数据安全重要性
发散问题,大家最近有没有因隐私或者敏感数据泄露而产生的问题以及烦恼?
生活中,手机、身份证、社保账号等泄露引发的困扰
工作中....
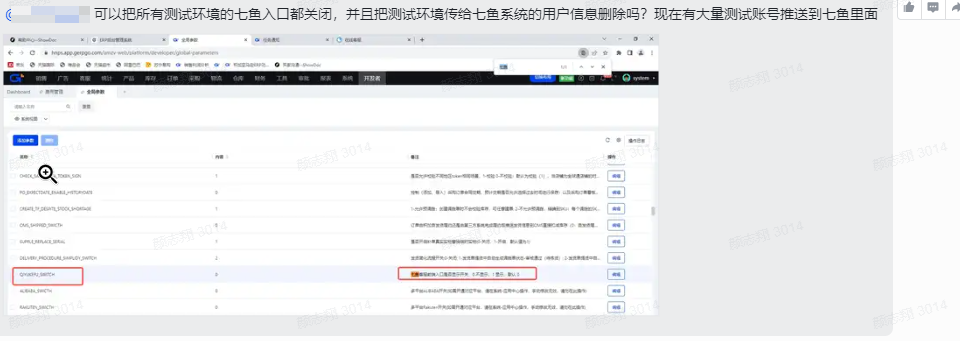
之前测试环境发送邮件给客户的用户等
1、什么是数据脱敏
定义:数据脱敏是指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。在涉及客户安全数据或者一些商业性敏感数据的情况下,在不违反系统规则条件下,对真实数据进行改造并提供测试使用,如手机号、卡号、客户号等个人信息都需要进行数据脱敏。
数据脱敏生活中常见,例如:
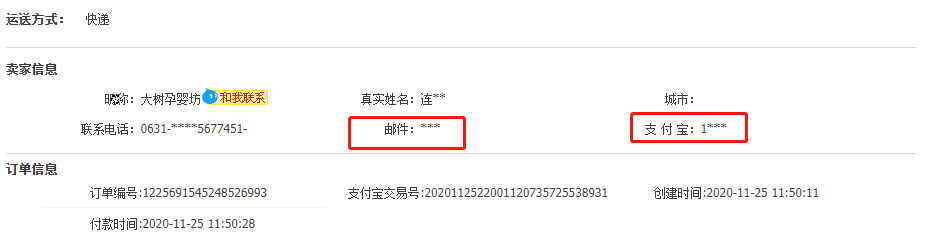
数据脱敏分类:静态数据脱敏和动态数据脱敏
1.1 静态数据脱敏
静态数据脱敏一般应用于数据外发场景,导出的数据是以脱敏后的形式存储于外部存贮介质中,实际上已经改变了存储的数据内容。原理是将数据抽取进行脱敏处理后,下发至脱敏库。开发、测试、培训、分析人员可以随意取用脱敏数据,并进行读写操作,脱敏后的数据与生产环境隔离,满足业务需要的同时保障生产数据的安全,例如需要将生产数据导出发送给开发人员、测试人员、分析人员等;概括为数据的“搬移并仿真替换”
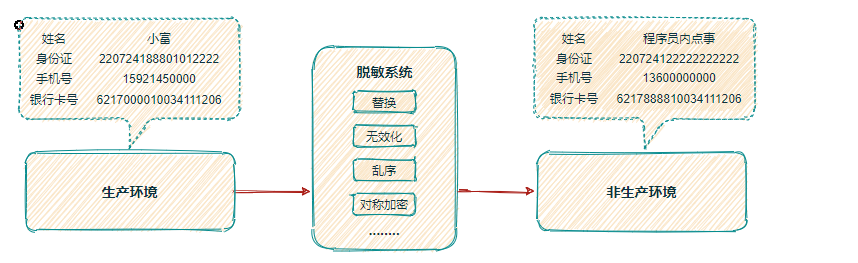
1.2 动态数据脱敏
动态数据脱敏:一般用在生产环境,访问敏感数据时实时进行脱敏,原理是将生产库返回的数据进行实时脱敏处理,例如:应用需要呈现部分数据,但是又不希望应用账号可以看到全部数据;运维人员需要维护数据,但又不希望运维人员可以检索或导出真实数据。系统生产环境的日志敏感词以及社交网站中污辱、谩骂、诋毁等辱骂内容做的处理。动态脱敏可以概括为“边脱敏,边使用”

1.3 数据脱敏必要性
《网络安全法》第四十二条:网络运营者不得泄露、篡改、毁损其收集的个人信息;未经被收集者同意,不得向他人提供个人信息。但是,经过处理无法识别特定个人且不能复原的除外。
《数据安全法》第二十七条:开展数据处理活动应当依照法律、法规的规定,建立健全全流程数据安全管理制度,采取相应的技术措施和其他必要措施,保障数据安全。
《个人信息保护法》第五十一条:个人信息处理者应当根据个人信息的处理目的、处理方式、个人信息的种类以及对个人权益的影响、可能存在的安全风险等,采取相应的加密、去标识化等安全技术措施。
《信息安全技术 网络安全等级保护基本要求》明确规定,二级以上保护则需要对敏感数据进行脱敏处理。其中H.4.3 安全计算环境要求“大数据平台应提供静态脱敏和去标识化的工具或服务组件技术。”H.4.5 安全运维管理 “应在数据分类分级的基础上,划分重要数字资产范围,明确重要数据进行自动脱敏或去标识使用场景和业务处理流程。
等等。。。。
1.4 数据脱敏的原则
防逆向破解原则: 无论采用哪种脱敏方法,都不能够通过破解方法获取到原始敏感数据。
表征原始数据原则: 脱敏后数据要保持一定的真实性以便数据能够应用开发、测试、分析的环境。 例如对姓名处理,脱敏后形式类似王*凯,而不能采用随意的值来替换姓名。
引用完整性原则: 经过脱敏后数据要保持引用完整性,例如对银行卡号进行脱敏处理(银行卡号是一个主键)所有引用了银行卡号信息的实体,经过脱敏处理后要能够关联到一起
1.5 常见的数据脱敏方案
常用方法如下:
- 字符串替换:将需要脱敏的字符串中指定位置的字符替换为“*”或其他符号。例如,将银行卡号的前12位用“*”代替。
- 掩码算法:类似于字符串替换,但是可以保留部分关键信息。例如,将手机号码中间四位用“****”代替。
- 加密算法:使用加密算法对需要脱敏的数据进行加密,并在存储和传输时保持加密状态。例如,可以使用AES、DES等加密算法对数据库中的敏感信息进行加密保存。
- 哈希算法:使用哈希算法对需要脱敏的数据进行计算,生成一段固定长度的哈希值代表原始数据。例如,可以使用MD5或SHA-256等哈希算法对用户密码进行脱敏处理。
- 数据库脱敏:使用数据库自带的脱敏函数(如MySQL的MD5函数)或第三方的脱敏插件(如Data Masker for MySQL)
- 人工审核:对于某些无法通过自动脱敏实现的敏感信息,可以通过人工审核方式来保护数据安全。微信小程序审核、税务数据审核、app上架审核等
综上所述,数据脱敏实现方案根据实际需求和安全要求,可以选择合适的方案来保护敏感数据。无论是静态脱敏还是动态脱敏,其最终都是为了防止组织内部对隐私数据的滥用。
2、敏感词过滤
敏感词过滤就是检查用户输入的内容有没有敏感词,检查之后做相应的处理,如直接阻止信息保存,接口返回错误信息或者把敏感词替换为*** 等
不管怎么处理,前提都得找到是否包含敏感词。要判断用户输入有无敏感词,首先要知道哪些词语是敏感词,也就是得有个敏感词库。
比如现在敏感词库里记录了两个敏感词:“a”和“b”,如何判断用户输入的内容里是否包含这两个敏感词呢?
最容易想到的方法是遍历敏感词库,依次判断输入内容是否有“a”和“b”。但是真实的敏感词库里存放的敏感词是非常多的,这时候遍历敏感词库的性能比较低,而且大部分情况下用户输入的内容都是不包含敏感词的,这时需要完全遍历敏感词库,也就是说大部分情况下遇到的都是这个算法复杂度最高的情形。因此敏感词过滤算法的性能很重要。
常用的敏感词过滤算法
2.1 双数组
分别存储脏字符以及敏感词库
存储结构定义:
public class DatCacheNode {
/**
* 脏字库
*/
private Set<Character> chars = Sets.newHashSet();
/**
* 敏感词库
*/
private Set<String> words = Sets.newHashSet();
}2.2 hash桶
二级hash(hash bucket)主要是通过hashmap来存储敏感词值。
存储结构定义:Map<Character, Map<Integer, Set<String>>>
2.3 Trie树算法
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
示例:一棵Trie树,表示关键字集合 {"abject"、"ablaze"、"able"、"abound"、"about"、"accent"、"accept"、"best"、"bestow"、"bet".....}

核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
实际上Trie 树不适合精确匹配查找,这种问题更适合用散列表或者红黑树来解决。Trie 树比较适合的是查找前缀匹配的字符串。
示例:
(1)存储结构定义:
public class TireTreeNode {
/**
* 节点值
*/
private char value;
/**
* 是否为一个单词
*/
private boolean word;
/**
* 子节点
*/
private List<TireTreeNode> children;
}(2)添加敏感词
逻辑: 对于要插入的一个字符串,遍历字符串的各个字符所对应的树中的节点分支向下走,直到字符串遍历完,将最后的节点标记,表示该单词已插入trie树。
public boolean put(String word) throws RuntimeException {
if (StringUtils.isBlank(word)) {
return false;
}
char firstChar = word.charAt(0);
TireTreeNode node = cacheNodes.find(firstChar);
if (node == null) {
node = new TireTreeNode(firstChar);
cacheNodes.addChild(node);
}
for (int i = 1; i < word.length(); i++) {
// 转换成char型
char nextChar = word.charAt(i);
TireTreeNode nextNode = null;
if (!node.isLeaf()) {
nextNode = node.find(nextChar);
}
if (nextNode == null) {
nextNode = new TireTreeNode(nextChar);
}
node.addChild(nextNode);
node = nextNode;
if (i == word.length() - 1) {
node.setWord(true);
}
}
return true;
}(3) 敏感词匹配
逻辑: 即从根开始按照字符串的字符顺序向下遍历trie树,一旦发现某个节点标记不存在或者单词遍历完成而最后的节点未标记,则表示该单词不存在,若最后的节点标记,表示该单词存在
/**
* 判断一段文字包含敏感词语
*
* @param partialMatching 是否支持匹配词语的一部分
* @param content 被匹配内容
* @return 是否匹配到的词语
*/
public boolean processor(boolean partialMatching, String content, Callback callback) {
if (StringUtils.isBlank(content)) {
return false;
}
//遍历字符匹配给与的内容中的敏感词
for (int index = 0; index < content.length(); index++) {
char firstChar = content.charAt(index);
TireTreeNode node = cacheNodes.find(firstChar);
if (node == null || node.isLeaf()) {
continue;
}
//遍历的字符个数
int charCount = 1;
for (int i = index + 1; i < content.length(); i++) {
char wordChar = content.charAt(i);
node = node.find(wordChar);
if (node == null) {
break;
}
charCount++;
//部分匹配,并且是敏感词
if ( partialMatching && node.isWord()) {
if (callback.call(StringUtils.substring(content, index, index + charCount))) {
return true;
}
break;
//是敏感词
} else if (node.isWord()) {
if (callback.call(StringUtils.substring(content, index, index + charCount))) {
return true;
}
}
//叶子节点则结束
if (node.isLeaf()) {
break;
}
}
if ( partialMatching) {
index += charCount;
}
}
return false;
}2.4 dfa算法
想法:trie tree查找字符,如果失败则需要回溯到前面节点进行循环查找,如果能解决这个回溯的问题,性能是否会更好?
例如使用上文生成的tried tree进行匹配【abestp】

DFA(Deterministic Finite Automata)即确定有穷自动机,与之对应的是 NFA(Non-Deterministic Finite Automata,不确定有穷自动机)。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA中不会有从同一状态出发的两条边标志有相同的符号。
简单点说就是,它是是通过event和当前的state得到下一个state,即event+state=nextstate。理解为系统中有多个节点,通过传递进入的event,来确定走哪个路由至另一个节点,而节点是有限的
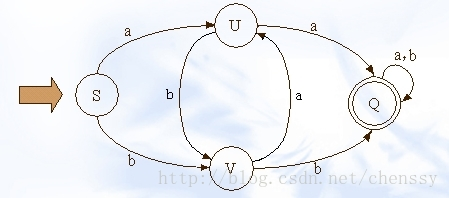
在这幅图中大写字母(S、U、V、Q)都是状态,小写字母a、b为动作。
存储结构定义:
public class DfaNode {
private char value;
private boolean word;
private Map<Character, DfaNode> children;
}插入逻辑与Trie树差不多,具体看附件示例代码。
2.5 过滤算法性能对比
词库:约2700
| 算法 | 过滤字符数 | 查询耗时 |
| 双数组 | 2507/2567168/82149376 | 31.45ms/46.21 ms/1.732 s |
| hash桶 | 2507/2567168/82149376 | 592.7 μs/34.92 ms/1.473 s |
| dfa算法 | 2507/2567168/82149376) | 305.5 μs/26.95 ms/673.8 ms |
| trie树算法 | 2507/2567168/82149376 | 608.5 μs/350.8 ms/10.98 s |
代码附件:
见博客资源 亲!
3. 扩展
hutool-dfa:https://www.jianshu.com/p/c511a448609e
敏感词自动过滤管理系统:
📎CN101964000B.pdf
网络游戏中敏感词过滤方法及系统:
📎CN103714160A.pdf