V1:https://blog.csdn.net/qq_51605551/article/details/140487051?spm=1001.2014.3001.5502
1.1 简介
EfficientNetV2是Google研究人员Mingxing Tan和Quoc V. Le等人在2021年提出的一种深度学习模型,它是EfficientNet系列的最新迭代,旨在提供更小的模型尺寸、更快的训练速度以及更高的计算效率,同时保持或提升模型的性能。EfficientNetV2通过一系列创新设计,在图像识别和其他视觉任务上取得了显著的性能提升,下面是对EfficientNetV2的详细介绍:
1. 背景与动机
EfficientNetV1的成功展示了通过复合缩放(compound scaling)策略,可以在不增加过多计算负担的情况下,显著提升模型性能。然而,随着模型复杂度的增加,训练时间和资源需求也相应增长。EfficientNetV2正是为了解决这一问题,目标是在保证高效率的同时,进一步提升模型的训练速度和参数效率。
2. 主要贡献
-
训练感知的神经架构搜索(Training-aware NAS):EfficientNetV2采用了一种新的神经架构搜索方法,该方法在搜索过程中直接考虑了模型的训练速度,而不只是最终的评估性能。这意味着搜索出来的模型不仅准确率高,而且训练起来更快。
-
Fused-MBConv结构:在EfficientNetV1中使用的MBConv(Mobile Inverted Residual Bottleneck)结构基础上,EfficientNetV2引入了Fused-MBConv。这种结构通过融合扩张卷积(expansion convolution)和深度可分离卷积(depthwise convolution),用一个标准的3x3卷积层替换,从而简化了网络结构,减少了计算成本,同时加速了训练过程。
-
更高效的缩放策略:EfficientNetV2不仅沿用了复合缩放的思想,还进一步优化了缩放策略,以适应新的Fused-MBConv结构,使得模型在不同规模下都能达到最佳的效率和性能平衡。
-
渐进式学习(Progressive Learning):这一策略允许模型从较小的规模开始训练,逐步过渡到更大规模的模型,有助于加速收敛并可能提升最终模型的性能。
3. 性能表现
EfficientNetV2在多个基准测试数据集上展示了卓越的性能,相比于EfficientNetV1和其他竞品模型,它能够在更短的时间内达到更高的准确率,同时保持模型的小巧。这表明其在资源有限的场景下特别有用,例如移动设备和嵌入式系统。
4. 局限性
尽管EfficientNetV2在许多方面取得了显著进步,但它的有效性和泛化能力仍受到训练数据集的限制。一些研究指出,为了更全面地验证其有效性,需要在更多样化的数据集上进行测试。
5. 应用领域
EfficientNetV2由于其高效性和高性能,被广泛应用于图像分类、物体检测、语义分割等计算机视觉任务,以及在医疗影像分析、自动驾驶、无人机导航等领域的实际应用中。
综上所述,EfficientNetV2是深度学习领域的一个重要进展,它通过一系列创新设计,在提高模型效率和训练速度的同时,保持了甚至提升了模型的准确性,为实际应用提供了更为强大的工具。

1.2 模型改进的问题
V1中存在的三个问题:

图像尺寸太大训练速度很慢
第一个问题:以V1-B6进行对比。V100是我们每块GPU每秒能够训练的图片的数量。
OOM是out of memory,内存溢出了。
batch size和trian size不同的情况下模型的训练速度对比。
我们可以发现,即使我们训练较小的图像尺寸,准确率还略微高一些。降低我们的图像尺寸,不仅能提高训练速度,还能增大我们的batch size尺寸。

浅层使用DW卷积速度很慢
从表格可以看出,浅层使用FuseMBConv是有V100速度提升的。但全部使用的话,参数量和计算量大幅上升。

Fused-MBConv(Fused Mobile Inverted Residual Bottleneck)结构是EfficientNetV2中引入的一种新型基础构建模块,旨在进一步优化模型的效率和训练速度。这一结构是基于EfficientNetV1中的MBConv模块发展而来的,但通过融合和简化原有组件,实现了更高效的计算和训练性能。以下是Fused-MBConv结构的详细解析:
MBConv vs. Fused-MBConv
-
MBConv结构:在EfficientNetV1中,MBConv模块由三个主要部分组成:扩张卷积(Expansion Convolution)、深度可分离卷积(Depthwise Convolution)、以及线性投影(Linear Projection)。首先,扩张卷积(通常是1x1卷积)用于增加通道数,然后是深度可分离卷积用于空间特征提取,最后是线性投影(又一个1x1卷积)用于减少通道数,通常伴有ReLU激活函数。
-
Fused-MBConv结构:在EfficientNetV2中,Fused-MBConv对上述流程进行了简化和融合。它将扩张卷积(如果有的话)和深度可分离卷积合二为一,使用一个标准的3x3卷积代替。这个单一的卷积层既负责通道扩张,又完成了空间特征的提取工作,因此减少了计算成本和模型复杂度。这种改动在模型的早期阶段(1-3阶段)尤其有效,能够显著提升训练速度,同时在参数和FLOPs(浮点运算次数)上的增加相对较小。
Fused-MBConv的优势
- 训练加速:通过减少计算步骤,Fused-MBConv能够加快模型前向和反向传播的速度,从而缩短训练时间。
- 资源效率:尽管Fused-MBConv在某些情况下可能会略微增加模型的参数量和计算量,但在模型的早期阶段,它能够以较小的资源开销实现更快的训练和推理。
- 性能保持:虽然进行了结构简化,但Fused-MBConv仍然能够维持或接近原始MBConv结构的性能水平,通过精心设计的架构搜索和缩放策略确保模型的有效性。
- 适应性增强:Fused-MBConv设计考虑到了现代硬件加速器的特性,如GPU和TPU,优化了计算密集型操作,使其更适合在这些平台上高效运行。
应用场景
Fused-MBConv主要被应用于模型的浅层,即网络的初始部分,因为在此阶段模型尺寸较小,简化结构带来的加速效果最为明显。随着网络深度增加,EfficientNetV2会逐渐回归使用更传统的MBConv模块,以保持模型的性能与效率之间的平衡。
总之,Fused-MBConv结构是EfficientNetV2在模型设计上的一个重要创新,它通过简化和融合关键的网络组件,实现了模型效率的大幅提升,特别是在模型训练阶段,这对于推动深度学习技术在资源受限环境下的应用具有重要意义。
同等的放大每个stage是次优的
V2的宽度和深度的缩放是非均匀的。(下图是V1)

V2做出的贡献
这里的提升11倍是V2的M和V1的B-7进行比较。
参数数量是V2与ResNet-Rs比较的。

1.3 V2的网络架构
mbconv后面的数字1,4,6代表升维的扩展因子expansion ratio,就是1x1卷积升维的倍数。
layers是重复堆叠的次数。channels对应是输出矩阵的channel。

对于Fused-MBconv模块,在源码的1-3stage中并没有SE注意力模块。
下图中,对于expansion=1的情况,主分支上只有3x3卷积,后面跟着BN和SiLu(就是swish)激活函数,然后dropout。对于expansion≠1的情况,3x3卷积后有一个1x1卷积。
注意:只有当输入输出channel相同时才有shortcut连接和dropout。

这里的dropout(V1也是这种dropout)和普通的dropout不一样,是stochastic depth。意思是网络从输入开始,经过网络的每一个block,每一个block都可以认为是一个残差结构,它的主分支上就是通过我们的f函数得到我们的输出,然后shortcut直接引入输入,然后这里会以一定的概率(这个概率是逐渐增大的)让“这一层block”失活,注意这里是将我们整个主分支上的输出进行丢弃。(这个dropout名称翻译过来就是随机深度)
因为只有输入输出channel相同时才有shortcut连接和dropout,所以不用担心通道数对不上的问题。
(这里的dropout仅指fused-mbconv以及mbconv层,不包括最后全连接前的dropout层)

Baseline
下图是V2中baseline的参数配置,下图中每个参数的含义看图:

V2-S
V2-S的参数(V2-S不是baseline,而是改进来的):
那行注释意思是在bseline基础上宽度(卷积核个数,详细去看V1的博客,下同)缩放1.4倍,深度(layer)缩放1.8倍。具体咋缩放的我们也不知道,我们知道结果就行。
下面就是缩放后的结果:

V2-M
V2-M的参数:(M比S多了一个stage,在最后一行)

其他训练参数

1.4 渐进式学习策略
EfficientNetV2中的渐进学习(Progressive Learning)是一种训练策略,旨在通过分阶段逐步增加模型的复杂度来加速训练过程并提高模型的最终性能。这一策略利用了模型在学习过程中的动态特性,通过逐步引入更复杂的特征表示和更深层次的网络结构,来优化训练效率和性能。以下是关于EfficientNetV2中渐进学习策略的详细解析:
核心思想
渐进学习的核心在于“逐步深化”,即从一个较小、较简单的模型开始训练,随着训练的进行,逐步增加模型的规模或者复杂度。这样做有几个好处:
- 加速初期收敛:小模型通常训练速度快,更容易收敛,可以快速捕捉到基本的特征和模式,为后续训练打下良好基础。
- 避免过早饱和:在训练的早期阶段,简单模型不容易陷入局部最优解,有利于探索更广阔的解空间。
- 资源高效:随着模型逐渐增大,已有的训练成果可以被继承,减少了从头训练大型模型所需的资源和时间。
- 性能提升:逐步增加模型复杂度可以逐步精细调整模型,从而在保持训练效率的同时,提升模型的最终性能。
实现方式
在EfficientNetV2中,渐进学习策略可能涉及以下方面:
- 分阶段训练:模型从一个小规模版本开始,完成初步训练后,增加网络的深度或宽度,或者引入更复杂的模块,然后继续训练。
- 动态图像尺寸:随着模型规模的增长,逐步增加输入图像的分辨率。这是因为较大的模型通常能更好地利用高分辨率图像中的细节信息。
- 适应性学习率:随着训练的深入,逐步降低学习率,以帮助模型在训练后期更精细地调整权重。
- 预训练与微调:在更大的数据集(如ImageNet21K)上预训练模型,然后在目标数据集(如ImageNet)上进行微调,这也是一种形式的渐进学习,先学习通用特征,再专注于特定任务。
效果与优势
- 更快的收敛速度:通过从小规模模型开始,EfficientNetV2能够迅速进入有意义的学习状态,进而加速整个训练过程。
- 更高的最终性能:渐进学习策略帮助模型在不同阶段逐步优化,最终达到更高的准确率和更好的泛化能力。
- 资源节约:与直接训练大型模型相比,分阶段训练可以更有效地利用计算资源,尤其是在硬件资源有限的情况下。
注意事项
尽管渐进学习带来了诸多优势,但其实施也面临着挑战,如如何平滑地从一个阶段过渡到下一个阶段,避免训练过程中的性能波动,以及如何优化不同阶段间的超参数选择等。因此,设计合理的训练策略和监控机制对于实现高效渐进学习至关重要。
使用不同的rand Aug等级的时候,会发现在size=128时,magnitude=5准确率最高,size=300时magnitude=15准确率最高。那么作者就在想是不是我们在使用不同的size的时候正则化的强度是不是也要进行一个相应的调整呢?

在一开始epoch=1,图像的尺寸较小,正则化方法也比较弱。随后逐渐增强。

具体的正则化强度是如何随着图像尺寸变化的策略:

下表给出了EfficientNetV2(S,M,L)三个模型的渐进学习策略参数:

为了证明这个渐进式学习策略是有效的,作者又将这个策略应用到了resnet和V1上:

1.5 模型性能



附
Stochastic Depth
Stochastic Depth是EfficientNetV2中采用的一种正则化技术,最初在论文《Deep Networks with Stochastic Depth》中提出,旨在提高深度神经网络的训练效率和泛化能力。这一技术在残差网络(ResNet)类架构中特别有效,包括EfficientNet系列中的模型。下面是关于EfficientNetV2中Stochastic Depth的详细解析:
基本概念
Stochastic Depth的基本思想是,在训练过程中以一定的概率随机丢弃(或“dropout”)网络中的某些残差块(Residual Block)的主路径输出,仅保留该块的快捷连接(Identity Connection或Shortcut Connection)的输出。这意味着,对于每个训练样本,网络的深度在每次前向传播时都是随机变化的。与传统的Dropout技术(随机失活神经元)不同,Stochastic Depth是作用在模型的结构层面,而非单个神经元。
工作原理
-
随机丢弃:对于每个残差块,设置一个丢弃概率 𝑝p,在训练时以概率 𝑝p 随机丢弃该块的主分支输出,只保留输入信号通过快捷连接直接传递到下一层。丢弃操作在整个训练过程中动态进行,每个块的丢弃是独立的。
-
动态网络深度:由于每个残差块都有可能被丢弃,实际上网络的深度在每次训练迭代中是随机变化的。这模拟了一个由浅到深的集成模型集合,每个模型具有不同的深度。
-
训练与推理的差异:在训练阶段应用Stochastic Depth,而在推理(测试)阶段,所有残差块都参与计算,但为了保持训练和测试行为的一致性,通常会按照训练时的期望深度调整残差块的权重。具体来说,每个残差块的输出在推理时会乘以 1−𝑝1−p(即保留概率),以补偿训练时的丢弃操作。
目标与优势
- 减轻过拟合:通过随机丢弃网络的一部分,Stochastic Depth增加了模型的多样性,有助于减少过拟合,提高泛化性能。
- 加速训练:丢弃部分网络可以减少计算量,尤其是在使用大规模数据集和深层网络时,有助于加速训练过程。
- 结构正则化:作为一种结构化的dropout形式,Stochastic Depth提供了额外的正则化手段,帮助模型学习更加鲁棒的特征表示。
- 模型压缩启发:通过观察哪些路径经常被丢弃,可以为模型剪枝提供线索,进一步压缩模型大小。
在EfficientNetV2中的应用
EfficientNetV2利用Stochastic Depth来优化其残差结构,尤其是那些包含shortcut连接的MBConv或Fused-MBConv模块。通过在训练期间随机丢弃部分网络块,模型能够以更少的计算成本探索更广泛的网络配置,进而提升效率和性能,同时保持模型在实际应用中的紧凑性和高效性。
RandAugment
RandAugment是一种自动化数据增强方法,它通过简化和自动化图像数据增强的参数选择过程,提高了机器学习和深度学习模型在计算机视觉任务中的训练效率和泛化能力。这种方法由Lukas Geiger等人在2020年提出,目的是减少传统数据增强方法中广泛存在的大量超参数调优需求,同时保持数据增强的多样性和有效性。
核心特点:
-
减少搜索空间:与之前的数据增强方法相比,RandAugment显著减小了参数搜索空间。它不需要对每个增强操作的强度和应用概率进行精细调整,而是通过两个超参数(N和M)来控制增强策略的整体强度和多样性。N代表从一组预定义的增强操作中选择的变换数量,而M是一个乘数,用来调节这些变换的强度。
-
无参数过程:为减少参数空间并保持图像多样性,RandAugment使用无参数过程替代了先前方法中的学习策略和概率选择。这意味着每次变换都是以均匀概率从N个预设的变换中选取的,并且所有变换都应用相同的强度M。
-
自动化和即插即用:由于其简化的参数设计,RandAugment可以直接应用于各种模型和数据集,无需为每项任务或数据集单独调整复杂的增强策略。这使得它成为一种即插即用的解决方案,易于集成到现有的训练流程中。
-
性能表现:在多个标准数据集(如CIFAR-10/100、SVHN和ImageNet)上,RandAugment展现出了与更复杂、搜索空间更大的数据增强方法相媲美或超越的性能。特别是在ImageNet上,它达到了85.0%的准确率,相比之前的最佳方法提高了0.6%,比标准增强技术高出1.0%。
-
泛用性:RandAugment不仅适用于图像分类任务,还被证明在目标检测等其他视觉任务上同样有效,能够提升模型性能,且在保持高效性的同时,减少了数据预处理的复杂性。
综上所述,RandAugment通过其简化的参数设计和自动化的增强策略,为数据增强提供了一种高效且实用的方法,有助于提升模型的训练效率和最终的预测性能。
RandAugment 应用实例:
假设你正在训练一个图像分类器,目标是识别不同类型的花卉。你的原始数据集包含了各种花卉的图片,每张图片都有一个对应的类别标签(例如,玫瑰、郁金香、百合等)。
-
定义 RandAugment 参数:首先,你需要设置 RandAugment 的两个关键超参数:
N和M。N表示从一组预定义的图像变换中选择的变换数量,而M控制这些变换应用的强度。例如,你可以设置N=2(每次数据增强从8种基础变换中随机选择2种)和M=10(变换强度范围为0到10的值)。 -
实施数据增强:对于数据集中的每张图片,算法会随机选择
N个变换(比如旋转和色彩抖动),并且为每个选定的变换独立地从[0, M]范围内抽取一个强度值。然后,按照这些参数对图像进行变换。例如,一张玫瑰花的图片可能会被随机旋转一个轻微的角度(比如5度)并增加一点色彩饱和度(强度系数为7)。 -
训练过程:经过 RandAugment 处理后的图像,连同其原始标签,被送入神经网络模型进行训练。由于每次迭代时增强方式都是随机的,这大大增加了模型看到的图像变化,促进了模型学习到更鲁棒的特征。
-
模型评估与优化:在训练过程中,通过验证集来监控模型性能,确保数据增强不仅增加了训练集的多样性,而且确实提高了模型在未见过数据上的分类准确性。
通过这种自动化且随机的过程,RandAugment 减少了手动设计数据增强策略的需要,同时在实践中已被证明能有效提升图像分类任务的性能。
Mixup
Mixup是一种创新的数据增强技术,由Hongyi Zhang等人在2017年的论文《mixup: Beyond Empirical Risk Minimization》中提出,并在ICLR 2018会议上发表。这项技术旨在通过创建训练样本的线性组合来提高机器学习模型的泛化能力,特别是深度学习模型。Mixup不仅限于图像数据,还适用于文本、语音等多种类型的数据。下面是mixup技术的详细解析:
基本原理
Mixup的核心思想是通过在训练过程中引入数据的线性插值,来生成“虚构”的训练样本,以此来平滑决策边界,减少过拟合,并促使模型学习更加鲁棒的特征表示。具体操作如下:
优势
实现细节
总之,mixup是一种简单而强大的技术,通过数据的创造性混合,有效促进了模型的泛化性能和鲁棒性。
例子:

通过在训练循环中反复执行这样的混合操作,模型学会了对输入数据进行更稳健的泛化,降低了过拟合的风险,并可能提高对对抗性攻击的抵抗力。
-
样本混合:对于数据集中的任意两个样本(𝑥𝑖,𝑦𝑖)和(𝑥𝑗,𝑦𝑗),首先随机抽取一个权重系数𝜆,通常𝜆∼𝐵𝑒𝑡𝑎(𝛼,𝛼),其中𝛼α是一个超参数,决定了𝜆的分布形状。然后,根据𝜆λ计算新样本的输入特征和标签:
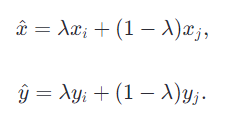
-
当应用于多分类问题时,标签𝑦𝑖和𝑦𝑗通常是one-hot编码,因此上述公式中的加法变成了对应位置的数值相加。
-
损失函数调整:使用交叉熵损失函数时,也需要相应地调整,以适应混合后的标签𝑦^。模型对混合样本𝑥^的预测𝑝^与混合标签𝑦^计算损失,这有助于模型学习到不同类别间的平滑过渡。
- 减少过拟合:通过引入数据的线性组合,模型被迫学习更为平滑的决策边界,这有助于减轻过拟合现象。
- 提高泛化能力:由于模型在训练时看到了更多样化但仍然合理的数据,这能增强其在未见过的数据上的表现。
- 对抗样本防御:Mixup通过鼓励模型在样本间进行平滑的预测,增强了模型对小扰动的鲁棒性,从而在一定程度上提升了对抗攻击的防御能力。
- 超参数选择:𝛼α的值决定了𝜆的分布,较大的𝛼倾向于生成更接近原始数据点的样本,而较小的𝛼则会产生更广泛的插值样本。
- 适用范围:尽管mixup最初针对图像分类任务,但后来被广泛应用于自然语言处理、语音识别等领域,只要数据可以线性插值,理论上都可应用此方法。
- 变种与拓展:随着研究的深入,mixup出现了多种变体,如CutMix、Manifold Mixup、PatchUp等,每种变体都有其特定的增强策略和应用场景,进一步丰富了数据增强的工具箱。














![[GXYCTF2019]Ping Ping Ping1](https://i-blog.csdnimg.cn/direct/ba497813864f4a318a5f65f9395636b0.png)