目录
一、库的操作
创建数据库
查看数据库
显示创建语句
修改数据库
删除数据库
备份和恢复
二、表的操作
创建表
查看表结构
修改表
删除表
三、表的增删查改
新增数据
插入否则更新
插入查询的结果
查找数据
为查询结果指定别名
结果去重
where 条件
结果排序
筛选分页结果
聚合函数查询
分组查询
HAVING 条件
修改数据
替换数据
修改数据
删除数据
截断表
SQL语句中不区分大小写,下面都以小写为主
下面的SQL语句第一行是最简便的,第二行是具体的,包含可选的内容,[ ] 中代表的是可选项
一、库的操作
创建数据库
创建一个新的数据库
create database 库名;
create database [if not exists] 库名 [charset=字符集] [collate=校验规则];charset:用于指定数据库所采用的编码格式,字符集
collate:用于指定数据库所采用的校验规则
如果创建数据库时未指明数据库的编码格式或校验规则,则默认使用MySQL配置文件中对应的编码格式和校验规则
默认的编码格式是utf8,默认的校验规则是utf8_general_ci
不指明数据库的编码格式和校验规则:
通过charset和collate分别指明数据库的编码格式和校验规则:
查看数据库
可以查看系统中所有的数据库
show databases;显示创建语句
可以查看对应数据库的创建语句
show create database 数据库名
注意:
①数据库的名字加上反引号,是为了防止使用的数据库名与关键字冲突②/*!40100 DEFAULT CHARACTER SET utf8 */不是注释,它表示当前MySQL版本如果大于4.10,则执行后面的SQL语句
修改数据库
可以修改数据库的字符集或校验规则
alter database 库名 [charset=字符集] [collate=校验规则];
需要注意的是MySQL数据库不支持修改库名
db1的字符集、校验规则原本是默认的,现在将数据库的字符集改为gbk,将数据库的校验规则改为gbk_bin:

删除数据库
删除一个现有的数据库
drop database 库名;
drop database [if exists] 库名;
删除数据库后该数据库对应的文件夹就被删除了
并且删除数据库后,该数据库下的所有表也都会被级联删除,因此不要随意删除数据库
备份和恢复
数据库的备份
mysqldump -P 端口号 -u 用户名 -p 密码 -B 数据库名1 数据库名2 ... > 数据库备份存储的文件路径
先创建一个数据库
接着在该数据库中创建两个表student、teacher,并插入一些数据


这时在命令行中执行如下命令即可将该数据库进行备份,并指定将备份后产生的文件存放在当前目录下:

back.sql文件即可看到,文件中的内容实际就是我们在该数据库中执行的各种SQL命令,包括创建数据库、创建表、插入数据等SQL语句
数据库恢复
使用如下命令即可对指定数据库进行恢复:
source 数据库备份的文件路径
删除数据库后,执行的代码:
![]()
此时就会恢复刚刚删除的数据库,且内容也与删除前完全一样
表的备份
mysqldump -P 端口号 -u 用户名 -p 密码 数据库名 表名1 表名2 ... > 表备份存储的文件路径
表的恢复
source 表备份的文件路径
表的备份与恢复类比上面的数据库的备份与恢复,使用方式是相同的
二、表的操作
DDL(数据定义语言):比如建表、删表、该表、新增列、删除列等
DML(数据操作语言):比如插入记录、删除记录、修改记录等
下面都是表的DDL操作
创建表
create table 表名(
列名1 类型1 [comment '注释信息'],
列名2 类型2 [comment '注释信息'],
列名3 类型3 [comment '注释信息']
);[charset=字符集] [collate=校验规则] [engine=存储引擎];comment表示对指定列添加注释信息
建表时没有指定使用哪种存储引擎,那么就会默认使用InnoDB存储引擎
查看表结构
desc 表名可以查看表的结构

①Field:表示该字段的名字
②Type:表示该字段的类型
③Null:表示该字段是否允许为空
④Key:表示索引类型,比如主键索引为PRI
⑤Default:表示该字段的默认值
⑥Extra:表示该字段的额外信息说明
show create table [表名]\G,可以查看创建表时的相关细节

修改表
新增列
alter table 表名 add 新增列名 新增列的属性;
修改列的属性
alter table 表名 modify 列名 修改后的列属性;
删除列
alter table 表名 drop 列名;
修改表名
alter table 表名 rename 新表名;
修改列名和属性
alter table 表名 change 列名 新列名 新列属性;
新增列如果想新增到哪一列之后,可以在后面加上 after 列名:
alter table student add name varchar(30) comment '姓名' after sex;
上述语句表示新增一列 name 列,并将 name 列放在 sex 列的后面
新增列后可能还需要对原来插入的记录进行修改,因为假设原有2条数据,此时新增一列,那么原有的2条数据中新增的那一列数据就默认为空
删除表
drop删除表结构会直接删除整个表,内存中就没有这个表了
delete删除只删除数据,不删除结构,delete完表还在,只是为空了
删除表结构
drop table [if exists] 表名;
删除表数据
delete from 表名;
删除部分数据
delete from 表名 where ...;三、表的增删查改
表的增删查改简称CRUD:Create(新增),Retrieve(查找),Update(修改),Delete(删除)
CRUD的操作对象是对表当中的数据,是典型的DML(Data Manipulation Language)数据操作语言
新增数据
insert into 表名 [列名] values [数据];新增数据时,如果在values前不加列名,就表示按照表中默认的列顺序进行全列插入
假设表的结构如下:

单行数据 + 全列插入
不加列名,全列插入
![]()
多行数据 + 指定列插入
用insert语句也可以一次向表中插入多条记录,插入的多条记录之间使用逗号隔开,并且插入记录时可以只指定某些列进行插入

插入否则更新
向表中插入记录时,如果待插入记录中的主键或唯一键已经存在,那么就会因为主键冲突或唯一键冲突导致插入失败
如果表中没有冲突数据,则直接插入数据
如果表中有冲突数据,则将表中的数据进行更新
insert into 表名 [列名] values [数据]
on duplicate key update [column1=value1, ...];column1=value1表示有冲突时,需要更新的列值
下图的含义就是:如果出现主键或唯一键冲突,则将表中冲突记录的学号和姓名进行更新
![]()
执行插入否则更新的SQL后,可以通过受影响的数据行数来判断本次数据的插入情况:
0 rows affected:表中有冲突数据,但冲突数据的值和指定更新的值相同
1 row affected:表中没有冲突数据,数据直接被插入
2 rows affected:表中有冲突数据,并且数据已经被更新
插入查询的结果
表示需要插入 select 出来的结果
insert [into] 表名 [列名] select ... [where...] [order by...] [limit...];删除表中重复的记录,重复的数据只能有一份
假设当前表数据如下:

要求删除测试表中重复的数据,思路如下:
①创建一张临时表,表的结构和数据与原表相同
②去重的方式查询并插入
③将原表改名,再将该表重命名为原表的名称,从而完成去重操作
步骤如下:
①创建临时表 no_duplicate 的时候可以借助like进行创建
![]()
②通过插入查询语句将去重查询后的结果插入到临时表中,临时表成功去重

③将原表改名,再将临时表改名为原表名称,完成去重操作
查找数据
select {*/列名/表达式} from 表名 [where] [order by] [limit];其中select后面是*就表示全列查询
如果是列名就对指定的列进行查询,多个列用逗号隔开
如果是表达式,表达式中可以包含多个表中已有的字段,例如列有数学、英语成绩,表达式就可以数学+英语成绩,从而计算出更多有意义的数据
后面的where、order by、limit都是可选项
{ }中的 / 代表可以选择其中某一条语句
全列查询
在查询数据时直接用*,表示进行全列查询,这时将会显示被筛选出来的记录的所有列信息:

指定列查询
查询数据时也可以只对指定的列进行查询,这时将需要查询的列在列表列出即可:
![]()
表示查找指定的 name 和 math 列
查询字段为表达式
我们也可以将表达式罗列到列表中:

此时就会多一个列,列名为1+1,每行数据都是1+1的值
这种方式可以帮助我们解决很多事情,例如如果有一个成绩表,我们想知道语文、数学和英语的总分表,此时就可以将 select 后面的表达式写成 chinese + math + english:
![]()
为查询结果指定别名
select 列名 [as] 别名 [, ...] from 表名;as可加可不加,也可以指定多个列的别名,在后面加逗号继续起别名即可
所以上面查询字段为表达式是,就可以将语数英的成绩综合改名为总分,此时表中的该列就名为总分:

结果去重
如果想要对查询结果进行去重操作,可以在SQL中的select后面带上distinct
select distinct 列名 from 表名;这种操作就用于查询的数据有重复值,我们想要将这些数据去重时的操作
where 条件
如果在查询数据时没有指定where子句,那么会直接将表中所有的记录作为数据源来依次执行select语句
如果在查询数据时指定了where子句,那么在查询数据时会先根据where子句筛选出符合条件的记录,然后将符合条件的记录作为数据源来依次执行select语句
where子句中可以指明一个或多个筛选条件,各个筛选条件之间用逻辑运算符and或or进行关联
下面是where子句中常用的逻辑运算符和比较运算符:
逻辑运算符:

比较运算符:
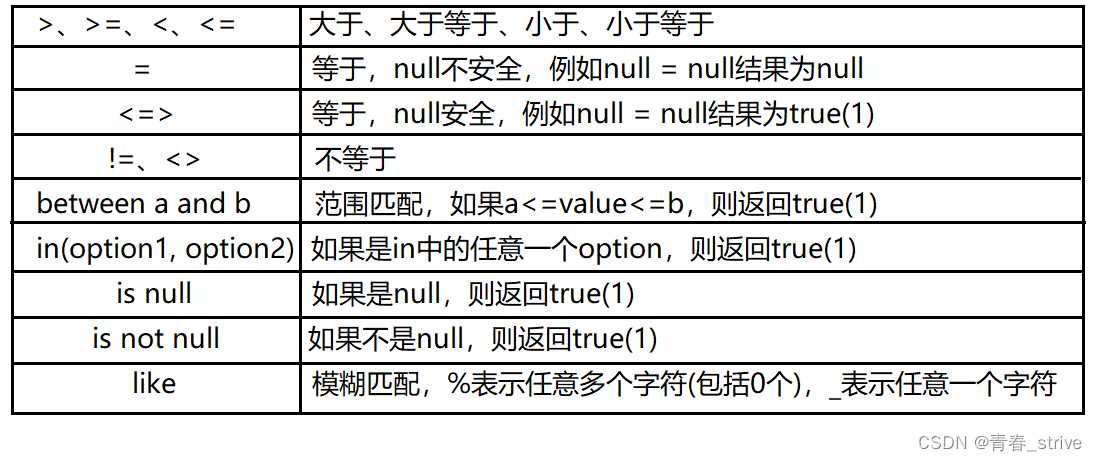
下面举几个使用 where 字句的样例:
①查询语文成绩在80到100分的同学及其语文成绩,下面这两种方式都可以
select name, chinese from exam_result where chinese between 80 and 100;
select name, chinese from exam_result where chinese >= 80 and chinese <= 100;②查询英语成绩是59或99分的同学及其英语成绩
select name, english from exam_result where english=59 or english=99;
select name, english from exam_result where english in (59,99);③查询姓王的同学/查询王某同学
查询姓王的同学
select name from exam_result where name like '王%';
查询王某同学
select name from exam_result where name like '王_';④NULL的查询
查询QQ号已知的同学/查询QQ号未知的同学
查询QQ号已知的同学
select name, qq from students where qq is not null;
查询QQ号未知的同学
select name, qq from students where qq<=>null;在与 null 值作比较的时候应该使用 <=> 运算符,使用 = 运算符无法得到正确的查询结果
⑤查询语文和数学总分大于180分的同学
select name, chinese+math 总分 from exam_result where chinese+math>180;需要注意的是,在where子句中不能使用select中指定的别名:
查询数据时是先根据where子句筛选出符合条件的记录
然后再将符合条件的记录作为数据源来依次执行select语句
所以在上面查询总分时,where后面不能写成 总分>180
结果排序
select {*/列名} from 表名 where order by 列名 [asc/desc];asc和desc分别代表的是排升序和排降序,不特殊指明就默认为 asc 排升序
注意:null值视为比任何值都小,因此排升序时出现在最上面
order by子句中可以指明按照多个字段进行排序,每个字段都可以指明按照升序或降序进行排序,各个字段之间使用逗号隔开,排序优先级与书写顺序相同
①查询同学的各门成绩,依次按数学降序、英语升序显示
select name, math, english from exam_result order by math desc, english asc;上述SQL中,当两条记录的数学成绩相同时就会按照英语成绩进行排序,如果这两条记录的英语成绩也相同就会继续按照语文成绩进行排序,以此类推
②查询同学及其总分,按总分降序显示
select name, chinese+math 总分 from exam_result order by chinese+math desc;
select name, chinese+math 总分 from exam_result order by 总分 desc;查询数据时是先根据where子句筛选出符合条件的记录
然后再将符合条件的记录作为数据源来依次执行select语句
最后再通过order by子句对select语句的执行结果进行排序
order by子句的执行是在select语句之后的,所以在order by子句中可以使用别名
所以上述SQL可以使用 总分 desc 这样的方式
③查询姓孙的同学或姓曹的同学及其数学成绩,按数学成绩降序显示
像这种长的题目,先完成查询,再进行排序
查询
select name, math from exam_result where name like '孙%' or name like '曹%';
排序
order by math desc;
查询和排序合并起来
select name, math from exam_result where name like '孙%' or name like '曹%'
order by math desc;筛选分页结果
从第0条记录开始,向后筛选出n条记录:
select {*/列名} from 表名 [where...] [order by] limit n;从第s条记录开始,向后筛选出n条记录:
select {*/列名} from 表名 [where...] [order by] limit n offset s;SQL中各语句的执行顺序为:where、select、order by、limit
limit子句在筛选记录时,记录的下标从0开始
如果从表中筛选出的记录不足n个,则筛选出几个就显示几个
按id进行分页,每页3条记录,分别显示第1、2、3页
第一页筛选3条记录(从0开始)
select * from exam_result limit 3 offset 0;
第二页筛选3条记录(从3开始)
select * from exam_result limit 3 offset 3;
第三页筛选3条记录(从6开始,不够就输出现有的数量)
select * from exam_result limit 3 offset 6;从表中筛选出的记录不足n个,则筛选出几个就显示几个
聚合函数查询
聚合函数可以在select语句中使用,此时select每处理一条记录时都会将对应的参数传递给这些聚合函数

使用*做统计
可以获取表中的记录个数
select count(*) from students;使用表达式做统计
在select语句中使用count函数,并将表达式作为参数传递给count函数,这时也可以统计出表中的记录条数
select count(1) from students;这种写法相当于下图,自行新增了一列列名为特定表达式的列,我们就是在用count函数统计该列中有多少个数据,等价于统计表中有多少条记录

统计班级收集的QQ号有多少个
select count(qq) from students;如果count函数的参数是一个确定的列名,那么count函数将会忽略该列中的NULL值
统计本次考试数学成绩的分数个数(去重)
select count(distinct math) from students;在count中加上 distinct 修饰能够完成去重的操作
统计平均总分
select avg(chinese+math) 平均总分 from exam_results;返回70分以上的英语最低分
结合where和聚合函数查询
select min(english) from exam_result where english>70;分组查询
select 列名 from 表名 [where...] group by 列名 [order by...] [limit...];查询SQL中各语句的执行顺序为:where、group by、select、order by、limit
group by后面的列名,表示按照指定列进行分组查询
显示每个部门的平均工资和最高工资
题目要求的是显示每个部门,所以就是按照部门分组查询
select deptno, avg(sal) 平均工资, max(sal) 最高工资 from emp group by deptno
显示每个部门的每种岗位的平均工资和最低工资
题目要求的是显示每个部门,所以就是按照部门和岗位分组查询
select deptno, avg(sal) 平均工资, min(sal) 最低工资 from emp group by deptno, job;
HAVING 条件
select ... from 表名 [where...] [group by...] [having...] [order by...] [limit...];SQL中各语句的执行顺序为:where、group by、select、having、order by、limit
having子句中可以指明一个或多个筛选条件
having子句和where子句的区别
①where子句放在表名后面,而having子句必须搭配group by子句使用,放在group by子句的后面
②where子句是对整表的数据进行筛选,having子句是对分组后的数据进行筛选
③where子句中不能使用聚合函数和别名,而having子句中可以使用聚合函数和别名
统计每个部门的平均工资
select deptno, avg(sal) 平均工资 from emp group by deptno; 显示平均工资低于2000的部门和它的平均工资
select deptno, avg(sal) 平均工资 from emp group by deptno having 平均工资<2000;修改数据
替换数据
如果表中没有冲突数据,则直接插入数据
如果表中有冲突数据,则先将表中的冲突数据删除,然后再插入数据
replace into 表名 [列名] values [数据];例如下图所示的语句,表达的含义就是如果出现冲突直接将冲突数据删除,再替换,如果没冲突,直接插入

执行替换数据的SQL后,也可以通过受影响的数据行数来判断本次数据的插入情况:
1 row affected:表中没有冲突数据,数据直接被插入
2 rows affected:表中有冲突数据,冲突数据被删除后重新插入
修改数据
update 表名 set 列名=数值 [...] [where...] [order by...] [limit...];在修改数据之前需要先找到待修改的记录,update语句中的where、order by和limit就是用来定位数据的
下面举例说明:
①将孙悟空同学的数学成绩修改为80分
update exam_result set math=80 where name='孙悟空';②将总成绩倒数前三的3位同学的数学成绩加上30分
update exam_result set math=math+30 order by chinese+math asc limit 3;③将所有同学的语文成绩修改为原来的2倍
update exam_result set chinese=chinese*2;删除数据
delete from 表名 [where...] [order by...] [limit...];在删除数据之前需要先找到待删除的记录,delete语句中的where、order by和limit就是用来定位数据的
①删除孙悟空同学的考试成绩
delete from exam_result where name='孙悟空';②删除整张表数据
delete from exam_result;假设表中有自增长的主键id,原本有三条数据,id分别是1,2,3,删除整张表数据后,再插入数据,不指明 id 是多少时,默认从4开始,这是有一个 AUTO_INCREMENT=n 的字段,表示下一次插入数据时自增长字段的值应该是 n
通过 show create table 表名 可以看到这个字段
截断表
truncate [table] 表名;①truncate只能对整表操作,不能像delete一样针对部分数据操作
②truncate实际上不对数据操作,所以比delete更快
③truncate在删除数据时不经过真正的事务,所以无法回滚
④truncate会重置AUTO_INCREMENT=n字段
使用截断表的操作时,删除完数据后,重新插入数据对应的自增长id值是重新从1开始增长
数据库的增删改查(CURD)操作到此结束