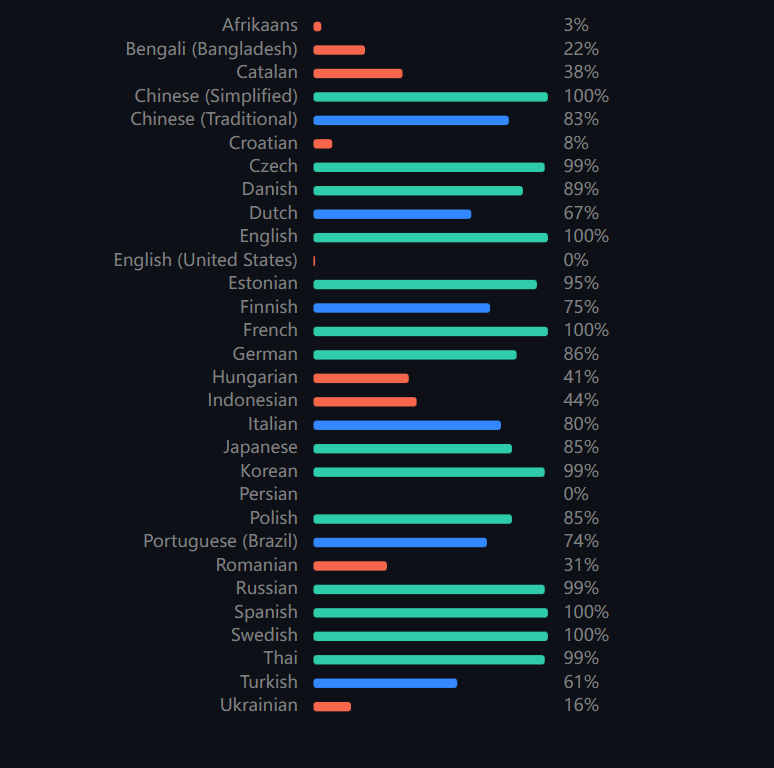
代码位置:test-c-2024: 对C语言习题代码的练习 (gitee.com)
一、前言:
1.1-排序定义:
排序就是将一组杂乱无章的数据按照一定的规律(升序或降序)组织起来。(注:我们这里的排序采用的都为升序)
1.2-排序分类:
常见的排序算法:
-
插入排序
a. 直接插入排序
b. 希尔排序 - 选择排序
a. 选择排序
b. 堆排序 - 交换排序
a. 冒泡排序
b. 快速排序 - 归并排序
a. 归并排序 - 非比较排序
a.计数排序
b.基数排序
1.3-算法比较:

1.4-目的:
今天,我们这里要实现的是快速排序。
1.5-快速排序定义:
通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,然后分别对这两部分记录继续进行排序,以达到整个序列有序。
二、快速排序-key的选择:
2.1-直接在left和right中选择:
这种选择方法具有局限性如果排序的序列已经为升序的情况下,根据快速排序的定义,我们可知,快速排序的话,会确定一个值的位置也就是key,这个值的作用就是把数据分割成独立的两部分,一部分是比他大,一部分是比他小,而如果是升序的情况下直接选择left,选出的left的值是最小的,也就是说右面的部分是N-1个数据,而如果是用递归的方式实现的快排,那么就需要递归N次,也就是建立N个栈才能实现最终排序的操作,如果数据量大就很有可能出现栈溢出的情况。
该情况下递归的图片如图所示:

2.2-随机选择key:
随机选择key,也就是说,在数组下标范围内,随机生成一个下标,采用这个下标位置的数据值作为key这样的情况下,我们就大大降低了选出的key是最小值的情况。能有效地减少栈溢出的情况。
2.3-三数取中:
三数取中就是在left 、midi((right+left)/2) 、right三个下标位置上的数据之间选择出这三个数据中的中间数。这样就避免了key为最小值的情况。
2.4-代码:
void Swap(int* p, int* q) //交换函数
{
int tem = *p;
*p = *q;
*q = tem;
}//直接选取法
int keyi = left;
//随机选keyi
int randi = left + (rand() % (right - left));
Swap(&a[randi], &a[left]);
int keyi = left;
//三数取中
int midi = GetMidNumi(a, left, right);
if (midi != left)
Swap(&a[midi], &a[left]);
int keyi = left;int GetMidNumi(int* a, int left, int right) //三数取中法
{
int mid = (left + right) / 2;
if (a[left] > a[mid])
{
if (a[mid] > a[right])
{
return mid;
}
if (a[left] < a[right])
{
return left;
}
else
{
return right;
}
}
if (a[left] < a[mid])
{
if (a[left] > a[right])
{
return left;
}
if (a[right] > a[mid])
{
return mid;
}
else
{
return right;
}
}
}三、快速排序-Hoare:
3.1-思路:
Hoare快速排序的思路就是:
如果key定义的是left,那么就首先从右边找小,找到以后再从左边出发找大,找完以后后将他们俩的数据调换,然后接着进行下一次先右后左找小再找大,直到left小于right为止。同理若定义key在right处那么就先左后右,处理方式与left类似。
这样排完一趟后,我们能将大于key的数分布在右边,小于key的数分布在左边,最后,我们只需要按照这个思路递归下去,就实现快速排序啦。
注意:在递归时,如果出现left>=right的情况下,我们就需要返回,否则就会死循环。
左边做key为什么相遇位置一定比key小?

3.2-过程图:

3.3-代码:
//Hoare
void QuickSort1(int* a, int left,int right) //快速排序---时间复杂度(O(N^logN))
{
if (left >= right)
return;
int begin = left;
int end = right;
//直接选取法
//int keyi = left;
//随机选keyi
//int randi = left + (rand() % (right - left));
//Swap(&a[randi], &a[left]);
//int keyi = left;
//三数取中
int midi = GetMidNumi(a, left, right);
if(midi!=left)
Swap(&a[midi], &a[left]);
int keyi = left;
while (left < right)
{
//右边找小
while (left<right&&a[right] >=a[keyi])
{
--right;
}
//左边找大
while (left<right&&a[left] <= a[keyi])
{
++left;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);
keyi = left;
//递归---小区间优化--小区间直接使用插入排序
if (end - begin+1 > 10)
{
QuickSort1(a, begin, keyi - 1);
QuickSort1(a, keyi + 1, end);
}
else
{
InsertSort(a + begin, end - begin + 1);
}
}四、快速排序-挖坑法:
4.1-思路:
快速排序,挖坑法的思路就是:
先将第一个数据存放在临时变量k中,形成一个坑位,然后再数组的右边出发,向左寻找小于key的数,然后将这个数填在以前的坑位上,然后在该处重新生成坑位,接着在从左边向右寻找,找大于ker的数,然后将这个数填在生成的坑位上,然后在该处重新生成坑位,就这样一直循环实现上述操作,直到left与right相遇为止,此时,该坑位就应该填key。。
这样排完一趟后,我们能将大于key的数分布在右边,小于key的数分布在左边,最后,我们只需要按照这个思路递归下去,就实现快速排序啦。
注意:在递归时,如果出现left>=right的情况下,我们就需要返回,否则就会死循环。
4.2-过程图:

4.3-代码:
//挖坑法
void QuickSort2(int* a, int left, int right) //快速排序---时间复杂度(O(N^logN))
{
if (left >= right)
return;
int begin = left;
int end = right;
//直接选取法
//int keyi = left;
//随机选keyi
//int randi = left + (rand() % (right - left));
//Swap(&a[randi], &a[left]);
//int keyi = left;
//三数取中
int midi = GetMidNumi(a, left, right);
if(midi!=left)
Swap(&a[midi], &a[left]);
int key = a[left];
int hole = left;
while (left < right)
{
while (left < right &&a[right] >= key)
{
--right;
}
a[hole] = a[right];
hole = right;
while (left < right&&a[left] <= key)
{
++left;
}
a[hole] = a[left];
hole = left;
}
a[hole] = key;
//递归---小区间优化--小区间直接使用插入排序
if (end - begin + 1 > 10)
{
QuickSort2(a, begin, hole - 1);
QuickSort2(a, hole + 1, end);
}
else
{
InsertSort(a + begin, end - begin + 1);
}
}五、快速排序-前后指针法:
5.1-思路:
快速排序,前后指针法的思路就是:
首先,定义一个prev=left ; cur=left+1。这里我们实现的操作:
1.cur找到比key小的值,++prove, cur和prev位置的数调换,然后++cur。
2.cur找到比key大的值,++cur。
说明:
1.prev要么紧跟着cur(prev下一个位置就是cur)。
2.prev跟cur中间隔着一段比key大的值。
就这样,按上述思想进入循环知道,直到cur走到数组末端的下一个位置为止,接下来我们要实行的操作就是将keyi位置的值(key)与prev位置的值交换。这样排完一趟后,我们能将大于key的数分布在右边,小于key的数分布在左边,最后,我们只需要按照这个思路递归下去,就实现快速排序啦。
注意:在递归时,如果出现left>=right的情况下,我们就需要返回,否则就会死循环。
5.2-过程图:

5.3-代码:
//前后指针法
void QuickSort3(int* a, int left, int right) //快速排序---时间复杂度(O(N^logN))
{
if (left>=right)
return;
int begin = left;
int end = right;
//直接选取法
//int keyi = left;
//随机选keyi
//int randi = left + (rand() % (right - left));
//Swap(&a[randi], &a[left]);
//int keyi = left;
//三数取中
int midi = GetMidNumi(a, left, right);
if (midi != left)
Swap(&a[midi], &a[left]);
int keyi = left;
int prev= left;
int cur = left + 1;
while (cur<=right)
{
if(a[cur]<a[keyi]&&++prev!=cur)
Swap(&a[cur], &a[prev]);
cur++;
}
Swap(&a[keyi], &a[prev]);
keyi = prev;
//递归---小区间优化--小区间直接使用插入排序
if (end - begin + 1 > 10)
{
QuickSort3(a, begin, keyi - 1);
QuickSort3(a, keyi + 1, end);
}
else
{
InsertSort(a + begin, end - begin + 1);
}
}六、递归的问题与优化:
6.1-递归的问题:
1.效率问题(略有影响)。
2.深度太深时会栈溢出。
递归过程图:

6.2-小区间优化:
小区间优化的思想就是:
将递归的最后几层,也就是基本有序的小区间,采用直接插入排序的方法,不再采用递归的方式,这样能够减少递归时所开辟栈。
因为,递归栈的开辟相当于二叉树,而二叉树的最后一层相当于总数的一半,如果把最后一层省掉,也就是省去了递归所需开辟栈的大概50%的空间。
所以,我们可以通过小区间优化来减少栈的开辟,在不影响时间复杂度的情况下,也减小了深度太深时会栈溢出的问题。
6.3-小区间优化代码:
//递归---小区间优化--小区间直接使用插入排序
if (end - begin + 1 > 10)
{
QuickSort3(a, begin, keyi - 1);
QuickSort3(a, keyi + 1, end);
}
else
{
InsertSort(a + begin, end - begin + 1);
}七、递归改非递归:
由上述可知,通过递归实现快排,具有一定的弊端,也就是栈溢出,所以这里我们可以采取将递归改成非递归的方式来实现快速排序
7.1-方式:
1.直接改成循环。
2.使用栈辅助改成循环。
通过上述代码可观察发现,递归改非递归的第一种方式,我们是实现不了的,所以我们这里需要借助栈来辅助将递归改成循环。
7.2-思路:
这里的思路就是将递归时的左右区间,存入栈中。然后在循环的过程中,我们只需将区间值出站即可。
注意:栈的原理是后进先出。
7.3-代码:
#include "Stack.h"
//递归改非递归
void QuickSortNonR(int* a, int left, int right) //快速排序---时间复杂度(O(N^logN))
{
ST ps;
STInit(&ps);
STpush(&ps, right); //入栈
STpush(&ps, left); //入栈
while (!STEmpty(&ps))
{
int begin= STTop(&ps); //取栈顶元素
STPop(&ps); //出栈
int end = STTop(&ps); //取栈顶元素
STPop(&ps); //出栈
int midi = GetMidNumi(a, begin, end);
if (midi != begin)
Swap(&a[midi], &a[begin]);
int keyi = begin;
int prev = begin;
int cur = begin + 1;
while (cur <= end)
{
if (a[cur] < a[keyi] && ++prev != cur)
Swap(&a[cur], &a[prev]);
cur++;
}
Swap(&a[keyi], &a[prev]);
keyi = prev;
if (keyi + 1 < end)
{
STpush(&ps, end); //入栈
STpush(&ps, keyi + 1); //入栈
}
if (keyi - 1 > begin)
{
STpush(&ps, keyi - 1); //入栈
STpush(&ps, begin); //入栈
}
}
for (int i = 0; i <=right; i++)
{
printf("%d ", a[i]);
}
printf("\n");
STDestory(&ps);
}
7.4-栈的代码:
#pragma once
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void STInit(ST* ps); //初始化
void STDestory(ST* ps); //释放销毁
void STpush(ST* ps, STDataType x); //入栈
void STPop(ST* ps); //出栈
int STSize(ST* ps); //栈中元素个数
bool STEmpty(ST* ps); //判断栈空
STDataType STTop(ST* ps); //栈顶元素
#define _CRT_SECURE_NO_WARNINGS 1
#include "Stack.h"
void STInit(ST* ps) //初始化
{
assert(ps);
ps->a = (STDataType*)malloc(sizeof(STDataType) * 4);
if (ps->a == NULL)
{
perror("malloc");
return;
}
ps->capacity = 4;
ps->top = 0; //top是栈顶元素的下一个位置
//ps->top=-1 //top是栈顶元素位置
}
void STDestory(ST* ps) //释放销毁
{
assert(ps);
ps->top = 0;
ps->capacity = 0;
free(ps->a);
ps->a = NULL;
}
void STpush(ST* ps, STDataType x) //入栈
{
assert(ps);
if (ps->top == ps->capacity)
{
STDataType* tem = (STDataType*)realloc(ps->a, sizeof(STDataType) * ps->capacity * 2);
if (tem == NULL)
{
perror("realloc");
return;
}
ps->a = tem;
ps->capacity *= 2;
}
ps->a[ps->top] = x;
ps->top++;
}
void STPop(ST* ps) //出栈
{
assert(ps);
assert(!STEmpty(ps));
ps->top--;
}
int STSize(ST* ps) //栈中元素个数
{
assert(ps);
return ps->top;
}
bool STEmpty(ST* ps) //判断栈空
{
assert(ps);
return ps->top == 0;
}
STDataType STTop(ST* ps) //返回栈顶元素
{
assert(ps);
assert(!STEmpty(ps));
return ps->a[ps->top - 1];
}
八、结语:
上述内容,即是我个人对数据结构排序中快速排序的个人见解以及自我实现。若有大佬发现哪里有问题可以私信或评论指教一下我这个小萌新。非常感谢各位友友们的点赞,关注,收藏与支持,我会更加努力的学习编程语言,还望各位多多关照,让我们一起进步吧!