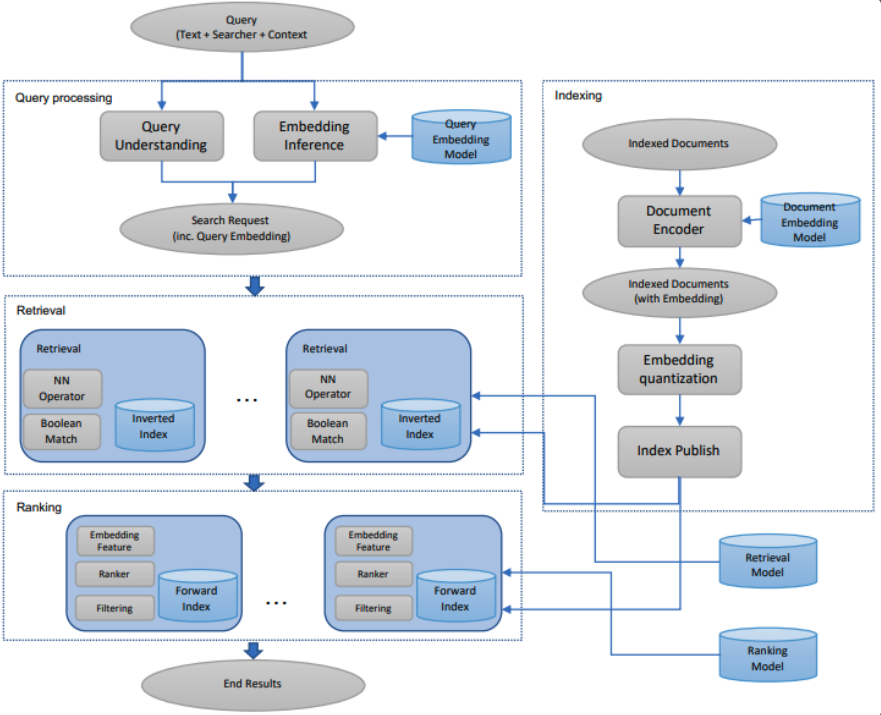
本文最早发表于电子发烧友论坛:【新提醒】【正点原子i.MX93开发板试用连载体验】基于深度学习的语音本地控制 - 正点原子学习小组 - 电子技术论坛 - 广受欢迎的专业电子论坛! (elecfans.com)
接下来就是要尝试训练中文提示词。首先要进行语料采集,这是一个比较耗费人力的事情,通常大公司会有有专人进行语料收集,我只好自己亲自做。这里参考了AliOS Things里面提供的一个录音工具,方便快速录音。对这个工具做了一点修改,原来的代码只能在Linux下运行,现在改成在Windows下也能运行。

import pyaudio
import wave
import random
import time
import os
from IPython import display
#from pydub import AudioSebment
#from pydub.playback import play
#from playsound import playsound
CHUNK = 2
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
SAMPLEWIDTH = 2
RECORD_SECONDS = 1
FILE_FORMAT = '.wav'
RECODER_NAME = 'lk'
#play stream
def play_wav(name, pyaudio):
f = wave.open(name,"rb")
#open stream
play_stream = pyaudio.open(format = p.get_format_from_width(f.getsampwidth()),
channels = f.getnchannels(),
rate = f.getframerate(),
output = True)
#read data
data = f.readframes(CHUNK)
while data:
play_stream.write(data)
data = f.readframes(CHUNK)
#stop stream
play_stream.stop_stream()
play_stream.close()
#close PyAudio
# pyaudio.terminate()
f.close()
def save_wav(name, frames):
wf = wave.open(name, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
def record_wav(duration):
time.sleep(0.2) # 1sec, 0.1sec
print("开始录音,请说话......")
# count = 3
# for i in range(3):
# time.sleep(0.2) # 1sec, 0.1sec
# count -= 1
# print(count)
frames = []
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
for i in range(0, int(RATE * duration / SAMPLEWIDTH)):
data = stream.read(CHUNK, exception_on_overflow = False)
frames.append(data)
#count = 0
#while count < int(RECORD_SECONDS * RATE):
# data = stream.read(CHUNK)
# frames.append(data)
# count += CHUNK
stream.stop_stream()
stream.close()
print("录音结束!")
return frames
# main function
if __name__ == '__main__':
p = pyaudio.PyAudio()
# input('请按回车键开始录制!\n')
# record files
count = 0
for i in range(250):
input('请按回车键开始录制!\n')
print("开始第%d录制!" % count)
hash_name = str(hex(abs(hash(RECODER_NAME + str(random.random()))) % 1000000000)).replace('0x','') \
+ '_nohash_' + str(count) + FILE_FORMAT
rframes = record_wav(1) # record 1 sec
save_wav(hash_name, rframes)
#time.sleep(0.5) # 1sec, 0.1sec
print("录音回放开始!\n")
play_wav(hash_name, p)
print("录音回放结束!\n")
value = input("按‘回车’保存,放弃本条请按‘其他’键并回车!\n")
if (value == ''):
count += 1
print("保存录音成功!")
else:
os.remove(hash_name)
print("已删除本条录音!")
#display.display(display.Audio(hash_name, rate=16000))
#wav = AudioSegment.from_wav(hash_name)
#play(wav)
p.terminate()