最近博主有一些elasticsearch的工作,所以更新的慢了些,现在就教大家快速入门,并对一些基本的查询、更新需求做一下示例,废话不多说开始:
1. ES快速上手
es下载:[https://elasticsearch.cn/download/]()这里关于es所需要的链接基本都有,可以快速下载使用
当你解压好了归档文件之后,Elasticsearch 已经准备好运行了
1 cd elasticsearch-<version> 2 ./bin/elasticsearch
es默认端口9200;transport端口是9300;transport端口主要用来java客户端操作,启动成功后,我们来安装一下kibana界面操作es的工具,也可以下载header,但是kibana界面比较友好并且最后部署ELK的时候也需要该工具,所以博主就直接安装kibana了
kibana下载:[https://elasticsearch.cn/download/]()还是跟es一样的链接,下载后解压并编辑config目录下编辑kibana.yml文件,主要配置如下:
1 server.port: 15601
1 server.host: "0.0.0.0"
1 elasticsearch.hosts: ["http://localhost:9200"]
只需要修改这几处配置就可以,前提是kibana的版本必须与es的版本是相同的,否则会包很多错误,并且启动失败,Linux启动时不能使用root用户启动,必须自己添加个人用户才可以,命令如下:
添加用户: 1 useradd testuser
设置密码: 1 passwd testuser
将我们的文件夹用户权限改变一下要不然启动时候老是提示没有权限: 1 chown -R testuser:testuser kibana
现在进入我们kibana的文件夹,以testuser启动kibana: 1 /bin/kibana
访问地址:http://localhost:15601
当看到这里的时候就已经OK了,我们终于可以开始使用es了。
我就不介绍es是干啥用的了,es具有分片的概念,分为主分片和副本分片,创建索引的时候一旦设置副本分片,必须有大于等于2台的机器,每个机器都有es,es之间的交互,需要自己在配置文件中作修改,否则不配置,永远只是单机,并且主分片在建索引的时候必须考虑清楚减多少个主分片,因为以后如果需要修改主分片,必须重新创建索引,你添加或则减少一个主分片,es往分片中存放数据的时候都会变,但是副本分片不一样,因为他是数据冗余的,一旦主分片宕机,副本会当选主分片,并且是要主分片存在,副本没有也可以,副本的作用就是提高数据的吞吐量。好了,开始实战:
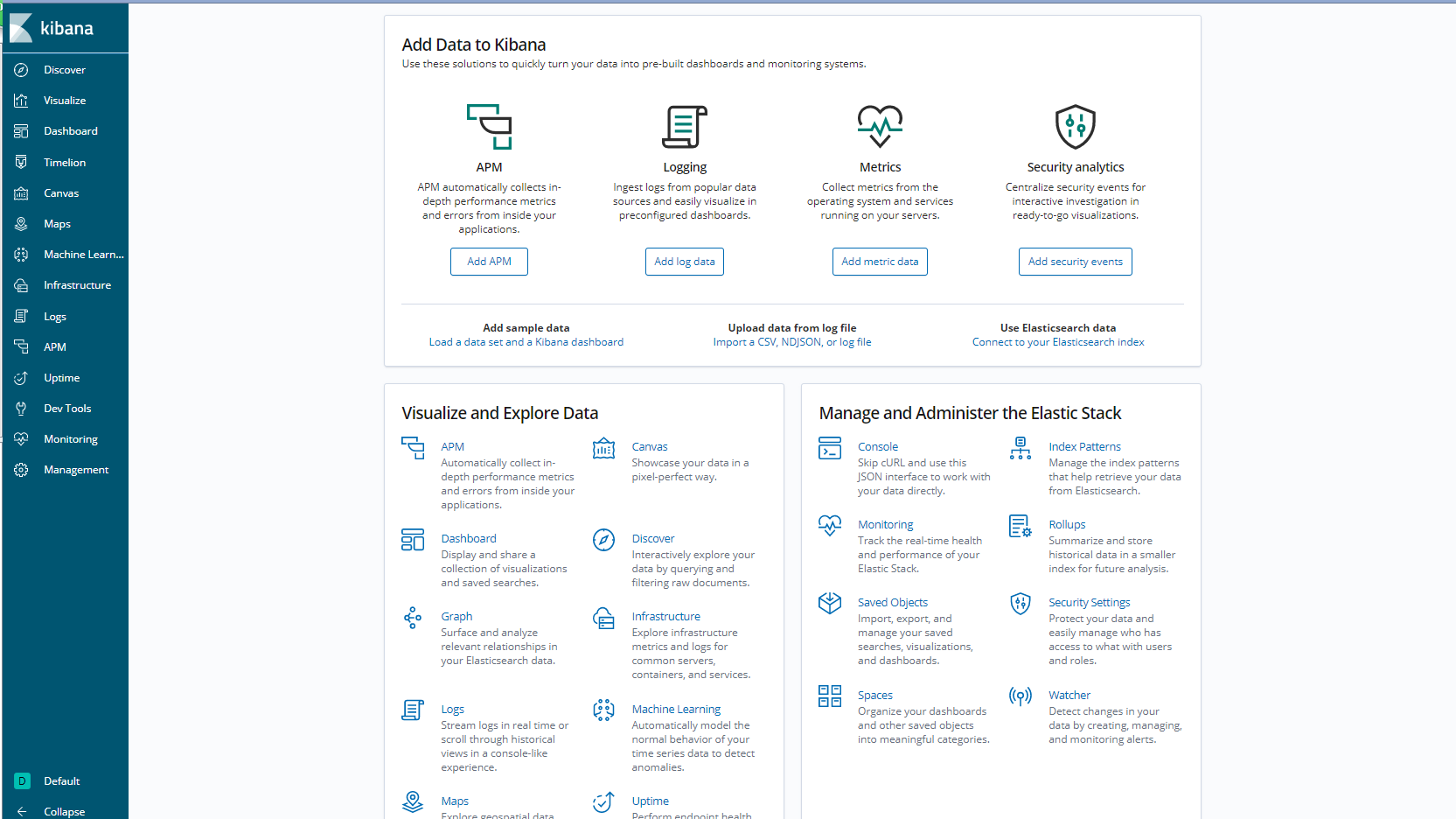
点击kibana的Dev Tools按钮,就可以在面板里写语句操作索引了:
建立索引:shards主分片 replicas副本分片设置的数量,看你有几台机器-1
PUT /test
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"age": {
"type":"integer"
}
}
}
}
}
建立mappings做好字段类型,并且text类型中使用分词器,不要使用默认的分词器,默认的分词器一个汉字分一个,查询出来基本没啥价值,中文分词器是ik,可以上网搜一下下载到es里面。
大家上过语文课,都知道语句有歧义问题,就比如武汉市长江大桥,可以断成武汉市长、江大桥;武汉市、长江大桥;这就是分词器如何切分的问题,所以es有关键字查询term,进行完全匹配,不进行分词器query匹配,除了这些,中文还有同义词一说,比如苹果水果与苹果手机,大家搜索的时候基本都是输入苹果,但是出来的却是苹果手机,水果很少,这就是因为es也可以做同义词查询。但是需要配置同义词文件,具体操作可以自行上网解决,主要就是创建索引的时候,使用自己在config中编辑的文本文件,该文件中有自己要使用到的同义词,比如:iPhone,苹果手机;
我们现在再来进行实战开发,本人接触的是使用ElasticsearchRestTemplate进行开发,该类基本含括了大部分需求开发查询。下面开始举例:
搜索查询:
1 String[] includes = new String[] {
2 "paperBaseId"
3 ,"auditInfoStatus"
4 };
5 SourceFilter sourceFilter = new FetchSourceFilterBuilder().withIncludes(includes).build();
6 SearchQuery searchQuery = new NativeSearchQueryBuilder()
7 .withSourceFilter(sourceFilter)
8 // 添加查询条件
9 .withQuery(QueryBuilders.termsQuery("paperBaseId",paperBaseId))
10 .build();
11 List<EsPaperBase> esPaperBaseList = elasticsearchRestTemplate.queryForList(searchQuery,EsPaperBase.class);
1 //单索引匹配更新
2 Map<String, Object> params = new HashMap<String, Object>();
3 params.put("flag", deleteFlag);
4 //ctx._source即为该索引本身
5 String code = "ctx._source.deleteFlag=params.flag;";
6 ScriptType type = ScriptType.INLINE;
7 //使用脚本进行更新字段值
8 Script script = new Script(type, Script.DEFAULT_SCRIPT_LANG, code, params);
9
10 UpdateByQueryRequest updateByQueryRequest = new UpdateByQueryRequest();
11 updateByQueryRequest.indices("exam_information");//设置索引
12 updateByQueryRequest.setDocTypes("doc");//设置文档,固定doc
13 updateByQueryRequest.setQuery(QueryBuilders.termsQuery("paperBaseId", paperBaseId));//设置查询
14 updateByQueryRequest.setScript(script);//如果有脚本,则添加
15 updateByQueryRequest.setConflicts("proceed"); // 设置版本冲突时继续
16 updateByQueryRequest.setRefresh(true);//请求结束后,对我们写入的索引进行调用刷新
17 this.elasticsearchTemplate.getClient().updateByQuery(updateByQueryRequest, RequestOptions.DEFAULT);//进行更新
1 //多索引匹配批量更新
2 Map<String,Object> updateMap = new HashMap<>();
3 updateMap.put("deleteFlag",deleteFlag);
4 updateMap.put("lastUpdateTime",currDatetime);
5 UpdateRequest doc = new UpdateRequest().doc(updateMap);
6 List<UpdateQuery> updateQuerys = new ArrayList<>();
7 //生成批量更新操作
8 paperBaseId.stream().forEach(id ->{
9 UpdateQuery build = new UpdateQueryBuilder()
10 .withUpdateRequest(doc)
11 .withDoUpsert(true)
12 .withIndexName("paper_base")
13 .withType("doc")
14 .withId(id).build();
15 updateQuerys.add(build);
16 });
17 elasticsearchTemplate.bulkUpdate(updateQuerys,BulkOptions.builder().withRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE).build());
18
1 //查询操作
2 MatchQueryBuilder lastUpdateUser = QueryBuilders.matchQuery("personId", userId);
3 MatchQueryBuilder deleteflag = QueryBuilders.matchQuery("deleteFlag", BaseEntity.DEL_FLAG_DELETE);
4 //创建bool多条件查询
5 BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
6 BoolQueryBuilder mustQuery = boolQueryBuilder.must(lastUpdateUser).must(deleteflag);
7 //嵌套索引,需要使用nest查询
8 mustQuery.must(QueryBuilders.nestedQuery("entityNodes", QueryBuilders.termQuery("entityNodes.node_type", recyclePaperDTO.getNodeType()), ScoreMode.None));
9 //可以使用should查询,不是必需条件
10 BoolQueryBuilder nodeQueryBuilder = QueryBuilders.boolQuery();
11 nodeQueryBuilder.should(QueryBuilders.nestedQuery("entityNodes", QueryBuilders.wildcardQuery("entityNodes.parent_ids", "*," + recyclePaperDTO.getNodeId() + "*"), ScoreMode.None));
12 nodeQueryBuilder.should(......);
13 mustQuery.must(nodeQueryBuilder);
14 //查询使用排序
15 SortBuilder order = new FieldSortBuilder("lastUpdateTime").order(SortOrder.DESC);
16 //可以使用高亮显示,就是html标签
17 HighlightBuilder highlightBuilder = new HighlightBuilder();
18 highlightBuilder.preTags("<span class='highlighted'>")
19 .postTags(</span>)
20 .field("paperBaseName");//哪个字段高亮
21 //使用分页查询
22 SearchQuery nativeSearchQueryBuilder = new NativeSearchQueryBuilder()
23 .withQuery(mustQuery).withSort(order).withHighlightBuilder(highlightBuilder)
24 .withPageable(PageRequest.of(recyclePaperDTO.getPageNum()-1, recyclePaperDTO.getPageSize())).build();
25 //进行查询,entityMapper使用默认的也可,EsPaperBase.class是需要自己映射的查询类
26 elasticsearchTemplate.queryForPage(nativeSearchQueryBuilder, EsPaperBase.class, new HighlightResultMapper(entityMapper));
27
1 @Data
2 @Builder
3 @NoArgsConstructor
4 @AllArgsConstructor
5 @Document(indexName = "paper_base", type = "doc")
6 @Setting(settingPath = "/elasticsearch/settings.json")//可设置主分片、副本分片、设置默认停用词等
7 public class EsPaperBase {
8
9 @Id
10 @Field(type = FieldType.Keyword, name = "paperBaseId")
11 private String paperBaseId;
12
13 /**
14 * 试卷名称
15 */
16 @MultiField(mainField = @Field(type = FieldType.Text, analyzer = "standard" , name = "paperBaseName"),
17 otherFields = {
18 @InnerField(suffix = "zh", type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart"),
19 @InnerField(suffix = "en", type = FieldType.Text, analyzer = "english"),
20 })
21 private String paperBaseName;
22
23 /**
24 * 共享级别名,可以使用分词器查询,模糊匹配
25 */
26 @Field(type = FieldType.Text, name = "shareLevelName")
27 private String shareLevelName;
28
29
30 /**
31 * 创建人,不可使用分词器查询,精准匹配
32 */
33 @Field(type = FieldType.Keyword, name = "personId")
34 private String personId;
35
36
37 /**
38 * 创建时间
39 */
40 @Field(type = FieldType.Date, name = "createtime", format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
41 private String createtime;
42
43 /**
44 * 更新时间
45 */
46 @Field(type = FieldType.Date, name = "lastUpdateTime", format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
47 private String lastUpdateTime;
48
49 /**
50 * 删除标识 0:未删除,1:已删除
51 */
52 @Field(type = FieldType.Keyword, name = "deleteFlag")
53 private String deleteFlag;
54 /**
55 * 试卷推荐,内嵌字段
56 */
57 @Field(type=FieldType.Nested,name="paperRecommends")
58 private List<EsPaperRecommend> paperRecommends;
59
60 ......
61 }
1 {//setting.json
2 "index": {
3 "number_of_shards": "5",
4 "number_of_replicas": "2",
5 "refresh_interval": "1s",
6 "max_rescore_window": 10000000
7 },
8 "analysis": {
9 "filter": {
10 "spanish_stop": {
11 "type": "stop",
12 "stopwords": [ "si", "esta", "el", "la" ]
13 },
14 "light_spanish": {
15 "type": "stemmer",
16 "language": "light_spanish"
17 }
18 },
19 "analyzer": {
20 "my_spanish": {
21 "tokenizer": "spanish",
22 "filter": [ //顺序很重要
23 "lowercase",
24 "asciifolding",
25 "spanish_stop",
26 "light_spanish"
27 ]
28 }
29 }
30 }
31 }
现在很多公司基本使用分布式架构应用,公司每个应用模块都有好几台机器,看日志问题也就衍生而来,我们最笨的方法就是每个服务器后台都打开进行查看,效率低下,此时,我们就可以使用es、kibana、logstash;简称ELK进行查看分布式日志系统,但是本文不会进行安装logstash进行演示,因为只做日志查询的需求,我们使用ELK的变种EFK即可,filebeat轻量级做日志收集即可,最主要的就是看我们如何进行配置,然后使用kibana进行查询日志。
安装完logstash后,解压在config中新建my-logstash.conf,该配置中注意三大块,input、filter、output;其中input是作为吸取日志的以.log为后缀的日志文件,filter是过滤配置,不用管,output则是导入到哪个elasticsearch中;配置如下:
1 input {
2 file {
3 type => "log"
4 path => ["/apps/svr/server/*/log.file"]
5 start_position => "end"
6 ignore_older => 0
7 codec=> multiline {
8 pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}"
9 negate => true
10 auto_flush_interval => 5
11 what => "previous"
12 }
13 }
14 beats {
15 port => 5044
16 }
17 }
18 output {
19 if [type] == "log" {
20 elasticsearch {
21 hosts => ["http://127.0.0.1:19200"]
22 index => "logstash-%{+YYYY.MM}"
23 #user => es
24 #password => es2018
25 }
26 }
27 }
如果自己动手配置的话,最好自己手动输入,不要复制粘贴,很有可能会有特殊字符出现导致启动失败;启动命令:./bin/logstah -f my-logstash.conf
最终我们就可以这样使用kibana进行查询日志的操作了。简单的基本应用就到此为止了,工作中基础的应用是没有问题了;