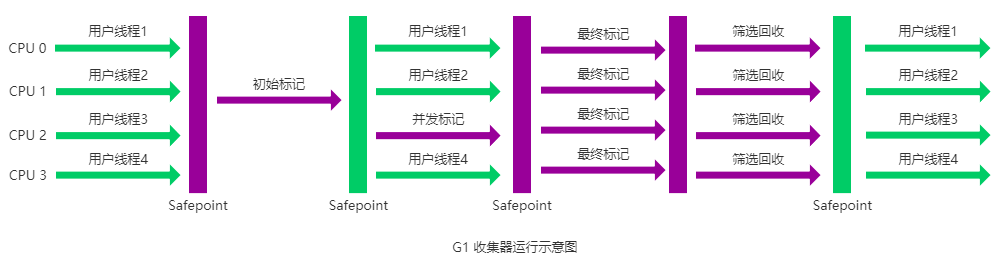
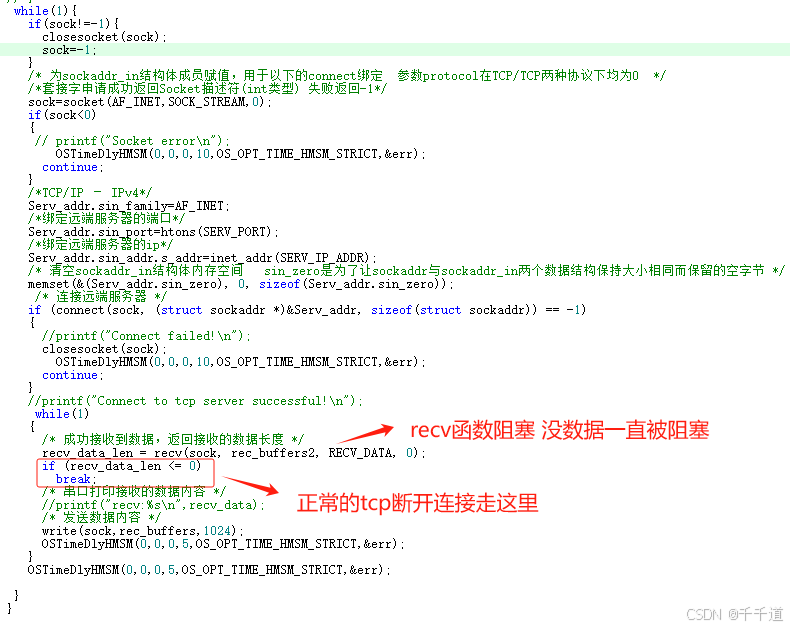
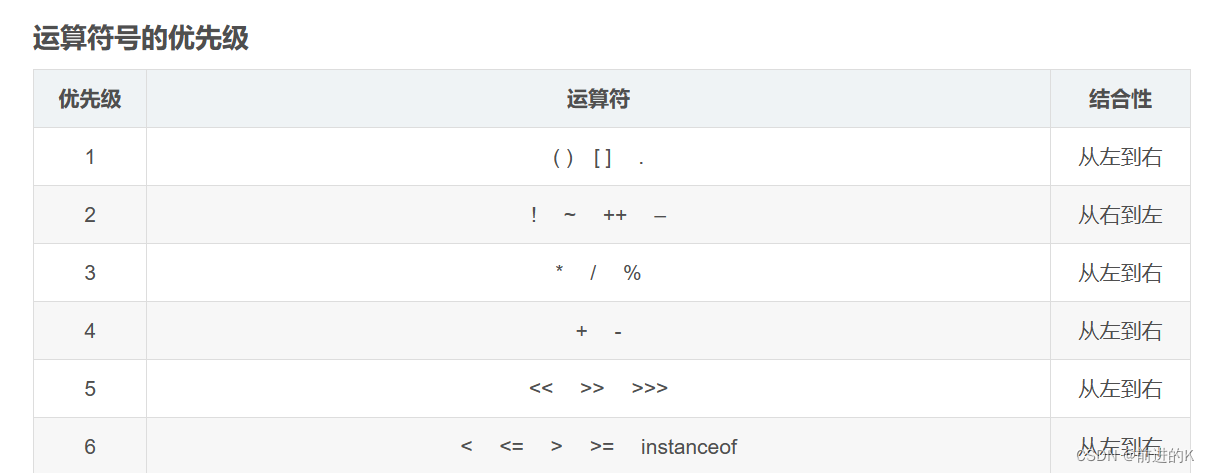
一、标记清除
1、原理
从根集合节点进行扫描,标记出所有的存活对象,最后扫描整个内存空间并清除没有标记的对象(即死亡对象)
标记后 (黑色:可回收 | 灰色:存活对象 | 白色:未使用 )

清除后
2、适用场景
-
存活对象较多的情况下比较高效
-
适用于年老代(即旧生代)
3、实现过程
-
标记阶段
-
标记阶段从root开始递归地给堆里所有被引用对象打上标记。标记算法一般是用深度或者广度搜索,深度搜索可以压缩内存使用量,所以一般用深度
-
-
清除阶段
-
collector也会遍历整个堆,然后回收释放所有没有打标的内存对象
-
清除阶段,通过变量 sweeping 遍历堆,具体来说就是从堆首地址 $heap_start 开始,按顺序一个个遍历对象的标志位
-
遍历回收过程中,我们用free_list空闲链表来链接所有被回收的空闲内存块
-
4、优化过程
-
multi-size空闲链表优化分配速度,按照区块大小来分配链表
-
延迟清理
5、优缺点
-
优点:
- 实现简单,逻辑清晰。
- 回收效率高,因为不需要移动存活对象。
-
缺点:
- 会产生内存碎片,这可能导致在内存充足但碎片较多时,无法为新对象分配足够的连续内存空间。
- 标记清除算法通常需要“Stop-the-World”,即暂停所有应用线程,以进行垃圾回收,这会影响应用的响应性能。
二、复制算法
1、原理
-
将活着的内存空间分为两块,每次只使用其中一块,在垃圾回收时将正在使用的内存中的存活对象复制到未使用的内存块中,之后清除正在使用的内存块中的所有对象,交换两个内存的角色,最后完成垃圾回收
-

2、实现过程
内存划分:
新生代内存被划分为Eden区和两个Survivor区(S0和S1)。默认情况下,Eden区和Survivor区的比例是8:1:1,即Eden区占80%,两个Survivor区各占10%。
对象分配:
新创建的对象首先被分配在Eden区,如果Eden区满了,会触发一次Minor GC(Young GC)。
Minor GC过程:
存活的对象(即还在被引用的对象)会被复制到其中一个Survivor区(S0或S1,假设当前使用的是S0)。清理Eden区和另一个Survivor区(S1)的内存空间。交换Survivor区的角色,即原本S0成为空闲区,原本S1成为下一次Minor GC的目标区。内存使用效率:由于新生代中大部分对象都是朝生夕死的,因此复制算法在新生代中的实际效率是非常高的。只有少量存活对象需要被复制,大部分内存空间都可以直接被清理掉。
3、优缺点
-
优点:
-
没有标记和清除过程,实现简单,运行高效。
-
复制过去以后保证空间的连续性,不会出现"碎片"问题。
-
缺点:
-
此算法的缺点也是很明显的,就是需要两倍的内存空间。
-
对于G1这种分拆成大量region的GC,复制而不是移动,意味着GC需要维护region之间对象引用关系,不管是内存占用或者时间开销也不小
三、标记整理
1、原理
标记整理和标记清除的非常相似,但是标记整理的过程是这样的,首先是标记要清理的对象,然后将剩下所有存活的对象都移动到一端,然后直接清理端边界以外的内存。其实也就是标记-整理-清除算法,多了一个对内存的整理的过程。
图解:
回收前回收前 (黑色:可回收 | 灰色:存活对象 | 白色:未使用 )

回收后

2、实现过程
标记整理算法主要分为两个阶段:标记阶段和整理阶段。
标记阶段:与标记清除算法相同,标记阶段会遍历整个堆内存,找出所有存活的对象(即被引用的对象),并给它们打上标记。
整理阶段:在标记阶段完成后,整理阶段会将所有存活的对象向一端移动(通常是向内存低地址方向移动),然后清理掉边界外的所有空间。这样,存活的对象就按照内存地址依次排列,从而消除了内存碎片
3、适用场景
JVM(Java Virtual Machine)中的标记整理(Mark-Compact)算法是垃圾回收(Garbage Collection, GC)的一种重要算法,它是对标记清除(Mark-Sweep)算法的改进,主要用于解决内存碎片问题
4、优缺点
算法优点
消除内存碎片:标记整理算法通过将所有存活对象移动到一端,并清理边界外的空间,从而有效消除了内存碎片,提高了内存空间的利用率。
提高内存分配效率:当需要给新对象分配内存时,JVM只需要维持一个内存的起始地址即可,这比维护一个空闲列表要简单得多,从而提高了内存分配的效率。
算法缺点
效率相对较低:与复制算法相比,标记整理算法在整理阶段需要移动存活的对象,这可能会导致一定的性能开销。尤其是在存活对象较多时,移动的开销会更加明显。
需要暂停用户线程:与大多数垃圾回收算法一样,标记整理算法在执行过程中也需要暂停用户线程(Stop-The-World, STW),以便对整个堆内存进行扫描和整理。这可能会影响应用程序的响应性能
四、增量算法
1、原理
增量算法的主要思想是将原本需要一次完成的垃圾回收过程拆分成多个较小的片段,这些片段可以在应用程序运行过程中交替执行,以减少单次垃圾回收所需的暂停时间
2、算法特点
减少STW时间:通过将垃圾回收过程拆分成多个较小的片段,增量算法可以显著减少单次垃圾回收所需的暂停时间,从而提高应用程序的响应性能。
交替执行:增量算法的各个片段可以在应用程序运行过程中交替执行,以实现垃圾回收与应用程序执行的并发。
逐步完成:增量算法通过逐步完成垃圾回收过程,可以在不中断应用程序执行的情况下,逐步释放内存空间
3、实现过程
增量算法的实现通常依赖于以下关键技术:
- 写屏障(Write Barrier):写屏障是一种用于在对象引用发生变化时执行特定操作的机制。在增量算法中,写屏障可以用于记录对象的引用变化,以便在后续的垃圾回收片段中处理这些变化。
- 读屏障(Read Barrier):读屏障用于在读取对象引用时执行特定操作。在增量算法中,读屏障可以用于确保在读取对象引用时能够正确地判断对象的存活状态。
- 增量标记(Incremental Marking):增量标记是增量算法中的核心部分,它负责在多个较小的片段中逐步完成对象的标记过程。通过增量标记,可以在不中断应用程序执行的情况下,逐步确定哪些对象是需要被回收的垃圾
4、优缺点
优势:
- 减少STW时间,提高应用程序的响应性能。
- 允许垃圾回收与应用程序执行并发进行,提高系统吞吐量。
不足:
- 由于垃圾回收过程被拆分成多个片段交替执行,可能会增加垃圾回收的总时间。
- 在处理对象引用变化时,需要引入额外的写屏障和读屏障机制,增加了系统的复杂性