🔗 LangChain for LLM Application Development - DeepLearning.AI
学习目标
1、Langchain的历史记忆 ConversationBufferMemory
2、基于窗口限制的临时记忆 ConversationBufferWindowMemory
3、基于Token数量的临时记忆 ConversationTokenBufferMemory
4、基于历史内容摘要的临时记忆 ConversationSummaryMemory
Langchain的历史记忆(ConversationBufferMemory)
import os
import warnings
from dotenv import load_dotenv, find_dotenv
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
_ = load_dotenv(find_dotenv())
warnings.filterwarnings('ignore')我们依然使用智谱的LLM,实例化一下Langchain的记忆模块,并构建一个带有记忆的对话模型
llm = ChatOpenAI(api_key=os.environ.get('ZHIPUAI_API_KEY'),
base_url=os.environ.get('ZHIPUAI_API_URL'),
model="glm-4",
temperature=0.98)
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=True
)进行对话
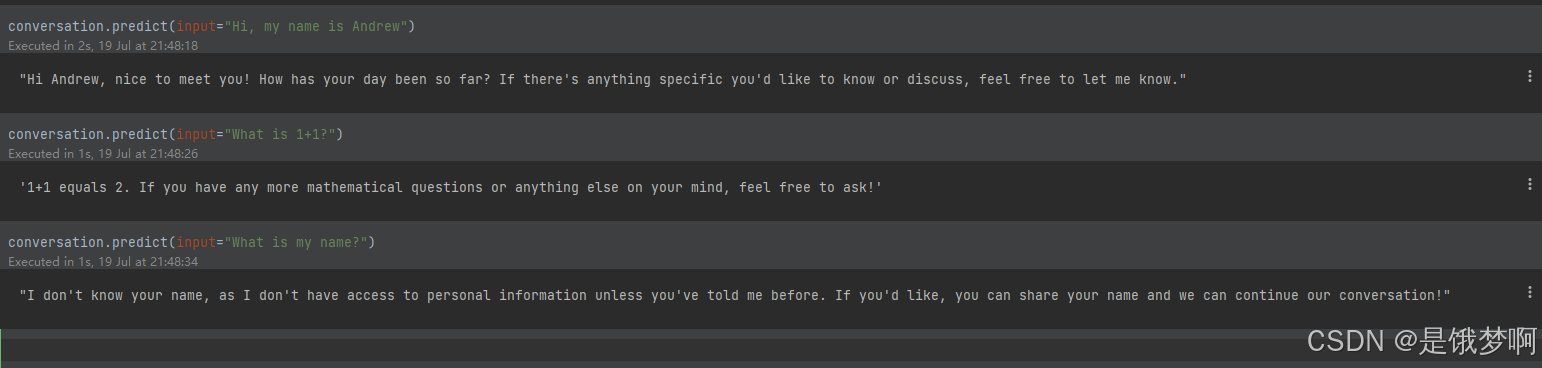
conversation.predict(input="Hi, my name is Andrew")
conversation.predict(input="What is 1+1?")
conversation.predict(input="What is my name?")模型确实可以记住我们的名字,打印一下记忆内容
#两种方式
print(memory.buffer)
memory.load_memory_variables({})此外,Langchain还提供了一个函数来添加对话内容
memory.save_context({"input": "Hi"},
{"output": "What's up"})基于窗口限制的临时记忆(ConversationBufferWindowMemory)
from langchain.memory import ConversationBufferWindowMemorymemory = ConversationBufferWindowMemory(k=1) #k表示我们保留最近几轮对话的数量我们先来添加两轮对话
memory.save_context({"input": "Hi"},
{"output": "What's up"})
memory.save_context({"input": "Not much, just hanging"},
{"output": "Cool"})通过对话历史可以发现,记忆中只保存了一轮的信息
memory.load_memory_variables({})
{'history': 'Human: Not much, just hanging\nAI: Cool'}我们使用这种记忆方式来构建一个对话模型,发现他确实遗忘了第一轮的信息
llm = ChatOpenAI(api_key=os.environ.get('ZHIPUAI_API_KEY'),
base_url=os.environ.get('ZHIPUAI_API_URL'),
model="glm-4",
temperature=0.98)
memory = ConversationBufferWindowMemory(k=1)
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=False
)
基于Token数量的临时记忆 ConversationTokenBufferMemory
由于langchain中计算token数量的函数并不支持GLM4,所有使用这个函数会报错,根据源代码目前是支持gpt-3.5-turbo-0301、gpt-3.5-turbo、gpt-4,不知道以后会不会加入国产的这些模型。
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=500)
memory.save_context({"input": "AI is what?!"},
{"output": "Amazing!"})
memory.save_context({"input": "Backpropagation is what?"},
{"output": "Beautiful!"})
memory.save_context({"input": "Chatbots are what?"},
{"output": "Charming!"})基于历史内容摘要的临时记忆 ConversationSummaryMemory
同理哈,这个函数的作用就是,我们会将历史的对话信息进行总结然后存在我们的记忆单元中,由于这里同样涉及到token的计算,所以这里也是无法正常运行的了。
from langchain.memory import ConversationSummaryBufferMemory
# create a long string
schedule = "There is a meeting at 8am with your product team. \
You will need your powerpoint presentation prepared. \
9am-12pm have time to work on your LangChain \
project which will go quickly because Langchain is such a powerful tool. \
At Noon, lunch at the italian resturant with a customer who is driving \
from over an hour away to meet you to understand the latest in AI. \
Be sure to bring your laptop to show the latest LLM demo."
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)
memory.save_context({"input": "Hello"}, {"output": "What's up"})
memory.save_context({"input": "Not much, just hanging"},
{"output": "Cool"})
memory.save_context({"input": "What is on the schedule today?"},
{"output": f"{schedule}"})
构建一个对话模型 (verbose设置为true可以查看到我们历史的一些信息)
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=True
)尝试进行提问
conversation.predict(input="What would be a good demo to show?")总结(吴恩达老师视频中的内容)