二叉树的遍历是一个数据结构中经常会遇到的知识点, 具体又分为前序, 中序和后序三种.
什么是树?
先来理解一下什么是树, 从一个我们相对熟悉的家谱树(Family Tree)说起吧.
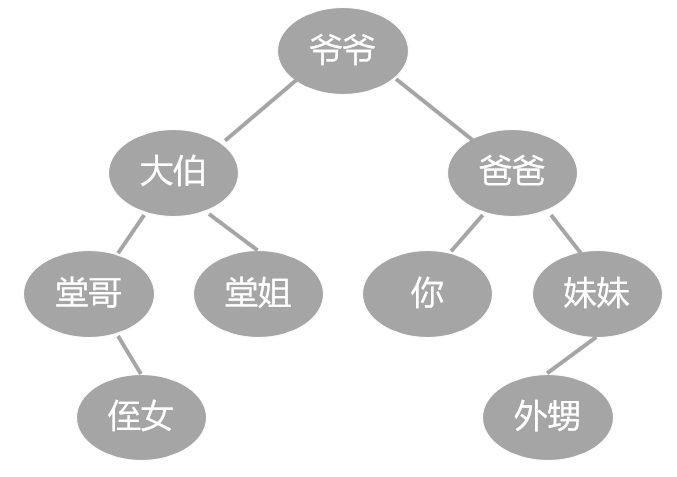
家族的根是爷爷, 然后生了两个娃, 大伯和你爸爸. 继续往下, 有堂哥堂姐, 还有你以及你妹, 等等.
一个家族繁衍下来, 很像一棵树开枝散叶, 当然跟真的树相比, 画出来时通常是倒过来的, 根在上面.
二叉树 VS 多叉树
明白了什么是树, 那什么又是二叉树呢?
首先这里每个人称为树的一个节点. 而每个节点下面呢? 可以看到最多只有两个节点.
可能养三个娃太费劲了, 或者计划生育, 顶多两个葫芦娃, 超生了就罚款, 当然现在应该不会了.
一个节点, 在它之下的节点, 多则两个,少则一个甚至没有, 这就是二叉树.
而如果像下边这样, 大伯之后还有个二伯, 你爸是老三, 那这就不算了.
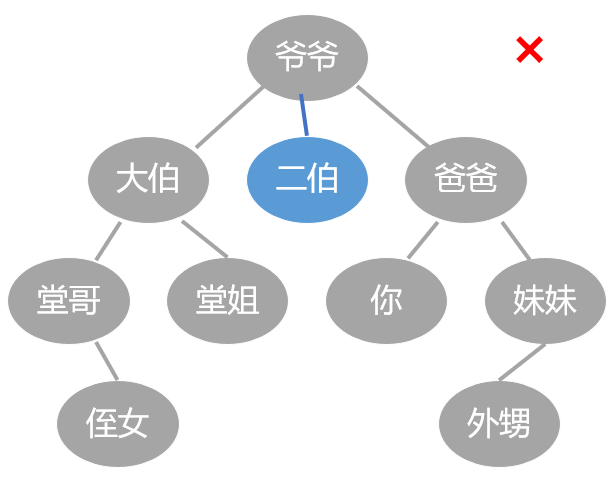
所以前面的图是二叉树, 后面的的则不是.
二叉树的节点(Node)
再来看二叉树的几种节点.
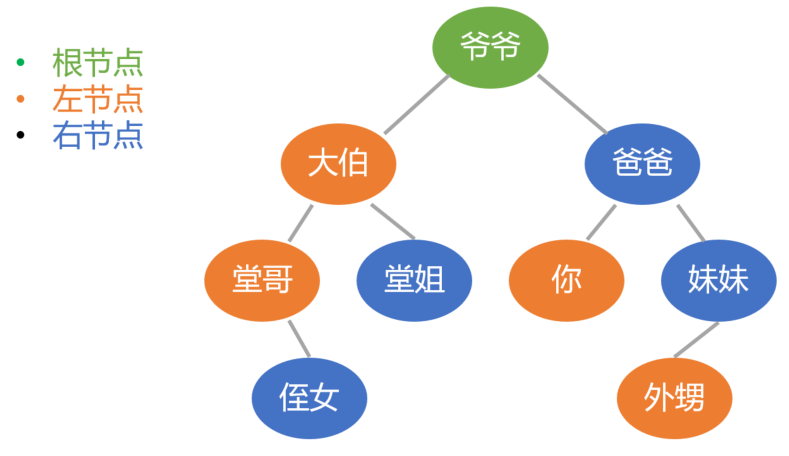
首先爷爷这里叫做 根节点, 老祖宗.
给他一个绿色, 不是帽子啊. 只是为了区分.
然后一个节点下面不是顶多两个节点嘛, 那左边这个呢就叫 左节点, 标成红色.
这里像大伯, 堂哥, 你还有外甥, 不管处在哪个层级或者说辈分也好, 只要在左边的就是左节点.
那其余的自然就是 右节点 了. 用蓝色表示.
二叉树的子树(subtree)
了解了左右节点后, 再来看一个子树的概念.
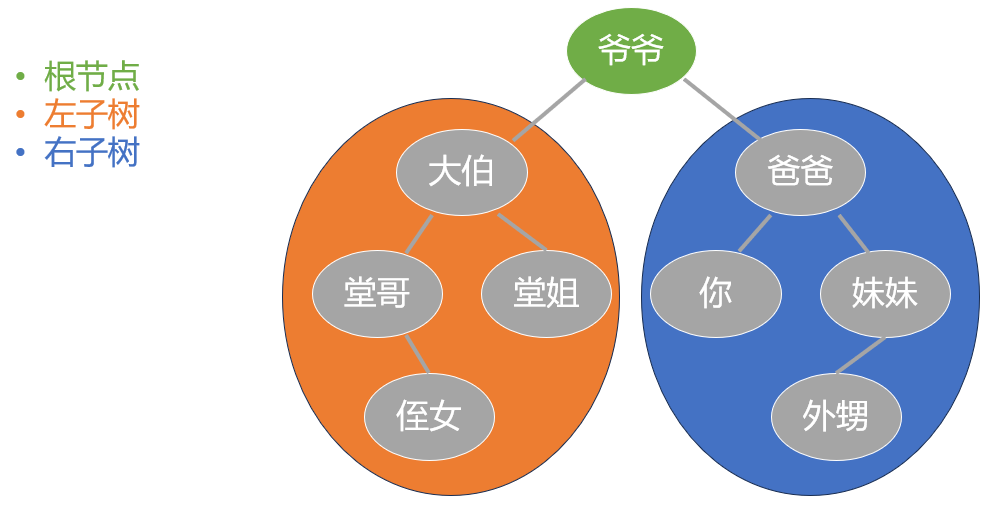
根节点左边这一支呢, 也就是你大伯一家子, 与节点类似, 就叫 左子树, 还是用红色表示.
右边的自然就是 右子树 了, 也就是你爸爸这一家子.
二叉树的遍历(traversal)
有了以上概念后, 再来看遍历. 那什么是遍历呢?
假设来说吧, 有一天你变得很出名, 然后有个好事的记者呢, 就想对你这整个家族的人, 都采访一下, 挖点奇闻轶事或者你小时候的糗事出来.
这种把一个树上全部节点都访问一次的行为, 就是遍历, 都历经一遍.
既然都要访问, 那现在的问题就是, 这里这么多人, 到底按什么顺序去访问.
对于二叉树, 深度优先的遍历有这么三种:
- 前序遍历(preorder)
- 中序遍历(inorder)
- 后序遍历(postorder)
二叉树的前序遍历
先来看什么是前序遍历.
它的大规则或者说大的方向是先访问根节点, 然后是左子树, 最后是右子树. 简称 “根-左-右”.
先采访爷爷. 然后是大伯一家子, 最后到你家.
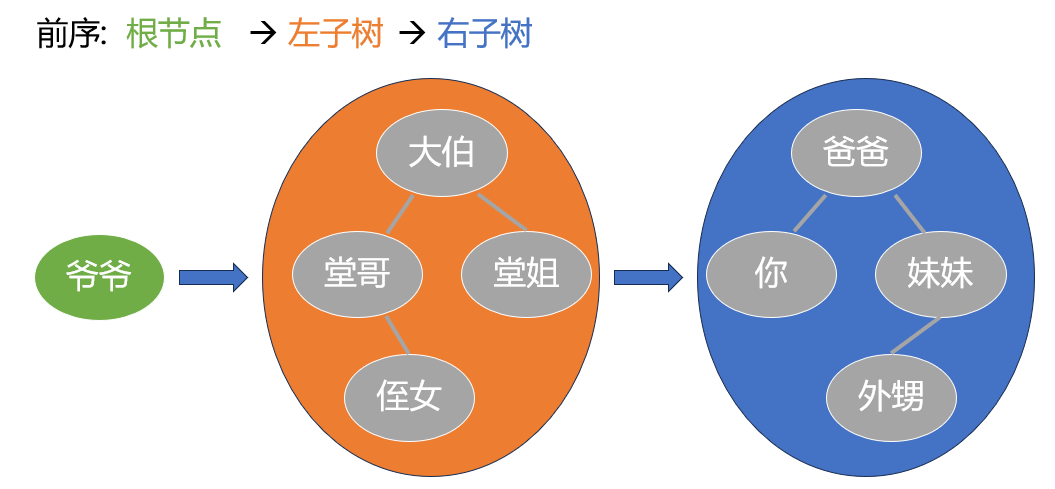
当然这两家子下面又还有很多人, 到底又先采访谁的小规则我们晚点再说.
先说另一个问题, 不知道你想过没有, 为什么大规则要这样安排呢?
二叉树遍历的就近原则
这里介绍二叉树遍历的一个可以叫做就近的原则吧.
假设来说, 这是个地图, 爷爷在江西, 然后子女通常围绕父母就近开枝散叶, 比如大伯就去了临近的广东, 而你爸爸则到了旁边的福建, 这是很自然的.
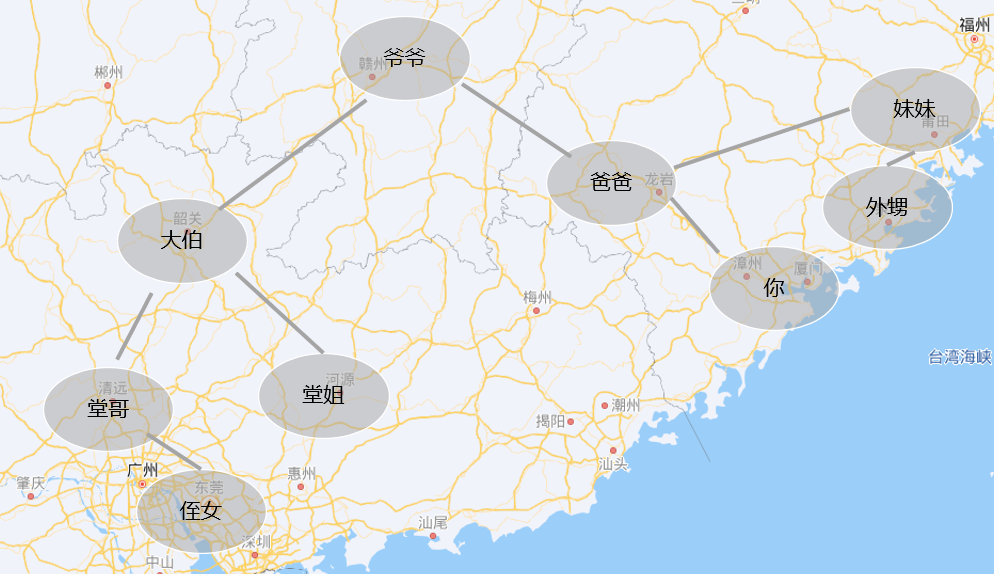
再往下呢, 也是类似的, 堂哥堂姐们就随着大伯在广东混了, 而你和你妹自然就在福建, 也是很合理的.
那回到记者采访的问题上, 假如这个记者刚采访完广东的大伯, 又大老远跑到福建去采访你爸爸,
左右横跳, 飞来飞去, 好不容易挣点稿费, 都交给铁道部或者民航局了, 不划算.
另外, 我们可能注意到一点, 大伯和你爸和爷爷之间都有一条线连接.
想象这是一棵树, 而记者则是一只蚂蚁, 他现在在大伯这个节点上, 他要去你爸那边, 其实他要先沿着左边的路爬回到爷爷这个根节点, 再顺着右边的树枝才能爬到你爸的节点上.
大伯和你爸之间其实是没有连线的. 如果有的话, 这就不是树形结构而是图形结构了.
左子树的前序遍历
明白了这个就近原则后, 我们继续看这个左子树里面的节点要按什么顺序去访问.
前面说了大规则是 根-左-右, 然后说子树里面要确定一个小规则. 其实呢, 并不存在所谓的小规则.
当把左子树单拎出来, 其实它还是一颗树. 因此依然可以按照 “根-左-右” 的规则.
先访问根节点, 大伯;
之后是左子树, 堂哥一家子;
最后是右子树, 堂姐, 或者说右节点, 目前就她一个, 可能还没出嫁或者还没生娃.
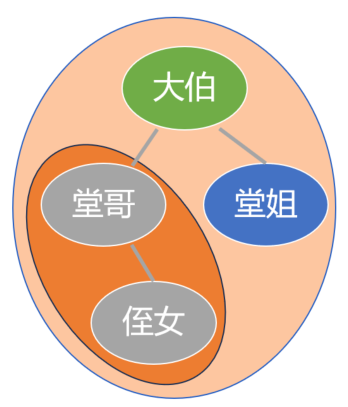
这里利用了子树和整棵树之间的一种自相似特性. 想象一下, 把一棵树的一个树枝掰断了, 插在地上, 它看上去是不是就像一颗小树?
儿子跟老子长得一样, 这就是自相似. 因为存在这种相似性, 就可以重复使用同一个规则, 而不需要针对各个子部分又发明新的规则, 这就是递归处理.
左子树的展开
那么将左子树展开, 爷爷之后是大伯, 然后是堂哥一家, 这个需要继续展开;
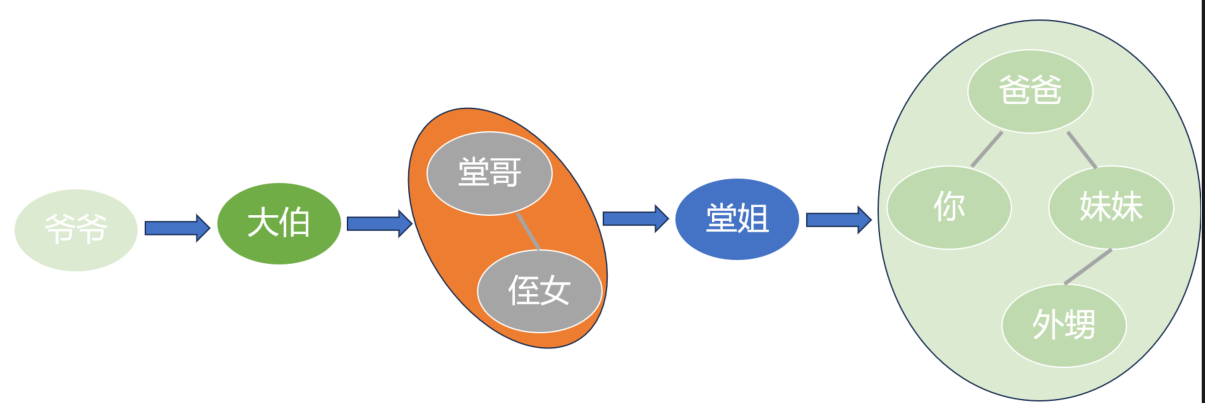
然后是堂姐, 最后到你家, 也是需要进一步展开.
左子树的继续展开
继续展开堂哥一家, 依然是按照 “根-左-右” 的顺序.
先是堂哥, 然后左子树, 这个大侄子这里没有, 可能因为他太调皮捣蛋了, 堂哥不要他, 让别人抱养走了;
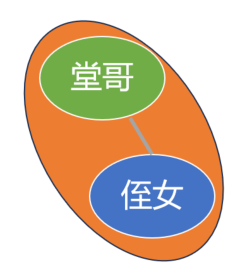
左子树或者左节点没有就跳过;
最后是右子树, 你侄女, 或者说右节点, 小学刚毕业呢, 还没到合法生娃的年纪, 下面没人了, 所以展开到她这里也结束了.
左子树的完全展开
这样就完全确定了大伯一家子的采访顺序.

大伯之后是堂哥, 再之后是侄女, 最后是堂姐.
右子树的展开
左子树展开完了, 再看右子树, 那就简单了, 依然是按照 “根-左-右” 的顺序,
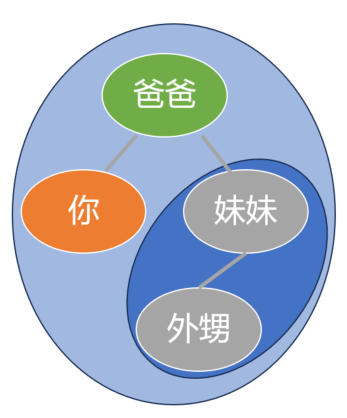
先是爸爸这个根节点; 然后是左子树, 或者说左节点, 也就是你, 光杆司令一个, 就不用继续展开了; 最后是右子树, 妹妹一家, 需要继续展开.
右子树的继续展开
展开后就是这样.
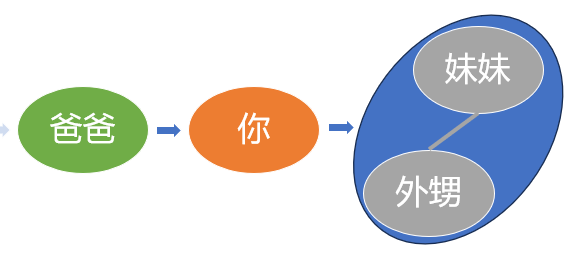
先是根节点爸爸, 其次是左节点你, 最后是右子树, 妹妹一家.
右子树的完全展开
最后妹妹一家再展开. 还是 “根-左-右” 的顺序:
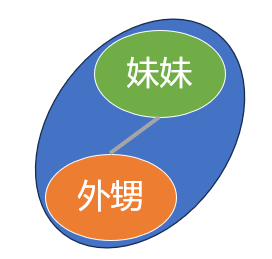
先是根节点, 妹妹; 再到左节点, 你外甥;
然后是右节点, 暂时没有, 还没怀上呢, 或者还没生出来, 还在妈妈肚子里喝羊水呢, 那就也不用管它, 跳过就完了.
至此, 这一大家子人的采访顺序就全部确定了.
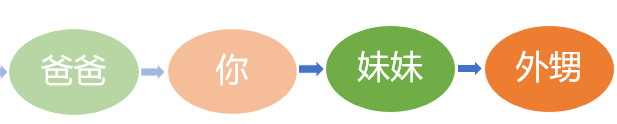
显然, 无论这棵树有多深, 哪怕向天再借500年, 家族不断繁衍, 子又生孙孙又生子, 子又有子子又有孙, 子子孙孙祖宗十八代, 照样可以按照这同一条规则去确定遍历的顺序.
前序遍历的总结
最后, 对前序遍历做个总结.
记住 “根-左-右” 这个顺序. 先是爷爷这个根节点, 然后左子树, 右子树.
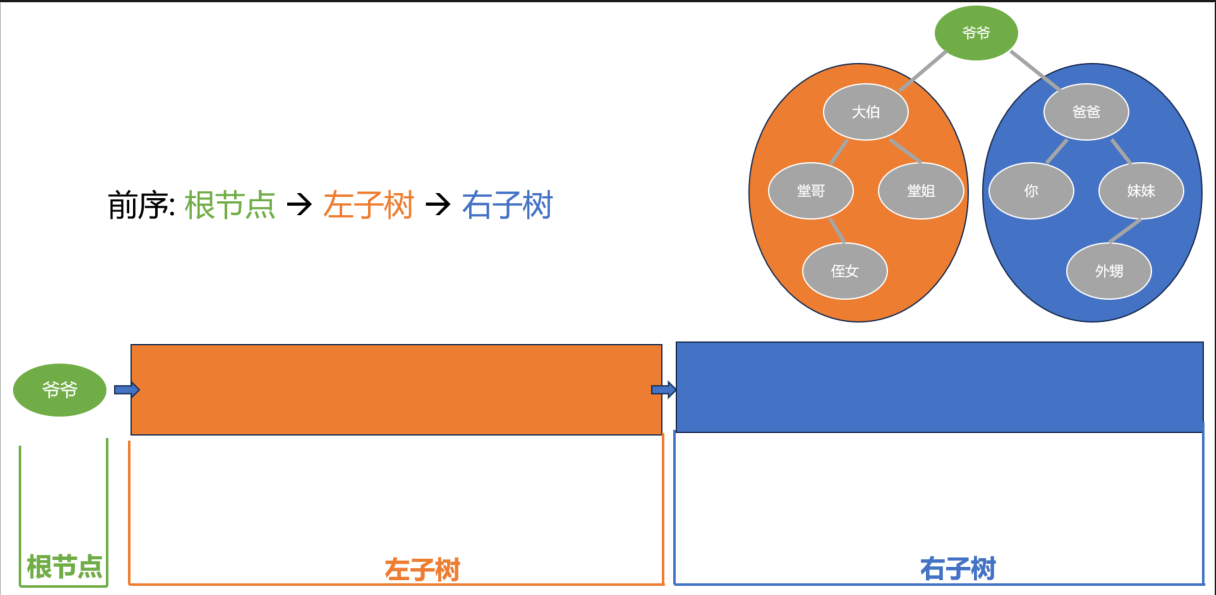
左子树里面, 又继续按照 “根-左-右” 的顺序:
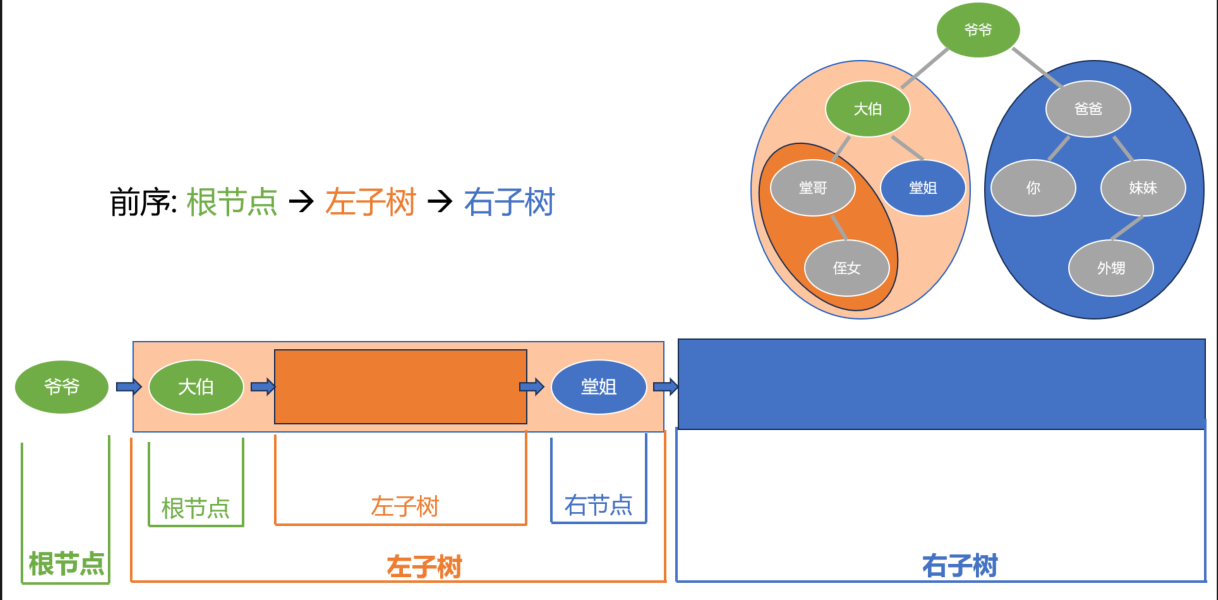
先是大伯这个根节点, 然后左子树, 之后右节点堂姐.
再之后, 堂哥这里, 还是按照 “根-左-右” 的顺序:
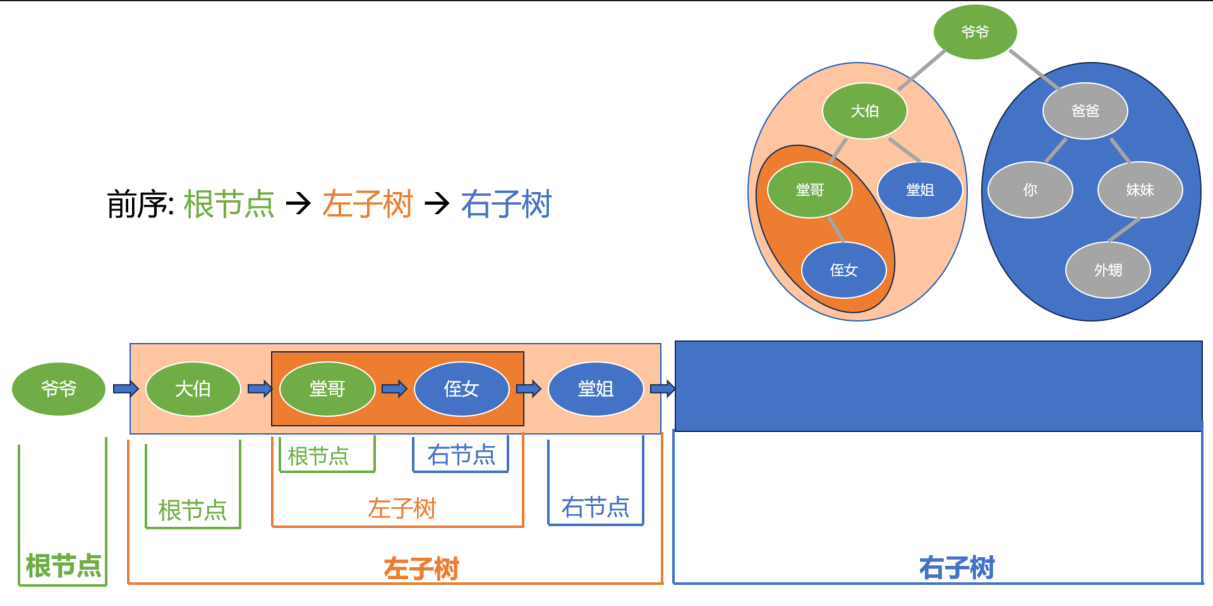
当然这时没有左子树, 那跳过就行了, 先是根节点, 然后右节点.
而右子树呢, 也是按照 “根-左-右, 根-左-右” 的顺序不断递归展开, 最终得到了前序遍历下, 所有节点的访问顺序.
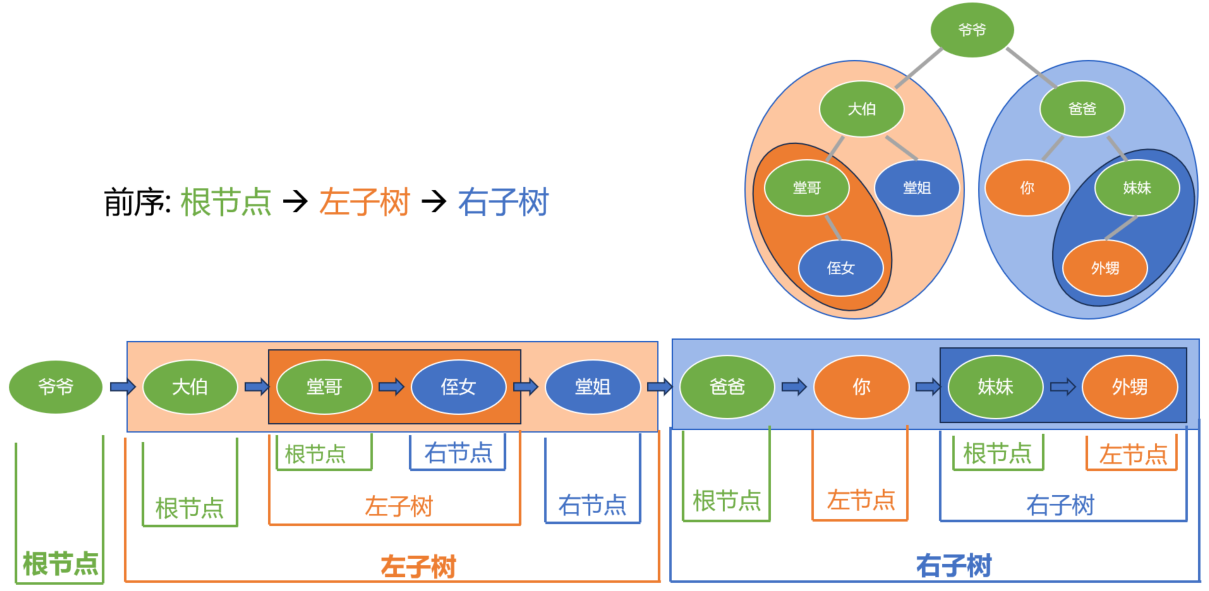
二叉树的中序遍历
明白了前序遍历后, 再来看中序遍历, 就很容易理解了, 唯一的区别是访问顺序.
中序遍历按照 “左-根-右” 的顺序, 根节点在中间.
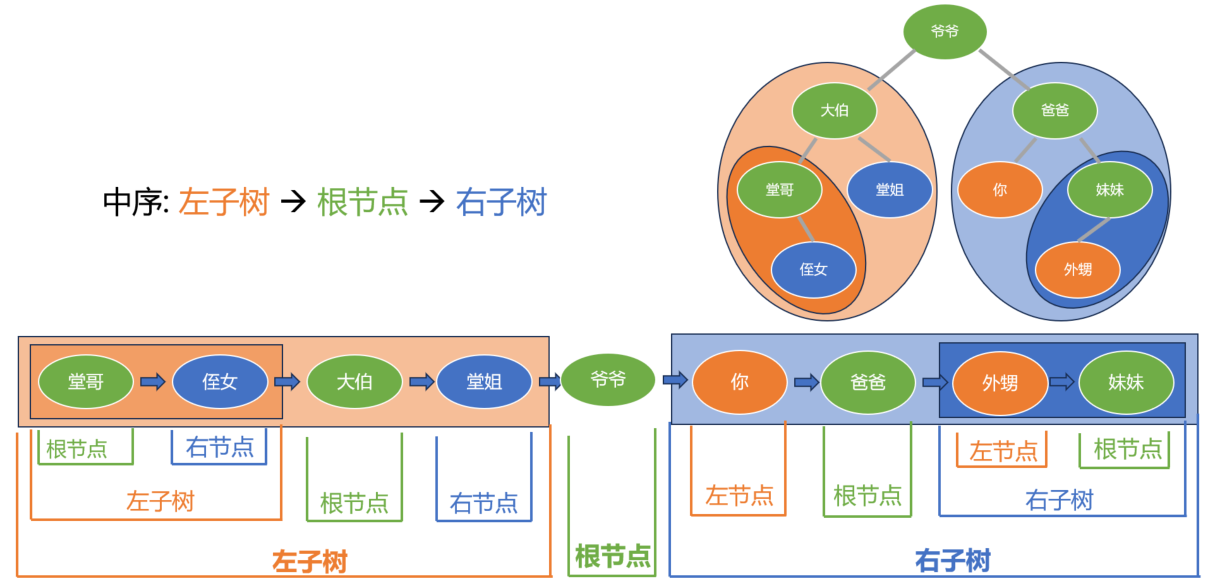
先是左子树, 堂哥一家子这次排在了最前;
然后才到根节点, 爷爷这里, 处于中间;
最后才是右子树, 也是你爸爸一家.
而每一个子部分呢, 递归地按照 “左-根-右” 的顺序展开, 直到完全展开成我们看到的这个顺序.
在这里, 像爷爷, 大伯, 爸爸这些根节点呢, 大概是处在中间, 或者是每个子部分的中间
那么这就是中序遍历, 也叫中根遍历, 根在中间.
二叉树的后序遍历
最后, 来看下后序遍历, 同样的道理, 只是顺序变成了 “左-右-根”, 根在最后.
读者可自己依葫芦画瓢, 尝试一下展开.
最终结果就是这样, 每一子部分都是按照"左-右-根"的顺序不断展开, 最终许多根节点是相对处在后面的.
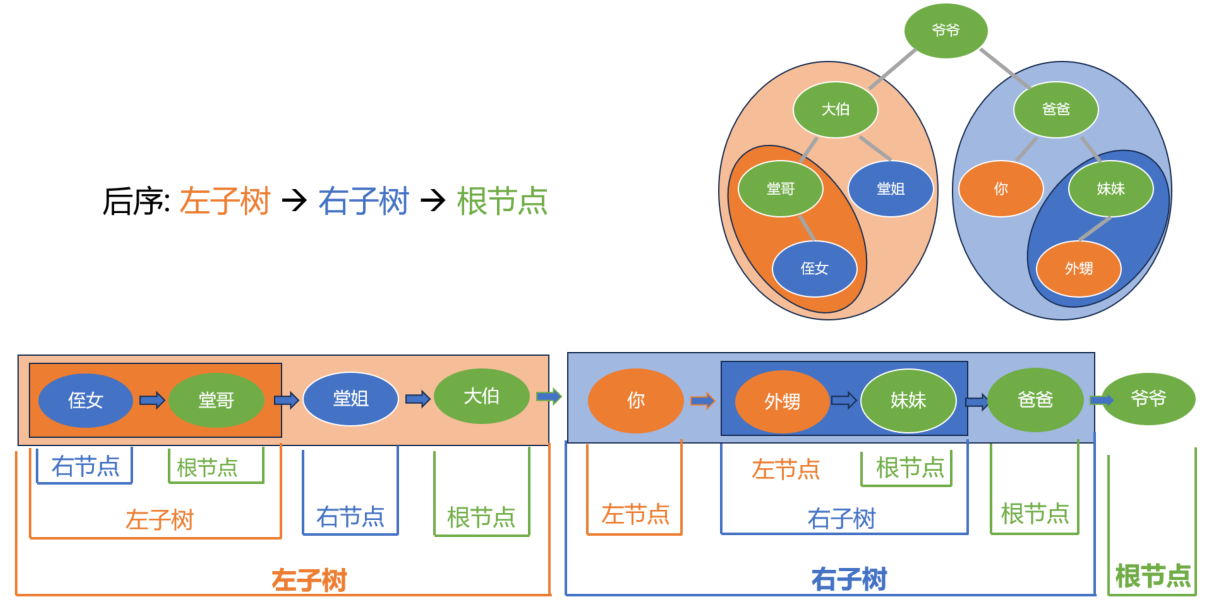
读者可以核对一下自己展开的结果是否正确. 如果有什么疑问, 可以对照着前面的前序和中序遍历好好理解一下, 举一反三, 因为道理都是类似的, 这里就不再展开那些细节了.
如果你得到了正确的访问顺序, 那可以说你已经正确地掌握了这三种遍历形式.
二叉树的遍历总结
最后是对二叉树这三种遍历的一个总结.
- 前序, 又叫 前根遍历, 按照 “根-左-右” 的顺序递归展开;
- 中序, 又叫 中根遍历, 按照 “左-根-右” 的顺序递归展开;
- 后序, 又叫 后根遍历, 按照 “左-右-根” 的顺序递归展开;
所以, 主要区别就在根的位置上.
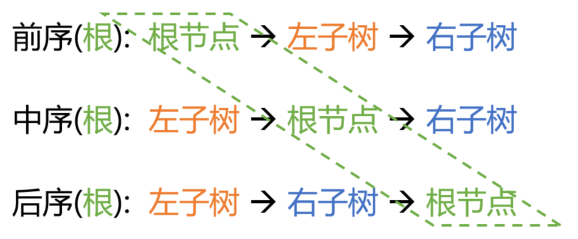
- 首先, 前中后指的就是根的位置.
- 其次, 左右子树则始终是先左后右.
- 最后, 递归应用以上规则直到子树全部展开.
关于二叉树的前序, 中序和后序这三种遍历方式就讲到这里, 谢谢大家.