目录
一、数据库类型
1)关系型数据库
2)非关系型数据库
二、Redis远程字典服务器
1)redis介绍
2)redis的优点
3)Redis 为什么那么快?
4)Redis使用场景
三、Redis安装部署
1)系统初始化
2)修改内核参数
3)安装依赖包、安装redis
4)创建redis的工作目录并创建redis程序用户,将redis程序执行文件加入到系统环境变量中
5)修改redis.conf配置文件
6)定义systemd服务管理脚本
四、redis命令工具的使用
1)redis-cli命令行工具
2)redis-benchmark测试工具
3)Redis数据库常用命令
① redis通用操作
② string数据类型
③ List数据类型
④ Hash数据类型(散列类型)
⑤ Set数据类型(无序集合)
⑥ zset(有序集合)
一、数据库类型
1)关系型数据库
关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。SQL 语句(标准数据查询语言)就是一种基于关系型数据库的语言,用于执行对关系型数据库中数据的检索和操作。
主流的关系型数据库包括 Oracle、MySQL、SQL Server、Microsoft Access、DB2、PostgreSQL 等。国内大多数据库都是基于PostgreSQL 二次开发的。以上数据库在使用的时候必须先建库建表设计表结构,然后存储数据的时候按表结构去存,如果数据与表结构不匹配就会存储失败。
2)非关系型数据库
NoSQL(NoSQL = Not Only SQL ),意思是“不仅仅是 SQL”,是非关系型数据库的总称。除了主流的关系型数据库外的数据库,都认为是非关系型。非关系型不需要预先建库建表定义数据存储表结构,每条记录可以有不同的数据类型和字段个数(比如微信群聊里的文字、图片、视频、音乐等)。主流的 NoSQL 数据库有Redis、MongBD、Hbase、Memcached、ElasticSearch、TSDB 等。
| 关系型数据库 | 非关系型数据库 | |
| 结构 | 二维表格模型 | 非二维表格式,不同的NoSQL采用不同的存储方式(比如键值对、文档、索引、图形结构、时间序列等) |
| 扩展方式 | 纵向扩展(提升单机的硬件性能) | 横向扩展(增加服务器节点数量) |
| 事务支持 | 基于ACID原则,对事务控制更稳定,细粒度更高 | 基于BASE原则,对事务控制的稳定性和细粒度不如SQL |
| 创建数据的方式 | 建库--->建表--->设计表结构--->插入数据字段内容 | 自带库--->自带数据集(表)--->创建键值对存储数据 |
| 典型代表 | MySQL Oracle PostgreSQL SQL-Server | Redis Memcached MongDB ElasticSearch Prometheus |
非关系型数据库可用于应对Web2.0纯动态网站类型的三高问题
- High performance——对数据库高并发读写需求 (高并发)
- Huge Storage——对海量数据高效存储与访问需求(高性能)
- High Scalability && High Availability——对数据库高可扩展性与高可用性需求(高可用)
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给Web2.0的数据库发展带来新的思路。让关系型数据库关注在关系上和对数据的一致性保障,非关系型数据库关注在存储和高效率上。例如,在读写分离的MySQL数据库环境中,可以把经常访问的数据存储在非关系型数据库中,提升访问速度。
二、Redis远程字典服务器
1)redis介绍
- 用C语言开发的,开源的,基于内存运行的NoSQL
- 存储结构:键值对(Key/Value KV)
- 数据类型:五大基础数据类型 string(字符串) list(列表) hash(哈希/散列) set(集合/无序集合) zset/sorted set(有序集合)
- 三种特殊的数据类型: HyperLogLogs(基数统计) Bitmaps(位图) geospatial(地理位置)
- 端口号:TCP/6379
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程。在实际生产环境中,需要根据实际的需求来决定开启多少个Redis进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。若CPU资源比较紧张,采用单进程即可。
2)redis的优点
- 具有极高的数据读写速度:数据读取的速度最高可达到10000次/s,数据写入速度最高可达到81000次/s。
- 支持丰富的数据类型:支持key-value、Strings、Lists、Hashes、Sets及Sorted Sets等数据类型操作。
- 支持数据的持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- 原子性:Redis所有操作都是原子性的。
- 支持数据备份:即master-salve模式的数据备份。
3)Redis 为什么那么快?
- redis是基于内存运行,数据的读写都是在内存中完成的
- 数据结构简单,可以直接使用 键值对 的方式存储数据
- 数据读写采用单线程模型,避免了多线程切换带来的CPU性能损耗,同时也不用考虑各种锁的影响
- 采用 I/O 多路复用模型,非阻塞IO可以使网络线程处理更多的网络连接请求,提高了网络并发能力
4)Redis使用场景
Redis作为基于内存运行的数据库,是一个高性能的缓存,一般应用在Session缓存、队列、排行榜、计数器、最近最热文章、最近最热评论、发布订阅等。Redis适用于数据实时性要求高、数据存储有过期和淘汰特征的、不需要持久化或者只需要保证弱一致性、逻辑简单的场景。
- string:用于分布式锁、计数器(如记录访问次数、点赞转发数量)
- list:用于消息队列、文章列表等
- hash:用于缓存用户信息、购物车等
- set:用于抽奖、共同关注、QQ内推等
- zset:用于排行榜、抖音热搜等
三、Redis安装部署
1)系统初始化
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
vim /etc/selinux/config
--->SELINUX=disabled2)修改内核参数
配置内核参数添加配置
vim /etc/sysctl.conf
----------------------------------------------
vm.overcommit_memory = 1 #内核允许超量使用内存直到用完为止,防止OOM杀死进程
net.core.somaxconn = 20480 #指定处于监听状态的连接请求队列的最大长度
sysctl -p #加载3)安装依赖包、安装redis
yum install -y gcc gcc-c++ make
cd /opt
rz -E
#redis-7.0.13.tar.gz
tar xf /opt/redis-7.0.13.tar.gz
cd /opt/redis-7.0.13
make
make PREFIX=/usr/local/redis install
#由于Redis源码包中直接提供了Makefile文件,所以在解压完软件包后,不用先执行./configure行配置,可直接执行make与make install命令进行安装4)创建redis的工作目录并创建redis程序用户,将redis程序执行文件加入到系统环境变量中
cd /usr/local/redis
mkdir conf log data
cd /opt/redis-7.0.13/
cp redis.conf /usr/local/redis/conf/
useradd -M -s /sbin/nologin redis
chown -R redis:redis /usr/local/redisvim /etc/profile
---> export PATH=$PATH:/usr/local/redis/bin
source /etc/profile
5)修改redis.conf配置文件
vim /usr/local/redis/conf/redis.conf
bind 192.168.170.200 #87行,添加监听的主机地址
protected-mode no #111行,将本机访问保护模式设置no。如果开启了,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应
port 6379 #138行,Redis默认的监听6379端口
tcp-backlog 20480 #147行,修改参数为20480,与内核参数一致
daemonize yes #309行,设置为守护进程,后台启动
pidfile /usr/local/redis/log/redis_6379.pid #341行,指定PID文件
logfile "/usr/local/redis/log/redis_6379.log" #354行,指定日志文件
dir /usr/local/redis/data #504行,指定持久化文件所在目录
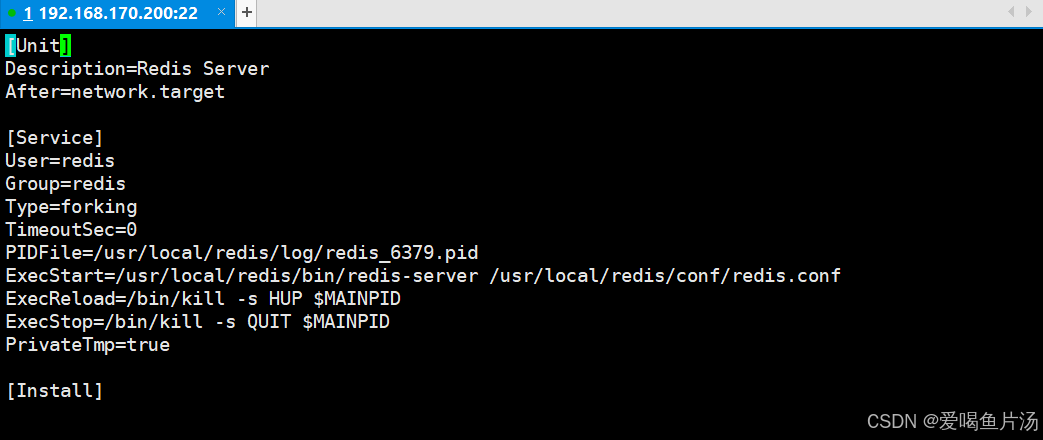
requirepass 123456 #1037行,增加一行,设置redis密码6)定义systemd服务管理脚本
cd /usr/lib/systemd/system
vim redis-server.service
-----------------------------------------------------------------------------
[Unit]
Description=Redis Server
After=network.target
[Service]
User=redis
Group=redis
Type=forking
TimeoutSec=0
PIDFile=/usr/local/redis/log/redis_6379.pid
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true
[Install]
WantedBy=multi-user.target
---------------------------------------------------------------------------------
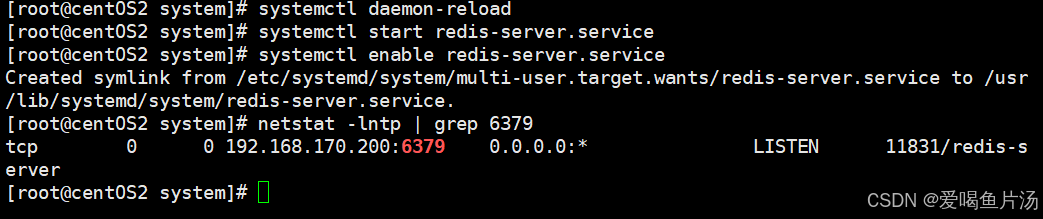
systemctl daemon-reload
systemctl start redis-server.service
systemctl enable redis-server.service
netstat -lntp | grep 6379
四、redis命令工具的使用
redis-cli:Redis客户端命令行工具
redis-benchmark:性能测试工具,用于检测Redis在本机的运行效率
redis-check-aof:修复有问题的AOF持久化文件
redis-check-rdb:修复有问题的RDB持久化文件
redis-server:Redis服务器启动命令
redis-sentinel:Redis哨兵集群使用
1)redis-cli命令行工具
语法:redis-cli -h 主机 -p 端口号 [-a password]
-h :指定远程主机
-p :指定Redis服务的端口号
-a :指定密码,未设置数据库密码可以省略-a选项
若不添加任何选项表示,则使用127.0.0.1:6379连接本机上的Redis数据库
登录redis
redis-cli -h <redis服务器地址> -p <redis端口> -a <redis密码>
2)redis-benchmark测试工具
redis-benchmark是官方自带的Redis性能测试工具,可以有效的测试Redis服务的性能。
基本的测试语法:redis-benchmark [选项] [选项值]。
-h :指定服务器主机名。
-p :指定服务器端口。
-s :指定服务器 socket
-c :指定并发连接数。
-n :指定请求数。
-d :以字节的形式指定 SET/GET 值的数据大小。
-k :1=keep alive 0=reconnect 。
-r :SET/GET/INCR 使用随机 key, SADD 使用随机值。
-P :通过管道传输<numreq>请求。
-q :强制退出 redis。仅显示 query/sec 值。
--csv :以 CSV 格式输出。
-l :生成循环,永久执行测试。
-t :仅运行以逗号分隔的测试命令列表。
-I :Idle 模式。仅打开 N 个 idle 连接并等待。
//向IP 地址为192.168.170.200端口为6379的Redis服务器发送100个并发连接与100000个请求测试性能
redis-benchmark -h 192.168.170.200 -p 6379 -a '123456' -c 100 -n 100000
//向IP 地址为192.168.170.200端口为6379的Redis服务器发送100个并发连接与100000个请求,每个连接数100个字节,仅显示每条命令执行的汇总信息(不显示分布图)
redis-benchmark -h 192.168.170.200 -p 6379 -a '123456' -c 100 -n 100000 -d 100 -p
//指定测试哪些命令的执行性能
redis-benchmark -h 192.168.170.200 -p 6379 -a '123456' -t set,get,lpush... -n 100000 -d 100-q
#测试存取大小为 100 字节的数据包的性能
redis-benchmark -h 192.168.170.200 -p 6379 -q -d 100 -a '123456'
3)Redis数据库常用命令
① redis通用操作
Redis支持多数据库,Redis默认情况下包含16个数据库,数据库名称是用数字0-15来依次命名。
多数据库相互独立,互不干扰。
del 键 #删除键
type 键 #查看键的数据类型
keys 键 #查询键,支持通配符 * ?
exists 键 #判断键是否存在
expire 键 秒数 #为键设置过期时间
ttl 键 #查看键当前的过期时间,-1 永不过期,-2 已过期
rename 键 新键 #重命名键,会覆盖已存在的键
renamenx 键 新键 #重命名键,不会覆盖已存在的键
dbsize #统计当前库中键的总数
config set requirepass '密码' #设置redis密码
config get requirepass #查看redis密码
select 库ID #切换库,默认库ID为 0~15
move 键 库ID #移动键到指定的库,如果目标库中有相同键,则操作会失败
flushdb #清空当前库所有键(慎用)
flushall #清空所有库所有键(慎用)
keys命令查看键
keys * #查看当前数据库中所有键
keys c* #查看当前数据库中以v开头的数据(支持通配符)
keys m???? #查看当前数据库中以z头后面包含任意四位的数据
exists命令判断键值是否存在,存在返回1,否则返回0。
exists 键名 设置键的过期时间
ttl 键 #查看键当前的过期时间,-1 永不过期,-2 已过期
expire 键 时间 #已存在键设置时间(秒为单位),设置后立马开始倒计时
setex 键 秒数 值 #创建键并设置过期时间
rename是对已有key进行重命名(覆盖)
rename 键 新键 #重命名键,会覆盖已存在的键
renamenx 键 新键 #重命名键,不会覆盖已存在的键 dbsize命令统计当前数据库中key的数目
dbsize #统计当前库中键的总数 config 修改密码
config set requirepass '密码' #设置redis密码
config get requirepass #查看redis密码
config set requirepass '' #设置redis空密码type查看数据类型
type 键 #查看键的数据类型 ② string数据类型
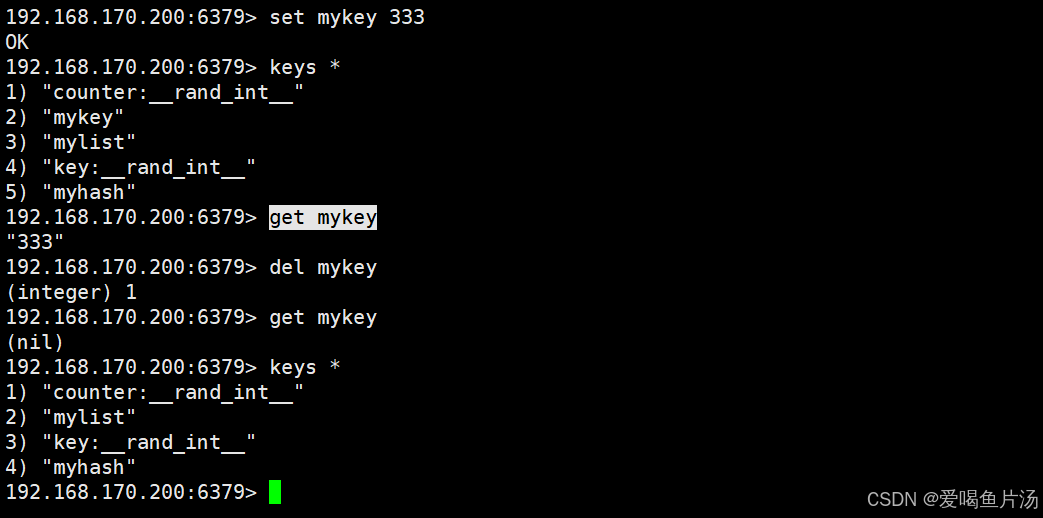
set:存放和设置string类型的键和值,命令格式为set 键名 值
get:获取string类型的键值,命令格式为get 键名
append追加内容
append 键 追加内容 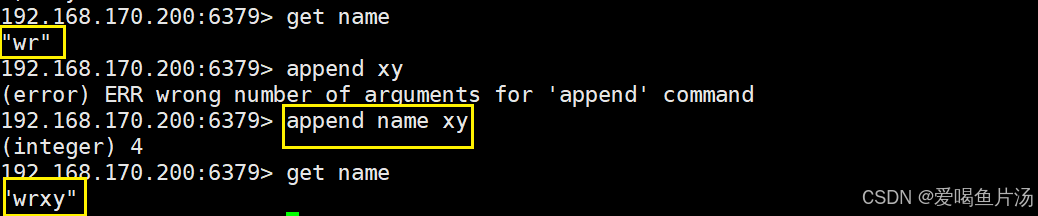
strlen命令获取键字符长度
strlen 键名 #获取指定Key的字符长度。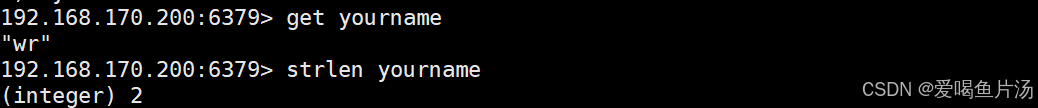
incr、decr递增和递减
incr 键名 #该Key的值递增1,还可以直接创建值为1键
decr 键名 #该Key的值递减1
只能递增递减数字
incrby mykey 10 #增加指定的整数
decrby mykey 5 #减少指定的整数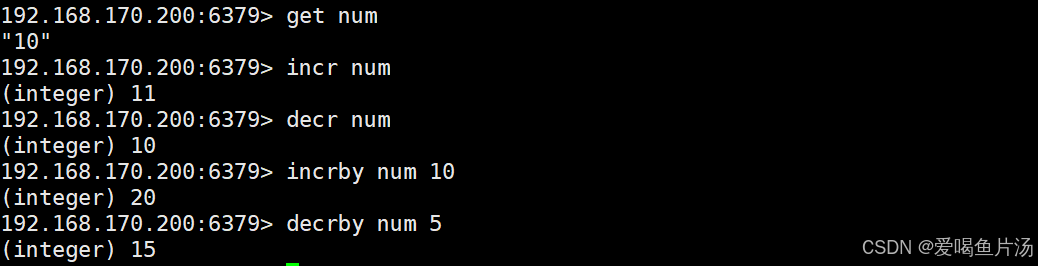
getset查询并重新设置值
getset 键名 数值 #在获取计数器原有值的同时,并将其设置为新值,这两个操作原子性的同时完成。setnx创建键值对
setnx mykey hello #若键并不存在,会创建键
setnx mykey hello #若键并存在,设置没有产生任何效果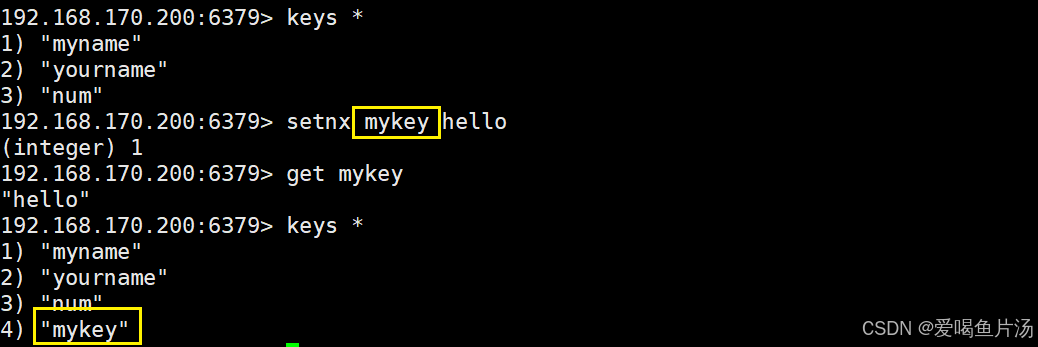
mset、mget批量设置键
mset key1 hello key2 world #批量设置了key1和key2两个键。
mget key1 key2 #批量获取了key1和key2两个键的值。
msetnx key3 hello key5 world #批量设置key3和key5两个键,所有字段要么全被设置,要么全不被设置。但凡有一个key存在就不会产生任何效果,若不存在则会创建③ List数据类型
概述:列表的元素类型为string,按照插入顺序排序,在列表的头部或尾部添加元素
lpush、lrange
lpush mykey a b c d #mykey键并不存在,该命令会创建该键及与其关联的List,之后在将参数中的values从左到右依次插入。
lrange mykey 0 2 #取从位置0开始到位置2结束的3个元素。
lrange mykey 0 -1 #取链表中的全部元素,其中0表示第一个元素,-1表示最后一个元素。lpushx
lpushx mykey2 zhangsan #mykey2键此时并不存在,因此lpushx命令将不会进行任何操作,其返回值为0。
lpushx mykey zhangsan lisi #mykey键此时已经存在,所以lpushx命令插入成功,并返回链表中当前元素的数量。 lpop删除、llen统计元素
lpop mykey #移除并返回mykey键的第一个元素,从左取
llen mykey #统计元素的数量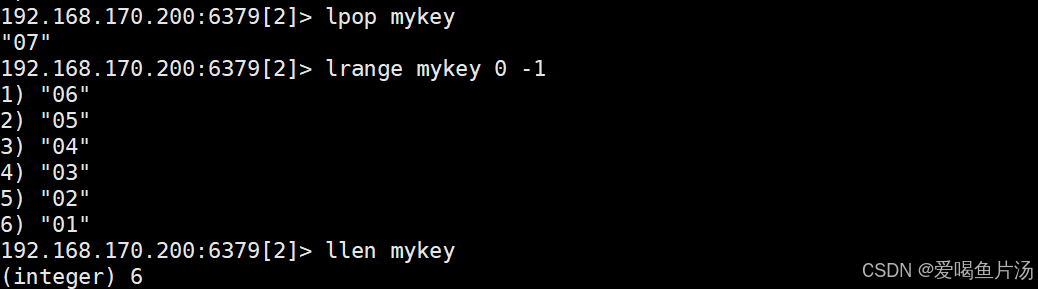
lrem从左边开始删除N个指定元素
lrem mykey 2 a #从头部(left)向尾部(right)变量链表,删除2个值等于a的元素,返回值为实际删除的数量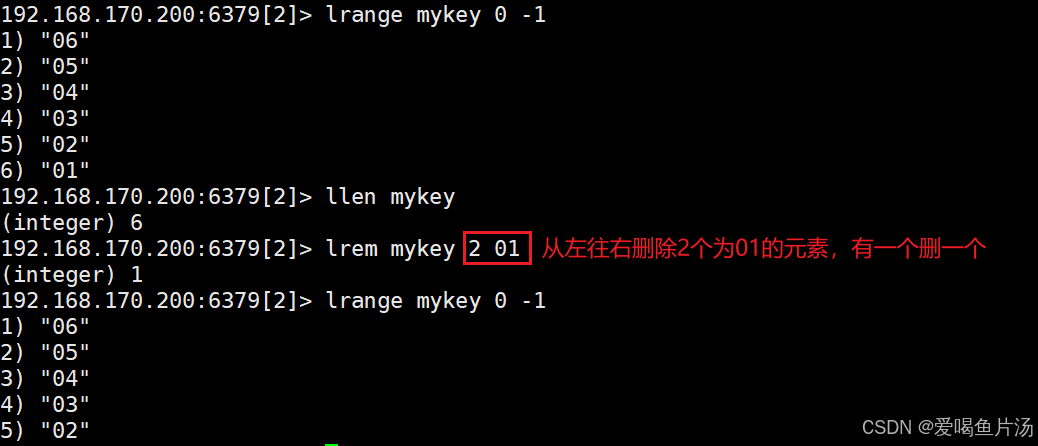
lindex、lset、ltrim
lindex mykey 1 #获取索引值为1(头部的第二个元素)的元素值。
lset mykey 1 e #将索引值为1(头部的第二个元素)的元素值设置为新值e。
ltrim mykey 0 2 #仅保留索引值0到2之间的3个元素,注意第0个和第2个元素均被保留。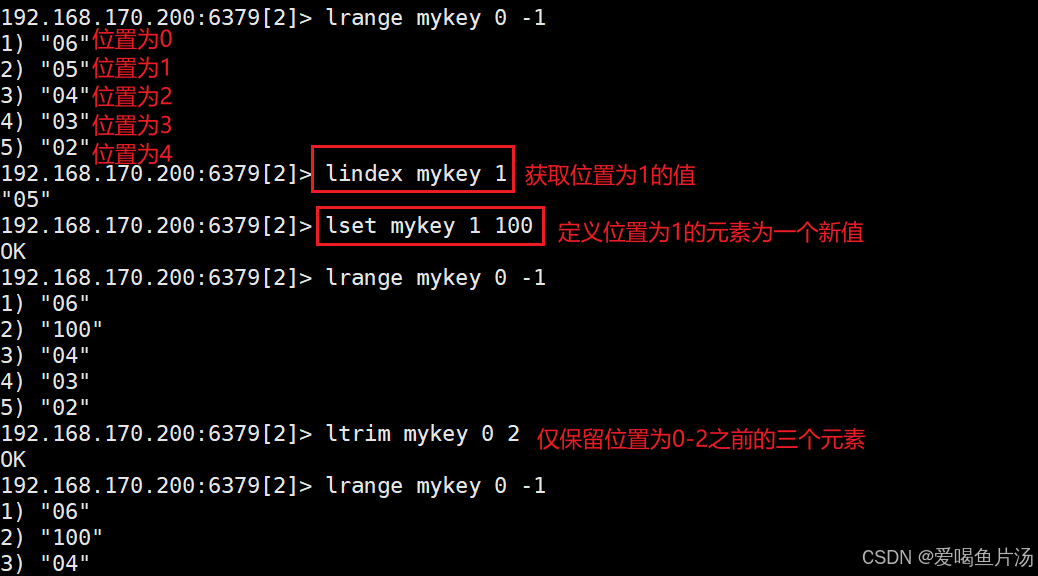
linsert
linsert 键 before|after 元素 值 #在指定元素前|后插入
linsert mykey before a a1 #在a的前面插入新元素a1。
linsert mykey after e e2 #在e的后面插入新元素e2,从返回结果看已经插入成功。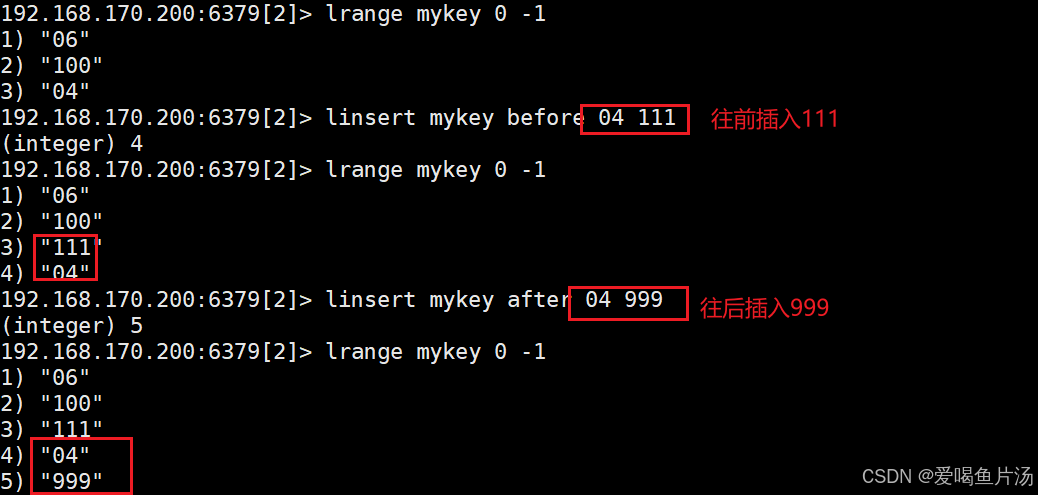
rpush、rpop
lpush 键 值1 值2 .... #从左边开始插入元素
rpush 键 值1 值2 .... #从右边开始插入元素
rpush mykey a b c d #从链表的尾部插入参数中给出的values,插入顺序是从右到左依次插入。
RPOP mykey #移除并返回mykey键的第一个元素。
rpoplpush mykey mykey2 #将mykey的尾部元素e弹出,同时再插入到mykey2的头部(原子性的完成这两步操作)。 ④ Hash数据类型(散列类型)
概述:hash用于存储对象。可以采用这样的命名方式:对象类别和ID构成键名,使用字段表示对象的属性,而字段值则存储属性值。 如:存储 ID 为 2 的汽车对象。
如果Hash中包含很少的字段,那么该类型的数据也将仅占用很少的磁盘空间。每一个Hash可以存储4294967295个键值对。
hset、hget、hdel
hset myhash field1 "zhang" #给键值为myhash的键设置字段为field1,值为zhang。
hget myhash field1 #获取键值为myhash,字段为field1的值"zhang"
hdel myhash field2 #删除myhash键中字段名为field2的字段,删除成功返回1。
hmset 键 字段1 值1 字段2 值2 .... #插入多个字段、值
hkeys 键 #查看所有的字段
hvals 键 #查看所有字段的值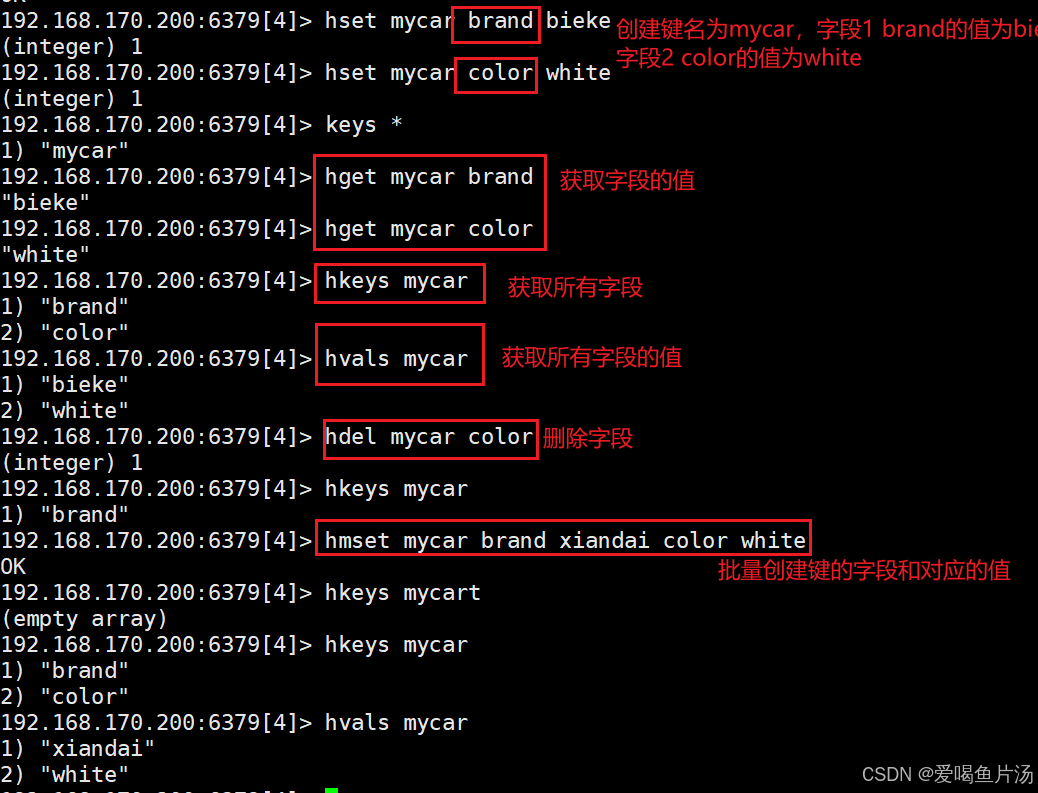
⑤ Set数据类型(无序集合)
概述:无序集合,元素类型为String类型,元素具有唯一性,不允许存在重复的成员。多个集合类型之间可以进行并集、交集和差集运算。
sadd、smembers、scard
sadd 键 值1 值2 .... #元素不能重复
sismember 键 值 #查看是否包含某个值
smembers 键 #查看元素,无序的
scard 键 #统计元素的数量 srandmember、spop、srem、semove
srandmember 键 n #随便显示n个元素
spop 键 #随机显示并删除一个元素
srem 键 值1 值2 ... #删除指定的元素
smove 键1 键2 值 #将键1的元素移动到键2中⑥ zset(有序集合)
概述
a、有序集合,元素类型为String,元素具有唯一性,不能重复。
b、每个元素都会关联一个double类型的分数score(表示权重),可以通过权重的大小排序,元素的score可以相同。应用范围
1)可以用于一个大型在线游戏的积分排行榜。每当玩家的分数发生变化时,可以执行ZADD命令更新玩家的分数,此后再通过ZRANGE命令获取积分TOP10的用户信息。当然我们也可以利用ZRANK命令通过username来获取玩家的排行信息。最后我们将组合使用ZRANGE和ZRANK命令快速的获取和某个玩家积分相近的其他用户的信息。
2)Sorted-Set类型还可用于构建索引数据。
zadd、zrange、zcard、zcount、zrem、zincrby、zscore、zrevrangebyscore
zrank 键 值 #查看某个元素的位置
zadd 键 权重1 值1 权重2 值2 .... #score权重是可以重复的,元素值是不可以重复的
zrange 键 起始位置 终止位置 [withscores] #起始位置 0表示左边开始的第一个元素,终止位置 -1表示到最后一个元素;[withscores]添加会显示权重
zrevrank 键 元素 #根据权重降序排,查看第元素的位置
zremrangebyrank 键 起始位置 终止位置 #删除位置N-M之间的元素 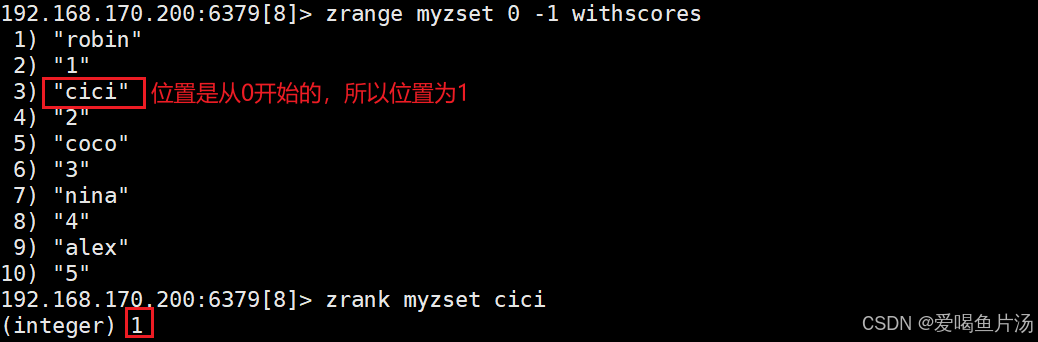
zcard 键 #统计元素的数量

zcount 键 起始权重 终止权重 #统计指定权重范围的元素数量

zrem 键 值1 值2 ... #删除指定的元素
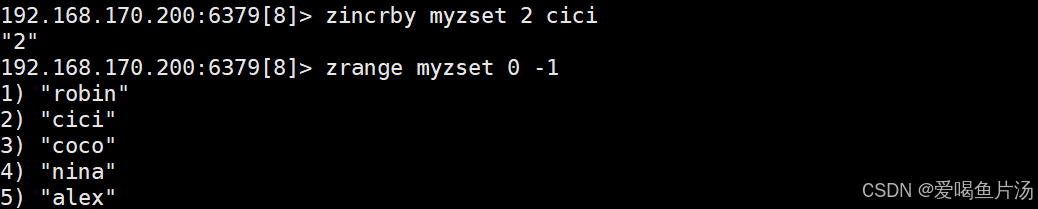
zincrby 键 权重 值 #添加新的元素或增加指定元素的权重(权重-1表示减1的意思)
zscore 键 值 #查看指定键的值的权重

zrevrangebyscore #获取指定权重范围的内容
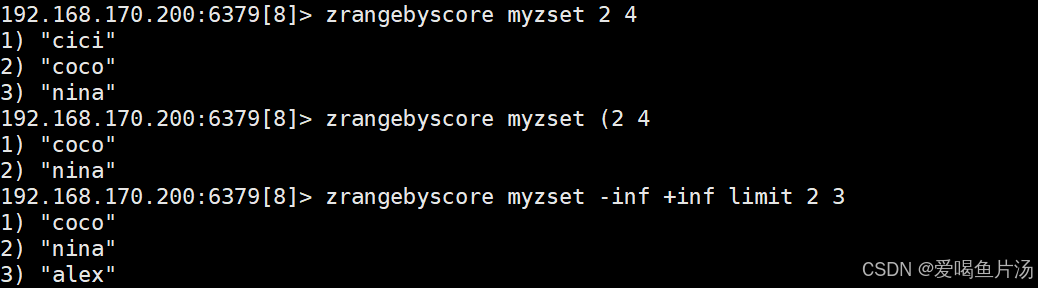
zrangebyscore myzset 2 4 #获取权重在2-4之间内容
zrangebyscore myzset (2 4 #获取权重在5-10之间内容,不包含5
zrevrangebyscore 键 起始权重 终止权重 [limit N M] #查看指定权重范围的元素,按score从小到大,limit N M 表示只显示第N个之后的M个元素(不包括第N个元素)
zrangebyscore myzset -inf +inf limit 2 3 #-inf表示第一个成员(位置索引值最低的,即0),+inf表示最后一个成员(位置索引值最高的),limit后面的参数用于限制返回成员的值,2表示从位置索引等于2的成员开始,取后面3个成员。
zrevrange 降序排
zrevrange 键 起始位置 终止位置 #降序查看
zrevrangebyscore 键 起始权重 终止权重 [limit N M] #按权重进行查看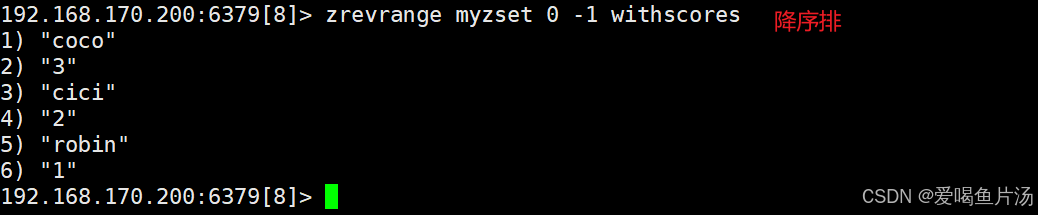












![[亲测可用]俄罗斯方块H5-网页小游戏源码-HTML源码](https://img-blog.csdnimg.cn/img_convert/1a724cc1ec486c71a9059676873771ff.png)