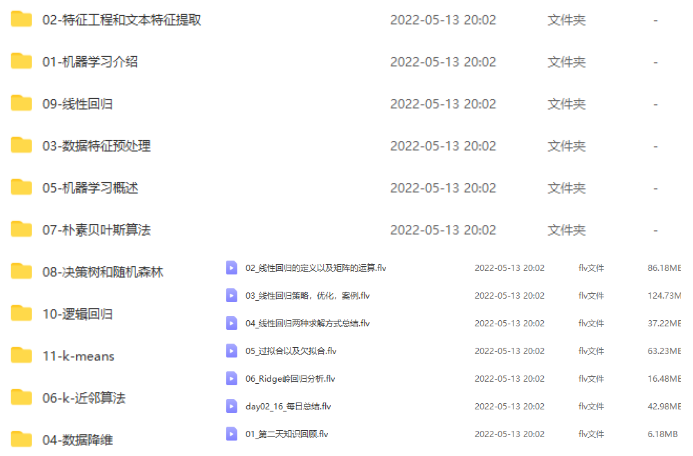
目录
背景
Floating point embeddings
特点
适用场景
丈量方式
Euclidean distance (L2)
Inner product (IP)
Cosine similarity (COSINE)
代码写法
索引类型
In-Memory
FLAT 索引
IVF_FLAT
IVF_FLAT的工作流程
平衡准确性与速度
性能考虑
代码写法
IVF_SQ8
原理
参数
代码
适用性小结
IVF_PQ
原理
参数
代码
HNSW
原理
参数
In-GPU
GPU_IVF_FLAT
原理
不同点
GPU_IVF_PQ
In-Disk
DISKANN
原理
feature 配置位置
limitation
代码
finetune
背景
作为向量数据库的重要核心概念,引入与适用场景匹配的相似度,在search 或 query 时至关重要。在前面讲述 Chroma 的相似度计算时,已经说清楚了 Cosine,IP, l2 三种相似度计算的不用及适用场景。Milvus 在相似度的匹配中,也包含了这些核心概念,但应该说 Milvus 在这方面考虑得更细致一些, 下面看下Milvus 在这方面的使用。
Chroma 更加侧重于轻量级的,LLM领域的 vector store 与 search,所以Chroma 更加关注的是 floating vector 的存储。因为熟悉 LLM embedding 的都应该很清楚,无论你使用何种 embedding 模型,包括 google transfomer,或是其他你在 mode scope 上下载的 embedding model,句子在 embedding 后肯定是一个 dim 维度的 float类型的向量。正因为如此,Chroma 的重点在关注 float vector 的embedding 上。所以还是那句话,应用场景决定了软件设计。
但Milvus 在关注 LLM 的 vector store 与 query 时,同时也关注 Binary 与 Sparse 的 embedding。下面依次详细解释。
Floating point embeddings
其实就是浮点嵌入型。
特点
浮点嵌入使用浮点数(如单精度float或双精度double)来表示向量中的每个元素。
浮点数提供了较高的精度,可以表示非常精确的数值。
存储成本相对较高,因为浮点数需要更多的存储空间。
适用场景
需要高精度计算的场景,如科学研究、金融分析等。
机器学习模型中的embedding层,特别是在处理复杂数据时,如图像、音频等。
适用于对相似度计算精度要求较高的应用,如新闻推荐、商品推荐等。
丈量方式
Euclidean distance (L2)
Inner product (IP)
Cosine similarity (COSINE)
在RAG与LLM原理及实践(4)--- 语义相似度距离衡量的三种方式chroma示例_rag 相似度-CSDN博客
已经解释的比较清楚了,这里的核心都是一样的,不明白直接看这里就行,不再熬述。
代码写法

L2, COSINE, IP 自己选择当下场景合适的就行。
索引类型
对于浮点数嵌入型的 vector,Milvus 区分的非常细,实际上在实现的时候,Chroma 也有类似的功能,只是没有明说,放在了代码中而已。下面依次看看。
In-Memory
FLAT 索引
FLAT索引在向量相似性搜索应用中,尤其是在需要完美准确性且数据集相对较小的场景(百万级别)下,是一个很好的选择。其最核心的特点就是FLAT索引不压缩向量,因此它是唯一能够保证精确搜索结果的索引类型。由于这种精确性,FLAT索引的结果也可以作为基准,用于与其他召回率低于100%的索引产生的结果进行比较。
FLAT索引之所以准确,是因为它采用了穷举搜索的方法。对于每个查询,它都会将目标输入与数据集中的每一组向量进行比较。这种方法的缺点是搜索速度较慢,因为它需要遍历整个数据集来查找匹配项。因此,FLAT索引在处理大规模向量数据时效率较低,不适合需要快速响应的场景。
在Milvus中,使用FLAT索引不需要设置任何参数,也无需进行数据训练。这使得FLAT索引的部署和使用变得非常简单直接,特别适用于那些对精确性有严格要求且数据集规模适中的场景。
其实就是在 Chroma 中对应的 暴力所有方式。
IVF_FLAT
inverted File with Flat Index是一种用于大规模向量搜索的高效索引方法,特别适用于处理高维向量数据,如图像、文本或音频的嵌入表示。它通过将向量数据分割成多个集群单元(即nlist个簇),并在每个簇中维护一个中心点,来加速相似度搜索过程。这种方法的关键在于,它仅需在查询时计算目标输入向量与这些簇中心点的距离,然后根据这些距离选择最相似的簇来进一步搜索其中的向量,从而显著减少了查询时间。
IVF_FLAT的工作流程
-
数据分割:首先,将所有的向量数据根据某种聚类算法(如K-means)分割成nlist个簇,并计算每个簇的中心点。
-
索引构建:为每个簇构建索引,并将簇内的向量数据与对应的簇中心点关联起来。在IVF_FLAT中,数据以原始形式存储,不进行额外的编码或压缩。
-
查询处理:
- 粗粒度筛选:当接收到一个目标输入向量时,首先计算它与所有簇中心点的距离。
- 细粒度搜索:根据这些距离,选择最相似的nprobe个簇(nprobe是系统设置的查询时要搜索的簇的数量)。
- 相似度计算:在选定的簇中,计算目标输入向量与簇内每个向量的相似度(如余弦相似度或欧氏距离)。