前言
今天,我将讨论如何区分美国和全球范围内不断涌现的数据隐私法所涵盖和不涵盖的数据类型。不同类型的数据受到更严格的保护,具体取决于司法管辖区,因此,如果您使用个人数据进行分析或机器学习,了解这一点很重要。

数据类别
PII — 个人身份信息
这通常是指单独使用时可能用于识别特定人员的一条数据。示例可能包括身份证号码,例如用于社会保障、驾驶执照或其他政府身份证的号码。您的全名也可能符合条件,您的完整街道地址、您的照片或您的电话号码也可能符合条件。
如果您曾经参与过人体研究,或者在需要接受数据安全培训的医疗保健等行业工作过,那么您可能对 PII 的概念很熟悉,因为您会经常接触此类信息。然而,这并不是全面数据隐私法所监管数据类型的全部范围。
个人资料或个人信息
根据现代数据隐私法规,您需要关注的更广泛范围通常被称为“个人信息”,其中包括:
- 可以组合在一起以识别特定人的数据点,例如出生日期和姓氏,或出生日期和邮政编码。
- 个人可能认为敏感且需要保密的数据点,可以与其他数据相结合以链接到特定的人
- 这些数据点可能成为歧视等非法待遇的基础,这些数据点可以与其他数据相结合,链接到特定的人
需要注意的一个关键点是,数据必须是个人级别的,并且必须有某种方式将其与单个个体联系起来,这样它才被视为受到法律保护。例如,如果你有一个数据集,其中包含 1000 个人的数据,包括性别和邮政编码,那么除非还包含更多数据,这些数据可以合并缩小到特定个人,否则这不是个人数据。任何给定邮政编码中可能都有足够多的特定性别的人,以至于你无法准确说出你谈论的是 60601 中的哪个女性身份的人。
然而,一旦你开始拥有年龄/出生日期、职业、种族/民族等其他数据,那么你就增加了锁定某个特定人的可能性,因此你的数据变得更加危险,更有可能受到数据隐私法的保护。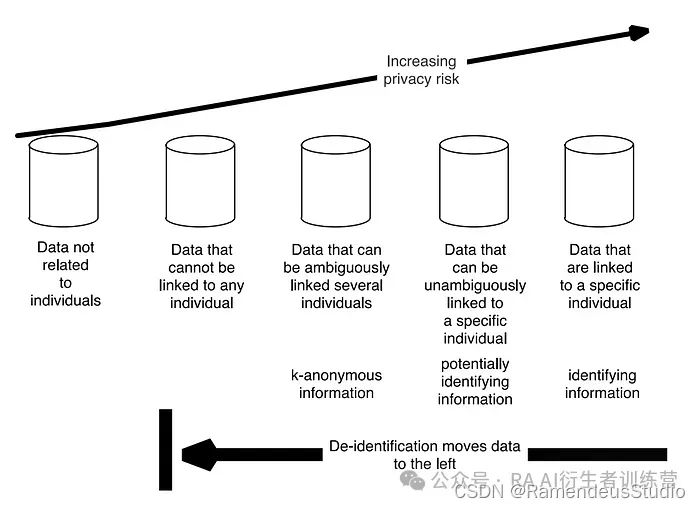
来源:Garfinkel
正如该图所示,数据越容易与个人联系起来,风险就越高。
此外,在大多数司法管辖区中,如果数据已经公开(例如政府的公共记录),那么数据就不会受到保护,可以放心使用而不必担心隐私法。
以这种方式属于数据隐私规则的其他各类数据包括:
- 标识符,例如真实姓名、别名、邮政地址、唯一个人识别符、在线识别符、IP 地址、电子邮件地址、帐户名称、社会安全号码、驾驶执照号码、护照号码或其他类似标识符。
- 受地方/联邦法律保护的分类的特征,例如种族、性别、性取向、宗教等。
- 商业信息,包括个人财产记录、购买、获得或考虑的产品或服务,或其他购买或消费历史或倾向。
- 生物特征信息。
- 互联网或其他电子网络活动信息,包括但不限于浏览历史、搜索历史以及有关消费者与互联网网站、应用程序或广告互动的信息。
- 地理位置数据,即某人曾经去过或当前所在位置的经纬度坐标。
- 音频、电子、视觉、热、嗅觉或类似信息。
- 专业或就业相关信息,例如职称、就业状况、服务年限、资历、前任雇主或薪水/工资。
- 教育信息,前提是该信息不是根据 FERPA 定义的公开的个人身份信息。
- 根据本细分中确定的任何信息得出的推论,创建关于消费者的档案,反映消费者的偏好、特征、心理趋势、倾向、行为、态度、智力、能力和天赋。
采取的行动
基于此,你可以看到,“数据点 X 是否受保护?”并不总是有一个简单的答案——上下文很重要。性别数据是否受保护?明智的答案是肯定的,如果它包含在包含其他信息的数据集中。如果你有关于个人的几行数据,其中只包含性别而没有其他信息,这可能不是一个风险,但大多数时候,当我们进行数据工作时,我们会查看多个特征,如果它们加起来可以识别出一个不同的个体,那么你手中就有个人信息了。
那么,该怎么办呢?处理个人数据时,有几种很好的策略可以最大程度地降低风险。
最小化
一个明智的建议是减少您存储的个人数据量。您保存的关于个人的每一个额外特征或数据点都会增加数据被拼凑起来识别某人的可能性,从而增加数据泄露可能对您的业务和客户造成严重损害的风险。仅存储实现目标所需的数据,不要存储更多数据。
聚合
另一个考虑因素是,您是否真的需要在个体层面查看数据,或者是否可以将数据点分组到更大的粒度。考虑您正在处理的问题,并确定个人是否一定是您感兴趣的单位。如果同样可以按组分析人员,这将大大降低您的风险(假设您在聚合完成后删除任何个人数据)。
去识别化
如果您知道需要在个人层面处理数据,则可以尽可能多地混淆数据,这样就无法通过逆向工程确定所代表的个人。根据我的经验,这通常涉及使用不可逆的哈希值,因为这可以让您保留数据点之间的关系,而这些数据点无法被人类解释,因此建模仍然有效,但无法通过数据追溯到不同的人。但是,您还可以使用许多其他技术,并且有一些很棒的资源可以帮助您了解如何进行去识别化过程,包括NIST 的这份报告。我特别建议开发人员研究使用多媒体(音频/视频/图像)数据时可用的技术,因为这些数据的去识别化过程可能要复杂得多。
风险评估
当您决定 PI 或 PII 对您的项目必不可少时,这构成了比其他选择更高的风险。坐下来思考一下使用这些数据的风险是什么,如何通过最佳实践将其最小化,以及您期望从项目中获得什么回报。有一些很好的资源可以对 AI/ML 项目进行一般风险评估,这些资源可以为您提供指导。如果您无法说服自己/您的同事,您的模型将实现的收益大于风险,那么这个项目可能不值得做。
同意
如果您需要在建模或分析中使用 PI 或 PII,这并非不可能——但您需要确保获得数据中所代表的个人的适当同意,以便将他们的信息用于您的目的。我强烈建议 ML 从业者参与编写提供给客户/用户的同意书语言,以便您确切地知道您有权做什么。否则,您可能会发现自己拥有数据,但没有权利将其用于您的项目——这是最糟糕的选择,因为您拥有的数据会带来风险而没有回报!
数据安全
再次强调,如果您决定需要使用 PI 或 PII,则需要考虑数据安全问题 — 这意味着您应该建立基础设施来保护这些数据免遭泄露、黑客攻击或未经授权的访问。组织中的任何人都不应拥有超出工作所需范围的访问权限,以便最大限度地减少可以看到个人数据的人数,从而降低风险。请咨询您的 IT 和安全团队,获取他们关于您可以实施的最佳实践的建议,并制定计划以防万一。
结论
我在这里分享的一些内容可能显而易见,但我认为在我们继续进行机器学习和数据科学工作时,重新审视个人信息的整个框架仍然很有价值。我知道我有时会开始将数据视为一种资源,而忘记了它如何真正代表个人,这是一种危险的情况,因为你可能会忘记个人数据会带来风险。
然而,风险不仅仅在于使用数据的人——由于法律框架的原因,滥用或草率使用客户数据的企业也面临重大风险。如果企业粗心地处理个人数据,GDPR 和 CCPA 都以巨额罚款的形式进行处罚。也许同样重要的是将其视为道德问题。人们信任您和您的组织,将他们的数据交给他们,应该不惜一切代价避免破坏这种信任。
这并不是说你不能使用个人数据进行机器学习 — 你可以!你只需要小心谨慎并采取必要的措施将风险降至最低。
带回家的要点
- 问问自己,这些数据是否可以与特定的个人联系起来,因为这意味着它受到法律的保护。
- 存储和使用个人数据会给您和您的组织带来风险,因此请权衡这一点与您期望从项目中获得的利益。
- 法规规定您如何处理这些数据,因此请小心谨慎并与您的法律团队沟通以确保合规。
祝你好运!
欢迎你分享你的作品到我们的平台上:www.shxcj.com 或者 www.2img.ai 让更多的人看到你的才华。
创作不易,觉得不错的话,点个赞吧!!!








![[JS]Generator](https://img-blog.csdnimg.cn/img_convert/a196abc46dcf19f8b16884958b8c0f0f.png)