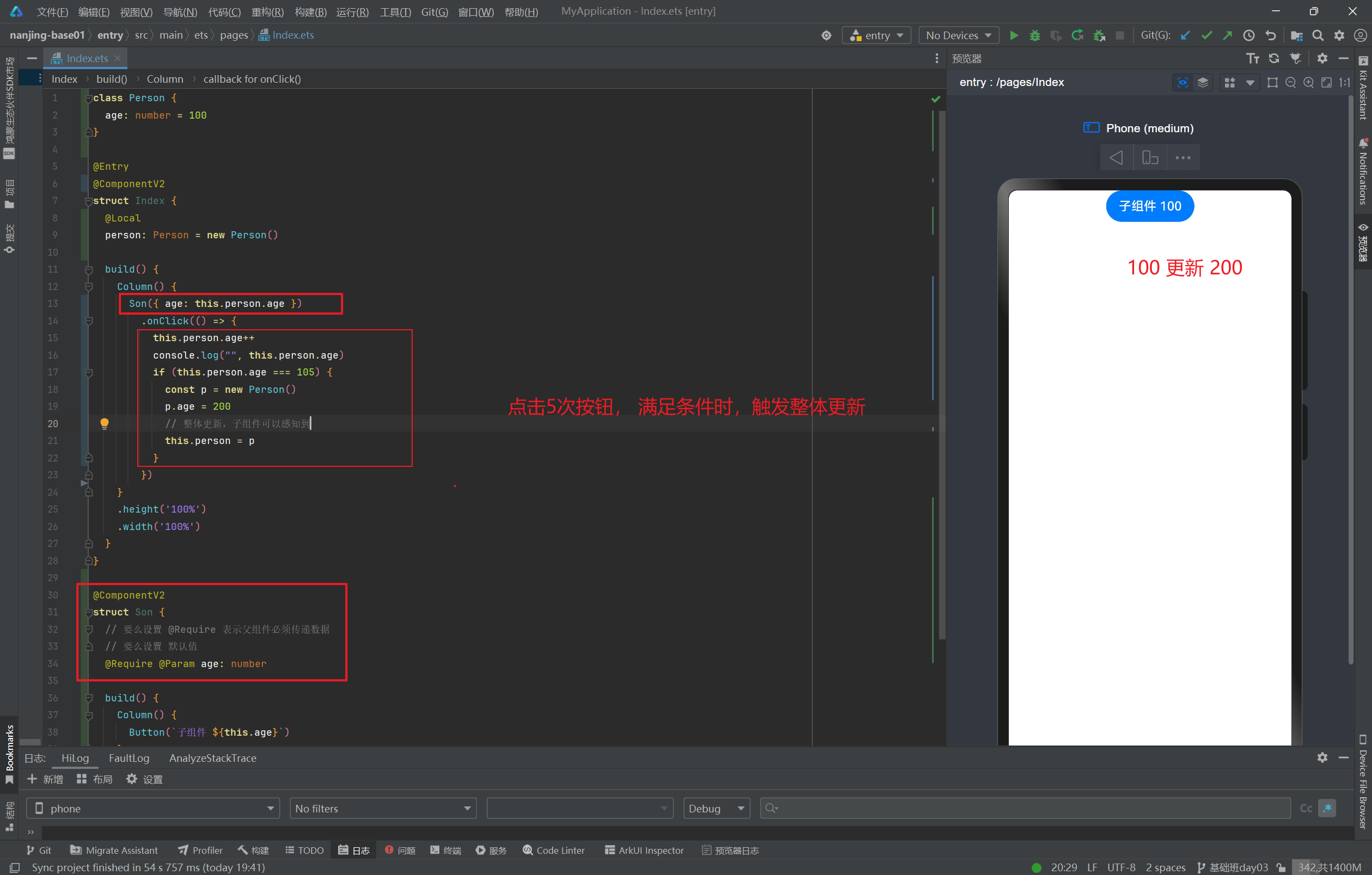
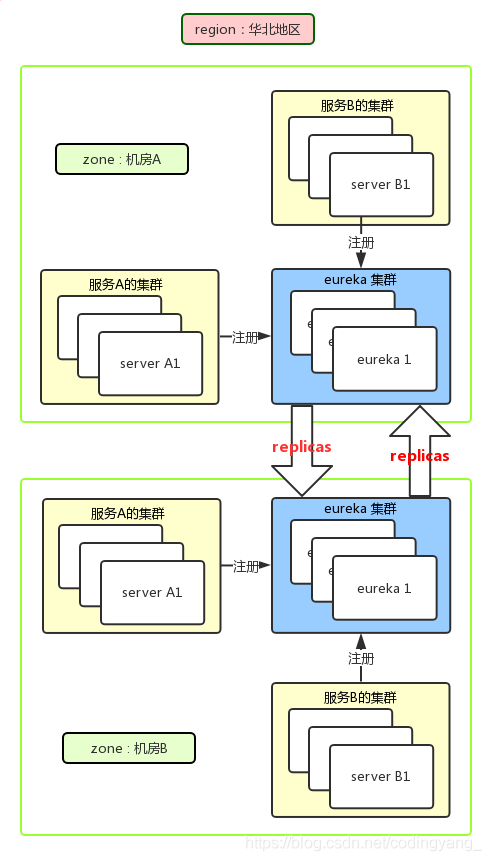
之前,我们分享了国内一些开源的大型语言模型(LLM)。今天,我想向大家介绍在Hugging Face平台上发现的一些国际上备受关注、被誉为超越GPT的LLM。对于熟悉LLM的朋友们而言,你们一定知道这些模型的强大之处:它们能够根据输入内容生成多样化的文本。这些模型经过大量数据训练,能够灵活模仿不同的写作风格、体裁和文本类型,其强大功能和多样性使它们在众多场景中发挥作用,例如文本摘要、问题解答和文本创作等。
但为什么会说这些模型超越了GPT呢?GPT作为OpenAI开发的一款广受欢迎的LLM,推出了多个版本,如GPT-2、GPT-3和GPT-4等,每个版本在规模和能力上都各有卓越。然而,GPT并非LLM的唯一选择。市场上存在许多其他由不同研究团队和机构开发的模型,这些模型在某些方面甚至有超越GPT的潜力。在这篇文章中,我将向大家展示这些模型的特点,并解释如何在Hugging Face平台上使用它们。
Hugging Face不仅是一个平台,它更像是一个资源库,汇集了超过12万个模型、2万个数据集以及5万个演示应用(Spaces),这些资源都是开源的,对公众开放。通过这个平台,你可以轻松地浏览、下载和使用这些模型,尤其是通过transformers库——一个既便捷又高效的Python库,专为LLM设计。值得一提的是,你还可以将自己的模型和数据集上传至Hugging Face Hub,与全球的LLM爱好者和AI专家交流合作。
1、Vigogne
Vigogne是蒙特利尔大学Bofeng Huang团队开发的一系列先进的大型语言模型(LLM)。这些模型在GPT架构的基础上进行了创新性的修改和优化,使得它们在效率和功能上更加卓越。一个关键的创新是引入了LORA(局部重权注意力)技术,这项技术有效减少了注意力机制的内存和计算需求。此外,Vigogne模型还采用了PEFT(位置编码微调)技术,这使得模型能够更好地适应不同任务和领域的特定位置编码要求。
模型地址:[huggingface.co/bofenghuang…]

Vigogne模型的种类众多,大小从7B到33B不等,展现出极强的多样性和适应性。这些模型在多个领域表现出色,能够生成高质量的文本,适用于聊天、指令生成和其他领域。你可以在Hugging Face Hub上找到这些模型,只需搜索用户名bofenghuang即可。比如,你可以试试vigogne-7b-chat模型,它专门设计用于生成引人入胜、流畅连贯的对话。下面是一个示例,展示了如何通过transformers库来使用这个模型:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
from vigogne.preprocess import generate_inference_chat_prompt
model_name_or_path = "bofenghuang/vigogne-7b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side="right", use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.float16, device_map="auto")
user_query = "Expliquez la différence entre DoS et phishing."
prompt = generate_inference_chat_prompt([[user_query, ""]], tokenizer=tokenizer)
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to(model.device)
input_length = input_ids.shape[1]
generated_outputs = model.generate(
input_ids=input_ids,
generation_config=GenerationConfig(
temperature=0.1,
do_sample=True,
repetition_penalty=1.0,
max_new_tokens=512,
),
return_dict_in_generate=True,
)
generated_tokens = generated_outputs.sequences[0, input_length:]
generated_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
2、JAIS
JAIS是由Core42和阿尔伯塔大学团队共同开发的一系列先进的大型语言模型(LLM)。这些模型基于GPT架构,但引入了若干关键的增强和优化措施,使得它们在性能上更加健壮和可扩展。例如,它们采用了名为GPTQ(GPT量化)的技术,这一技术通过使用低精度算术运算来减少模型的大小和响应时间。另一个创新是ACTORDER(激活函数排序)技术,它通过重新排序激活函数来提高模型的并行处理能力和吞吐量。
模型地址:[huggingface.co/core42/jais…]

JAIS模型有着多种不同的规模和版本,其参数的规模从13B到30B不等,展示了其在不同应用场景中的适应性和多功能性。这些模型在众多领域中都能够产生高质量的文本,如聊天、bloom等领域。你可以在Hugging Face Hub上通过用户名core42找到这些模型。举个例子,jais-13b-chat-hf模型能够基于特定输入生成幽默而机智的对话。下面是一个示例,展示了如何通过transformers库的使用:
# -*- coding: utf-8 -*-
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "inception-mbzuai/jais-13b"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True)
def get_response(text,tokenizer=tokenizer,model=model):
input_ids = tokenizer(text, return_tensors="pt").input_ids
inputs = input_ids.to(device)
input_len = inputs.shape[-1]
generate_ids = model.generate(
inputs,
top_p=0.9,
temperature=0.3,
max_length=200-input_len,
min_length=input_len + 4,
repetition_penalty=1.2,
do_sample=True,
)
response = tokenizer.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)[0]
return response
text= "عاصمة دولة الإمارات العربية المتحدة ه"
print(get_response(text))
text = "The capital of UAE is"
print(get_response(text))
3、BERTIN
BERTIN是一个由Manuel Romero和他在Platzi团队开发的特别的大型语言模型(LLM)。它是基于EleutherAI创造的GPT-3变种——GPT-J架构的,但BERTIN远不止是GPT-J的一个复制版本。这个模型是专门针对广泛的西班牙语文本进行训练的,成为了第一个能够高效生成高质量西班牙语文本的LLM。除此之外,它还具备处理代码生成和其他任务的能力。
模型地址:[huggingface.co/mrm8488/ber…]

BERTIN拥有不同的规模和版本,其参数的范围从6B到12B。这使得它能够适应多种领域的需求,生成高质量的文本,比如在聊天、alpaca和chivo等方面。你可以在Hugging Face Hub上通过用户名mrm8488找到它。例如,bertin-gpt-j-6B-ES-8bit模型就是其中之一,它擅长根据给定的输入生成流畅和连贯的西班牙语文本。下面是一个示例,展示了如何利用transformers库来使用这个模型:
import transformers
import torch
from Utils import GPTJBlock, GPTJForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
transformers.models.gptj.modeling_gptj.GPTJBlock = GPTJBlock # monkey-patch GPT-J
ckpt = "mrm8488/bertin-gpt-j-6B-ES-8bit"
tokenizer = transformers.AutoTokenizer.from_pretrained(ckpt)
model = GPTJForCausalLM.from_pretrained(ckpt, pad_token_id=tokenizer.eos_token_id, low_cpu_mem_usage=True).to(device)
prompt = tokenizer("El sentido de la vida es", return_tensors='pt')
prompt = {key: value.to(device) for key, value in prompt.items()}
out = model.generate(**prompt, max_length=64, do_sample=True)
print(tokenizer.decode(out[0]))
4、Mistral
Mistral是剑桥大学的FPHam团队开发的一系列新型大型语言模型(LLM)。这些模型虽然以GPT-2架构为基础,经过扩展和改进,从而在表现力和多样性方面有了显著提升。例如,它们引入了CLP(对比性语言预训练)技术,这种技术特别强化了模型在理解自然语言的风格、情感和主题方面的能力。此外,Mistral模型还采用了PEFT(位置编码微调)技术,以更好地适应不同任务和领域中的位置编码需求。
模型地址:[huggingface.co/mistralai/M…]

Mistral模型涵盖多种规模和版本,参数大小从6B到7B不等,这使得它们能够广泛应用于各类领域,包括指导性文本、提问、bloom等。在Hugging Face Hub上,你可以通过搜索用户名FPHam来找到这些模型。比如,你可以尝试使用mistral-7b-chat模型,这个模型擅长根据特定输入生成相关且引人入胜的问题。下面是一个展示如何通过transformers库使用这个模型的简单示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("openskyml/mistral-7b-chat")
model = AutoModelForCausalLM.from_pretrained("openskyml/mistral-7b-chat")
# encode the input text
input_ids = tokenizer.encode("The Eiffel Tower is a famous landmark in Paris.", return_tensors="pt")
# generate the output text
output_ids = model.generate(input_ids, max_length=50)
# decode the output text
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(output_text)
5、Igel
Igel是由Phil Schmid及其在Hugging Face团队开发的一款新颖的大型语言模型(LLM)。该模型建立在EleutherAI创造的GPT-3变种GPT-Neo架构之上。但是,Igel并不仅仅是GPT-Neo的翻版,而是一个全新的模型,专门针对大量多样化的德语文本进行训练。这使得Igel成为首个能够高效生成高质量德语文本的LLM,并且它还具备处理代码生成和其他任务的能力。
模型地址:[huggingface.co/philschmid/…]

Igel提供了多种不同的规模和版本,其参数的规模从2.7B到13B不等,显示出其广泛的应用潜力。这个模型在多个领域都能生成高质量的文本,比如聊天、alpaca和igel等。你可以在Hugging Face Hub上通过用户名philschmid找到它。例如,instruct-igel-001模型是其中的一个选择,它擅长根据给定的输入生成流畅和连贯的德语文本。以下是一个展示如何利用transformers库来使用这个模型的示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("philschmid/instruct-igel-001")
model = AutoModelForCausalLM.from_pretrained("philschmid/instruct-igel-001")
# encode the input text
input_ids = tokenizer.encode("Wie macht man einen Kuchen?", return_tensors="pt")
# generate the output text
output_ids = model.generate(input_ids, max_length=50)
# decode the output text
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(output_text)
结论
在Hugging Face平台上,你能发现一些相较于GPT更具优势的大型语言模型(LLM)。这些模型不仅功能全面,让人印象深刻,还充满创新和多样性。它们能够适用于各种不同的领域、语言和任务,生成高质量的文本,同时还可以轻松地结合transformers库进行使用。在Hugging Face Hub上,还有更多其他LLM模型等待你去探索,你可以找到符合你需求和兴趣的新奇、令人兴奋的模型。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓