1. 函数概念和调用原理
1.1 基本介绍
函数是基本的代码块,用于执行一个任务。
Go 语言最少有个 main() 函数。
你可以通过函数来划分不同功能,逻辑上每个函数执行的是指定的任务。
函数声明告诉了编译器函数的名称,返回类型,和参数。
Go 语言标准库提供了多种可动用的内置的函数。例如,len() 函数可以接受不同类型参数并返回该类型的长度。如果我们传入的是字符串则返回字符串的长度,如果传入的是数组,则返回数组中包含的元素个数。
简单点理解,函数就是一个或者多个功能的集合体。
1.2 函数的作用
- 结构化编程对代码的最基本的封装,一般按照功能组织一段代码
- 封装的目的为了复用,减少冗余代码
- 代码更加简洁美观、可读易懂
1.3 函数的分类
- 内建函数,如make、new、panic等
- 库函数,如math.Ceil()等
- 自定义函数,使用func关键字定义
1.4 函数定义与调用
func 函数名(参数列表) [(返回值列表)]{
函数体(代码块)
[return 返回值]
}
这里[]表示其中的内容可有可无
func main(){
被调用函数()
}
函数名就是标识符,命名要求一样
定义中的参数列表称为形式参数,只是一种符号表达(标识符),简称形参
返回值列表可有可无,需要return语句配合,表示一个功能函数执行完返回的结果
函数名(参数列表) [(返回值列表)] 这部分称为函数签名
Go语言中形参也被称为入参,返回值也被称为出参
1.4.1 普通函数定义
package main
// 函数声明/定义(定义时)
func add(){
Println("函数体,具体执行功能的代码块。")
}
func main() {
add()// 函数调用(调用时)
}
1.4.2 带参数的函数定义
1.4.2.1 使用形参(入参)与实参
package main
import "fmt"
// x int, y int属于形式参数(形参或入参)。还可以写成x, y int
// add(x int, y int)属于签名
func add(x int, y int) {
fmt.Println(x + y)
}
func main() {
// 函数调用时,把add函数所需形参传过去,这种参数被称为“实参”,还能成为“传参”
add(4, 5) // 注意参数的对应关系
}
==========调试结果==========
9
1.4.3 定义包含返回值的函数
调用时,如果有返回值,需要在调用时定义对应返回值个数的变量去接收。
package main
import "fmt"
// add(x int, y int) int,括号后的int表示返回值的类型和数量。
func add(x int, y int) int {
fmt.Println("add函数的执行结果:", x+y)
// 定义返回值为1
return 1 // return之后的语句不会执行,函数将结束执行
}
func main() {
// add函数的返回值赋值给v变量
v := add(4, 5) // go语言中,只能在有返回值的情况下,才能用变量接住,不然定义了会报错。
fmt.Println("add函数的返回值:", v)
//fmt.Println(add(4, 5)) // 如果返回值只用一次那这样也可以,等同于上面两条。多次调用还是建议定义变量,使用起来方便
}
==========调试结果==========
add函数的执行结果: 9
add函数的返回值: 1
上述代码执行过程:
- 系统从上到下加载代码,加载到v := add(4, 5)时,先执行add(4, 5)。
- 在内存中找到add函数,并把4和5作为实参传递给add函数中的x和y。
- add函数开始执行fmt.Println(“add函数的执行结果:”, x+y),也就是把x+y的结果输出到控制台。
- add函数中的println函数执行完毕后,开始执行return 1,最终会返回一个1给到main函数中的v。
- 执行main中的print函数,输出add函数的返回值。
1.5 函数调用原理
特别注意,函数定义只是告诉你有一个函数可以用,但这不是函数调用执行其代码。至于函数什么时候被调用,不知道。一定要分清楚定义和调用的区别。
函数调用相当于运行一次函数定义好的代码,函数本来就是为了复用,试想你可以用加法函数,我也可以用加法函数,你加你的,我加我的,应该互不干扰的使用函数。为了实现这个目标,函数调用的一般实现,都是把函数压栈(LIFO),每一个函数调用都会在栈中分配专用的栈帧,本地变量、实参、返回值等数据都保存在这里。
一句不准确的口诀:函数的每一次调用都是独立的,不相干的。—— wayne
上面的代码,首先调用main函数,main压栈,接着调用add(4, 5)时,add函数压栈,压在main的栈帧之上,add调用return,add栈帧消亡,回到main栈帧,将add返回值保存在main栈帧的本地变量out上。
2. 函数类型与返回值
2.1 函数类型
可以看出同一种签名的函数是同一种类型
package main
import "fmt"
func fn1() {}
func fn2(i int) int { return 100 }
func fn3(j int) (r int) { return 200 }
func main() {
fmt.Printf("%T\n", fn1)
fmt.Printf("%T\n", fn2)
fmt.Printf("%T\n", fn3)
}
==========调试结果==========
func() // 没有参数的函数,就是这样的
func(int) int
func(int) int
2.2 函数返回值
函数返回值为局部变量。
2.2.1 无返回值函数
注意:在Go中,无返回值的函数不允许使用变量去接,会报错。
package main
import "fmt"
func fn1() {
fmt.Println("这是一个无返回值函数!")
}
func main() {
// a := fn1() // 由于没有返回值,所以千万不要用变量去接,会报错
fn1()// 无返回值,不需要传参的函数直接调用即可。
}
==========调试结果==========
这是一个无返回值函数!
2.2.2 带返回值的函数
2.2.2.1 返回一个值
package main
import "fmt"
func fn2() int { // 此处的int表示该函数有1个返回值
return 100 // 返回一个值
}
func main() {
v := fn2() // 变量接收返回值
fmt.Println("fn2函数的返回值为:", v)
}
==========调试结果==========
fn2函数的返回值为: 100
package main
import "fmt"
func fn3() int {
var r = 100
return r
}
func main() {
v := fn3()
fmt.Println("fn3函数的返回值为:", v)
}
==========调试结果==========
fn3函数的返回值为: 100
package main
import "fmt"
func fn4() (r int) { // 直接在函数后面定义变量和类型也可以,r也相当于就是个占位符
r = 300
return r
// return // 还可以这样,return后面不接变量,由系统自动推断到r int
}
func main() {
v := fn4()
fmt.Println("fn4函数的返回值为:", v)
}
==========调试结果==========
fn4函数的返回值为: 300
package main
import "fmt"
func fn4() (r int) {
t := 300
return t //该方式相当于r = t
}
func main() {
v := fn4()
fmt.Println("fn4函数的返回值为:", v)
}
==========调试结果==========
fn4函数的返回值为: 300
2.2.2.2 返回多个值
package main
import "fmt"
// go允许多返回值
func fn5() (int, int) { // (int, int),两个int表示有两个返回值
a, b := 4, 50
return a, b
}
func main() {
v1, v2 := fn5() // 注意:返回值变量要和返回值数量相对应
fmt.Println("fn5函数的返回值为:", v1, v2)
}
==========调试结果==========
fn5函数的返回值为: 4 50
package main
import "fmt"
func fn6() (i int, j bool) {
// return 100, false // 这样可以
i, j = 200, true
return // 这样也可以,相当于return i, j
}
func main() {
v1, v2 := fn6()
fmt.Println("fn6函数的返回值为:", v1, v2)
}
==========调试结果==========
fn6函数的返回值为: 200 true
这里看一个特殊示例
package main
import "fmt"
func fn7() (i int, j bool) {// 这里的i j也是充当了出参占位符的角色,同时也是局部变量,仅在该函数中使用
return
}
func main() {
v1, v2 := fn7()
fmt.Println("fn7函数的返回值为:", v1, v2)
}
==========调试结果==========
fn7函数的返回值为: 0 false
从结果可以看出,不明确指定返回值的情况下,int默认为0,bool默认为false。
其实就是只声明,但是不赋值,使用了对应数据类型的默认值。
再看一个非常特殊的示例
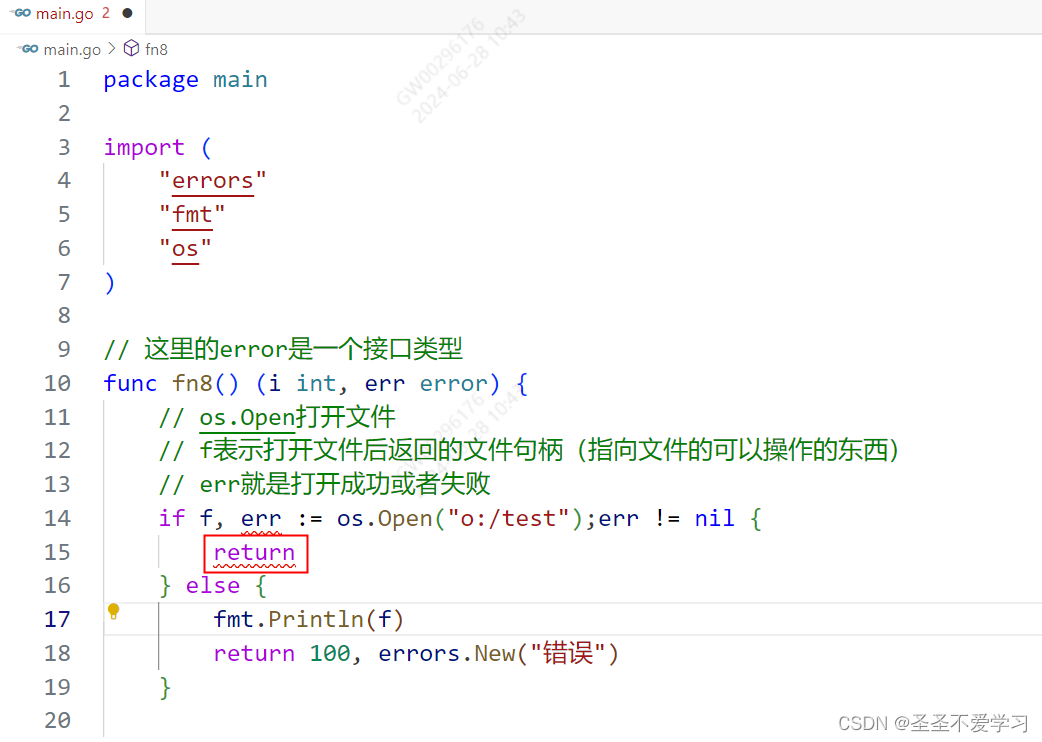
为什么上图return报错了?
根本原因是return不知道把结果返回给谁!因为if f,err := xxx,这里相当于重新在if中声明了一个f局部变量和err局部变量,但是fn8函数的出参也定义了err变量,由于存在两个err变量,导致return不知道把结果返回给哪个err,所以报错了。
解决办法如下如图:
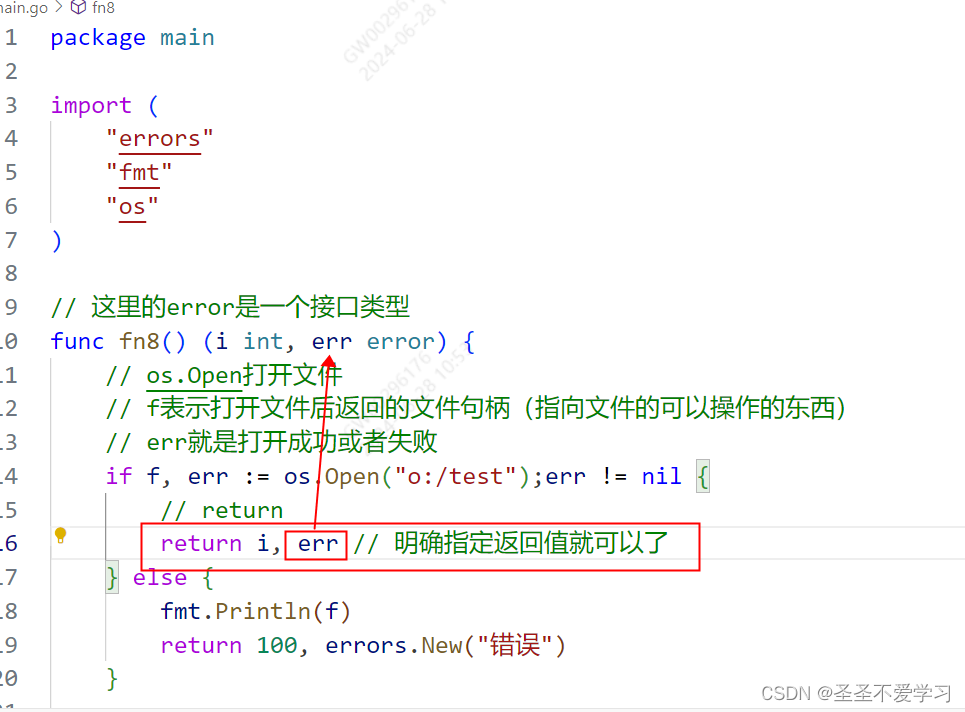
2.2.3 返回值总结
- 实际工作中,还是更建议显示的指定return 返回值,便于阅读。
- 可以返回0个或多个值。
- 可以在函数定义中写好返回值参数列表。
○ 可以没有标识符,只写类型。但是有时候不便于代码阅读,不知道返回参数的含义
○ 可以和形参一样,写标识符和类型来命名返回值变量,相邻类型相同可以合并写
○ 如果返回值参数列表中只有一个返回参数类型,小括号可以省略
○ 以上2种方式不能混用,也就是返回值参数要么都命名,要么都不要命名- return
○ return之后的语句不会执行,函数将结束执行
○ 如果函数无返回值,函数体内根据实际情况使用return
○ return后如果写值,必须写和返回值参数类型和个数一致的数据
○ return后什么都不写那么就使用返回值参数列表中的返回参数的值,如果返回值参数没有赋过值,就用零值
3. 函数的形参与可变参数
3.1 形参
- 可以无形参,也可以多个形参
- 不支持形式参数的默认值
- 形参是局部变量
3.1.1 定义无标识符形参
无标识符形参不建议使用,因为没办法在函数中拿到这个值(实参)。
定义形参的目的是为了在函数中使用,这种在函数中无法使用的形参,定义了也是没有意义的。
package main
import "fmt"
func fn1(int) { // 不建议这样用,因为没有办法获取传进来的实参100
fmt.Println("无标识符形参!")
}
func main() {
// 传递实参
fn1(100)
}
==========调试结果==========
无标识符形参!
3.1.2 定义有标识符形参
推荐使用该方式。
package main
import "fmt"
func fn2(x, y int) {
// 明确定义形参标识符后,就可以在函数体内部调用了
fmt.Printf("有标识符形参:x=%v,y=%v", x, y)
}
func main() {
fn2(100, 200)
}
==========调试结果==========
有标识符形参:x=100,y=200
3.1.2.1 形参默认值示例
注意:Go语言不支持形参默认值,所以不要这样定义。
package main
import "fmt"
// func config(a,b int, c string = "OK"){ // 这样是不可以的
func config(a, b int, c string) {
fmt.Println(a, b, c)
}
func main() {
// config(1,2)
config(1, 2, "ok")
}
==========调试结果==========
1 2 ok
3.2 可变参数(name … type)
在 Go 语言中,可变参数是指函数可以接受任意数量的参数。
这通过在函数的参数列表中使用省略号 … 和参数类型来实现,最终可变参数收集实参到一个切片中,注意最终数据类型是切片。
使用可变参数可以让你的函数更加灵活,能够处理不同数量的输入。
注意:如果有可变参数,那它必须位于参数列表中最后。
3.2.1 定义可变参数函数
package main
import "fmt"
// ...表示任意数量的参数(0到n个),int为参数类型,nums为可变参数名称。
func fn6(nums ...int) {
fmt.Printf("可变参数nums的值:%d\n可变参数nums的类型:%[1]T\n可变参数nums的长度:%[2]d\n可变参数nums的容量:%[3]d\n", nums, len(nums), cap(nums))
}
func main() {
fn6()
fn6(1, 3, 100)
}
==========调试结果==========
可变参数nums的值:[]
可变参数nums的类型:[]int
可变参数nums的长度:0
可变参数nums的容量:0
可变参数nums的值:[1 3 100]
可变参数nums的类型:[]int
可变参数nums的长度:3
可变参数nums的容量:3
3.2.2 切片分解(切片传递)
切片分解其实就是把传入的切片的header复制给了新的切片。
切片分解不会导致底层数组扩容,因为复制的header。
3.2.2.1 示例一
package main
import "fmt"
func fn6(nums ...int) {
fmt.Println(nums)
fmt.Printf("%p %p\n", &nums, &nums[0])
}
func main() {
var p = []int{1, 3}
fn6(p...)// 这里就相当于是header复制
fmt.Printf("%p %p\n", &p, &p[0])
}
==========调试结果==========
[1 3]
0xc000008090 0xc0000180a0
0xc000008078 0xc0000180a0
3.2.2.2 示例二
func fn7(x, y int, nums ...int) {
fmt.Printf("%d %d; %T %[3]v, %d, %d\n", x, y, nums, len(nums),
cap(nums))
}
p := []int{4, 5}
fn7(p...) // 错误,不能用在普通参数上
fn7(1, p...) // 错误,不能用在普通参数上
fn7(1, 2, 3, p...) // 错误,不能用2种方式为可变参数传参,不能混用
// fn7(1, 2, p..., 9, 10) // 语法错误
// fn7(1, 2, []int{4, 5}..., []int{6, 7}...) // 语法错误,不能连续使用p...,只能一次
// 正确的如下
fn7(1, 2, []int{4, 5}...)
fn7(1, 2, p...)
fn7(1, 2, 3, 4, 5)
3.2.3 小练习:编写一个函数,它可以接受任意数量的整数参数,并返回它们的总和。
package main
import (
"fmt"
)
// 编写一个函数 sum,它可以接受任意数量的整数参数,并返回它们的总和。
func Sum(nums ...int) int {
a := 0
for _, v := range nums {
a += v
}
return a
}
func main() {
fmt.Println(Sum(10, 2, 10))
}
==========调试结果==========
22
4. 作用域
作用域实际上就是在说“标识符”的可见范围,有点类似于全局变量和局部变量这种概念。
函数天然就是一个作用域,Go中的作用域主要如下:
- 语句块作用域
如if、for、switch等语句中使用短格式定义的变量,可以认为就是该语句块的变量,作用域仅在该语句块中。- 显示的块作用域
{xxx},这就是显示的块作用域。- universe块作用域
- 包块作用域
- 函数块作用域
4.1 语句块作用域
package main
import "fmt"
func main() {
t := []int{1, 2, 3, 4}
for _, v := range t {
fmt.Println(v)
}
// 语句块外部引用变量v失败,因为v的作用域只在for循环内部
//fmt.Println(v)
fmt.Println("------------------")
var v = 1 // 这里再定义一个v也不会有冲突,因为两个v的作用域不同
fmt.Println(v)
}
==========调试结果==========
1
2
3
4
------------------
1
4.2 显示的块作用域
package main
import "fmt"
func main() {
{
const a = 100
var b = 200
c := 300
fmt.Println(a,b,c)
}
// 这样是不可以的,abc标识符只能在{}中生效。
//fmt.Println(a,b,c)
}
==========调试结果==========
100 200 300
4.3 universe块(宇宙块)
宇宙块,意思就是全局块,不过是语言内建的(就是go系统的内置函数)。
预定义的标识符就在这个全局环境中,因此什么bool、int、nil、true、false、iota、append等标识符全局可见,随处可用。
4.4 包块作用域
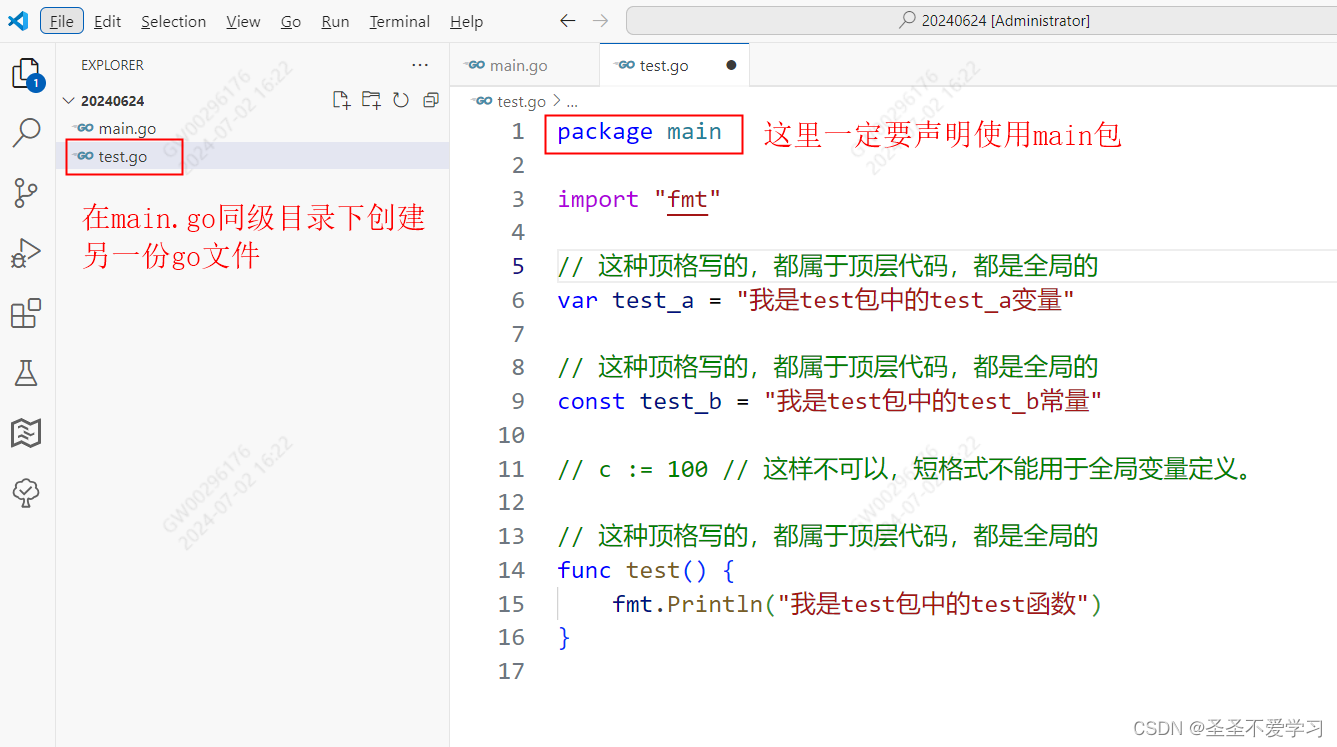
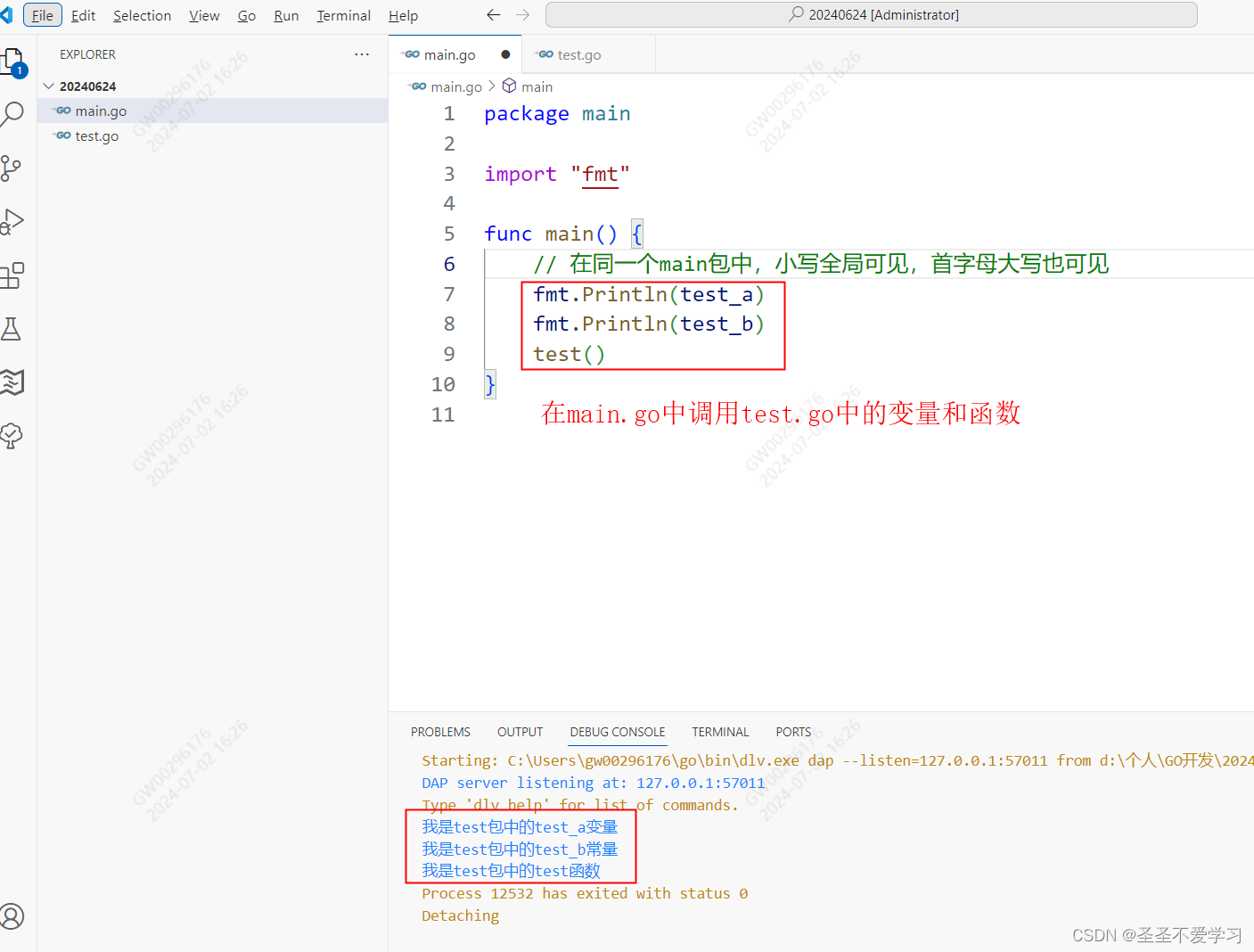
所谓包块作用域,就是说多份代码文件都属于同一个包,那么在main包中就可以调用其他包的变量或函数。
所有包内定义全局标识符,包内可见。包外需要大写首字母导出,使用时也要加上包名。如fmt.Print
如下图:
4.5 函数块作用域
函数声明的时候使用了花括号,所以整个函数体就是一个显式代码块。这个函数就是一个块作用域。
4.6 作用域综合测试
package main
import "fmt"
var a = 100
const b = 200
//c := 300 // 错误,定义全局变量,不能使用短格式
func main() {
// 全局变量可以在函数体内部调用(向内穿透)
a = 500
fmt.Println("调用全局变量a:", a)
// 由于作用域不同,所以a可以在函数体内部二次定义,此时的a为函数体内局部变量
var a = 1000 // 重复定义不代表覆盖,全局a和局部a是两个完全独立的个体
fmt.Println("调用局部变量a:", a) //同时存在相同全局和局部变量时,优先采用就近原则
fmt.Println("调用全局常量b:", b)
const b = "abc"
fmt.Println("调用局部常量b:", b)
}
==========调试结果==========
调用全局变量a: 500
调用局部变量a: 1000
调用全局常量b: 200
调用局部常量b: abc
再来看个特殊例子
package main
import "fmt"
var a = 100
func showA() int { // 看这里
return a
}
func main() {
a = 500
fmt.Println("调用全局变量a:", a)
var a = 1000
fmt.Println("调用局部变量a:", a)
fmt.Println("return返回值:", showA()) // 看这里
}
看下上面showA函数最终的返回值是多少?
答案是500。
因为showA函数体内部是没有a这个变量的,所以它只能向函数体外寻找,只能找到a这个全局变量,而在main函数中,全局变量a的结果已经被修改为500了,所以最终返回值为500。
5. 递归函数
什么是递归?
可以理解为在linux系统中的某个目录下找某一个文件,会一层一层目录去找,直到找到为止,这就是递归。
什么是递归函数?
有两种递归方式:
- 直接在自己函数中调用自己。
- 间接在自己函数中调用的其他函数中调用了自己。可以理解为A调用B,B函数体中又调用了A。
这种间接的递归非常危险,要尽量避免出现间接递归。
并且不管是1或2这种递归调用,假设函数体内部没有返回,那么每次调用都会生成一个“栈争”,有点类似于叠盘子(可以称为递归前进段),直到内存中分配的栈空间耗尽(盘子叠满了),程序就崩溃了。
正常应该是能叠就能收,收这个操作被称为“递归返回段”。
注意:
- 递归函数要有边界条件(递归终止条件,防止无限递归)、递归前进段、递归返回段。
- 递归函数必须有边界条件(递归终止条件,防止无限递归)。
- 当边界条件不满足时,递归前进。
- 当边界条件满足时,递归返回。
5.1 斐波那契数列递归
5.1.1 版本一:普通循环实现
package main
import "fmt"
func fib1(n int) int {
switch {
// 如果小于0,说明传参为负数
case n < 0:
panic("n is negative!!!")
// 如果为0,就直接返回0,因为斐波那契数列的第一个数字就是0
case n == 0:
return 0
// 如果是1或2,就直接返回1,因为0,1,1,……
case n == 1 || n == 2:
return 1
}
// 开始计算第三个数字
a, b := 0, 1 // 先定义两个初始值
for i := 0; i < n-2; i++ { // n-2是因为上面已经输出了2个数字(0和1)
a, b = b, a+b
}
return b
}
func main() {
v := fib1(4) // 显示单个斐波那契数列
fmt.Println(v)
}
==========调试结果==========
2
5.1.2 版本二:递归实现
斐波那契数列:1,1,2,3,……
实现公式:F(n)=F(n-1)+F(n-2)。n-1就是前一个数字,n-2就是前面第二个数字
还是理解为:从第三个数开始往后,都是前两数的和
package main
import "fmt"
func fib2(n int) int {
// (2)判断函数传参值为1或2就直接返回1,相当于就是“边界条件”。
if n == 0 {
panic("传参不能为0")
} else if n == 1 || n == 2 { // 此处的1和2表示的是第一个数和第二个数
return 1
}
// (1)递归调用
return fib2(n-1) + fib2(n-2)
}
func main() {
v := fib2(6)
fmt.Println(v)
}
==========调试结果==========
8
执行过程解释
- return fib2(n-1) + fib2(n-2)
假设我传参为3,也就是fib2(3),那么fib2(n-1) + fib2(n-2)就变成了fib2(3-1) + fib2(3-2)=return fib2(2) + fib2(1),这就形成了递推公式。
但是在递归调用中,必须有前进段和返回段,也就是必须要加边界条件防止无限递归。
这里如果不加边界条件,那么3就会分裂成2和1,2分裂成1和0,1分裂成0和-1,就这么无限分裂下去且没有返回阶段。- 定义边界条件,if判断。
还是假定传参为fib2(3),那么return fib2(2) + fib2(1)=fib2(3),这么看着是不是不对。
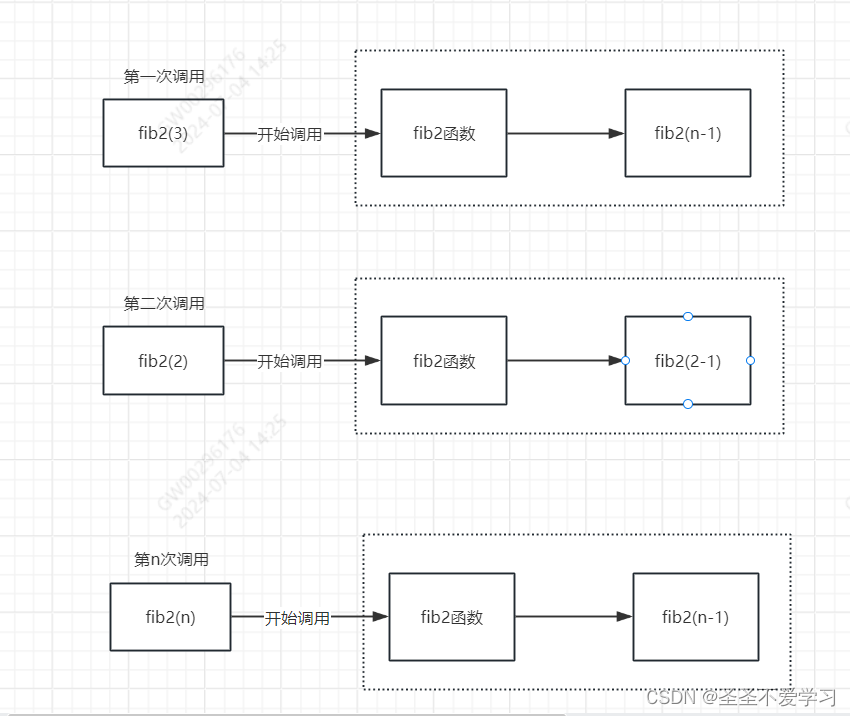
实际的执行过程是先把fib2(3-1)=2带入到形参处落栈,如下图:
加法先执行左边。
> 然后再把fib2(3-2)=1带入到形参处落栈,入下图:
但是在这个过程中,单单n-2就能无限次分裂了,所以必须设置边界条件来阻止无限递归。
else if n == 1 || n == 2 {return 1},有了这个判断,就阻止了递归调用的无限调用,同时,还返回了值给了fib2(3),这个1相当于被它进行了暂计,等到计算fib2(n-2)时,也会把结果暂计下来,最后运行return 1 + 1,并把最终返回值返回给main函数,到此整个函数调用结束。
5.1.3 版本三:循环改调用实现
就是把版本一里面你的循环,改成函数递归调用。
循环的次数等于递归调用的次数。
package main
import "fmt"
func fib3(n, a, b int) int {
if n < 3 {
return b
}
return fib3(n-1, b, a+b)
}
func main() {
v := fib3(10, 1, 1)
fmt.Println(v)
}
==========调试结果==========
55
5.1.4 三种方式效率对比
上面三种方式,效率最高的是fib1、其次是fib3,效率最差的是fib2。
为什么fib2效率最差?主要就是因为这个公式fib2(n-1) + fib2(n-2),看下图:
稍微传参一个大一点的数字,函数体内部会存在大量的重复计算,严重浪费时间和资源。
不过也有解决办法,就是把fib分裂出来的结果先到map中查询一次,没有匹配到的就把结果存到map中,一旦匹配到的结果,就说明之前肯定已经计算过了,就不用重复计算了。
唯一的缺点可能就是需要多消耗一点内存,但是运行速度变快了。

5.2 间接递归
func foo() {
bar()
}
func bar() {
foo()
}
foo()
就像上面的代码,foo中调用bar,bar中调用foo。
不推荐这么玩,特别是复杂代码,出了问题非常不利于排查。
5.3 递归总结
能不用就不用
- 递归是一种很自然的表达,符合逻辑思维
- 递归相对运行效率低,每一次调用函数都要开辟栈帧
- 递归有深度限制,如果递归层次太深,函数连续压栈,栈内存就溢出了
- 如果是有限次数的递归,可以使用递归调用,或者使用循环代替,循环代码稍微复杂一些,但是只
- 要不是死循环,可以多次迭代直至算出结果
- 绝大多数递归,都可以使用循环实现
- 即使递归代码很简洁,但是能不用则不用递归
6. 匿名函数
6.1 什么是匿名函数
匿名函数是Go语言中的一种特殊函数,它没有函数名,通常用于快速定义一个功能,然后立即使用它。它们可以作为参数传递给其他函数,或者存储在变量中,以便稍后使用。
6.2 为什么要用匿名函数
在Go语言中,匿名函数是一种没有名称的函数,它们在某些情况下非常有用,比如当需要一个简单的功能,但又不想为此创建一个完整的函数定义时。
调用的话,由于没有名字,所以只能选择立即调用或者赋值给一个标识符。
主要使用场景是用作高阶函数中,是传入的逻辑,函数允许传入参数,就是把逻辑外置。
所谓高阶函数就是返回值或形参是一个函数,两者满足其一皆为高阶函数。
如下例子就会演示这种场景。
6.3 定义匿名函数
6.3.1 方式一:纯匿名函数
package main
import "fmt"
func main() {
// 定义匿名函数并调用,但是只能使用一次,因为它没有标识符。
v := func(x, y int) int {
return x + y
}(4, 5)
fmt.Println(v)
}
==========调试结果==========
9
6.3.2 方式二:匿名函数加高阶函数
package main
import "fmt"
// fn func(x,y int) int,这一步就属于逻辑外移了
// 所谓逻辑外移,就是calc函数本身并不管运算逻辑如何实现,而是由fn函数把运算逻辑作为参数传递进来
func calc(a, b int, fn func(x, y int) int) int {// fn是高阶函数
// 这个r对应的是fn func(x,y int) int中最后的这个int
r := fn(a, b)
// 这个r对应的是这个int {
return r
}
func minus(x, y int) int {
return x - y
}
func main() {
// fn函数的运算逻辑,在这里作为实参传入{return x + y}
fmt.Println(calc(4, 5, func(x, y int) int { return x + y }))
fmt.Println(calc(4, 5, func(x, y int) int { return x * y }))
fmt.Println(calc(4, 5, minus))// 注意minus不要写成minus()
}
==========调试结果==========
9
20
-1
7. 函数嵌套
package main
import "fmt"
func outer() {
c := 99
var inner = func() {
fmt.Println("1 inner c=", c)
}
inner()
fmt.Println("2 outer c=", c)
}
func main() {
outer()
}
==========调试结果==========
1 inner c= 99
2 outer c= 99
可以看到outer中定义了另外一个函数inner,并且调用了inner。outer是包级变量,main可见,可以调用。而inner是outer中的局部变量,outer中可见。
8. 闭包
自由变量: 未在本地作用域中定义的变量。例如定义在内层函数外的外层函数的作用域中的变量。
闭包: 就是一个概念,出现在嵌套函数中,指的是内层函数引用到了外层函数的自由变量(局部变量),就形成了闭包。闭包是运行期动态的概念(只有在运行期间才会有闭包)。
略
9. defer
9.1 介绍
defer意思是推迟、延迟。语法很简单,就在正常的语句前加上defer就可以了。
在某函数中使用defer语句,会使得defer后跟的语句进行延迟处理,当该函数return前,或发生panic时,defer后语句开始执行。
同一个函数可以有多个defer语句,依次加入调用栈中(LIFO),函数返回或panic时,从栈顶依次执行
defer后语句。执行的先后顺序和注册的顺序正好相反,也就是后注册的先执行。
defer后的语句必须是一个函数或方法的调用。
9.2 示例
9.2.1 示例一
package main
import "fmt"
func main() {
fmt.Println("start")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("stop")
}
==========调试结果==========
start
stop
3
2
1
9.2.2 示例二
package main
import "fmt"
func main() {
fmt.Println("start")
count := 1
defer fmt.Println(count)
count++
defer fmt.Println(count)
count++
defer fmt.Println(count)
count++
fmt.Println("stop")
}
==========调试结果==========
start
stop
3
2
1
为啥上述代码执行结果是321,为什么?因为defer注册时就,就把其后语句的延迟执行的函数的参数准备好了,也就是注册时计算。
9.2.3 示例三:特殊示例
package main
import "fmt"
func main() {
fmt.Println("start")
count := 1
defer func() {
fmt.Println(count)
}()
count++
defer fmt.Println(count)
count++
defer fmt.Println(count)
count++
fmt.Println("stop")
}
==========调试结果==========
start
stop
3
2
4
为什么结果是3 2 4?
(1)首先main函数中的内容从上到下加载到内存中,这里先忽略defer func() { fmt.Println(count) }(),继续往下看
(2)count++,count从原来的1变成2
(3)紧接着defer fmt.Println(count),此时的count就会被加载成2。
(4)count++,count从原来的2变成3。
(5)defer fmt.Println(count),此时的count就会被加载成3。
(6)count++,count从原来的3变成4。
再回来看defer func() { fmt.Println(count) }()。
函数定义部分:func() { fmt.Println(count) }
函数调用部分:()
再看fmt.Println(count)。
有啥区别?Println函数,在执行时,是有明确的传参的,就是count,而我们的匿名函数呢,它没有,它的结构是:func() { 函数体内部 },这就导致在加载的时候,这个匿名函数是不会有任何变化的,等到真正执行这个函数的时候,函数体内部的println函数才开始执行,此时的count变量经过几次迭代,就已经变成4了。