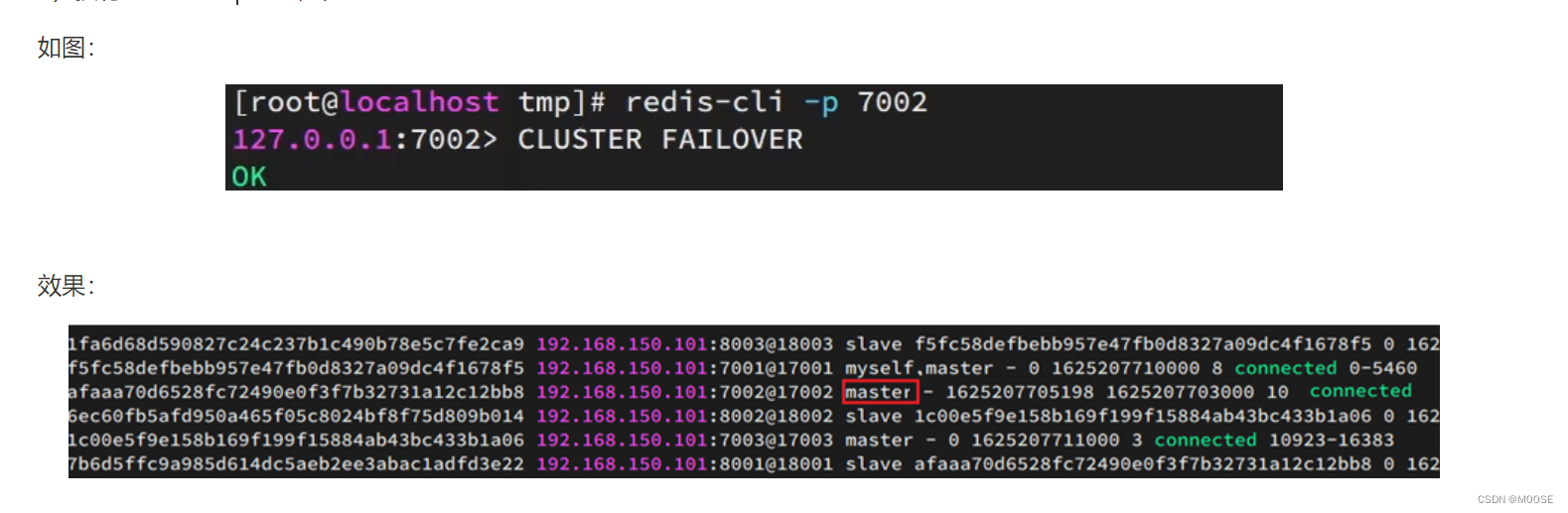
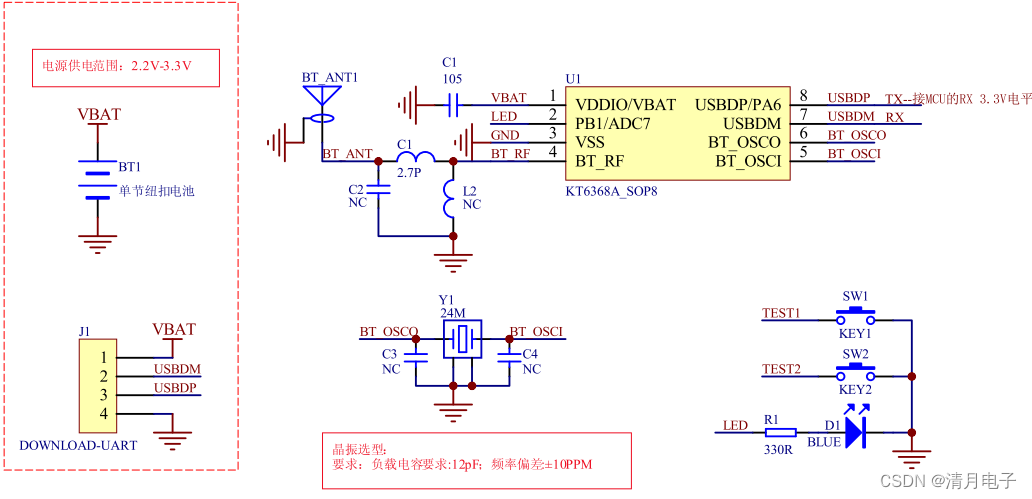
随着各行业数字化、智能化建设的脚步加快,OCR得到了普及应用。当前,OCR技术主要应用于标准证件、票据识别,通过自动检测并识别、提取文字,减少人工录入信息的工作量,提升业务效率。
目前,企业对OCR的识别精度、定制灵活度、迭代速度等有了更高的要求。范围有限的常规证件、发票识别已经无法满足企业业务场景中种类繁多的单证处理需求,越来越多的企业,开始定制OCR识别模型,以满足个性化的卡证、票据、文档识别需求。
定制OCR通常的方式有:委托外部厂商定制OCR模型,或自行开发OCR模型。
委托外部厂商定制OCR存在以下难点:
1.定制成本高
企业的业务场景复杂,需要识别多类型的卡证、票据、单据,且同类单据常会有多种版式,交付定制成本高昂。
2.定制周期长
厂商驻场定制开发识别引擎周期长、效率低、沟通对接时间成本高,技术能力无法很快赋能业务。尤其是对于定期会更改版式的银行单据,版式调整后需要厂商进行模型调适,工作流程长,效率低。
3.不固定版式文档识别率低
传统规则算法,在不固定版式上不具备很好的泛化能力。对于不固定版式文档,识别率低,可用性差,定制OCR时,常常需要对特定版式做高度定制化开发,存在重复采购风险。
4.业务数据保密性要求高
金融机构数据保密性要求强,可能无法对厂商提供业务数据作为训练样本,模型性能无法保障。
而自行开发模型可以满足模型迭代灵活性与数据保密性需求,但需要从零开始搭建技术团队、招聘算法人才,在研发成本与时间投入上,常常比采购外部服务更高,由于缺乏算法积累,在应对复杂场景与不固定版式文档上,生产的模型也较难具备可用性。
1.基于文字识别训练平台,自主开发OCR模型
除了上述两种方式,目前,一种更具效率、可用性、灵活性的OCR模型开发方式,正在被越来越多的企业所采用:依托外部厂商开发的文字识别训练平台,自主开发OCR模型。由于这些文字识别训练平台内置成熟的算法模型,企业不需要组建专业的算法团队,即可自行完成模型的创建、训练、部署全流程开发工作流。
合合信息基于在智能文字识别领域深耕16年的深度学习算法能力与实训经验,推出了文字识别训练平台,为有OCR自主定制开发需求的企业提供低代码、自动化的一站式OCR开发平台。


合合信息文字识别训练平台是面向零基础的开发者或实际业务人员的全流程一站式OCR开发平台。针对文本检测、文字识别、文档分类、信息抽取等任务,基于先进的深度学习算法,提供了集模型创建、数据标注、模型训练、模型测试、模型部署于一体的机器学习服务。
合合信息文字识别训练平台内置了场景丰富的预训练模型,配备了信息抽取(锚点)、信息抽取(K-V)、信息抽取(NLP)、信息抽取(长文本)、分类识别五大模型类型,以满足固定版式、半固定版式、不固定版式、长文本文档的识别与分类需求,根据文档特点创建适配的模型类型,有效提升识别精度,降低训练难度。
1.1信息抽取(锚点)
基于预置的文字检测与识别模型,针对固定版式的卡证票据,框选出版式参照区与所需提取的信息区域,即可实现数据的结构化提取。选择该模型无需训练,只需要一张样本配置好固定字段与识别字段后,即可直接完成模型创建。
1.2信息抽取(K-V)
基于内置的高性能预训练模型,针对用户标注的键值对位置和文本信息,训练专属场景的AI模型,从而提升文本检测、文本识别、字段属性分析的精度,此方法适用于半固定版式的文档分析,例如卡证、票据。
1.3信息抽取(NLP)
基于内置的多模态(图像、文本)高性能预训练模型,针对用户标注的键值对位置和文本信息,训练专属场景的信息抽取模型,从而提升文本检测、文本识别、字段属性分析的精度,此方法适用于不固定版式的文档分析,例如海外Invoice、物流单据、采购单据等。
1.4信息抽取(长文本)
智能化语义理解,不受文本空间位置变化影响,适用于多页不固定版式文档的信息抽取,例如合同、报告、标书、档案等。
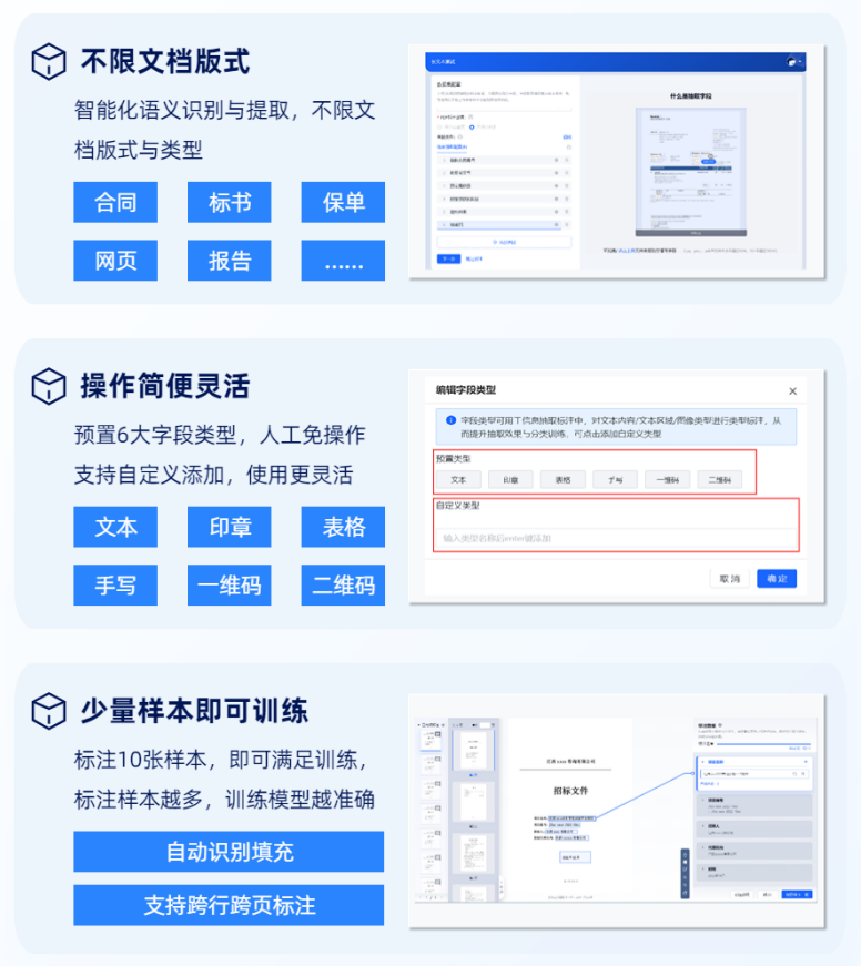
1.5分类识别
通过大量图片类型标注,基于深度学习算法学习图片特征,从而达到图片的分类识别。该模型有两种算法:纯图像算法模式,适合差异较大的图像分类;图像+文本算法模式,能对图像特征与文本特征进行特征融合处理,适合相似度较高的图像分类。
2.数据回流:终身自主学习
合合信息文字识别训练平台具备特有的数据回流功能,通过搭建数据回流交换平台连接业务平台(数据生产系统)与文字识别训练平台,将实际业务中产生的标注信息数据进行拉取、整合、格式转换与统计后回流至文字识别训练平台,并用于对应模型的训练、测试,提升模型的识别准确率,实现“在业务场景中越用越好用”的持续迭代效果,真正做到了智能化和终身学习。

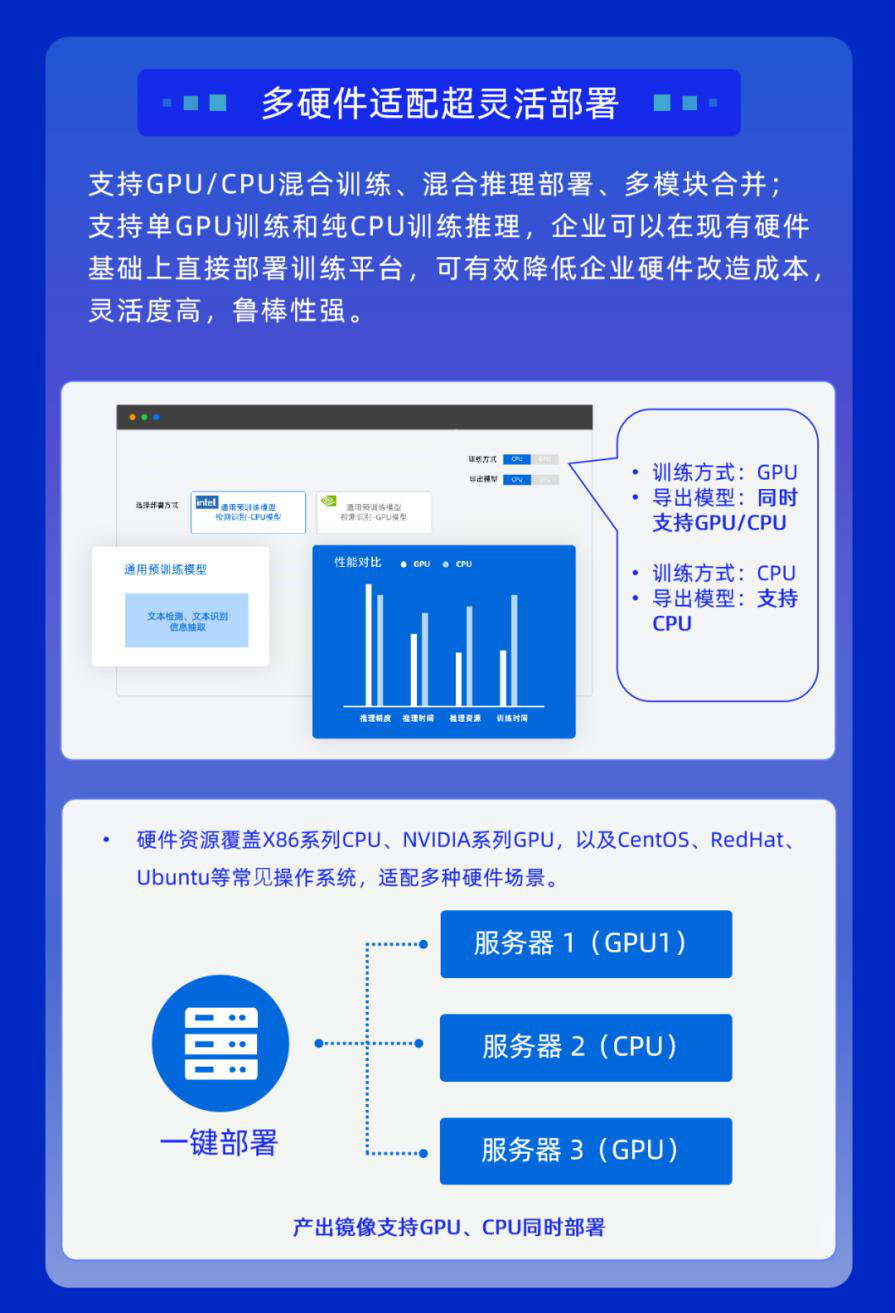
3.CPU/GPU训练与部署
合合信息文字识别训练平台支持GPU/CPU混合训练、混合推理部署、多模块合并,支持单GPU训练和纯CPU训练推理。企业可以在现有的硬件基础上直接部署文字识别训练平台,不需要额外的硬件投入,可降低企业硬件改造成本,灵活性高,鲁棒性强。
4.技术应用典型场景
4.1银行集中运营
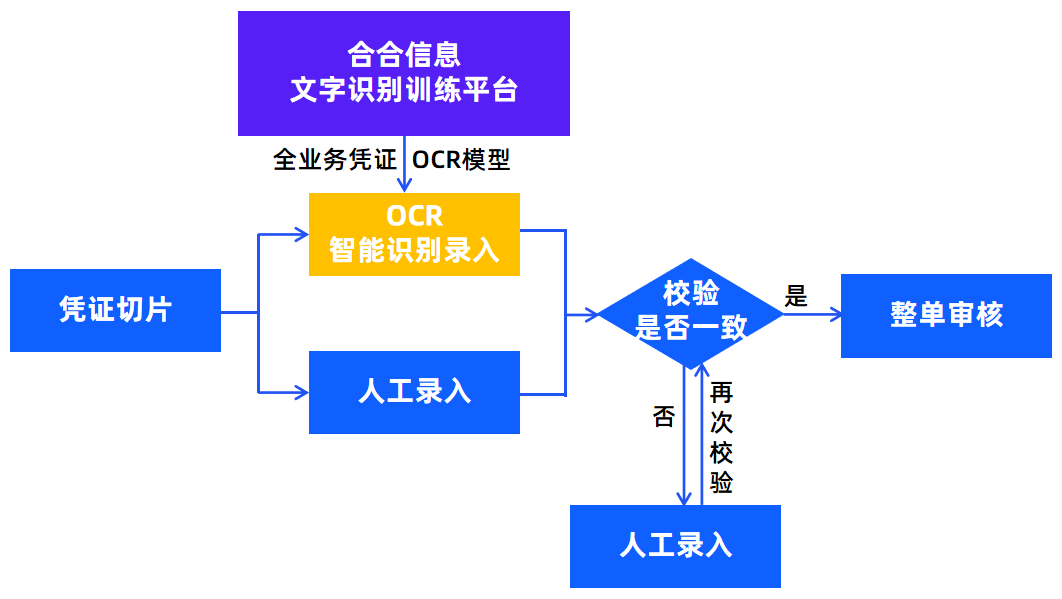
当前,股份制银行、头部城商行、农商行与头部券商纷纷推进集中运营建设,形成分支机构前台受理、专门机构后台集中处理的业务运作模式。在集中运营中,长流程的业务被切分成“前台受理-录入-审核-授权”几段清晰分离、相对短的流程。录入环节通常为“两录一校”,两位录入员分别录入凭证切片上的信息,校验员判断两录结果是否一致。
基于文字识别训练平台可生产多类型凭证的OCR识别模型,将其中一录由人工录入转变为智能文字识别录入,系统自动识别提取切片信息,另一录依然为人工录入,将智能文字识别结果与人工录入结果进行一致性校验,在保证录入流程严格准确的基础上,大幅度提升了业务效率,降低人力成本。
4.2银行后督
银行需要根据会计规范与银行相关法规,对行内各网点的业务交易进行事后监督,通过对业务凭证、营业日报表等进行复审、核对、检验,实现重点监督、差错处理与综合对账。传统事后监督流程中,由于人工审核的人力与效率的局限性,无法对全业务进行审查,只能手工抽查部分大额交易凭证,后督业务覆盖不全面。
文字识别训练平台可输出覆盖全类型凭证的智能文字识别能力,如:转账支票、现金支票、进账单、收款凭证、电子转账凭证、信汇凭证、托收凭证、收费凭证、现金交款单、银行承兑汇票、商业承兑汇票及各类申请书、缴款书、通知书等,赋能银行后督系统对全业务凭证需审核字段进行自动识别提取,后督员依照审核要求,对字段相互间信息、字段与身份证件信息、联网信息等进行核对校验,建立全业务后督体系,充分发挥后督防弊纠错、规范行为、保证资金安全的作用。
4.3跨境贸易反洗钱审查
应国内与国际监管要求,外资银行需要对从事跨境贸易的企业客户在行内的每笔资金交易往来进行排查,确保交易有实际匹配的跨境贸易活动,严格识别与筛查洗钱风险。由于跨境贸易的凭证种类多样,且有大量的不固定版式凭证,如:海外invoice、订单合同、运输单,人工审核方式需要耗费大量人力,传统OCR模型对不固定版式的识别精度较低,需要高度定制。
基于文字识别训练平台,银行可自主对固定、半固定、不固定版式凭证进行识别模型创建和迭代训练,持续提升识别准确率,实现AI全生命流程管理,通过对报关单、核注清单、进账单、信用证开立申请书、海外invoice、订单合同等贸易凭证的智能识别、匹配、审核,构建智能化的跨境贸易反洗钱审查体系。
4.4供应链管理
集团企业的供应链管理业务中,涉及到发票、合同、运输单、货物清单、出/入库单等多类型票据、单据,且由于集团企业供应商数量庞大,供应链票据种类繁多且数量巨大,票据录入审核、电子化归档需要花费大量人力与时间。
集团企业可通过文字识别训练平台实现模型创建、数据标注、模型训练、模型测试、模型部署的一站式OCR开发,实现对多类型、多版式供应链票据的智能分类与识别,并支持对接ERP系统,赋能供应链管理智能化升级。
合合信息文字识别训练平台产品试用:
https://www.wenjuan.com/s/EZVZNbu/