1 前言
jieba 是一个非常流行的中文分词库,具有高效、准确分词的效果。
它支持3种分词模式:
- 精确模式
- 全模式
- 搜索引擎模式
jieba==0.42.1
测试环境:python3.10.9
2 三种模式
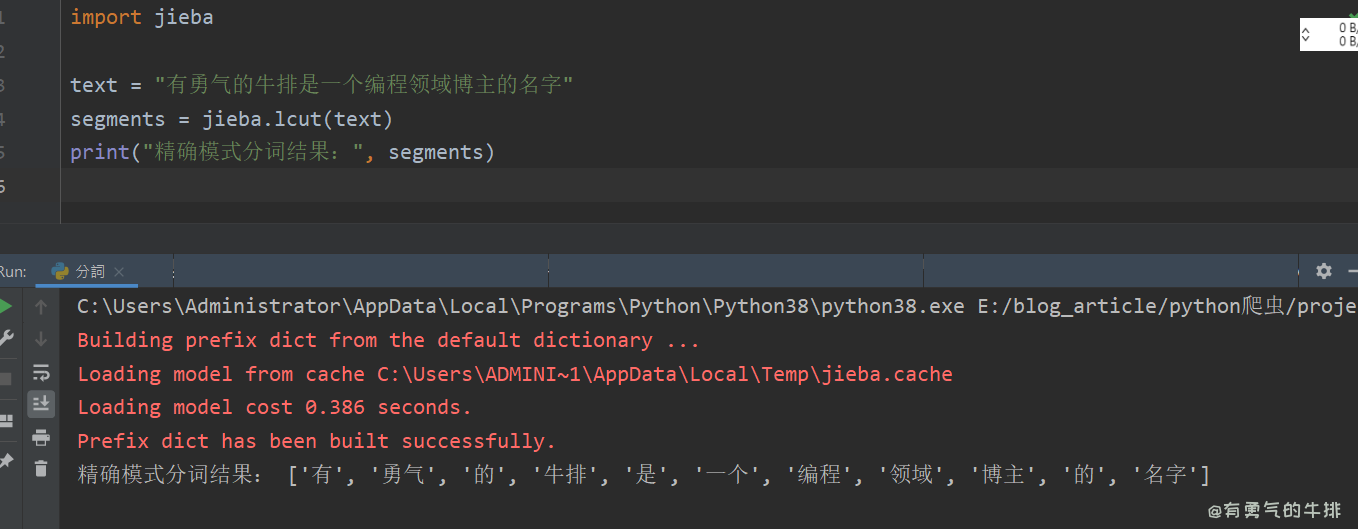
2.1 精确模式
适应场景:文本分析。
功能:可以将句子精确的分开。
import jieba
text = "有勇气的牛排是一个编程领域博主的名字"
segments = jieba.lcut(text)
print("精确模式分词结果:", segments)
# ['有', '勇气', '的', '牛排', '是', '一个', '编程', '领域', '博主', '的', '名字']
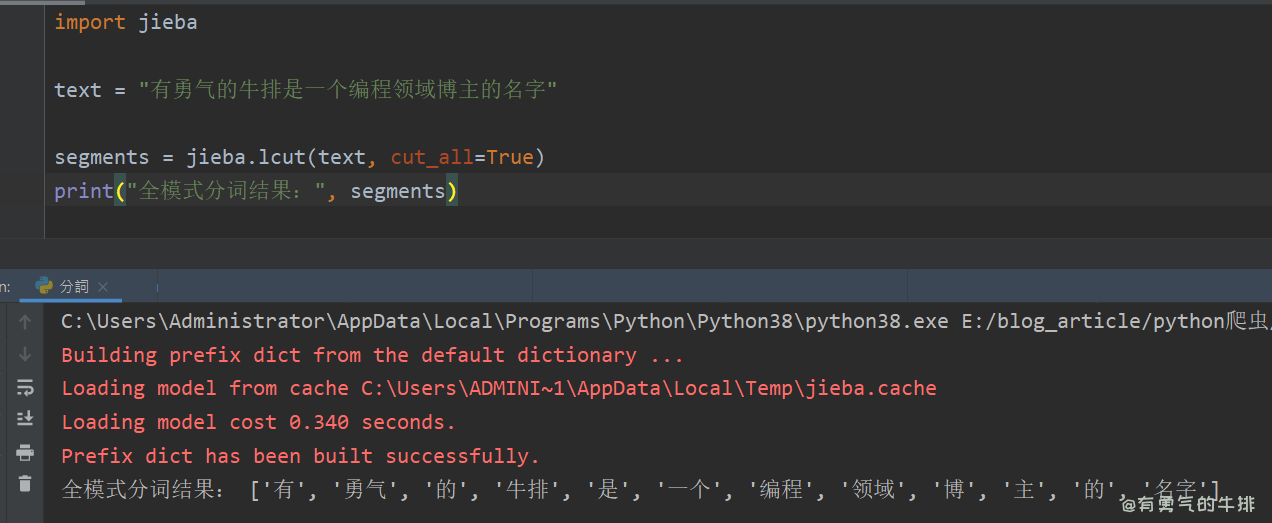
2.2 全模式
适应场景:提取词语。
功能:可以将句子中的成词的词语扫描出来,速度非常快,但不能解决歧义问题。
import jieba
text = "有勇气的牛排是一个编程领域博主的名字"
segments = jieba.lcut(text, cut_all=True)
print("全模式分词结果:", segments)
# ['有', '勇气', '的', '牛排', '是', '一个', '编程', '领域', '博', '主', '的', '名字']
2.3 搜索引擎模式
适应场景:搜索分词。
功能:在精确模式的基础上,对长分词进行切分,提高召回率。
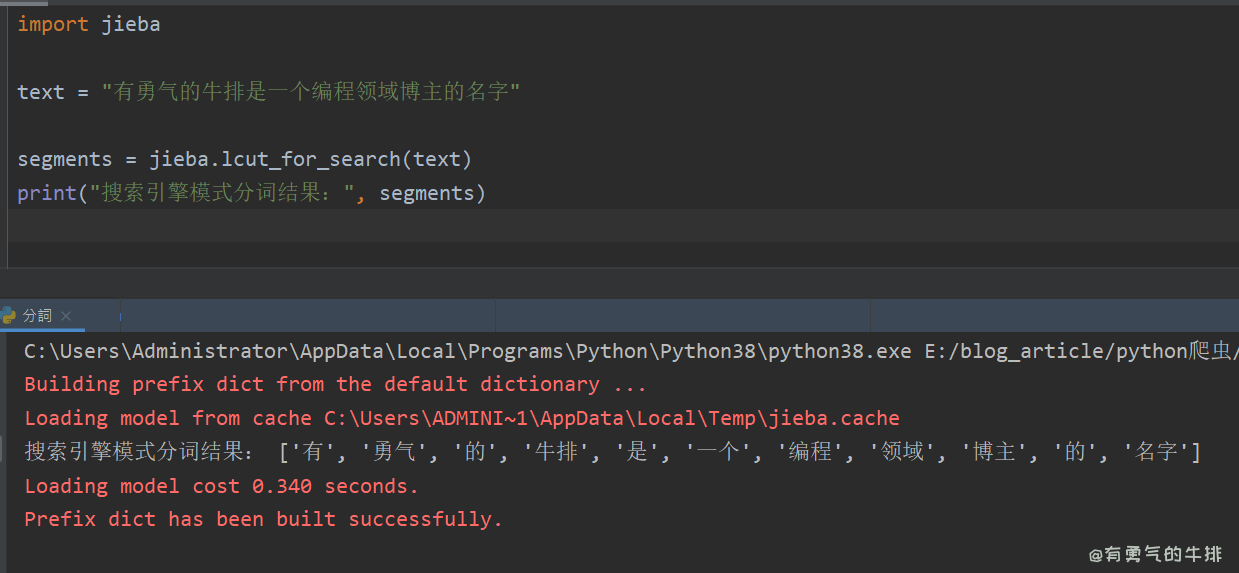
import jieba
text = "有勇气的牛排是一个编程领域博主的名字"
segments = jieba.lcut_for_search(text)
print("搜索引擎模式分词结果:", segments)
3 自定义词典
jieba允许用户自定义词典,以提高分词的准确性。
比如专业术语、名字、网络新流行词汇、方言、以及其他不常见短语名字等。
3.1 添加单个词语
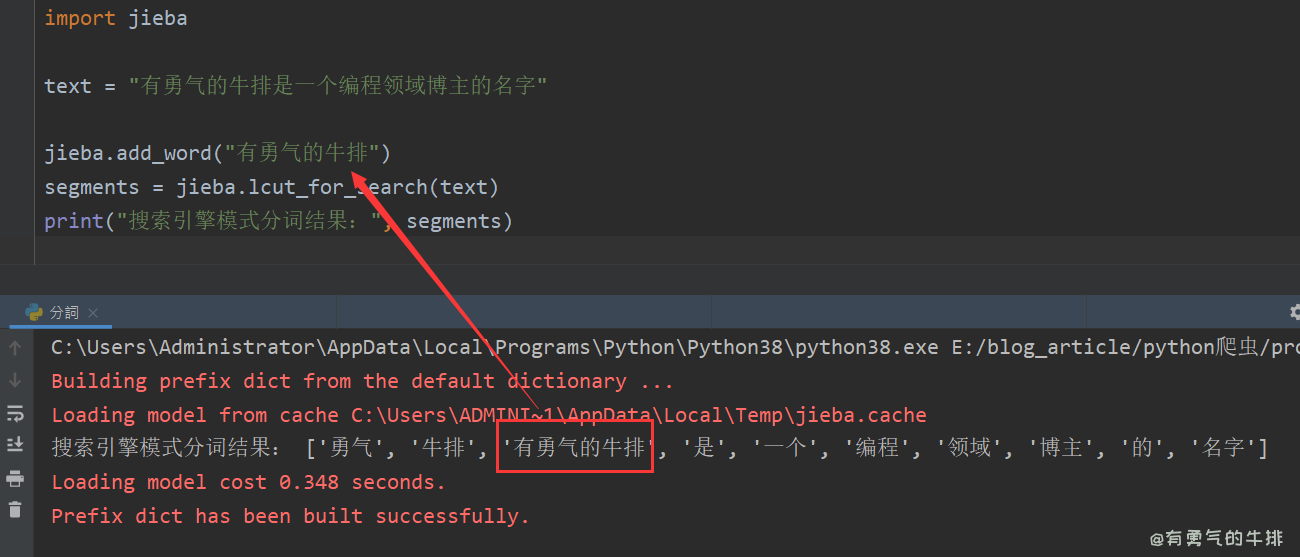
import jieba
text = "有勇气的牛排是一个编程领域博主的名字"
jieba.add_word("有勇气的牛排")
segments = jieba.lcut_for_search(text)
print("搜索引擎模式分词结果:", segments)
# ['勇气', '牛排', '有勇气的牛排', '是', '一个', '编程', '领域', '博主', '的', '名字']
3.2 添加词典文件
cs_dict.txt
有勇气的牛排
编程领域
main.py
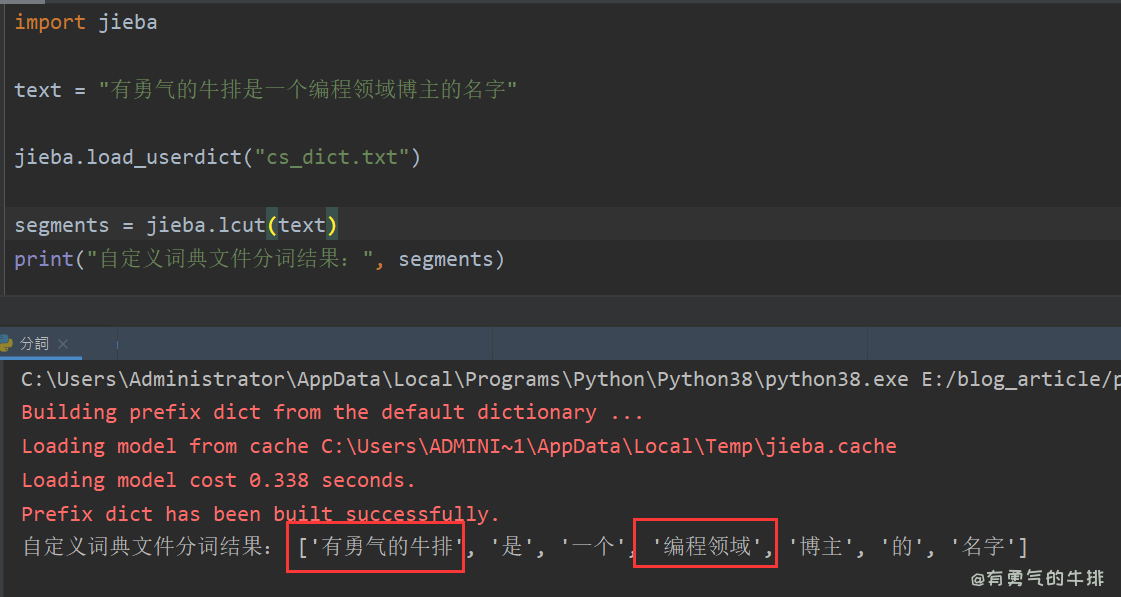
import jieba
text = "有勇气的牛排是一个编程领域博主的名字"
jieba.load_userdict("cs_dict.txt")
segments = jieba.lcut(text)
print("自定义词典文件分词结果:", segments)
# ['有勇气的牛排', '是', '一个', '编程领域', '博主', '的', '名字']
4 词性标注
jieba 的词性标注(POS tagging)功能使用了标注词性(Part-of-Speech tags)来表示每个词的词性。
4.1 词性对照表
原文地址:https://www.couragesteak.com/article/454
a 形容词 ad 副形词
ag 形容词性语素 an 名形词
b 区别词 c 连词
d 副词 dg 副语素
e 叹词 f 方位词
g 语素 h 前缀
i 成语 j 简称略语
k 后缀 l 习用语
m 数词 mg 数语素
mq 数量词 n 名词
ng 名语素 nr 人名
ns 地名 nt 机构团体
nz 其他专名 o 拟声词
p 介词 q 量词
r 代词 rg 代词性语素
s 处所词 t 时间词
tg 时间词性语素 u 助词
vg 动语素 v 动词
vd 副动词 vn 名动词
w 标点符号 x 非语素字
y 语气词 z 状态词
4.2 测试案例
import jieba.posseg as pseg
text = "有勇气的牛排是一个编程领域博主的名字"
words = pseg.cut(text)
for word, flag in words:
print(f"{word} - {flag}")
5 关键词提取
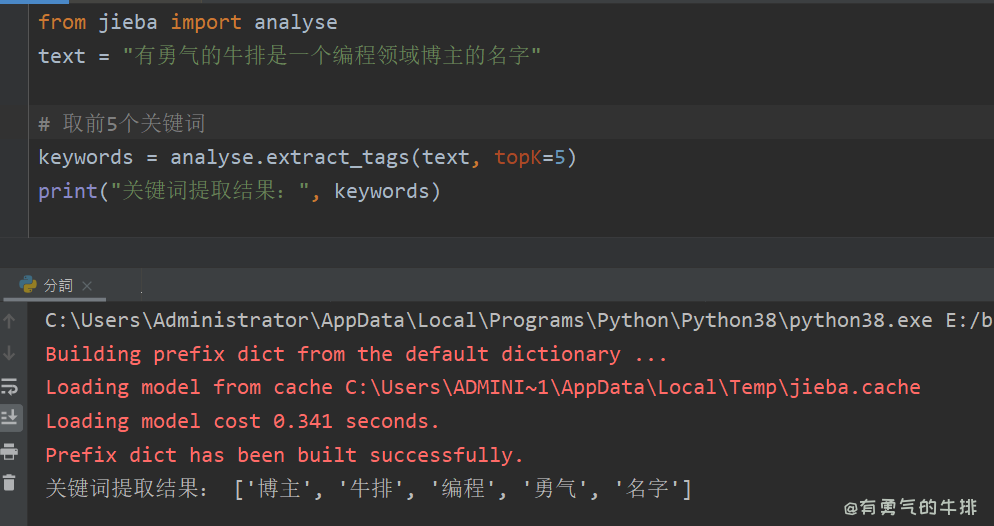
from jieba import analyse
text = "有勇气的牛排是一个编程领域博主的名字"
# 取前5个关键词
keywords = analyse.extract_tags(text, topK=5)
print("关键词提取结果:", keywords)
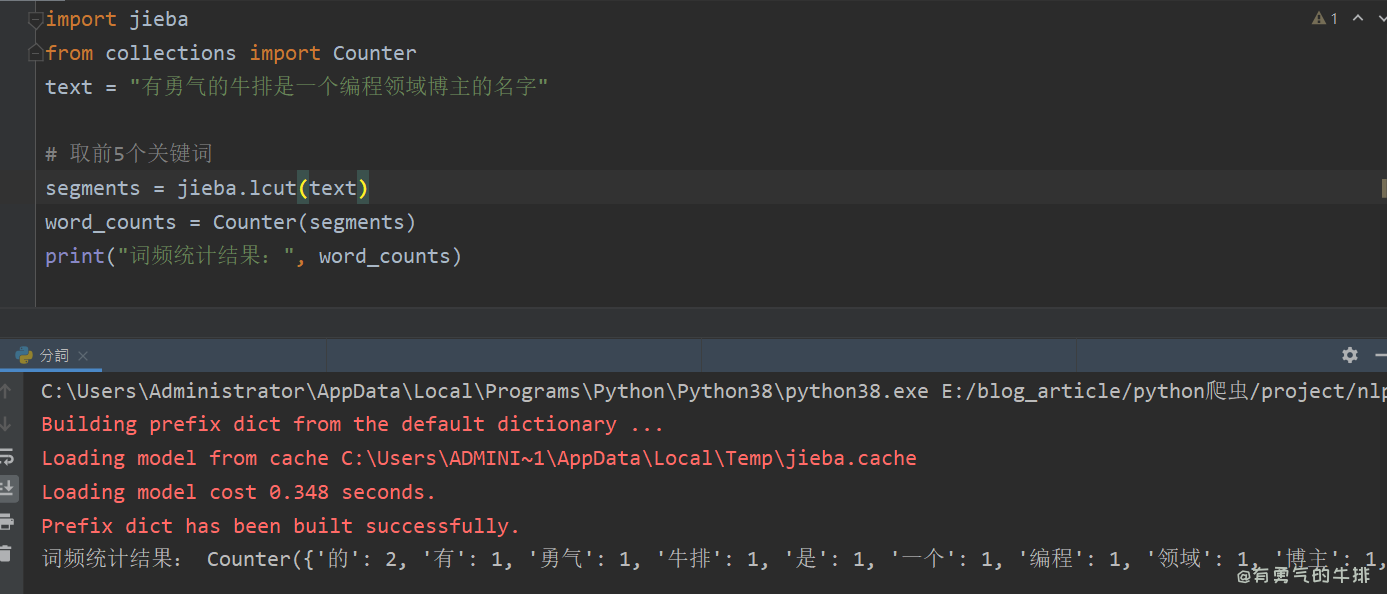
6 词频统计
import jieba
from collections import Counter
text = "有勇气的牛排是一个编程领域博主的名字"
# 取前5个关键词
segments = jieba.lcut(text)
word_counts = Counter(segments)
print("词频统计结果:", word_counts)