1、安装graphframes的步骤
1.1 查看 spark 和 scala版本
在终端输入: spark-shell --version 查看spark 和scala版本

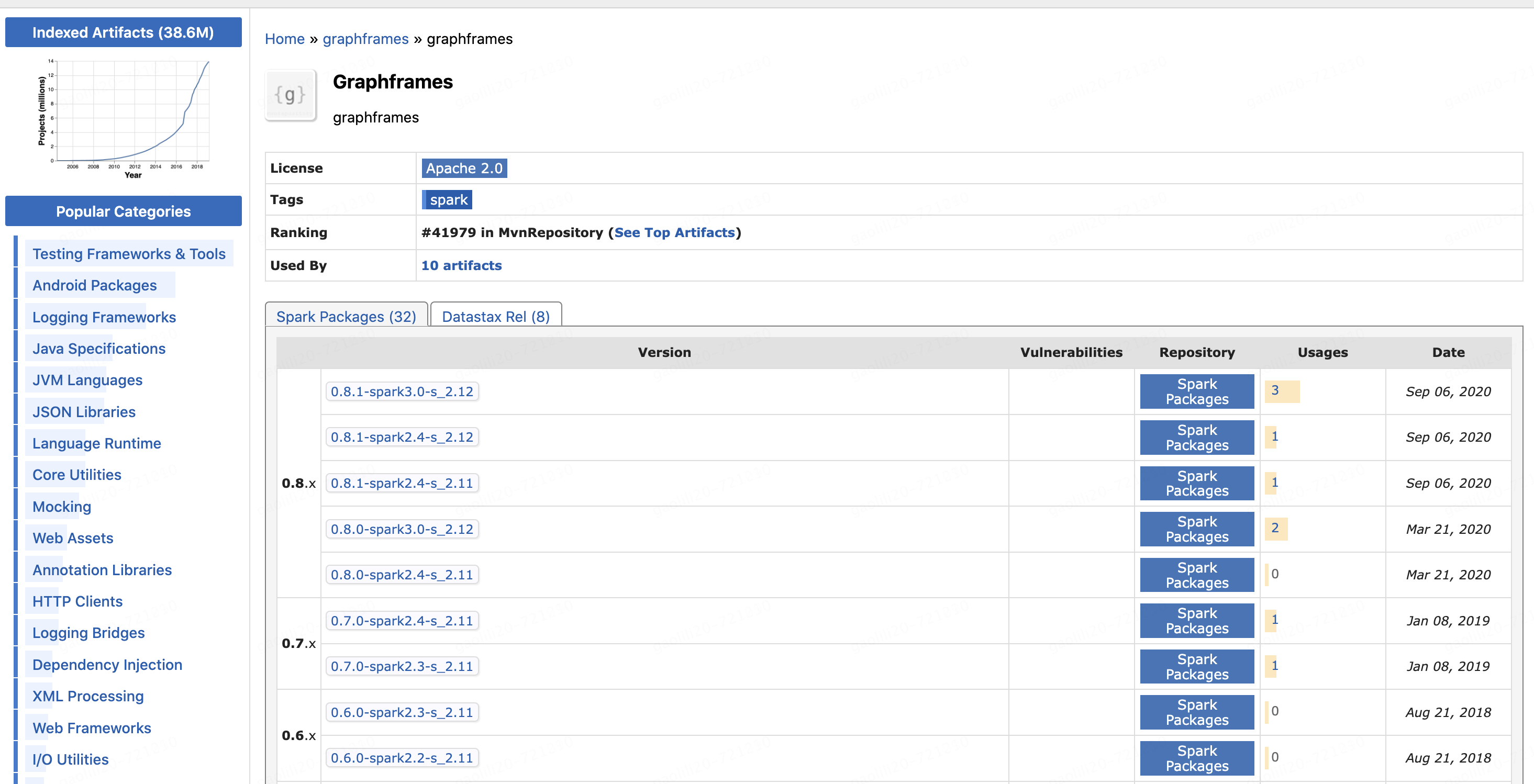
1.2 在maven库中下载对应版本的graphframes
https://mvnrepository.com/artifact/graphframes/graphframes
我这里需要的是spark 2.4 scala 2.11版本
https://mvnrepository.com/artifact/graphframes/graphframes/0.8.0-spark2.4-s_2.11
1.3 在pyspark的环境中配置graphframe的jar包
os.environ['PYSPARK_PYTHON'] = 'Python3.7/bin/python'
os.environ['PYSPARK_SUBMIT_ARGS'] = '--jars graphframes-0.8.1-spark2.4-s_2.11.jar pyspark-shell'
spark = SparkSession \
.builder \
.appName("read_data") \
.config('spark.pyspark.python', 'Python3.7/bin/python') \
.config('spark.yarn.dist.archives', 'hdfs://ns62007/user/dmc_adm/_PYSPARK_ENV/Python3.7.zip#Python3.7') \
.config('spark.executorEnv.PYSPARK_PYTHON', 'Python3.7/bin/python') \
.config('spark.sql.autoBroadcastJoinThreshold', '-1') \
.enableHiveSupport() \
.getOrCreate()
spark.sparkContext.addPyFile('graphframes-0.8.1-spark2.4-s_2.11.jar')2、导入GraphFrame创建图
2.1 导入包使用
from graphframes import GraphFrame2.2 创建图的例子
from pyspark.sql.types import *
import pandas as pd
from graphframes import GraphFrame
#创建图的方法1
v = spark.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
], ["id", "name", "age"])
# Create an Edge DataFrame with "src" and "dst" columns
e = spark.createDataFrame([
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
], ["src", "dst", "relationship"])
# Create a GraphFrame
g = GraphFrame(v, e)
# Query: Get in-degree of each vertex.
g.inDegrees.show()

也可以简单化顶点和边:
#创建图的方法2
edges_df= spark.createDataFrame([
("a", "b"),
("b", "c"),
("c", "b"),
], ["src", "dst"])
nodes_df=spark.createDataFrame([
(1, "a"),
(2, "b"),
(3, "c")
], ["num","id"])
graph=GraphFrame(nodes_df, edges_df)
graph.inDegrees.show()
3、使用GraphFrame查看图
3.1 找出age属性最小的顶点
# 你可以像使用 dataframe一样来使用 graphframe!!!!
g.vertices.groupBy().min("age").show()

3.2 过滤顶点和边,创建子图
# 直接用filterVertices和filterEdges过滤顶点和边用来创建子图
g1.filterVertices("age > 30").filterEdges("relationship = 'friend'").vertices.show()
g1.filterVertices("age > 30").filterEdges("relationship = 'friend'").dropIsolatedVertices().vertices.show()
3.3 也可以像dataframe一样过滤顶点和边
g.vertices.where(col("id")=="a").show()
print(g.vertices.where(col("age")==34).count())
g.edges.show()
g.edges.where(col("src")>col("dst")).show()
3.4 路径搜索和筛选
# 路径搜索
paths = g.find("(a)-[e]->(b)")
paths.show()
# 路径搜索 和筛选
path = g.find("(a)-[e]->(b)")\
.filter("e.relationship = 'follow'")\
.filter("a.age < b.age")
path.show()
3.5 计算BFS
# 计算bfs
res = g1.bfs("id='b'","id<>'b'")
res.select([column for column in res.columns]).show()
3.6 查看关系数据集中的列
# 选择关系数据集中的列
e2 = paths.select("e.src", "e.dst", "e.relationship")
e2.show()

3.7 使用顶点和边的集合构造子图
# 使用顶点和边的集合构造子图
g2 = GraphFrame(g.vertices, e2)
g2.vertices.show()
g2.edges.show()

3.8 统计符合条件的边和顶点个数
# Query: Count the number of "follow" connections in the graph.
t = g.edges.filter("relationship = 'follow'").count()
print(t)
print(g.vertices.where(col("age")==34).count())3.9 计算每个节点的入度和出度
from pyspark.sql import functions as F
# 计算每个节点的入度和出度
in_degrees = g.inDegrees
out_degrees = g.outDegrees
# 找到具有最大入度的节点
max_in_degree = in_degrees.agg(F.max("inDegree")).head()[0]
node_with_max_in_degree = in_degrees.filter(in_degrees.inDegree == max_in_degree).select("id")
# 找到具有最大出度的节点
max_out_degree = out_degrees.agg(F.max("outDegree")).head()[0]
node_with_max_out_degree = out_degrees.filter(out_degrees.outDegree == max_out_degree).select("id")
# 打印结果
node_with_max_in_degree.show()
node_with_max_out_degree.show()

3.10 计算顶点的pagerank
# Run PageRank algorithm, and show results.
results = g.pageRank(resetProbability=0.01, maxIter=5)
results.vertices.select("id", "pagerank").show()
results.vertices.show()
4、graphframes和spark 的graphX的区别
GraphX - Spark 2.3.0 Documentation
GraphFrames,该类库是构建在Spark DataFrames之上,它既能利用DataFrame良好的扩展性和强大的性能,同时也为Scala、Java和Python提供了统一的图处理API。GraphX基于RDD API,不支持Python API; 但GraphFrame基于DataFrame,并且支持Python API。
目前GraphFrames还未集成到Spark中,而是作为单独的项目存在。GraphFrames遵循与Spark相同的代码质量标准,并且它是针对大量Spark版本进行交叉编译和发布的。
与Apache Spark的GraphX类似,GraphFrames支持多种图处理功能,有下面几方面的优势:
1、统一的 API: 为Python、Java和Scala三种语言提供了统一的接口,这是Python和Java首次能够使用GraphX的全部算法。
2、强大的查询功能:GraphFrames使得用户可以构建与Spark SQL以及DataFrame类似的查询语句。
3、图的存储和读取:GraphFrames与DataFrame的数据源完全兼容,支持以Parquet、JSON以及CSV等格式完成图的存储或读取。
在GraphFrames中图的顶点(Vertex)和边(Edge)都是以DataFrame形式存储的,所以一个图的所有信息都能够完整保存。
4、GraphFrames可以实现与GraphX的完美集成。两者之间相互转换时不会丢失任何数据。
5、书:图算法《Graph Algorithm》
O'Reilly free ebook《Graph Algorithm - Practical Examples in Apache Spark and Neo4j》
作者 Mark Needham & Amy E. Hodler
书旨在围绕这些重要的图分析类型,包括算法、概念、算法在机器学习上的实际应用,来扩展我们的知识和能力。从基本概念到基本算法,从处理平台和实际用例,作者为图的精彩世界编制了一份具有启发性和说明性的指南。
《图算法》第四章-1 路径查找和图搜索算法
![CTF-Web习题:[BJDCTF2020]Mark Loves cat](https://i-blog.csdnimg.cn/direct/166d3d717ca548ac82a461b1b2cf12aa.png)