目录
- 一、简介
- 二、架构
- 三、分区Partition
- 1.分区概念
- 2.Offsets(偏移量)和消息的顺序
- 3.分区如何为Kafka提供扩展能力
- 4.producer写入策略
- 5.consumer消费机制
一、简介
Apache Kafka 是分布式发布 - 订阅消息系统,在 kafka 官网上对 kafka 的定义:一个分布式发布 - 订阅消息传递系统。
Kafka 最初由 LinkedIn 公司开发,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
Kafka 的主要应用场景有:日志收集系统和消息系统。
Kafka的原理、基础架构、以及使用场景-mikechen的互联网架构
二、架构
Kafka 的架构包括以下组件:
Kafka的原理、基础架构、以及使用场景-mikechen的互联网架构
- 1、话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名;
- 2、生产者(Producer):是能够发布消息到话题的任何对象
- 3、服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或 Kafka 集群;
- 4、消费者(Consumer):可以订阅一个或多个话题,并从 Broker 拉数据,从而消费这些已发布的消息;
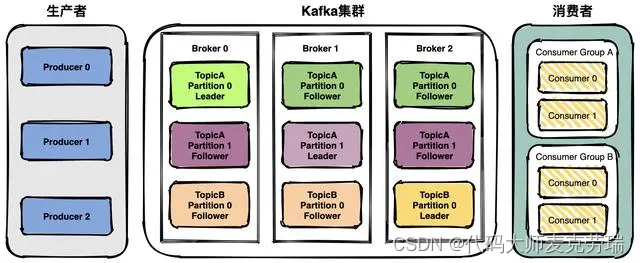
上图中可以看出,生产者将数据发送到 Broker 代理,Broker 代理有多个话题 topic ,消费者从 Broker 获取数据。
三、分区Partition
用过消息队列的同学对Kafka都不陌生,但是Kafka的topic中存在一个分区的概念,这是他和其他消息队列组件性能上一分高下的其中一个技术点,当然也是用好Kafka需要咱们开发人员理解透彻的一个技术点,接下来咱们就来掰扯一下分区Partition。
1.分区概念
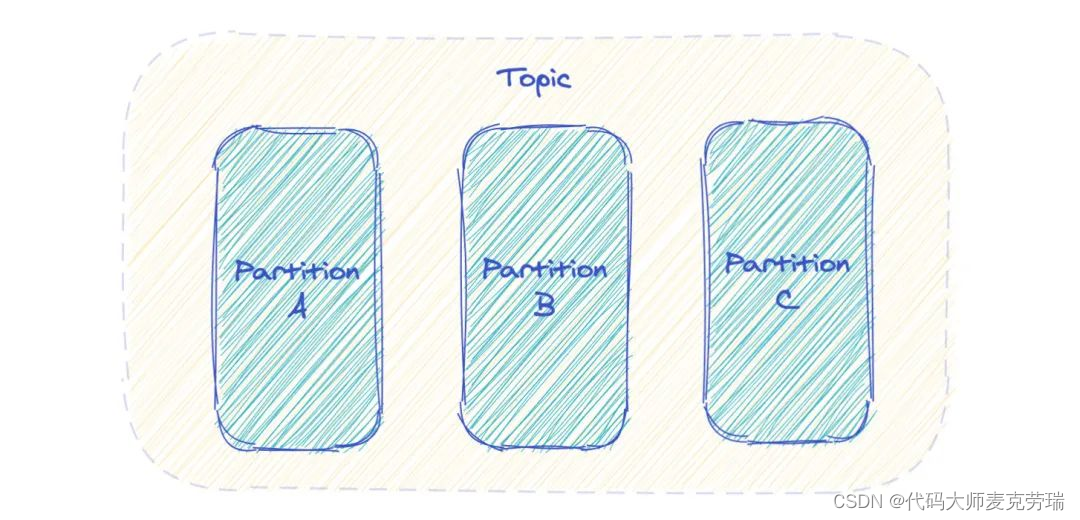
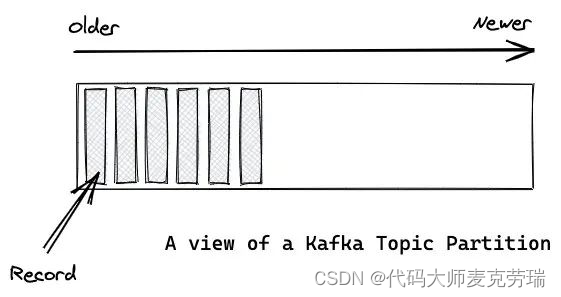
Kafka 中 Topic 被分成多个 Partition 分区。
Topic 是一个逻辑概念,Partition 是最小的存储单元,掌握着一个 Topic 的部分数据。
每个 Partition 都是一个单独的 log 文件,每条记录都以追加的形式写入。
Record(记录) 和 Message(消息)是一个概念。
2.Offsets(偏移量)和消息的顺序
Partition 中的每条记录都会被分配一个唯一的序号,称为 Offset(偏移量)。
Offset 是一个递增的、不可变的数字,由 Kafka 自动维护。
当一条记录写入 Partition 的时候,它就被追加到 log 文件的末尾,并被分配一个序号,作为 Offset。
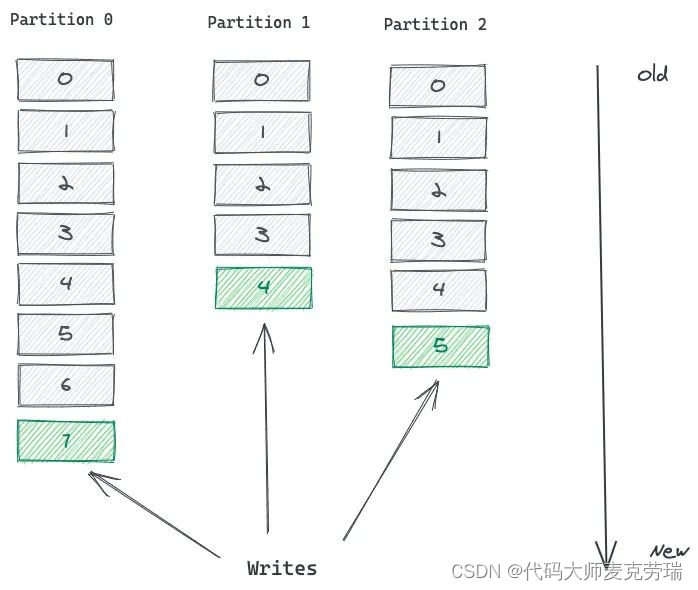
如上图,这个 Topic 有 3 个 Partition 分区,向 Topic 发送消息的时候,实际上是被写入某一个 Partition,并赋予 Offset。
消息的顺序性需要注意,一个 Topic 如果有多个 Partition 的话,那么从 Topic 这个层面来看,消息是无序的。
但单独看 Partition 的话,Partition 内部消息是有序的。
所以,一个 Partition 内部消息有序,一个 Topic 跨 Partition 是无序的。
如果强制要求 Topic 整体有序,就只能让 Topic 只有一个 Partition。
3.分区如何为Kafka提供扩展能力
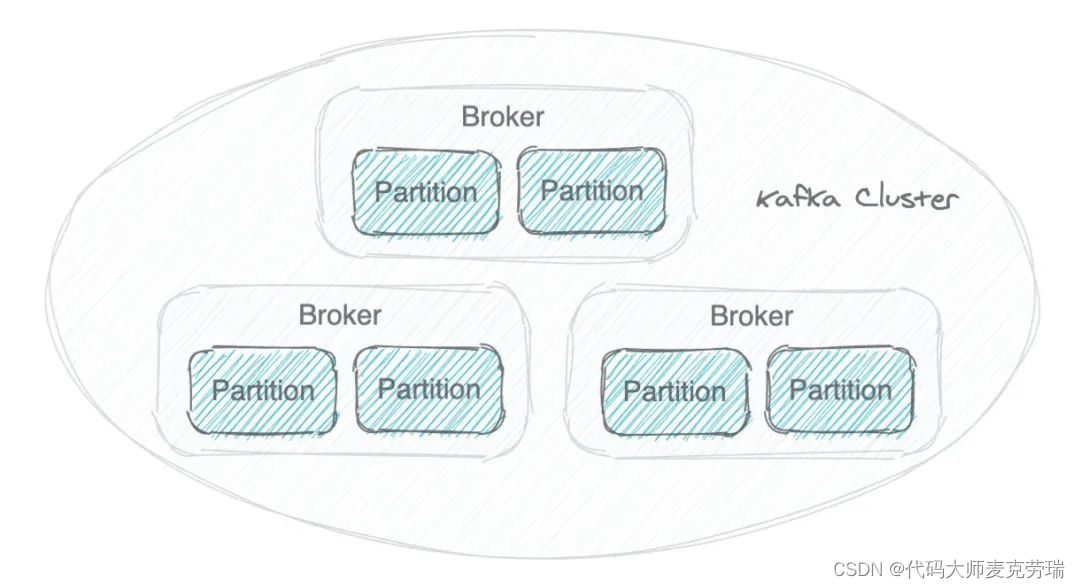
一个 Kafka 集群由多个 Broker(就是 Server) 构成,每个 Broker 中含有集群的部分数据。
Kafka 把 Topic 的多个 Partition 分布在多个 Broker 中。
这样会有多种好处:
- 如果把 Topic 的所有 Partition 都放在一个 Broker 上,那么这个 Topic 的可扩展性就大大降低了,会受限于这个 Broker 的 IO 能力。把 Partition 分散开之后,Topic 就可以水平扩展 。
- 一个 Topic 可以被多个 Consumer 并行消费。如果 Topic 的所有 Partition 都在一个 Broker,那么支持的 Consumer 数量就有限,而分散之后,可以支持更多的 Consumer。
- 一个 Consumer 可以有多个实例,Partition 分布在多个 Broker 的话,Consumer 的多个实例就可以连接不同的 Broker,大大提升了消息处理能力。可以让一个 Consumer 实例负责一个 Partition,这样消息处理既清晰又高效。
Kafka 为一个 Partition 生成多个副本,并且把它们分散在不同的 Broker。
如果一个 Broker 故障了,Consumer 可以在其他 Broker 上找到 Partition 的副本,继续获取消息。Partition 为 Kafka 提供了数据冗余。
4.producer写入策略
生产者写入分区的策略主要有以下几种:
1.轮询分区策略:生产者可以使用轮询策略将消息依次写入每个分区,实现负载均衡。在每次发送消息时,生产者会按照轮询的方式选择下一个可用的分区,并将消息写入该分区。这样可以确保消息均匀地分布在各个分区中。
2.随机分区策略:Kafka生产者随机的将消息写入分区,有可能会造成消息的分布不均,所以这个策略基本上也很少用。
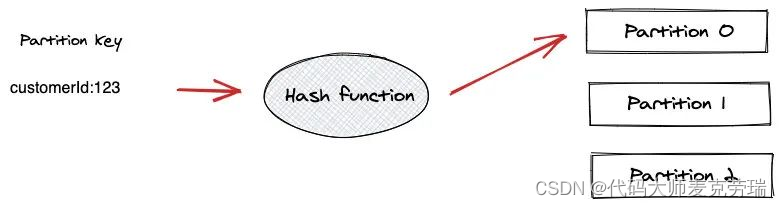
3.按 key 分区策略:Kafka生产者基于消息的键(key)进行哈希计算,然后将消息写入对应的分区。这种策略可以保证具有相同键的消息被写入到相同的分区,从而保证消息的顺序性。
这种方式需要注意 Partition 热点问题。
例如使用 User ID 作为 Partition Key,如果某一个 User 产生的消息特别多,是一个头部活跃用户,那么此用户的消息都进入同一个 Partition 就会产生热点问题,导致某个 Partition 极其繁忙。
4.自定义分区策略:Kafka生产者可以使用自定义分区策略来决定将消息写入哪个分区。
5.consumer消费机制
Kafka 不像普通消息队列具有发布/订阅功能,Kafka 不会向 Consumer 推送消息。当年因为不想换消息队列,用Kafka强行实现了发布订阅功能也正是利用了他的消费机制,具体可以看我之前的一篇帖子SpringBoot Kafka动态指定消费组。
Consumer 必须自己从 Topic 的 Partition 拉取消息。
一个 Consumer 连接到一个 Broker 的 Partition,从中依次读取消息。
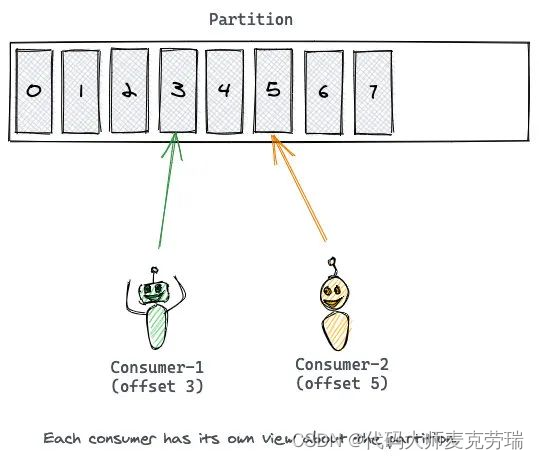
消息的 Offset 就是 Consumer 的游标,根据 Offset 来记录消息的消费情况。
读完一条消息之后,Consumer 会推进到 Partition 中的下一个 Offset,继续读取消息。
Offset 的推进和记录都是 Consumer 的责任,Kafka 是不管的。
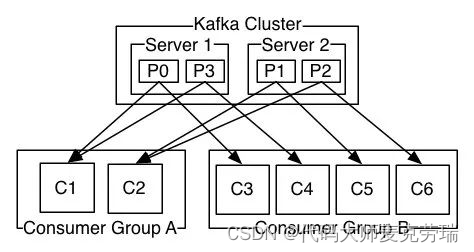
Kafka 中有一个 Consumer Group(消费组)的概念,多个 Consumer 组团去消费一个 Topic。
同组的 Consumer 有相同的 Group ID。
Consumer Group 机制会保障一条消息只被组内唯一一个 Consumer 消费,不会重复消费。
消费组这种方式可以让多个 Partition 并行消费,大大提高了消息的消费能力,最大并行度为 Topic 的 Partition 数量。
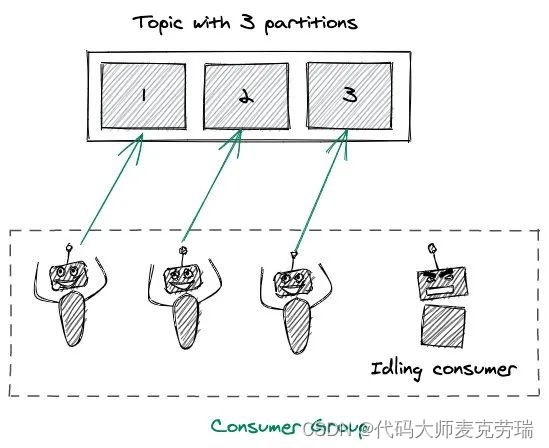
当你consumer数量大于partition数量的时候,其余空闲的consumer就是一种容错机制,当有consumer因其他原因无法正常工作时,空闲的节点就会补充上来。