xv6实现的动态内存分配虽然只有不到100行代码,但却体现了动态内存分配的精髓,非常值得学习
xv6的内存布局
一谈到C语言的动态内存分配,就会想到堆以及malloc()和free()这两个函数。先来回顾一下XV6中的内存布局是怎样的,我们动态分配的内存就在下图的heap部分:
总体思路
在看源码之前,我们先来想想自己会如何设计malloc()和free()。
设计malloc(),我们需要给malloc()传入一个参数表示需要申请的内存块的大小,同时返回申请成功的内存块的首地址,在xv6中的系统调用sbrk()刚好就能满足这一需求。
设计free(),我们需要给free()传入一个内存块地址,让他能自动地释放掉对应的内存块,然而如果仅仅只有内存块地址的信息是不够的,删多少就是一个问题,解决办法就是给每一个内存块添加size这一属性;同时释放掉的内存我们也需要处理,不然那块内存就会被浪费,解决办法是使用链表管理所有可用的内存块。

照着上面的思路,我们再来看看源码是如何实现这些功能的。
umalloc.c:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/param.h"
// Memory allocator by Kernighan and Ritchie,
// The C programming Language, 2nd ed. Section 8.7.
typedef long Align;
union header {
struct {
union header *ptr;
uint size;
} s;
Align x;
};
typedef union header Header;
static Header base;
static Header *freep;
void
free(void *ap)
{
Header *bp, *p;
bp = (Header*)ap - 1;
for(p = freep; !(bp > p && bp < p->s.ptr); p = p->s.ptr)
if(p >= p->s.ptr && (bp > p || bp < p->s.ptr))
break;
if(bp + bp->s.size == p->s.ptr){
bp->s.size += p->s.ptr->s.size;
bp->s.ptr = p->s.ptr->s.ptr;
} else
bp->s.ptr = p->s.ptr;
if(p + p->s.size == bp){
p->s.size += bp->s.size;
p->s.ptr = bp->s.ptr;
} else
p->s.ptr = bp;
freep = p;
}
static Header*
morecore(uint nu)
{
char *p;
Header *hp;
if(nu < 4096)
nu = 4096;
p = sbrk(nu * sizeof(Header));
if(p == (char*)-1)
return 0;
hp = (Header*)p;
hp->s.size = nu;
free((void*)(hp + 1));
return freep;
}
void*
malloc(uint nbytes)
{
Header *p, *prevp;
uint nunits;
nunits = (nbytes + sizeof(Header) - 1)/sizeof(Header) + 1;
if((prevp = freep) == 0){
base.s.ptr = freep = prevp = &base;
base.s.size = 0;
}
for(p = prevp->s.ptr; ; prevp = p, p = p->s.ptr){
if(p->s.size >= nunits){
if(p->s.size == nunits)
prevp->s.ptr = p->s.ptr;
else {
p->s.size -= nunits;
p += p->s.size;
p->s.size = nunits;
}
freep = prevp;
return (void*)(p + 1);
}
if(p == freep)
if((p = morecore(nunits)) == 0)
return 0;
}
}
不看函数,先看数据。
header
union header {
struct {
union header *ptr; // 指向下一个内存块
uint size;
} s;
Align x;
};
前面提到内存块的size和链表就是由header实现的,他是umalloc里的核心数据结构
freep
static Header base;
static Header *freep;
freep表示指向空闲链表任意节点的指针,base用于初始化freep
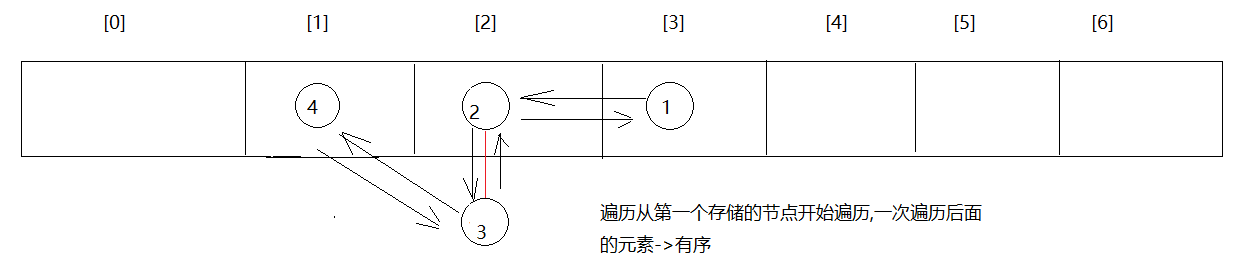
内存池模型
在看源码之前先看一下xv6动态内存分配时的内存池模型,这样更助于代码理解。

从图中可以看到:
- 每一个申请的内存块都不是单独存在的,而是由header+数据载荷构成
- 空闲的内存块会被加入空闲链表中管理(使用中的不会加入链表管理),并且空闲链表是一个环形链表
- freep指向其中一个空闲内存块
下面的源码结合这张图理解效果最佳
malloc()
malloc()用于申请指定大小的内存块,并返回内存块首地址
void*
malloc(uint nbytes)
{
Header *p, *prevp;
uint nunits;
// 计算申请nbytes空间需要多少Header结构(向上取整)
nunits = (nbytes + sizeof(Header) - 1)/sizeof(Header) + 1;
// 初始化空闲链表
if((prevp = freep) == 0){
base.s.ptr = freep = prevp = &base; // 使用base进行初始化
base.s.size = 0;
}
// 遍历空闲链表
for(p = prevp->s.ptr; ; prevp = p, p = p->s.ptr){
// 内存池中是否有满足条件的内存块
if(p->s.size >= nunits){
if(p->s.size == nunits)
prevp->s.ptr = p->s.ptr;
else {
p->s.size -= nunits;
p += p->s.size;
p->s.size = nunits;
}
freep = prevp;
return (void*)(p + 1);
}
// 内存池没有则morecore申请新的内存块
if(p == freep)
if((p = morecore(nunits)) == 0)
return 0;
}
}
计算需要申请的内存大小
nunits = (nbytes + sizeof(Header) - 1)/sizeof(Header) + 1;
在umalloc中所有的内存块都是以header为单位进行分配的(也就是说我们的内存块占用空间是n header,而非n byte),目的是以header个单位对齐。
这里需要注意的是,在从byte转换为header时,两数相除需要向上取整才能容纳所有的数据。
向下取整:a/b eg.13 / 3 = 4
向上取整:(a-1)/b + 1 eg.(13 + 3 - 1) / 3 = 5
所以(nbytes + sizeof(Header) - 1)/sizeof(Header)计算出了数据载荷占用的header个数后,还需要+1加上一个header。
初始化空闲链表
if((prevp = freep) == 0){
base.s.ptr = freep = prevp = &base; // 使用base进行初始化
base.s.size = 0;
}
空闲链表只有在最开始会被初始化,判断条件就是freep为0的话就是还未初始化;紧接着会将base的地址赋值给prevp,freep(base是位于data段的一个静态变量,由编译器分配地址);同时base的地址还会赋值给base.s.ptr,环形链表就是在这里形成的。
遍历空闲链表
for(p = prevp->s.ptr; ; prevp = p, p = p->s.ptr){
// 内存池中是否有满足条件的内存块
if(p->s.size >= nunits){
if(p->s.size == nunits)
prevp->s.ptr = p->s.ptr;
else {
p->s.size -= nunits;
p += p->s.size;
p->s.size = nunits;
}
freep = prevp;
return (void*)(p + 1);
}
// 内存池没有则morecore申请新的内存块
if(p == freep)
if((p = morecore(nunits)) == 0)
return 0;
}
遍历空闲链表中的空闲内存块,查看空闲链表(内存池)中是否有满足条件(空闲内存块大小>= 待申请内存块大小)的内存块:
- 有则将此内存块拿去用,这里涉及链表节点以及大小的调整。
- 没有则通过morecore申请新的内存块。因为他是从freep的后一个节点开始遍历的,遍历一圈结束时也就是p == freep的时候。
我们不会将以前的内存块彻底删除,而是将他留下,作为内存池的一部分重复使用。这样的好处是减少了申请新内存块的开销:
- 空间上,不需要额外的空间;
- 时间上:免去了物理地址到虚拟地址空间的映射,特别是对于lazy allocation的场合,频繁的申请新的地址空间特别耗时。
morecore()
morecore()用于申请新的内存块
static Header*
morecore(uint nu)
{
char *p;
Header *hp;
if(nu < 4096)
nu = 4096; // 设置最小分配单位为4096个header
p = sbrk(nu * sizeof(Header)); // 分配新的内存块
if(p == (char*)-1)
return 0;
hp = (Header*)p;
hp->s.size = nu;
free((void*)(hp + 1)); // 将新内存加入空闲链表
return freep;
}
morecore()会设置最小的分配单位为4096个header,可能是尽量分配大空间,因为小空间的内存块更容易产生内存碎片(猜测);然后通过sbrk()系统调用申请新的内存块,最后将新申请的这个内存块通过free()加入空闲链表,他会在malloc的下次循环被使用。
free()
free()用于释放内存块,同时还会合并空闲内存
void
free(void *ap)
{
Header *bp, *p;
// 获取内存块对应的header地址
bp = (Header*)ap - 1;
// 遍历内存块的位置(位于哪两个空闲内存之间)
for(p = freep; !(bp > p && bp < p->s.ptr); p = p->s.ptr)
if(p >= p->s.ptr && (bp > p || bp < p->s.ptr))
break;
// 检查并合并相邻的内存块
if(bp + bp->s.size == p->s.ptr){
bp->s.size += p->s.ptr->s.size;
bp->s.ptr = p->s.ptr->s.ptr;
} else
bp->s.ptr = p->s.ptr;
if(p + p->s.size == bp){
p->s.size += bp->s.size;
p->s.ptr = bp->s.ptr;
} else
p->s.ptr = bp;
// 更新指向空闲内存块的指针
freep = p;
}
free()首先遍历当前内存块的位置,它需要获得它相邻空闲链表节点的位置,这样才能进行之后的操作;然后它会检查当前内存块的大小是否满足合并的条件,分别和前后内存块比较,不能合并则重定向链表指向。
Linux中的malloc()实现
Linux中的动态内存分配策略有些许不一样:
- malloc小于128k的内存,使用brk分配内存
- malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0)
之所以使用brk来分配小内存,是因为brk是在堆空间这块连续区域上申请内存,频繁的brk申请大内存很容易导致内存的碎片化;而mmap不用担心这个问题,因为他是在堆和栈上的一片独立的区域分配的内存,不会有内存碎片的问题。
看起来mmap很有用,那为什么还需要brk来申请小内存呢?
这就是我们上面总结的知识了。brk并不是每次都需要申请新内存,而是可以从内存池中重用以前申请的内存,再次访问该内存不需要任何系统调用和缺页中断,开销极小,相比mmap每次都是重新申请要方便许多。