浅谈RLHF---人类反馈强化学习
news2026/2/15 0:16:48

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1926622.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

Android Toast
Toast
Toast是Android常用的简单控件,主要用来进行简短的信息提示,如图1所示。 图1 Toast效果图
Toast的基本用法很简单,不需要设置layout,只需要在程序中调用即可。Toast调用makeText()方法设置需要显示的界面、显示的内容、显…
简洁实用的原创度检测工具AntiPlagiarism NET 4.132
AntiPlagiarism NET是一个适用于Windows的程序,它允许您检查文本的唯一性和从不同Internet来源借用的存在。使用AntiPlagiarism NET,您可以: 将程序用于不同的目的该程序适用于学生、教师、记者、文案作者和其他需要检查其文本或其他作者文本…

SpringBoot实战:多表联查
1. 保存和更新公寓信息
请求数据的结构
Schema(description "公寓信息")
Data
public class ApartmentSubmitVo extends ApartmentInfo {Schema(description"公寓配套id")private List<Long> facilityInfoIds;Schema(description"公寓标签i…
![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 游乐园门票 (200分) - 三语言AC题解(Python/Java/Cpp)](https://i-blog.csdnimg.cn/direct/a5194b8227494fa5bd1455549b1beda3.png)
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 游乐园门票 (200分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 最新华为O…

4000厂商默认账号密码、默认登录凭证汇总.pdf
获取方式:
链接:https://pan.baidu.com/s/1F8ho42HTQhebKURWWVW1BQ?pwdy2u5 提取码:y2u5

C语言 ——— 调试的时候如何查看当前程序的变量信息
目录
调试前/后的调试窗口
编辑
调试窗口 --- 监视
调试窗口 --- 内存
调试窗口 --- 调用堆栈 调试前/后的调试窗口
调试前的调试窗口: 调试前的调试窗口是没有显示的,只有在调试的时候才会有相对应的调试窗口
调试后的调试窗口:…

头歌资源库(31)象棋中马遍历棋盘的问题
一、 问题描述 二、算法思想 这是一个典型的深度优先搜索问题。 首先,我们创建一个mn的棋盘,并初始化所有的点为未访问状态。 然后,我们从(0, 0)位置开始进行深度优先搜索。 在每一步中,我们先标记当前位置为已访问࿰…

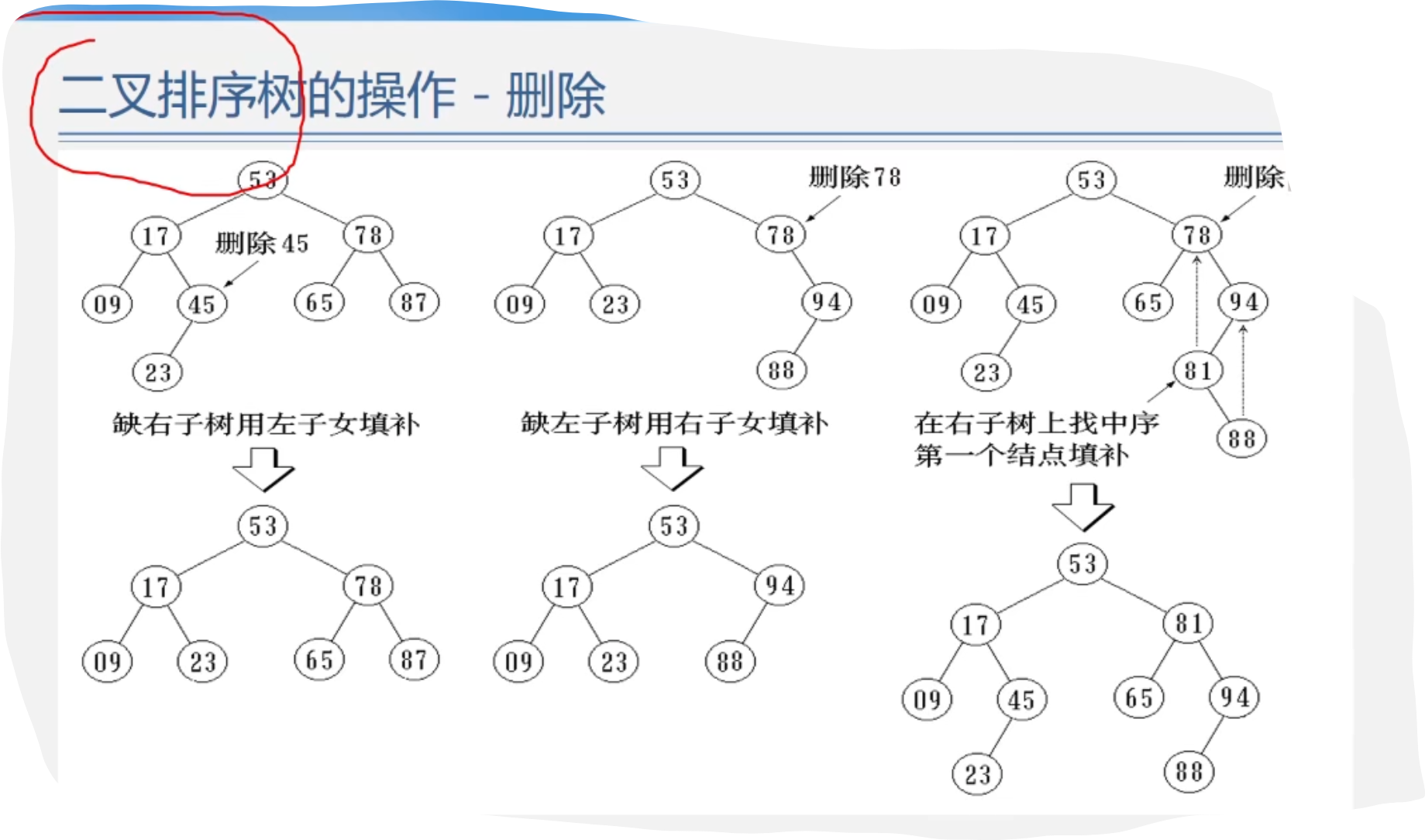
数据结构——查找(线性表的查找与树表的查找)
目录
1.查找
1.查找的基本概念
1.在哪里找? 2.什么查找?
3.查找成功与否?
4.查找的目的是什么?
5.查找表怎么分类?
6.如何评价查找算法?
7.查找的过程中我们要研究什么?
2.线性表…

【周末闲谈】Stable Diffusion会魔法的绘画师
个人主页:【😊个人主页】 系列专栏:【❤️Python】 文章目录 前言Stable Diffusion介绍 使用ComfyUI 和 WebUIComfyUIWebUI 配置需求 Stable Diffusion资源分享吐司AiAUTOMATIC1111Civitai绘世整合包Nenly同学stability.ai 前言
在很早之前&…

2-33 基于matlab的用于计算无故障的斜齿轮对啮合时接触线长度随时间的变化
基于matlab的用于计算无故障的斜齿轮对啮合时接触线长度随时间的变化,根据需求设置斜齿轮对的相应参数,得到结果。程序已调通,可直接运行。 2-33 斜齿轮对啮合时接触线长度 齿轮参数 - 小红书 (xiaohongshu.com)

【笔记】nginx命令
查看 启动 通过./nginx启动nginx之后
可以在虚拟机中进入/usr/local/nginx/html 去查看cat index.html 也就是此页面的源代码 进入vim /etc/profile 配置完之后保存退出 source /etc/profile 手动重载资源 随后就可以在任意位置重载资源了
nginx -s reload 部署静态资源就把静…

【Linux】进程程序替换 + 模拟实现简易shell
前言
上一节我们介绍了 **进程终止**和 **进程等待**等一系列问题,并做了相应的验证,本章将继续对进程控制进行介绍,重点学习进程程序替换,并进行相应验证,在此基础上,自己模拟实现一个shell,该…


机器人相关工科专业课程体系
机器人相关工科专业课程体系 前言传统工科专业机械工程自动化/控制工程计算机科学与技术 新兴工科专业智能制造人工智能机器人工程 总结Reference: 前言
机器人工程专业是一个多领域交叉的前沿学科,涉及自然科学、工程技术、社会科学、人文科学等相关学科的理论、方…


SpringCloud02_consul概述、功能及下载、服务注册与发现、配置与刷新
文章目录 ①. Euraka为什么被废弃②. consul简介、如何下载③. consul功能及下载④. 服务注册与发现 - 8001改造⑤. 服务注册与发现 - 80改造⑥. 服务配置与刷新Refresh ①. Euraka为什么被废弃
①. Eureka停更进维 ②. Eureka对初学者不友好,下图为自我保护机制 ③. 阿里巴巴…

taro小程序terser-webpack-plugin插件不生效(vue2版本)
背景
最近在做公司内部的小程序脚手架,为了兼容老项目和旧项目,做了vue2taro,vue3taro两个模板,发现terser-webpack-plugin在vue2和vue3中的使用方式并不相同,同样的配置在vue3webpack5中生效,但是在vue2webpack4中就…

【Linux】:重定向和缓冲区
朋友们、伙计们,我们又见面了,本期来给大家带来关于重定向和缓冲区的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从入门到精…

【题解】 栈和排序(栈 + 预处理 / 贪心)
https://www.nowcoder.com/practice/95cb356556cf430f912e7bdf1bc2ec8f?tpId196&tqId37173&ru/exam/oj
预处理最大值
#include <climits> // 包含标准整数类型的定义
#include <vector> // 包含标准vector容器的定义class Solution {public:/*** 栈排…