阅读时间:2023-12-26
1 介绍
年份:2019
作者:Johannes von Oswald,Google Research;Christian Henning,EthonAI AG;Benjamin F. Grewe,苏黎世联邦理工学院神经信息学研究所
期刊: 未发表
引用量:379
Von Oswald J, Henning C, Grewe B F, et al. Continual learning with hypernetworks[J]. arXiv preprint arXiv:1906.00695, 2019.
本文提出了任务条件的超网络(元模型网络)作为一种适用于持续学习的神经网络模型,它通过使用使用一个较小的超网络来生成目标网络的权重,然后再结合限制权重更新的正则化方法(如EWC、SI、MAS)来实现连续学习。超网络是基于任务身份来生成权重,在这种学习模式下,任务是顺序呈现的,目标是在学习新任务的同时,保留或提升在先前任务上的性能,同时利用已获得的知识。然后加上连续学习中权重更新的正则化技术,使得超网络在生成权重时能够保留之前任务的学习成果。实验结果表明,这种方法在压缩模式下,超网络能够有效地用相对较少的参数来生成一个更大的目标网络的参数,也能实现长期记忆的保持。论文还探讨了任务嵌入空间的结构,并展示了任务条件超网络能够展示迁移学习的能力。
2 创新点
- 任务条件超网络:提出了一种新型的超网络,它能够根据任务身份生成目标网络的权重,从而实现对不同任务的适应。
- 任务嵌入学习:任务嵌入作为可学习的参数,使得超网络能够为每个任务生成独特的权重配置,增强了模型对任务之间差异的适应性。
- 持续学习中的灾难性遗忘解决方案:可以通过加入正则化机制,有效地解决灾难性遗忘问题。
- 模型压缩:利用分块超网络实现了模型压缩,使得超网络的参数数量可以少于目标网络的参数数量,从而减少了存储和计算资源的需求。
- 上下文无关推理:提出了在任务身份未知的情况下进行推理的策略,包括基于预测不确定性的任务推断和使用生成模型进行合成数据重放。
3 算法步骤
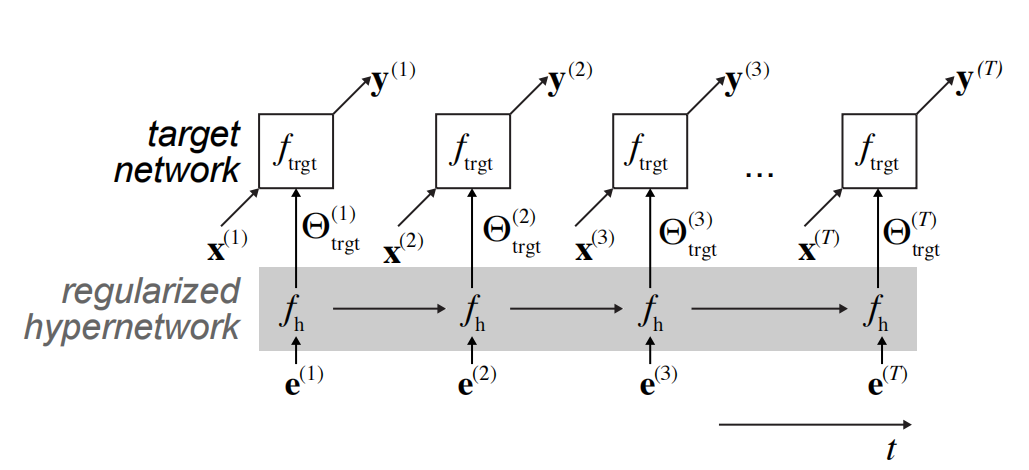
- 初始化超网络
- 超网络是一个元模型(metamodel),其参数为 Θ h \Theta_h Θh,用于生成目标网络的权重 Θ t r g t \Theta_{trgt} Θtrgt。
- 学习任务嵌入
- 对于每个任务,学习一个任务嵌入向量 e ( t ) e(t) e(t),该向量为超网络提供任务特定的上下文。
- 目标网络权重生成
- 使用超网络和任务嵌入向量,生成目标网络的权重配置 Θ t r g t = f h ( e , Θ h ) \Theta_{trgt} = f_h(e, \Theta_h) Θtrgt=fh(e,Θh)。
- 正向传播与任务学习
- 利用生成的权重 Θ t r g t \Theta_{trgt} Θtrgt和当前任务的数据 ( X ( t ) , Y ( t ) ) (X(t), Y(t)) (X(t),Y(t))进行正向传播,并通过反向传播更新超网络参数 Θ h \Theta_h Θh。
- 权重更新正则化
- 为了防止灾难性遗忘,使用一个正则化项来惩罚那些改变先前任务学习到的权重配置的参数更新。正则化项 L o u t p u t L_{output} Loutput确保了在训练新任务时,先前任务的权重配置 Θ h ∗ \Theta_h^* Θh∗保持稳定。
- 计算总损失
- 总损失 L t o t a l L_{total} Ltotal由当前任务的损失 L t a s k L_{task} Ltask和输出正则化项 L o u t p u t L_{output} Loutput组成。
- 更新超网络参数
- 使用优化算法(Adam)根据总损失 L t o t a l L_{total} Ltotal更新超网络的参数 Θ h \Theta_h Θh。
- 记忆保持
- 在学习新任务时,通过正则化项保持对先前任务的记忆,而不需要存储大量的数据。
- 任务条件超网络的压缩
- 通过分块(chunking)策略,超网络可以迭代地生成目标网络的一部分权重,从而实现模型压缩。
- 上下文无关推理
- 在某些情况下,任务身份在推理时可能不明确。本文提出了策略来推断任务身份,例如基于预测不确定性的方法或使用生成模型进行合成数据重放。
- 预测不确定性的方法:给定一个输入样本,网络需要推断它属于哪个任务。使用超网络为所有已知任务生成权重配置,并使用这些权重在目标网络上进行前向传播。对于每个任务,计算网络输出的熵(或不确定性),低熵意味着高确定性。选择预测不确定性最低的任务作为输入样本的任务标签。
- **任务推断网络:**训练一个辅助网络来预测输入样本的任务身份。使用超网络保护的合成数据和真实数据训练一个任务推断网络。根据任务推断网络的输出,选择相应的任务嵌入向量,并使用超网络生成目标网络的权重。
- 生成重放:重放方法不需要考虑任务身份,统一输入模型预测。首先使用超网络生成的参数训练一个生成模型,在训练新任务时,从生成模型中合成先前任务的数据。将合成数据与当前任务的真实数据混合,用于训练目标模型。可以使用额外的任务推断网络来确定输入样本的任务身份。
- 经验重放:重放方法不需要考虑任务身份,统一输入模型预测。在训练新任务时,将重放数据与当前任务的真实数据结合。在推理时,不依赖于任务上下文,直接使用训练过程中学到的权重进行前向传播。
4 实验分析
(1)不同方法的回归拟合表现
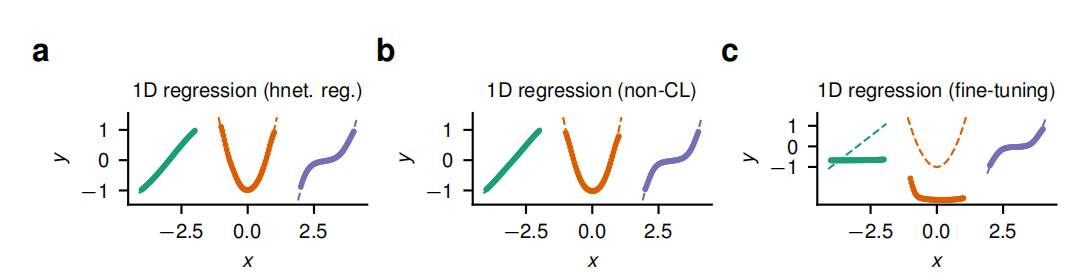
虚线表示真实函数,而标记点则展示了模型预测的结果。超网络能够顺序地学习一系列逐渐增加次数的多项式函数,并且能够很好地拟合每个任务的函数,即使在顺序学习的过程中也是如此。微调方法虽然在新任务上可能表现良好,但会牺牲对旧任务的记忆,导致先前任务的性能下降。
(2)Permuted MNIST基准测试上的实验结果
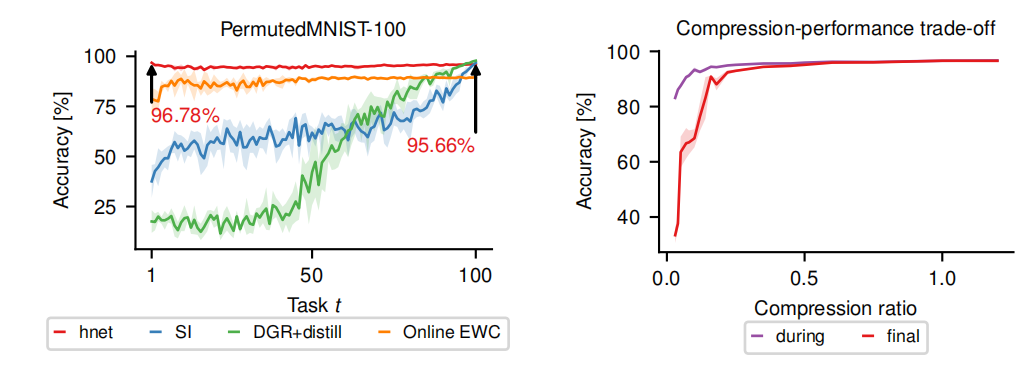
超网络在模型参数数量较少的情况下实现有效的持续学习,即使在压缩比低于1的情况下也能保持较高的准确率。
(4)Permuted MNIST和Split MNIST实验中不同持续学习方法的平均测试准确率
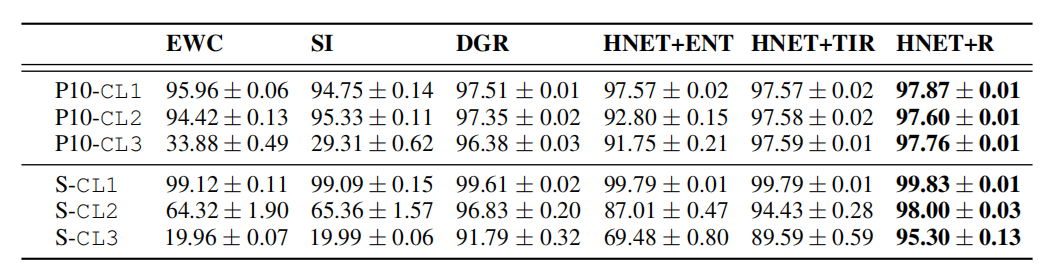
- EWC:在线弹性权重固化(online Elastic Weight Consolidation)。
- SI:突触智能(Synaptic Intelligence)。
- DGR:深度生成性重放(Deep Generative Replay),具体为DGR+distill。
- HNET+ENT:基于超网络的方法,使用预测分布的熵来推断任务身份(仅在CL1中使用HNET)。
- HNET+TIR:使用超网络保护的识别-重放网络(基于变分自编码器VAE)来从输入模式中推断任务。
- HNET+R:主分类器通过混合当前任务数据和由超网络保护的VAE生成的合成数据进行训练。
任务条件超网络(HNET)在持续学习环境中,尤其是在需要顺序学习并记忆多个任务的场景中,具有显著的性能优势。这些方法能够有效地解决灾难性遗忘问题,并在不同任务之间实现有效的知识迁移。
(5)Split MNIST基准测试中任务嵌入空间的二维可视化
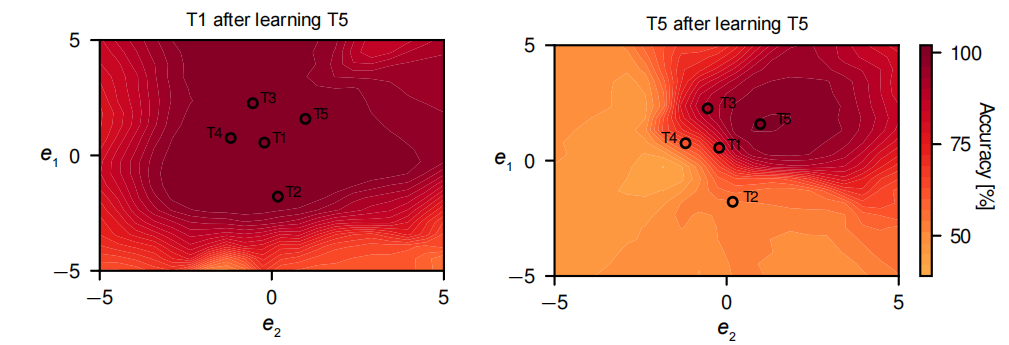
图a中在低维(二维)嵌入空间中,模型也能够实现高分类性能,并且几乎没有遗忘。
图b中最后一个任务占据了一个有限的高性能区域,当远离该嵌入向量时,性能逐渐下降,但下降是平滑的。这表明即使在有限的嵌入空间内,模型也能够为每个任务找到一个相对独立的区域,以保持其性能。
(4)持续学习基准测试
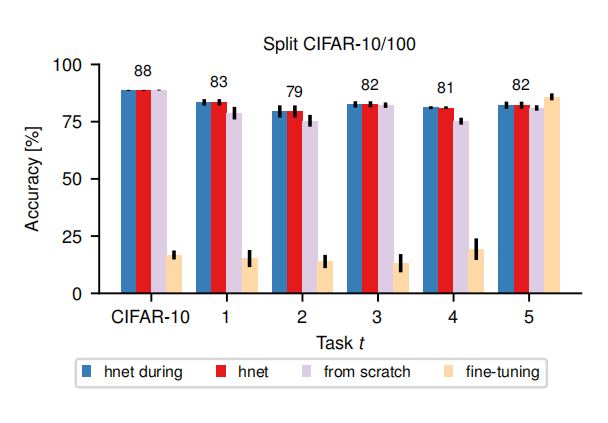
使用超网络保护的ResNet-32模型显示出几乎没有任何遗忘的现象。最终的平均性能(红色)与每个任务训练结束后立即测试的性能(蓝色)相匹配,这表明模型在学习新任务时能够保留对先前任务的记忆。从红色线高于紫色线看出,表明利用先前学习的知识比从头开始训练每个任务的性能更好。当禁用超网络的正则化项时(黄色),模型表现出强烈的遗忘现象。这表明正则化项在防止灾难性遗忘中起着关键作用。
5 思考
(1)使用分块超网络(Chunked Hypernetworks)的主要动机和优势是什么?
- 模型压缩:
- 在现代深度神经网络中,权重的数量通常非常庞大。分块超网络通过分批次生成目标网络的权重,可以减少所需的存储空间和计算资源。
- 参数效率:
- 分块超网络允许使用较少的参数来控制目标网络的权重,这使得模型更加参数高效,尤其是在资源受限的环境中。
- 灵活性:
- 分块超网络提供了一种灵活的方式来生成目标网络的权重,可以根据不同任务的需求调整生成的权重块。
- 任务特定权重生成:
- 通过为每个任务学习特定的任务嵌入向量,分块超网络可以生成适合特定任务的权重,从而提高任务的性能。
- 减少灾难性遗忘:
- 在持续学习场景中,分块超网络可以通过正则化技术保护先前任务的知识,减少在学习新任务时对旧任务知识的遗忘。
如果不使用分块超网络,可能会有以下影响:
- 存储需求增加:
- 需要存储整个目标网络的权重,这在权重数量庞大时会占用大量存储空间。
- 计算成本增加:
- 在训练和推理过程中,需要处理更多的参数,这会增加计算资源的消耗。
- 灾难性遗忘:
- 在持续学习环境中,如果不采取措施保护先前任务的知识,学习新任务时可能会遗忘旧任务的知识,导致性能下降。
- 泛化能力受限:
- 没有分块超网络的灵活性,可能难以为不同的任务生成最优的权重配置,从而影响模型在新任务上的泛化能力。
- 训练难度增加:
- 直接在目标网络上进行训练可能会使得模型更难收敛,尤其是在任务之间存在显著差异的情况下。
- 资源分配不均:
- 在没有模型压缩的情况下,可能无法有效地利用有限的计算和存储资源,导致资源分配不均。
(2)只有在分块的超网络结构中借鉴了PNN架构。