- 1.16.2 介绍一下`ReentrantReadWriteLock`特点?
- 1.16.3 介绍一下`ReentrantReadWriteLock`的读锁和写锁?
- 1.17 StampedLock
- 1.17.1 冷门问题——`StampedLock` 了解吗?介绍下
- 1.17.2 `StampedLock`和`ReentrantReadWriteLock`有什么区别?
- 1.18 Atomic
- 1.18.1 `Atomic`了解吗?介绍下?
- 1.18.2 `Atomic` 是怎么实现原子性操作的?
- 2 进程和线程相关问题
- 2.1 什么是进程?什么是线程?
- 2.2 线程
- 2.2.1 为什么使用线程?【使用线程有什么好处?】
- 2.2.2 如何创建一个JVM线程?
- 2.2.3 系统线程和JVM线程有什么区别?
- 2.2.4 使用`Runnable` 和 `Callable` 创建的线程有什么区别?
- 2.2.5 如何获取`Callable`的返回值
- 2.2.6 重点——简单描述一下线程生命周期,以及线程的每个状态是如何流转的?
- 2.2.7 `Thread::join` 方法有什么用?介绍下
- 2.2.8 `Thread::**yield**` 方法有什么用?介绍下
- 2.2.9 `Thread::sleep` 和 `Object::wait` 方法对比?
- 2.2.10 `Thread::start` 和 `Thread::run` 区别?
- 2.2.11 `Object::notify` 和 `Object::notifyAll` 区别?
- 2.2.12 多线程一定就效率高吗?
- 2.2.13 使用多线程会带来什么问题?
- 2.2.14 多线程开发下,如何保证线程安全?
- 2.2.15 介绍下线程上下文切换?
- 2.2.16 介绍下线程在系统中是如何调度执行的?
- 2.2.16 线程调度算法都有哪些?
- 2.2.17 线程活跃竞争问题有哪些?简单介绍下
- 2.2.18 在JVM内存布局中,哪些是线程私有的?
- 2.3 进程
- 2.3.1 进程生命周期状态有哪些?
- 2.3.2 进程之间如何通信?
- 2.3.3 什么是僵尸进程?它有什么危害?如何解决?
- 3 线程池相关问题
- 3.1 什么是线程池?
- 3.2 为什么使用线程池?【使用线程池有什么好处?】
- 3.3 如何创建一个线程池?
- 3.4 为什么不推荐使用`Java Executors`提供的内置线程池工具?
- 3.5 有哪些类型的线程池?分别有什么特点?
- 3.6 线程池参数有哪些?每个参数都有什么含义?
- 3.7 一个任务进入线程池后,线程池会做哪些处理?
- 3.8 线程池任务拒绝策略有哪些?
- 3.9 线程池的任务队列都有哪些类型?每种队列都有什么特点?
- 3.10 线程池中的线程数量该怎么设置?
- 3.11 线程池中线程运行异常,线程会销毁还是保持活性?
- 3.12 如何获取线程池中,线程任务执行结果?
- 3.13 线程池阻塞队列介绍下?
- 3.14 线程池 `execute()`和 `submit()` 方法有什么区别?
- 3.15 为什么线程池阻塞队列泛型类型是`Runnable`,但是可以通过submit() 将 `Callable` 任务放入阻塞队列中?
- 4 高并发相关问题
- 4.1 什么是高并发?
- 4.2 高并发有什么特点?
- 4.3 常见的高并发问题?
- 4.4 怎么解决高并发?
1 基础问题
1.1 什么是并发,什么是并行?区别在哪?
并发和并行都指同一个时间内,同时有多个执行单元执行。例如同一时间内,有多个线程同时执行。
区别在于,并发指同一时间段内有多个执行单元执行,而每个执行点只有一个执行单元执行。并行则是同一个时间点内有多个执行单元执行。
1.2 同步和异步解释下?
同步在一段处理逻辑里,一个请求发出后,执行陷入阻塞,必须得到请求响应结果,才可以继续执行。异步则是在请求发出后,无需等待响应结果,继续执行。
1.3 常见的高并发场景有哪些?
- 电商红包秒杀
- 社交媒体热点事件
- 在线游戏的大型多人对战
1.4 面对高并发,常见的架构设计有哪些?
- 缓存:高并发性能瓶颈一般出现在数据访问层,利用缓存可以提高数据访问效率,降低系统延迟。
- 分布式系统+负载均衡:利用分布式扩展机器资源,可以增加访问带宽,可以处理更多的并发请求。利用负载均衡可以平衡分布式机器资源,提高系统可用性。
- 异步处理:对于一些请求可以异步处理,避免请求堆积,导致系统崩溃。
- RDB数据库优化:利用分库分表等技术,提高数据的访问效率。
- 限流和熔断:限制流量输入,避免系统因为流量过载而崩溃。通过熔断机制,可以避免流量突增引起的系统持续不可用问题。
1.5 并发三要素了解吗?
并发三要素是原子性、可见性和有序性。
- 原子性:指操作要么全部完成,要么全部失败
- 可见性:并发编程下,线程对
共享变量的修改对其他线程是可见的 - 有序性:程序执行必须按照代码先后顺序来执行
1 锁相关问题
1.1 什么是死锁?
死锁一般包括进程死锁和线程死锁,但都是在并发场景下,两个或者多个执行单元由于争夺资源而陷入持续等待,一直陷入阻塞的场景。形成死锁有四个必要条件:
- 互斥条件:执行资源同一时间只能被一个执行单元获取
- 请求与保持条件:每个执行单元在获取执行资源之前,一直保持对执行资源的请求
- 循环等待条件:多个执行单元由于资源依赖而形成一个阻塞环,每个环节点都等待上一个节点释放资源。
- 不可剥夺条件:资源被占有后,除非主动释放,否则无法被其他执行单元获取。
最好列举个场景,不然表述不清,面试官也不容易理解。
1.2 如何解决死锁?
解决死锁的办法就是破坏死锁形成条件中的任意一个,即可避免整体阻塞。
例如对于互斥条件+请求与保持条件,可以将资源的获取看成一个原子性操作,即要么全部获取资源成功,要么全部获取资源失败。
例如对于不可剥夺条件对于资源占有,也可以设置超时时间,如果超过超时时间,则主动释放资源占用。
例如对于循环等待条件,可以定义资源的请求顺序,释放时倒序,避免循环等待。
一个执行单元需要
ABC三个资源,无序下,可以先获取ABC中任意一个。假设有两个执行单元T1和T2,T1获取了A,T2获取了B,那么T1再获取B时,由于不可剥夺特性,则会阻塞,T2获取A同理。
有序下,则可以解决这种问题,例如规定ABC三个资源,必须先获取A,然后B,最后C。对于T2,则不可能存在获取B的情况下,而没有获取到A。也就是说T1不会被T2阻塞,T1可以继续正常获取B,从而避免了资源请求的循环等待。
1.3 java 如何检测死锁?
使用jmap、jstack等命令查看 JVM 线程栈和堆内存的情况,如果有死锁,jstack 的输出中通常会有 Found one Java-level deadlock的字样。也有一些Java自带的检测工具,比如JConsole,可以直接看到死锁信息。
1.4 如何避免死锁?
和解决死锁问题原理差不多,只要破坏死锁条件即可。
避免死锁的关键就是资源分配,可以借助一些算法思想来避免死锁。比如著名的银行家算法,设置一个资源分配顺序,每次分配资源之前,进行安全性判断,如果满足则分配,不满足则拒绝。
还有一些基础的思想,比如减小锁粒度,避免占用不必要的资源。设置资源占用超时时间,避免资源持续占用等。
1.5 什么是悲观锁?
悲观锁是一种思想,主要表达的是——并发场景下,对一个资源的访问,悲观者认为该资源访问过程中,总是会受到其他因素影响,从而影响最终执行结果。
针对这种情况,悲观者每次访问资源之前都对其加锁,屏蔽其可见性,从而保证资源只能被悲观者获取执行。
常见的悲观锁实现方式有MySQL的行级锁,表级锁等。
1.6 Java中常见的悲观锁实现方式有哪些?
常见的有synchronized和ReentrantLock。
synchronized是Java的一个关键字,提供了锁机制。被synchronized修饰的资源,比如变量、类等,在同一时间只能被一个线程获取和使用。
ReentrantLock是Java提供的一个工具包装类,允许线程可以对资源进行包装,并且手动的加锁和释放锁。被ReentrantLock包装的资源,同一时间只能有一个线程获取和使用。
1.7 悲观锁有哪些特点?
- 访问资源之前,会提前加锁,防止其他执行单元获取资源。
- 被锁资源,在锁未释放前,对其他执行单元该资源是不可见,不可访问的。
- 会降低并发量,其他执行单元由于获取不到资源,会一直阻塞。
- 适合写多读少的场景
1.8 乐观锁
1.8.1 什么是乐观锁?
乐观锁是一种思想,主要表达的是——并发场景下,对一个资源的访问处理,乐观者认为该资源的访问处理过程中,其他人获取该资源并不会影响其本身的提交执行结果。乐观锁是一种逻辑概念,会在最终交付时,比较执行结果是否符合预期,如果不符合则认为受其他因素影响,拒绝交付。
1.8.2 怎么实现一个乐观锁?
乐观锁可以通过CAS算法来实现,比较常见的是version + CAS,比如在数据库访问过程中,对每个记录增加一个版本号,每次修改数据库记录时,比较提交的版本号是否符合预期,如果符合则允许修改。
1.8.3 什么是CAS算法?
CAS = compare and swap,即比较后再交换。比如在数据库中,访问修改一个数据记录,这个数据记录有一个版本号字段——CAS = version。每次修改前,需要访问获取数据库记录。假设初始有两个线程T1和T2,两个线程并发访问数据库记录,T1和T2初始读的数据记录中,version版本号一致,都为1。在T1修改数据库记录提交后,判断version版本号是否和T1所持有的一直,一直都是1,更新数据,并更新版本号为2。T2在提交数据时判断版本号是否一致,由于和记录版本号不一致,拒绝执行。
简单来说,CAS就是每次提交修改之前,都和原始数据进行比较,如果一致则提交执行。
1.8.4 CAS有什么问题?
存在ABA问题,假设用version来做CAS设计,假设T1,T2线程获取到的版本号是1,T2做了相应的处理,将版本号改为2,此时T1还没有执行提交,而又有一个T3线程获取了资源,版本号为2。T3提交了执行,将版本号改为1。此时T1再来执行,由于T1的版本号和当前版本号一致,所以T1提交了数据更新。如果T3更新提交后,并没有回滚数据到T1获取时的状态,则T1提交后,可能和预期结果不一致,从而导致一些数据一致性问题。
1.8.5 乐观锁有什么特点?
- 逻辑上概念,实际并不会对资源进行加锁处理,而是在提交时通过比较手段,来更新资源。
- 被锁资源,仍然可以被其他线程获取使用
- 适合读多写少的场景
- 并发编程下,减少锁资源互斥,提升并发性能。
1.8.6 乐观锁和悲观锁有什么区别?
- 实现思路不一样,并发场景下,乐观锁认为其他线程对当前资源处理无影响,悲观锁相反。
- 适用场景不一样,乐观锁适合读多写少,资源竞争少的情况;悲观锁适合写多读少的情况,资源竞争比较激烈的情况。
- 资源使用不一样,悲观锁资源使用远大于乐观锁
- 加锁场景不一样,乐观锁加锁后,其他任务仍然可以读取该资源信息;悲观锁加锁后,资源不能被其他任务访问。
1.9 synchronized
1.9.1 synchronized 是什么?
synchronized是Java语法中的一个关键字,可以修饰代码块、静态方法和实例方法,主要是解决线程同步执行时,资源互斥问题。
1.9.2 synchronized的基本作用是什么?
synchronized是Java中的一个关键字,用于控制对共享资源的并发访问,确保线程安全。它的基本作用包括:
- 互斥性:确保一次只有一个线程可以执行某个方法或代码块。
- 可见性:保证线程在执行过程中对共享资源的修改对其他线程是可见的。
- 原子性:确保被
synchronized修饰的代码块或方法中的操作是原子的,即不可被中断的。
1.9.3 synchronized可以应用于哪些范围?
synchronized可以应用于以下范围:
- 实例方法:作用于当前对象实例,进入同步代码前要获得当前对象实例的锁。
- 静态方法:作用于当前类,进入同步代码前要获得当前类对象的锁(即类的Class对象锁)。
- 代码块:指定加锁对象,对给定对象加锁,进入同步代码块前要获得给定对象的锁。
1.9.4 synchronized是如何实现线程同步的?
synchronized通过Java虚拟机(JVM)的内置锁(Monitor)来实现线程同步。当一个线程访问某个对象的synchronized方法或代码块时,它会尝试获取该对象的锁。如果锁已被其他线程持有,则当前线程将被阻塞,直到锁被释放。
在JVM中,每个对象都有一个与之关联的Monitor对象,该对象包含了锁的状态信息和等待队列等。当线程尝试获取锁时,如果锁未被占用,则线程将锁标记为占用状态并继续执行;如果锁已被占用,则线程将被加入等待队列中等待。
1.9.5 synchronized的锁是可重入的吗?
是的,synchronized的锁是可重入的。这意味着同一个线程可以多次获得同一个对象的锁,而不会导致死锁。JVM会为每个锁维护一个计数器,当线程第一次获得锁时,计数器加1;当线程每次重新进入同步代码块时,计数器也会加1;当线程退出同步代码块时,计数器减1。只有当计数器减为0时,锁才会被释放。
1.10 volatile
1.10.1 volatile是什么?
volatile是Java的一个关键字,主要是用来修饰变量,让变量多线程之间是可见的,而且变量初始化时跳过指令重排。
1.10.2 volatile作用是什么?
- 保证变量的修改在多线程之间是可见的
- 屏蔽变量在初始化时——指令重排
1.10.3 volatile怎么保证变量多线程之间可见?
通过内存屏障来保证变量在多线程之间可见。
每个线程在修改直接内存中的数据信息时,首先是会将直接内存的数据复制到线程内部缓存中,然后在线程内部缓存修改数据信息后,最后同步给直接内存来达到数据修改目的。volatile则是提供一个内存屏障,屏蔽线程内部缓存,让线程访问数据时直接访问直接内存。当被volatile修饰的变量,每次都访问的是直接内存。
1.10.4 synchronized与volatile的区别是什么?
synchronized和volatile都是Java中用于并发编程的工具,但它们的用途和原理有所不同:
- 用途:
volatile主要用于解决变量在多个线程之间的可见性问题,即确保一个线程对变量的修改能够被其他线程立即看到;而synchronized则主要用于解决多个线程同时访问共享资源时的互斥问题。 - 原理:
volatile通过内存屏障来保证变量的可见性和有序性;而synchronized则是通过内置锁(Monitor)来实现对共享资源的互斥访问。 - 使用范围:
volatile只能用于变量;而synchronized可以用于方法、代码块以及静态方法。
1.11 冷门问题——synchronized在JDK 6及以后的版本中进行了哪些优化?
在JDK 6及以后的版本中,synchronized进行了多项优化以提高性能,包括:
- 偏向锁(Biased Locking):在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得。偏向锁就是利用了这一特性,通过CAS操作将锁标记为偏向某个线程,从而减少线程获取锁的开销。
- 轻量级锁(Lightweight Locking):当存在多个线程竞争锁时,如果线程之间的锁竞争不是很激烈,则可以使用轻量级锁。轻量级锁通过自旋(Spinning)来尝试获取锁,从而避免线程阻塞和上下文切换的开销。
- 锁消除(Lock Elimination):JVM在编译时如果发现某些锁的加锁和解锁操作是多余的,则会进行锁消除优化,以提高性能。
1.12 排他(X)锁和共享(S)锁了解吗?
排它锁也叫独占锁,写锁,被X锁锁住的资源,无法被其他任务共享。其他任务要是使用,必须等X锁释放后,再去使用。S锁也叫读锁,被S锁锁住的资源,其他任务可以给资源再加S锁,加了S锁的任务,可以继续读取资源,但不能修改。
1.13 公平锁和非公平锁了解吗?
公平锁指多任务调度情况下「也可以理解为多线程申请访问资源时」,如果资源已经被锁,则其他任务陷入调度。如果资源被释放,则等待时间最长的任务先获取资源并加锁。类似一个队列,符合FIFO获取资源。
非公平锁指多任务调度情况下,锁住资源释放,每个任务都有机会获取执行资源加锁。
1.14 ReentrantLock
1.14.1 ReentrantLock了解吗?
ReentrantLock是java提供的锁工具,与synchronized类似,是一个可重入同步锁。不过ReentrantLock功能更加强大,具有高度的灵活性,提供丰富的功能支持,比如非公平锁、公平锁、超时中断、轮询获取等。
ReentrantLock默认是非公平锁,可中断锁。
结构继承图

1.14.2 ReentrantLock 和 synchronized 的区别?
ReentrantLock是Java提供的API锁工具类,synchronized是Java提供的锁关键字,基于JVM实现。ReentrantLock比synchronized更加灵活,ReentrantLock支持手动加锁和释放,自己可以控制范围。ReentrantLock是可以响应锁中断,提供了lockInterruptibly()方法,在线程获取锁的过程中,如果响应中断,可以中断获取锁行为;synchronized则不行,等待锁的线程无法响应中断。如果线程在等待锁的过程中被中断,它会继续等待,直到获取到锁。ReentrantLock既是公平锁,也是非公平锁,默认非公平锁;synchronized它实现的是非公平锁,即无法保证等待时间最长的线程能够最先获取到锁。ReentrantLock内部实现了condition接口,可以与锁绑定多个条件变量。每个条件变量都提供了自己的等待/通知机制,这使得线程间的协作更加灵活。synchronized没有提供条件变量,每个线程的唤醒和等待操作,都是用Object类来实现的。
1.14.3 ReentrantLock实现Condition接口有什么用?
Condition是Java提供的条件接口,内部包含了线程唤醒和等待的方法。可以在ReentrantLock中注册多个Condition实例,用于选择性的唤醒和等待线程,使线程调度更加灵活。
1.15 什么是可中断锁,什么是不可中断锁?
- 可中断锁指线程在获取锁的过程中,可以直接中断获取行为,从而去处理其他逻辑。
- 不可中断锁指线程在获取锁的过程中,不可以被中断,只有获取到锁后,才能处理其他逻辑。
1.16 ReentrantReadWriteLock
1.16.1 介绍一下ReentrantReadWriteLock?
ReentrantReadWriteLock 是Java提供的一个锁工具,内部有两种锁——读锁和写锁,保证了读写分离,是一个可重入锁。ReentrantReadWriteLock一般用于读多写少的场景,比如缓存、数据库连接池等。
1.16.2 介绍一下ReentrantReadWriteLock特点?
- 读锁和写锁分离,线程在同一时间只能获取一种锁
ReentrantReadWriteLock是可重入锁,允许重复获取ReentrantReadWriteLock是既是公平锁,也是非公平锁ReentrantReadWriteLock内部允许锁降级,但只允许写锁降级为读锁,不允许读锁降级为写锁
1.16.3 介绍一下ReentrantReadWriteLock的读锁和写锁?
- 读锁:
ReentrantReadWriteLock的读锁是一种共享锁,允许多个线程同时获取读锁,即可以提高并发效率。 - 写锁:
ReentrantReadWriteLock的写锁是一种排他锁【独占锁】,只允许一个线程获取写锁。写锁可以降级为读锁,但是读锁不可降级为写锁。
1.17 StampedLock
1.17.1 冷门问题——StampedLock 了解吗?介绍下
StampedLock是Java8提供的一个锁工具,内部包含读锁、写锁,允许乐观读获取读锁。StampedLock所有的锁实现都是悲观锁,而且StampedLock的写锁只允许一个线程获取,读锁可以允许多个线程获取,但不支持线程重入获取锁。
1.17.2 StampedLock和ReentrantReadWriteLock有什么区别?
StampedLock因为内部使用了乐观读机制,所以一般StampedLock的性能比ReentrantReadWriteLock好。StampedLock是不可重入锁,ReentrantReadWriteLock是可重入锁。- 获取读锁的方式不同,
StampedLock采用的是乐观读获取锁,ReentrantReadWriteLock则是直接获取。
StampedLock参考文档:https://segmentfault.com/a/1190000015808032
1.18 Atomic
1.18.1 Atomic了解吗?介绍下?
Atomic是Java提供的原子类工具,常见的有AtomicInt、AtomicLong等。
1.18.2 Atomic 是怎么实现原子性操作的?
Atomic内部采用了 volatile + CAS来实现原子操作。
2 进程和线程相关问题
2.1 什么是进程?什么是线程?
进程是系统基础运行单元,是一段运行程序,是系统资源分配和调度的最小单位,例如JVM就是一个进程。线程是基于进程之上的,是系统最小的执行单元,大部分资源来源于进程,本身拥有少量资源,例如程序计数器、虚拟机栈等。
2.2 线程
2.2.1 为什么使用线程?【使用线程有什么好处?】
线程是系统最小的执行单元,使用线程有如下好处:
- 可以充分的利用多核CPU资源,提高系统运行效率
- 可以提高程序的并发性能,降低系统延迟
- 降低程序系统开销,因为线程的资源是依赖进程的
- 简化系统程序之间的通信,例如共享内存和资源
- 可以提高程序灵活性,比如同步和异步
2.2.2 如何创建一个JVM线程?
创建JVM线程有很多方式,常见的有:
- 继承
Thread类 - 实现
Runnable接口 - 实现
Callable接口和FutureTask类 - 利用线程池创建
2.2.3 系统线程和JVM线程有什么区别?
简单说下就行了,没必要说的那么深
- JVM的线程是基于JVM进程创建的,线程本身的调度与资源分配,由JVM控制;线程的资源全部来自于JVM进程。系统线程则是依赖于操作系统,不同的操作系统其线程实现方式不同,而且系统线程包含内核态线程、用户态线程等。
- JVM线程在不同的JDK版本有不同的实现,早期的JVM线程是基于操作系统的原生线程实现的,现在大多使用的JVM线程则是用户线程,也就是说现在的线程都是独立自主的。
- JVM线程生命周期状态由JVM控制,系统线程则由操作系统控制。
2.2.4 使用Runnable 和 Callable 创建的线程有什么区别?
Runnable没有返回值,Callable有返回值。
2.2.5 如何获取Callable的返回值
Callable接口的实现类一般被FutureTask构造方法使用,执行线程会返回一个Future对象,调用Future对象的get()方法,可以获取Callable的返回值
2.2.6 重点——简单描述一下线程生命周期,以及线程的每个状态是如何流转的?
线程状态
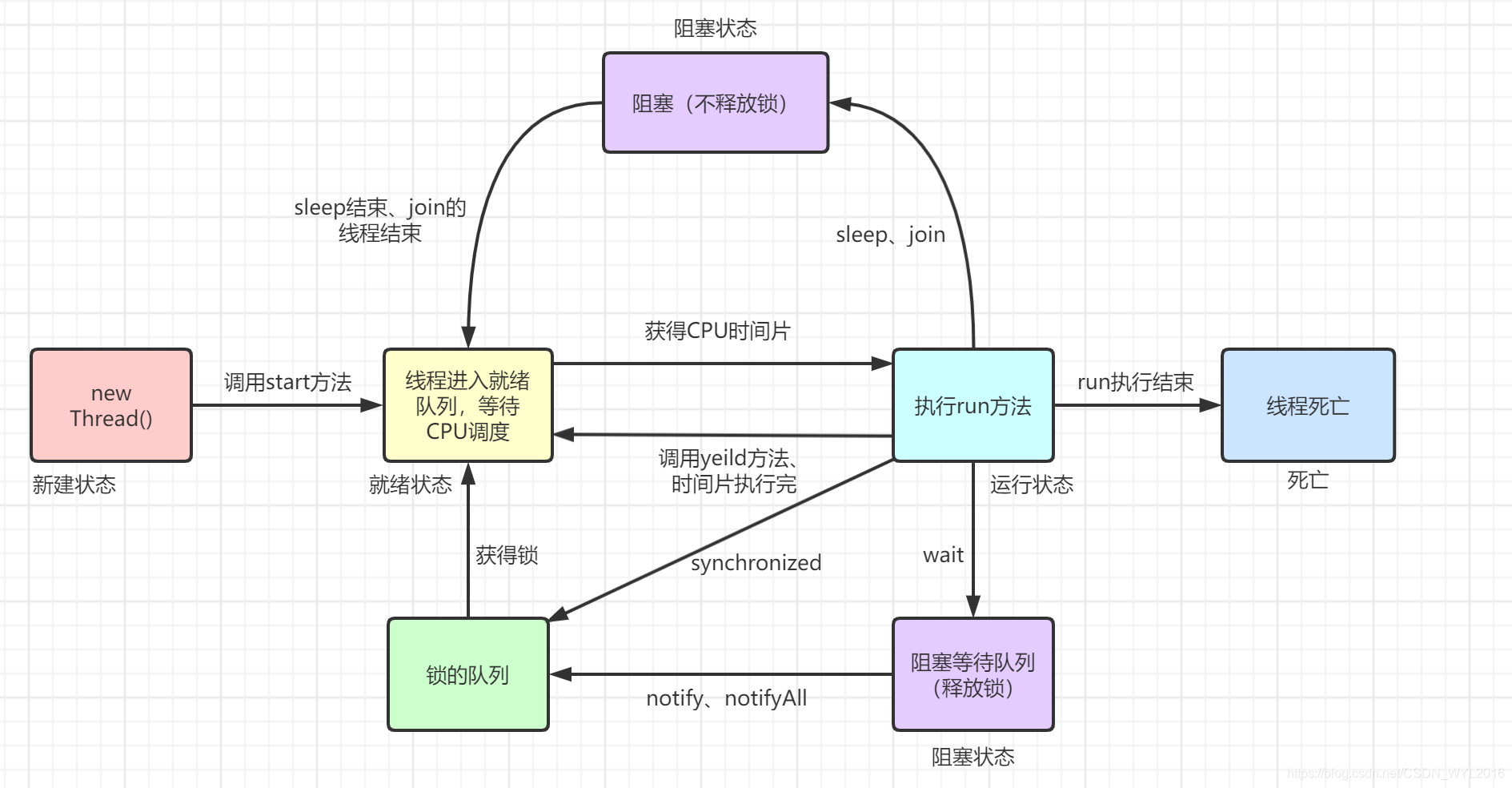
线程生命周期的状态包括,NEW(新建)、Runnable(就绪)、Running(运行)、Block(阻塞)、Time waiting(超时等待)和 Dead(死亡)。
- NEW(新建):调用
Thread::new方法时,线程处于新建状态,是线程的初始状态 - Runnable(就绪):调用
Thread::start方法后,或者线程阻塞完毕,就会进入就绪状态,等待CPU调用执行 - Running(运行):就绪状态下的线程获取到执行时间片后,会进入运行状态,运行线程任务。
- Block(阻塞):线程的时间片执行完成,就会进入阻塞状态,等待下一次系统调度
- Time waiting(超时等待):超时等待相当于在阻塞状态上增加了超时时间,如果超过阻塞时间,则进入调度队列,等待CPU调度。
- Dead(死亡):死亡状态,表示线程已经执行完毕
2.2.7 Thread::join 方法有什么用?介绍下
Thread::join 方法作用是将另外一个线程加入到当前线程的执行计划中,当前线程只有等另外一个线程执行完毕后才能执行当前线程。例如线程A join 线程B,线程A会陷入阻塞等待状态,只有在线程B执行完毕后,线程A才会继续调度。
2.2.8 Thread::**yield** 方法有什么用?介绍下
Thread::yield 方法主要作用是让出当前线程执行时间片资源,让线程进入就绪状态,等待系统调度运行。
2.2.9 Thread::sleep 和 Object::wait 方法对比?
Thread::sleep方法会让线程陷入沉睡状态,本身不会释放线程占用的任何锁资源。如果睡眠时间到达,则会唤醒线程继续执行。Object::wait方法则会让线程进入等待阻塞池,本身只会让出监听锁资源,只有等待其他线程唤醒,才会继续执行。
Thread::sleep一般用于控制线程执行节奏,Object::wait 则是用于线程之间的通信。
2.2.10 Thread::start 和 Thread::run 区别?
调用 Thread::run方法本身不会启动线程,只是一个普通的对象实例方法。Thread::start则是让线程启动,进入就绪状态,等待JVM调度执行。
2.2.11 Object::notify 和 Object::notifyAll 区别?
Object::notify会唤醒监听当前对象的线程,只会唤醒一个,具体唤醒那个由系统的调度算法决定。Object::notifyAll则会唤醒监听当前对象的所有线程,所有线程去竞争该对象锁,只有竞争到对象锁的线程才会执行,其他线程则会继续阻塞等待。
2.2.12 多线程一定就效率高吗?
多线程不一定比单线程效率快,比如在一些计算任务里面,采用多线程不如单线程效率高,因为多线程之间存在上下文切换,线程调度等一些列操作,这些操作会影响执行效率。
2.2.13 使用多线程会带来什么问题?
一般常见的问题包括:
- 死锁问题,多线程操作经伴随锁资源竞争,容易发生死锁
- 线程安全问题,多线程会对共享资源做操作,如果没有合理的锁控制,则会引发线程安全问题
- 程序编程难度上升,可能容易引发系统漏洞
- 上下文切换,造成多余的资源浪费
2.2.14 多线程开发下,如何保证线程安全?
一般引发线程安全问题的,都是锁资源使用不当,程序结构设计不当引起的。基本的常见方法包括:
- 使用恰当的同步机制和原子操作
- 使用并发工具类管理共享资源,比如并发集合等
- 使用锁机制,保证资源的竞争安全性
- 尽量避免使用共享资源,做合理的线程设计
2.2.15 介绍下线程上下文切换?
线程上下文切换的目的是实现多线程的并发执行,通过保存当前线程的上下文信息(包括寄存器信息、栈信息等),并将新的线程的上下文信息加载到CPU中,以便新的线程可以继续执行。这样,多个线程可以交替执行,从而充分利用CPU资源,提高程序的执行效率和响应速度。
2.2.16 介绍下线程在系统中是如何调度执行的?
线程在系统中的调度模型主要有两种,分别是抢占式调度**和**时间片式调度(分时式调度)。
抢占式调度:线程池中线程根据优先级进行排序,每次调取优先级最高的线程进行调度执行,适合优先级层次补齐的线程池。时间片式调度(分时式调度)**: **给线程池中的线程每次分配一个时间片,每次调度取有时间片的线程进行执行,适合优先级相等线程池。
2.2.16 线程调度算法都有哪些?
常见的算法包括:
- 先进先出(FIFO)调度:按照线程任务进入顺序放入到一个队列中,每次从队列中获取一个任务进行执行。
- 最短时间调度:按照线程任务的执行时间排序,每次取执行时间最短的任务进行调度执行。
- 时间片轮询调度:维护一个队列,将任务按照进入顺序放入到队列中。按FIFO获取线程任务,每次给线程分配时间片,当时间片执行时间到达时,如果任务完成,则移出队列;如果没有完成,则将未完成的任务放入到队列中,等待下一次调度。
- 多级队列调度算法:和时间片轮询调度相似,不过每次分配时间片的大小是递增的。
- 优先级抢占调度:给线程分配调度优先级,根据优先级排序,每次取最高优先级线程任务调度。
2.2.17 线程活跃竞争问题有哪些?简单介绍下
活跃竞争问题包括饥饿,死锁,活锁。分别如下:
- 死锁:多线程之间竞争锁,由于锁一直被别的线程占用,又陷入相互等待,迟迟导致获取不到锁而被阻塞的一种情况。产生条件包括——请求与保持条件、循环等待条件、资源不可剥夺条件和资源互斥。
- 活锁:指线程已经获取了相关的锁资源,线程虽然一直执行,但一直没有到最终状态的情况。
- 饥饿:指线程迟迟获取不到资源,无法执行。一般发生在优先级调度策略中,低优先级线程一直被高优先级抢占资源无法执行。
2.2.18 在JVM内存布局中,哪些是线程私有的?
JVM内存布局中包括——堆内存、方法区、程序计数器、虚拟机栈、本地方法栈。其中,程序计数器、虚拟机栈和本地方法栈是线程私有的。
2.3 进程
2.3.1 进程生命周期状态有哪些?
运行、就绪、阻塞、挂起
2.3.2 进程之间如何通信?
- 消息管道:通过管道可以实现亲属进程之间的数据传输
- 消息队列:可以让进程将信号发送给消息队列,然后其他进程可以监听该消息队列,完成进程之间的通信
- 共享内存:可以通过进程修改共享内存内容,然后其他进程读取该共享内存内容,从而完成通信
- 信号量(Semaphore):信号量是一个计数器,用于控制多个进程对共享资源的访问。
- 套接字(Socket):不仅可用于同一台机器上的进程间通信,还可用于不同机器之间的网络通信。
2.3.3 什么是僵尸进程?它有什么危害?如何解决?
- 定义:僵尸进程是指子进程已经结束,但父进程尚未通过调用
wait()或waitpid()等系统调用来回收子进程的状态信息,从而导致子进程的进程描述符(PCB)仍然保留在系统中的进程。 - 危害:僵尸进程虽然不占用CPU和内存资源,但它们仍然占用系统中的一个进程表项,如果系统中存在大量僵尸进程,将导致进程表资源耗尽,影响新进程的创建。
- 解决:
- 杀死父进程:这将导致操作系统接管所有孤儿进程,并最终回收它们的资源。但这种方法可能会对其他依赖于父进程的应用程序产生不良影响。
- 重启父进程:如果父进程可以安全地重启,这将导致它重新初始化并回收所有僵尸子进程的资源。
- 发送SIGCHLD信号:向父进程发送SIGCHLD信号可以促使其调用
wait()或waitpid()来回收子进程的资源。这通常是处理僵尸进程的首选方法。
3 线程池相关问题
3.1 什么是线程池?
线程池是一个线程管理工具,主要是用于降低线程使用资源消耗。当有新的任务放入线程池后,现成的创建、调度、销毁都是通过线程池来管理。
3.2 为什么使用线程池?【使用线程池有什么好处?】
- 降低资源消耗:线程池避免了线程的重复创建和销毁对资源的消耗
- 提高系统性能:通常不用通过新建线程来接受新任务,大部分情况下会使用原本的活性线程执行任务。
- 降低编程难度:降低并发编程难度
- 提高系统稳定性:线程内部有一些的任务管理策略,可以通过这些策略提升系统稳定性。
- 支持不同任务类型:线程池对
Runable和Callable两种线程任务类型都支持。
3.3 如何创建一个线程池?
Java提供了两种创建线程池的方法,分别是:
- 通过
ThreadPoolExecutor构造方法创建 - 通过
Executors工具类创建
3.4 为什么不推荐使用Java Executors提供的内置线程池工具?
Java Executors 内置方法创建的线程都有一定的弊端。
- 比如利用
Executors::newFixedThreadPool和Executors::newSingleThreadPool创建的线程池,底层使用的阻塞队列是LinkedBlockingQueue,该队列是一个无界阻塞。如果有大量任务进入线程池,则可能会导致OOM。 - 比如利用
Executors::newCacheThreadPool创建的线程池,底层使用的是SynchronousQueue同步队列。虽然该队列是一个有界队列,但是它的边界值是Integer.MAX_VALUE,如果有大量慢任务插入线程池,可能会导致OOM。 - 比如利用
Executors::newScheduleThreadPool创建的线程池,底层使用的是DelayedWorkQueue延迟阻塞队列。虽然该队列是一个有界队列,但是它的边界值是Integer.MAX_VALUE,如果有大量请求堆积,可能会导致OOM。
3.5 有哪些类型的线程池?分别有什么特点?
FixedThreadPool固定线程池——特点是核心线程池数量等于最大线程池数量,该线程池底层使用了一个链表结构的阻塞队列,适合一些对稳定要求比较高的场景。SingleThreadPool单一线程池——特点是核心线程池数量等于最大线程池数量等于一,该线程池是特殊的FixedThreadPool,适合一些需要异步处理场景和对任务顺序严格控制的场景。CacheThreadPool缓存线程池——特点是线程池线程数量是动态设置的,该底层维护了一个同步队列,本身不存储任务,而是将任务直接提交给线程执行。该线程池适合任务量大,但耗时小的场景。ScheduleThreadPool调度线程池——特点是线程池数量是动态设置的,该底层维护了一个延迟队列。该线程池适合定时,或者周期性的任务场景。
3.6 线程池参数有哪些?每个参数都有什么含义?
参数有7个,分别是:
- 核心线程数量:表示线程池核心线程数量
- 最大线程数量:表示线程池最多可以允许多少个线程并发执行
- 超时时间:表示超过最大核心线程池的线程数量的线程,存活多长时间后被销毁
- 超时时间单位:存活时间单位
- 任务队列:用于接受进入线程池的线程任务
- 线程工厂:表示线程池创建线程方式
- 拒绝策略:表示新进入任务超过线程池最大任务数量后,线程池对该任务的处理方式
3.7 一个任务进入线程池后,线程池会做哪些处理?
step1:判断线程池线程数量是否小于核心线程池数,如果小于,新建一个线程,并且将这个任务分配给该新建线程
step2:如果大于核心线程池,则将任务放入到阻塞队列中
step3:如果阻塞队列已经满了,则判断线程数量是否大于核心线程池数,且小于最大线程数。如果是,则新建线程,将该任务分配给该线程
step4:如果线程已经等于最大线程数,则调用拒绝策略,拒绝执行该线程任务
3.8 线程池任务拒绝策略有哪些?
- AbortPolicy:默认策略,直接拒绝执行当前任务,并且抛出一个拒绝异常
- CallerRunsPolicy:将任务上抛,丢该父线程执行
- DiscardPolicy:丢弃当前任务
- DiscardOldestPolicy:丢弃等待时间最长的任务
此外,还可以实现RejectedExecutionHandler接口,自定义拒绝策略。
3.9 线程池的任务队列都有哪些类型?每种队列都有什么特点?
- 阻塞队列:常见的有ArrayBlockQueue和LinkedBlockQueue,该队列是一个线程安全队列,插入和移除操作都会阻塞队列,要求多个线程在同一个时间点只能由一个线程操作。
- 同步队列:也是阻塞队列的一种,但是它的容量是0,插入和移除操作都会阻塞。线程获取任务时,都是从队列中获取任务,同步队列则保证线程获取任务时不是从队列获取,而是从提交的地方直接获取。【一手交钱一手交货,没有中间商赚差价】
- 延迟调度队列:该队列存储的底层结构是优先级队列,每个任务都有一个延迟时间,每个任务到达延迟时间后,会根据优先级排序。线程获取任务时,先根据延迟时间判断,如果没有到达,则不会分配任务给线程。
3.10 线程池中的线程数量该怎么设置?
线程池一般在实际使用的时候,都要经过分类,主要分为如下三类:
- IO密集型线程池:该线程池的特点是有大量的IO型操作,例如常见的RPC线程池。一般设置该线程池线程数量时,建议数量 = CPU核数 * 2 + 1。因为IO密集的操作,特点是大量等待和上下文切换操作,一般不会长时间占用CPU资源。
- CPU计算密集型线程池:该线程池的特点是有大量的计算操作,计算操作在计算机中一般是CPU完成的。建议数量 = CPU核数 - 1,因为CPU计算密集的线程,大量上下文切换对计算不例,所以应尽量保证CPU资源充分利用。之所以减一,是因为预留一个线CPU核数
- 混合线程池:IO密集型线程池和CPU计算密集型线程池的混合,以CPU计算密集型线程池设置条件为主。
3.11 线程池中线程运行异常,线程会销毁还是保持活性?
Java线程池提交任务有两种方式,一种是调用线程池的execute(Task task)方法,获取该任务的线程,如果发生运行异常,则会直接销毁线程,并且抛出异常信息。另一种是调用线程池的的submit(Task task)方法,该方法会返回一个Future对象。在调用该对象的get()方法获取执行结果时,如果利用try-cache捕获并处理了异常,则线程不会被销毁,否则就销毁。
3.12 如何获取线程池中,线程任务执行结果?
首先要现成执行体实现了Callable接口,然后调用现成的submit()提交任务,该方法会返回一个Future对象。调用Future对象的get()方法可以获取到现成的执行结果。
3.13 线程池阻塞队列介绍下?
阻塞队列是线程池的一个构成参数,该阻塞队列主要是用来存储线程需要执行的任务,线程池需要从该队列中获取任务,并且分配线程去执行该任务。阻塞队列是安全性队列,遵循FIFO原则,添加和移除操作都有同步锁,保证了同一个时间点只允许一个线程操作该队列。
3.14 线程池 execute()和 submit() 方法有什么区别?
- 任务参数不同:
execute()方法参数是一个Runnable实例对象,submit()是Callable实例对象。 - 返回结果不同:
execute()方法没有返回对象,是Void,submit()返回一个Future实例对象,该对象存储了任务返回值。 - 底层实现不同:
execute()方法会将任务参数,直接添加到阻塞队列中。submit()则是先将任务参数用FutureTask对象包装,该FutureTask对象实现了Runnable接口,然后再将FutureTask包装对象添加到阻塞队列。
3.15 为什么线程池阻塞队列泛型类型是Runnable,但是可以通过submit() 将 Callable 任务放入阻塞队列中?
submit() 底层会对任务参数用FutureTask对象包装,然后将FutureTask对象添加到阻塞队列中。因为FutureTask类实现了Runnable接口,所以submit() 可以将Callable任务参数放到阻塞队列中。
4 高并发相关问题
4.1 什么是高并发?
高并发(High Concurrency)是指系统能够同时处理大量的请求或者连接,并且能够在短时间内响应这些请求。它主要发生在web系统集中大量访问,收到大量请求的场景中,例如12306的抢票情况、天猫双十一活动等。高并发会导致系统在这段时间内执行大量操作,如资源的请求、数据库的操作等,进而可能引发系统资源不足、响应变慢甚至宕机的问题。
4.2 高并发有什么特点?
- 大量请求:系统需要接受大量请求
- 同时访问:大量请求基本上都发生在同一时间点
- 资源竞争:请求之间存在资源的相互竞争
- 响应时间要求:一般对请求响应速率要求比较高,用户要求快速响应
4.3 常见的高并发问题?
- 请求延迟:由于大量请求,系统资源不够,可能引起请求延迟
- 资源竞争:资源抢夺比较激烈,可能会导致系统性能下降,例如死锁等
- 数据库瓶颈:在高并发场景下,数据库容易成为系统的瓶颈。数据库的读写性能、连接数和数据量等都可能成为制约系统性能的因素。
- 系统宕机:如果系统的容量和性能没有得到充分的规划和设计,一旦遭遇流量高峰,系统容易宕机。此外,系统的硬件故障、网络故障以及软件缺陷等也可能导致系统宕机。
4.4 怎么解决高并发?
- 优化代码和数据库:
- 通过优化查询语句和数据结构来提高数据库的查询效率。
- 使用缓存技术减少对数据库的访问次数,如Redis、Memcached等。
- 采用读写分离、数据库集群等方案来扩展数据库的容量和性能。
- 分布式部署和负载均衡:
- 将系统拆分成多个子系统,并将它们部署在不同的服务器上,实现分布式部署。
- 使用负载均衡技术(如Nginx)将用户请求分发到不同的服务器上,实现负载均衡和流量削峰。
- 限流和降级:
- 设置合理的限流策略,限制系统的并发请求数或QPS(Queries Per Second),避免系统因过载而崩溃。
- 在系统压力过大时,主动降低部分功能或服务的性能和可用性,以保证核心功能的稳定运行。
- 监控和预警:
- 监控系统的各项指标(如CPU使用率、内存占用率、响应时间等),及时发现系统存在的问题和瓶颈。
- 通过预警机制在问题发生前通知相关人员进行处理,保证系统的稳定性和可用性。
- 硬件升级和扩展:
- 根据系统需求升级服务器硬件性能,如增加CPU核心数、内存容量等。
- 通过增加服务器数量来分担用户请求的压力,实现水平扩展。
- 采用异步架构和微服务架构:
- 异步架构可以将耗时的操作放入消息队列等待处理,从而提高系统的并发处理能力。
- 微服务架构将系统拆分成多个小的服务单元,每个服务单元独立部署和扩展,从而有效分散高并发带来的压力。


![[数据集][目标检测]野猪检测数据集VOC+YOLO格式1000张1类别](https://i-blog.csdnimg.cn/direct/81004a10bc4046b89602613151df0c5f.png)