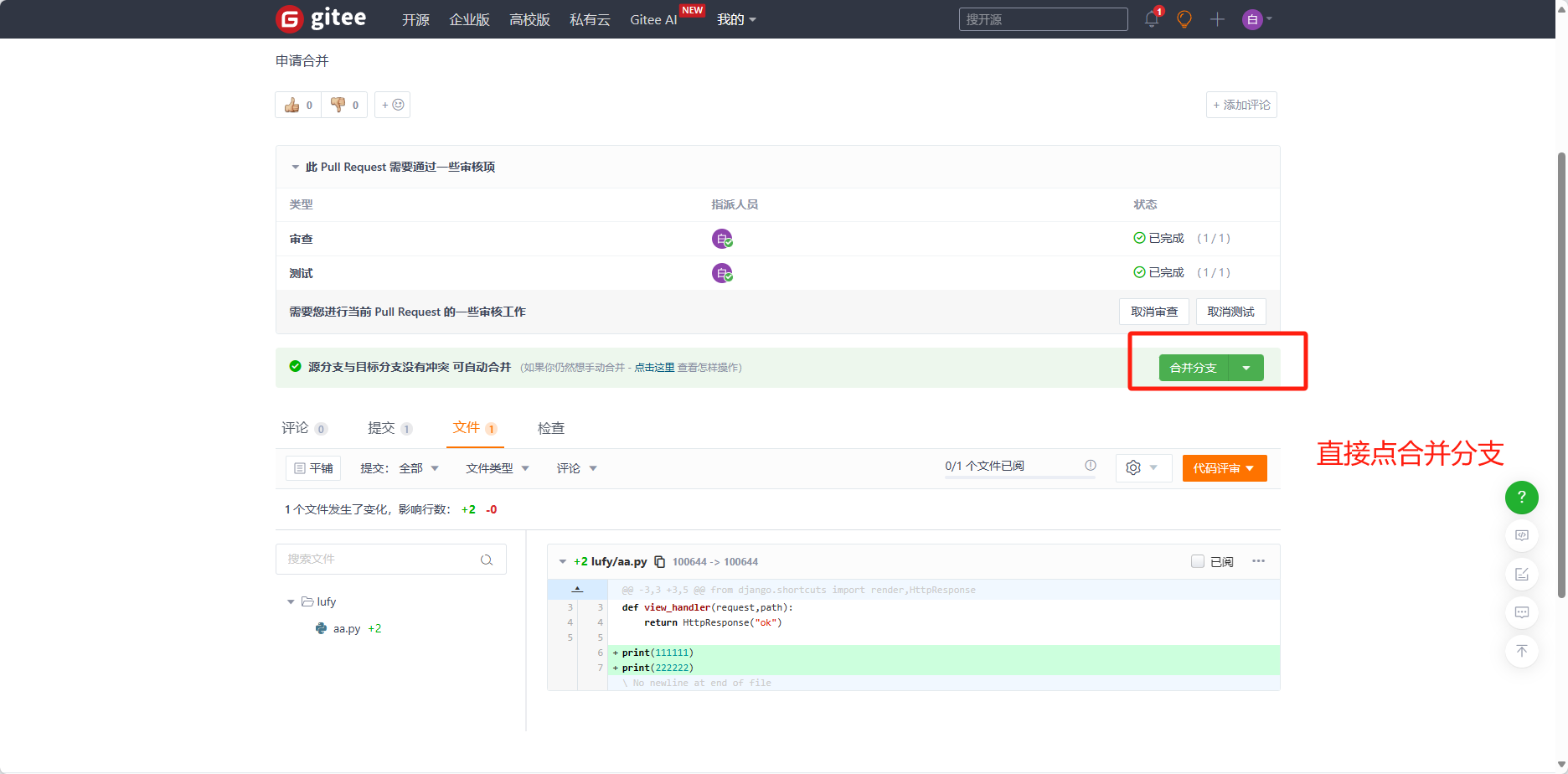
数据结构 —— B树
- B树
- B树的插入操作
- 分裂
- 孩子分裂
- 父亲分裂
我们之前学过了各种各样的树,二叉树,搜索二叉树,平衡二叉树,红黑树等等等等,其中平衡二叉树和红黑树都是控制树的高度来控制查找次数。
但是,这都基于内存能放的下:
平衡二叉树和红黑树等数据结构确实是为了在内存中高效处理动态数据集而设计的。它们的主要目标是在各种操作(如查找、插入和删除)中保持对数时间复杂度O(log n),其中n是树中节点的数量。这意味着随着数据集的增长,操作时间不会线性增长,而是以较慢的速度增长,保持较高的性能。
在设计上,平衡二叉树和红黑树假设整个数据集能够被加载到内存中,这是因为这些树的算法和操作需要频繁地遍历树的不同部分。磁盘I/O操作比内存访问要慢得多,因此如果数据集太大而不能完全装入内存,使用这些数据结构将大大降低效率。
但是,直接在磁盘上实现平衡二叉树或红黑树通常不是最有效的方法,因为磁盘访问的成本高,而这类树的许多操作涉及多次磁盘读写。因此,对于大规模数据集,更常见的做法是使用专门针对磁盘访问优化的数据结构,如B树或B+树,它们在设计上考虑了磁盘I/O的特性,可以更有效地处理大量数据。
B树
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树(后面有一个B的改进版本B+树,然后有些地方的B树写的的是B-树,注意不要误读成"B减树")。一棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
- 根节点至少有两个孩子
- 每个分支节点都包含k-1个关键字和k个孩子,其中 ceil(m/2) ≤ k ≤ m ceil是向上取整函数
- 每个叶子节点都包含k-1个关键字,其中 ceil(m/2) ≤ k ≤ m
- 所有的叶子节点都在同一层
- 每个节点中的关键字从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
- 每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An)其中,Ki(1≤i≤n)为关键字,且Ki<Ki+1(1≤i≤n-1)。Ai(0≤i≤n)为指向子树根结点的指针。且Ai所指子树所有结点中的关键字均小于Ki+1。n为结点中关键字的个数,满足ceil(m/2)-1≤n≤m-1。
说白了,我们以前的树中,一个结点包含的数据量只能有一个:
 B树的基本思想就是一个结点可以携带多个数据:
B树的基本思想就是一个结点可以携带多个数据:

但是每个结点也有自己的要求:一个结点要包括数据和孩子:
假设我们是一棵3阶的B树,规定每个结点的孩子最多有3个,而数据个数比孩子个数小1:
 但是我们数据个数为偶数的话,后面的分裂操作不好操作,所以我们会多开一个数据空间,但是不会装入任何数据,同时会增加一个孩子:
但是我们数据个数为偶数的话,后面的分裂操作不好操作,所以我们会多开一个数据空间,但是不会装入任何数据,同时会增加一个孩子:

B树的插入操作
我们这里以3阶的B树为例:
int a[] = {53, 139, 75, 49, 145, 36, 101} //构建b树

下面我们要插入75:
 这个时候数据个数已经超过了两个,需要进行分裂:
这个时候数据个数已经超过了两个,需要进行分裂:
分裂
这个时候75被提出来:


接下来我们插入49,145:

孩子分裂
接着我们插入36


父亲分裂
我们这样一直插入,插入到139:


B树的插入过程是反人类的,是先有孩子,再有父亲,其中孩子会分裂,父亲也会分裂
我们来看看代码,大家能看懂多少看多少:
#pragma once
#include <iostream>
using namespace std;
// B-树节点模板定义
template<class K, size_t M>
struct BTreeNode
{
// 键数组,存储节点的关键字
K _keys[M];
// 子节点数组,存储指向子节点的指针
BTreeNode<K, M>* _Children[M + 1];
// 指向父节点的指针
BTreeNode<K, M>* _Parent;
// 节点中的实际关键字数量
size_t _n;
// 构造函数,初始化节点
BTreeNode()
{
// 初始化所有键为空
for (int i = 0; i < M; i++)
{
_keys[i] = K();
_Children[i] = nullptr;
}
// 初始化最后一个子节点指针为空
_Children[M] = nullptr;
_Parent = nullptr;
_n = 0; // 节点中实际关键字数量为0
}
};
// B-树模板类定义
template<class K, size_t M>
class BTree
{
typedef BTreeNode<K, M> _Node;
public:
// 查找键的函数
pair<_Node*, int> Find(const K& key)
{
_Node* cur = _root; // 从根节点开始查找
_Node* parent = nullptr;
while (cur)
{
size_t i = 0;
// 在当前节点中查找键
while (i < cur->_n)
{
if (key < cur->_keys[i])
{
break; // 键小于当前键,应该在左子树
}
else if (key > cur->_keys[i])
{
i++; // 键大于当前键,检查下一个键
}
else
{
return make_pair(cur, i); // 找到键,返回节点和键的索引
}
}
// 移动到下一个子节点
parent = cur;
cur = cur->_Children[i];
}
// 没有找到键,返回父节点和-1
return make_pair(parent, -1);
}
// 插入键到节点中的函数
void InsertKey(_Node* node, const K& key, _Node* child)
{
int end = node->_n - 1;
// 找到插入位置并移动键和子节点
while (end >= 0)
{
if (key < node->_keys[end])
{
node->_keys[end + 1] = node->_keys[end];
node->_Children[end + 2] = node->_Children[end + 1];
end--;
}
else
{
break;
}
}
// 插入新的键和子节点
node->_keys[end + 1] = key;
node->_Children[end + 2] = child;
node->_n++;
}
// 插入键的主函数
bool Insert(const K& key)
{
if (_root == nullptr)
{
// 如果树为空,创建根节点并插入键
_root = new _Node();
_root->_keys[0] = key;
_root->_n++;
return true;
}
pair<_Node*, int> ret = Find(key);
if (ret.second >= 0)
{
// 键已存在,返回false
return false;
}
_Node* parent = ret.first;
K newkey = key;
_Node* child = nullptr;
while (1)
{
// 在父节点中插入键
InsertKey(parent, newkey, child);
if (parent->_n < M)
{
// 如果父节点未满,插入成功
return true;
}
else
{
// 父节点已满,需要分裂
size_t mid = M / 2;
// 创建一个新节点,并将父节点的一部分键和子节点移动到新节点中
_Node* brother = new _Node;
size_t j = 0;
size_t i = mid + 1;
for (; i <= M - 1; i++)
{
brother->_keys[j] = parent->_keys[i];
brother->_Children[j] = parent->_Children[i];
if (parent->_Children[i])
{
parent->_Children[i]->_Parent = brother; //父节点分裂,分裂出了父亲的brother
}
j++;
parent->_keys[i] = K();
}
// 处理新节点的最后一个右孩子节点
brother->_Children[j] = parent->_Children[i];
if (parent->_Children[i])
{
parent->_Children[i]->_Parent = brother;
}
brother->_n = j;
parent->_n -= j + 1;
// 将父节点的中间键提升到新节点
newkey = parent->_keys[mid];
child = brother;
if (parent->_Parent == nullptr)
{
// 如果父节点是根节点,则创建新的根节点
_root = new _Node();
_root->_keys[0] = parent->_keys[mid];
_root->_Children[0] = parent;
_root->_Children[1] = brother;
_root->_n = 1;
parent->_keys[mid] = K();
parent->_Parent = _root;
brother->_Parent = _root;
break;
}
else
{
// 继续向父节点的父节点插入分裂后的节点
newkey = parent->_keys[mid];
parent->_keys[mid] = K();
child = brother;
parent = parent->_Parent;
}
}
}
return true;
}
// 中序遍历树的函数
void InOrder()
{
_InOrder(_root);
}
// 递归实现的中序遍历
void _InOrder(_Node* pRoot)
{
if (nullptr == pRoot)
return;
for (size_t i = 0; i < pRoot->_n; ++i)
{
_InOrder(pRoot->_Children[i]);
cout << pRoot->_keys[i] << " ";
}
_InOrder(pRoot->_Children[pRoot->_n]);
}
private:
// 树的根节点
_Node* _root = nullptr;
};
// 测试函数
void Test()
{
int a[] = { 53, 139, 75, 49, 145, 36, 101, 34, 1, 9, 41 };
BTree<int, 3> t;
for (auto e : a)
{
t.Insert(e);
}
t.InOrder();
}
我们可以测试,如果打印的顺序是升序,说明我们代码的逻辑没问题:

写代码要注意几点:
- 插入新结点,有可能改变父子关系(是第一个数据的孩子,插入后有可能会变成第二个数据的孩子)。
- 分裂结点也有可能改变父子关系(变成父亲兄弟的孩子)