一、使用范围(作者经验):
- 类别 < 10 通常采用独热编码方式。
- 类别 > 50( 通常这种情况需要使用哈希桶),通常最好使用嵌入。
- 10 - 50 可以尝试两种方式,选择最优。
目的:同义词具有非常接近的嵌入(将嵌入向量当作嵌入空间中的坐标,则同义词在嵌入空间中对应的点挨得近,差别越大的词对应的点挨得越远)
二、举例:
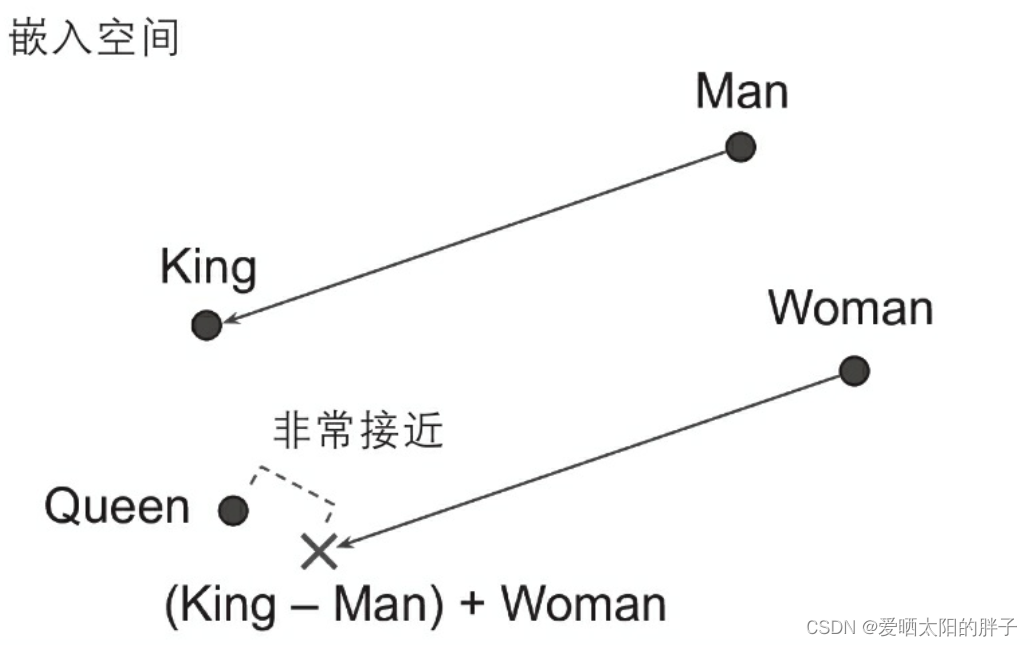
如果计算King-Man+Woman(添加和减去这些单词的嵌入向量),则结果非 常接近Queen单词的嵌入(见图1)。换句话说,词嵌入编码了性别的概念!同样,可以计算Madrid-Spain+France,其结果接近Paris(巴黎),这似乎表明首都的概念也在嵌入中进行了编码。
补充:
表征学习:对输入数据表征越好,神经网络就越容易做出准确的预测,因此训练使嵌入成为类别的有用表征。
三、代码
Keras提供了一个keras.layers.Embedding层来处理嵌入矩阵(默认情况下是可训练 的)。创建层时,它将随机初始化嵌入矩阵,然后使用某些类别索引进行调用时,它将返回相应的行。下面是一个简单的应用——将数据用一个1*3的向量表示。
tf.keras.layers.Embedding()使用:tf.keras.layers.Embedding() 详解
代码:
vocab = tf.constant([1,1,2])
embedding = tf.keras.layers.Embedding(max(vocab)+1, 3)
embed = embedding(vocab)
print(embed)
输出:
tf.Tensor(
[[ 0.03242571 0.03685233 0.0223361 ]
[ 0.03242571 0.03685233 0.0223361 ]
[ 0.01391158 0.00046493 -0.00371295]], shape=(3, 3), dtype=float32)






![[golang Web开发] 3.golang web开发:处理请求](https://img-blog.csdnimg.cn/3099c80aac37473abeb9f41f8f61bd2a.png)