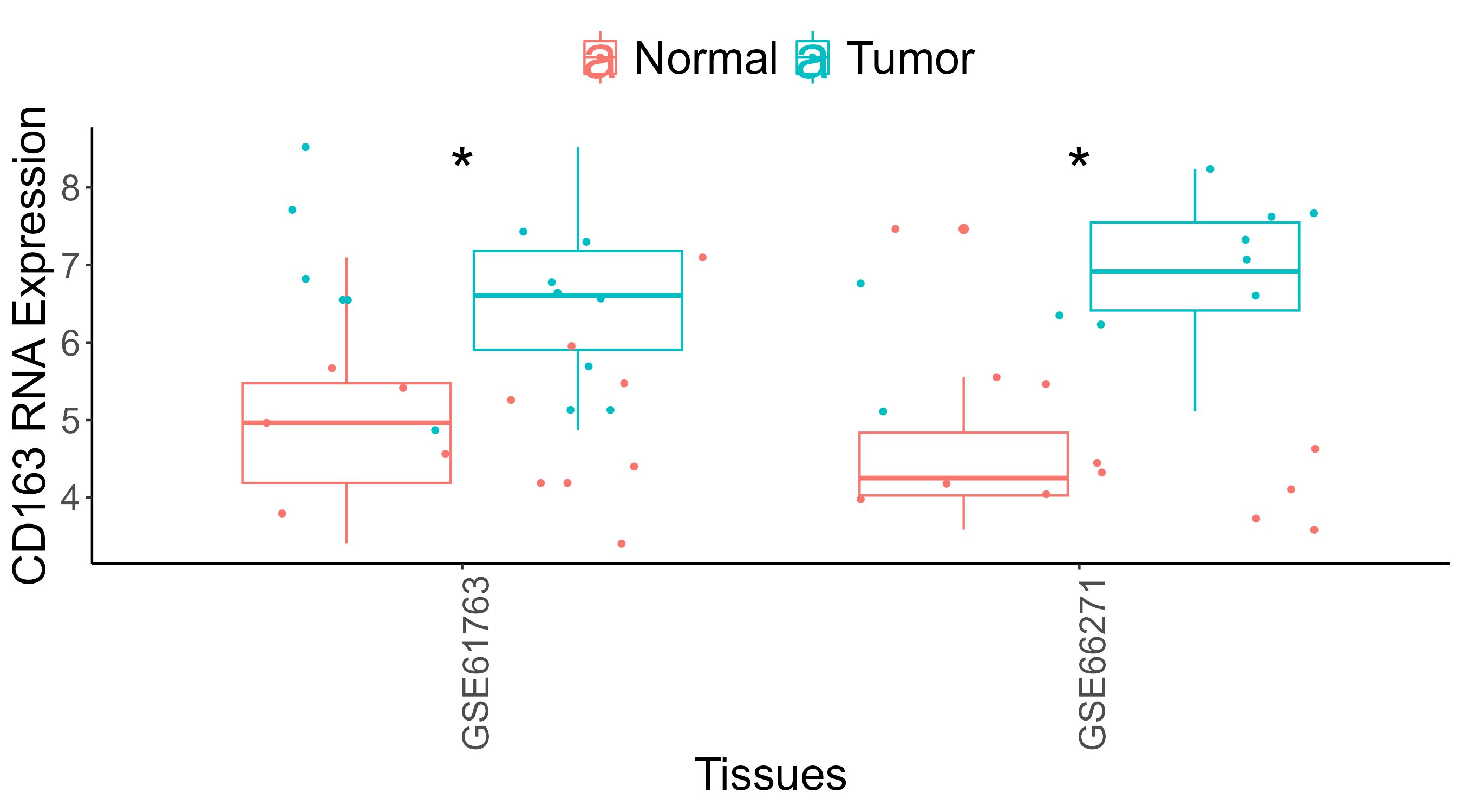
列表推导式(List Comprehensions)是 Python 中一种简洁且强大的创建列表的方式。通过使用列表推导式,可以用一行代码来生成列表,而不是通过多行代码的循环或其他方法。
一、列表推导式的基本语法
列表推导式的基本语法如下:
[expression for item in iterable if condition]
expression: 每次迭代时计算的表达式,可以是任意合法的 Python 表达式。item: 当前迭代的元素。iterable: 任何可迭代的对象,例如列表、元组、字符串等。condition: 可选的条件表达式,只有当条件为 True 时,才会将expression计算的结果添加到列表中。
1.1 基本示例
将一个列表中的每个元素乘以 2:
numbers = [1, 2, 3, 4, 5]
doubled = [x * 2 for x in numbers]
print(doubled) # 输出: [2, 4, 6, 8, 10]
1.2 带条件的列表推导式
仅保留偶数并将其平方:
numbers = [1, 2, 3, 4, 5]
squared_evens = [x ** 2 for x in numbers if x % 2 == 0]
print(squared_evens) # 输出: [4, 16]
二、嵌套列表推导式
列表推导式可以嵌套,用于处理多维列表(如矩阵)或生成笛卡尔积。
2.1 处理多维列表
将一个二维列表(矩阵)展平为一维列表:
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
flattened = [num for row in matrix for num in row]
print(flattened) # 输出: [1, 2, 3, 4, 5, 6, 7, 8, 9]
2.2 生成笛卡尔积
生成两个列表的笛卡尔积:
colors = ['red', 'green', 'blue']
sizes = ['S', 'M', 'L']
cartesian_product = [(color, size) for color in colors for size in sizes]
print(cartesian_product)
# 输出: [('red', 'S'), ('red', 'M'), ('red', 'L'), ('green', 'S'), ('green', 'M'), ('green', 'L'), ('blue', 'S'), ('blue', 'M'), ('blue', 'L')]
三、列表推导式的高级用法
3.1 使用函数和复杂表达式
在列表推导式中使用函数和更复杂的表达式:
def square(x):
return x * x
numbers = [1, 2, 3, 4, 5]
squared_numbers = [square(x) for x in numbers]
print(squared_numbers) # 输出: [1, 4, 9, 16, 25]
3.2 条件表达式(if-else)
在列表推导式中使用条件表达式:
numbers = [1, 2, 3, 4, 5]
parity = ['even' if x % 2 == 0 else 'odd' for x in numbers]
print(parity) # 输出: ['odd', 'even', 'odd', 'even', 'odd']
四、列表推导式的性能优化
列表推导式不仅使代码更简洁,还可以提升性能。其性能通常优于显式循环,因为列表推导式在底层进行了优化。
4.1 对比显式循环
显式循环与列表推导式的性能对比:
import time
# 显式循环
start_time = time.time()
numbers = [x for x in range(1000000)]
squared_numbers_loop = []
for x in numbers:
squared_numbers_loop.append(x ** 2)
end_time = time.time()
print("显式循环耗时:", end_time - start_time)
# 列表推导式
start_time = time.time()
squared_numbers_lc = [x ** 2 for x in numbers]
end_time = time.time()
print("列表推导式耗时:", end_time - start_time)
4.2 避免不必要的计算
在列表推导式中避免不必要的计算:
# 低效的列表推导式
low_efficiency = [x + y for x in range(10) for y in range(10)]
# 高效的列表推导式
high_efficiency = [x + y for x in range(10) for y in range(x, 10)]
五、实际应用案例
5.1 数据清洗
列表推导式在数据清洗中的应用:
data = [" apple ", "banana", " cherry", "date "]
cleaned_data = [item.strip() for item in data]
print(cleaned_data) # 输出: ['apple', 'banana', 'cherry', 'date']
5.2 文件处理
列表推导式在文件处理中的应用:
# 读取文件并提取每行的长度
with open('example.txt', 'r') as file:
line_lengths = [len(line) for line in file]
print(line_lengths)
5.3 多重条件过滤
列表推导式在多重条件过滤中的应用:
numbers = range(100)
filtered_numbers = [x for x in numbers if x % 2 == 0 and x % 3 == 0]
print(filtered_numbers) # 输出: [0, 6, 12, 18, 24, 30, 36, 42, 48, 54, 60, 66, 72, 78, 84, 90, 96]
5.4 生成字典和集合
除了生成列表,推导式还可以生成字典和集合:
# 字典推导式
numbers = range(5)
squares_dict = {x: x**2 for x in numbers}
print(squares_dict) # 输出: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
# 集合推导式
unique_squares = {x**2 for x in numbers}
print(unique_squares) # 输出: {0, 1, 4, 9, 16}
六、常见误区与注意事项
6.1 过度使用列表推导式
虽然列表推导式非常方便,但过度使用可能会导致代码可读性降低。对于过于复杂的逻辑,显式循环可能更清晰。
# 过于复杂的列表推导式
complex_list_comp = [x**2 for x in range(10) if x % 2 == 0 for y in range(x) if y % 2 == 1]
# 更清晰的显式循环
result = []
for x in range(10):
if x % 2 == 0:
for y in range(x):
if y % 2 == 1:
result.append(x**2)
6.2 忽略生成器表达式
当处理大量数据时,生成器表达式可以节省内存:
# 列表推导式(占用较多内存)
squared_numbers = [x**2 for x in range(1000000)]
# 生成器表达式(节省内存)
squared_numbers_gen = (x**2 for x in range(1000000))
Python 的列表推导式是一种强大且简洁的创建列表的方法。通过使用列表推导式,可以用简洁的语法实现复杂的列表生成逻辑,同时提升代码的可读性和执行效率。本文详细讲解了列表推导式的基本语法、嵌套用法、高级用法、性能优化、实际应用案例以及常见误区和注意事项。