【Faster R-CNN】之 Resize_and_Padding
- 1、前言:
- 2、resize_image_and_bbox
- 1)先对图像做resize处理
- 2)再对 bounding box 做resize处理
- 3、padding_images
- 代码
1、前言:
在上一篇文章 【Faster R-CNN】之 Dataset and Dataloader 代码精读 中,我们重写了 Dataset 和 Dataloader, 可以迭代的 读出 batch 数据了。每个batch 中的数据 包括 image 和 target, 数据形如:
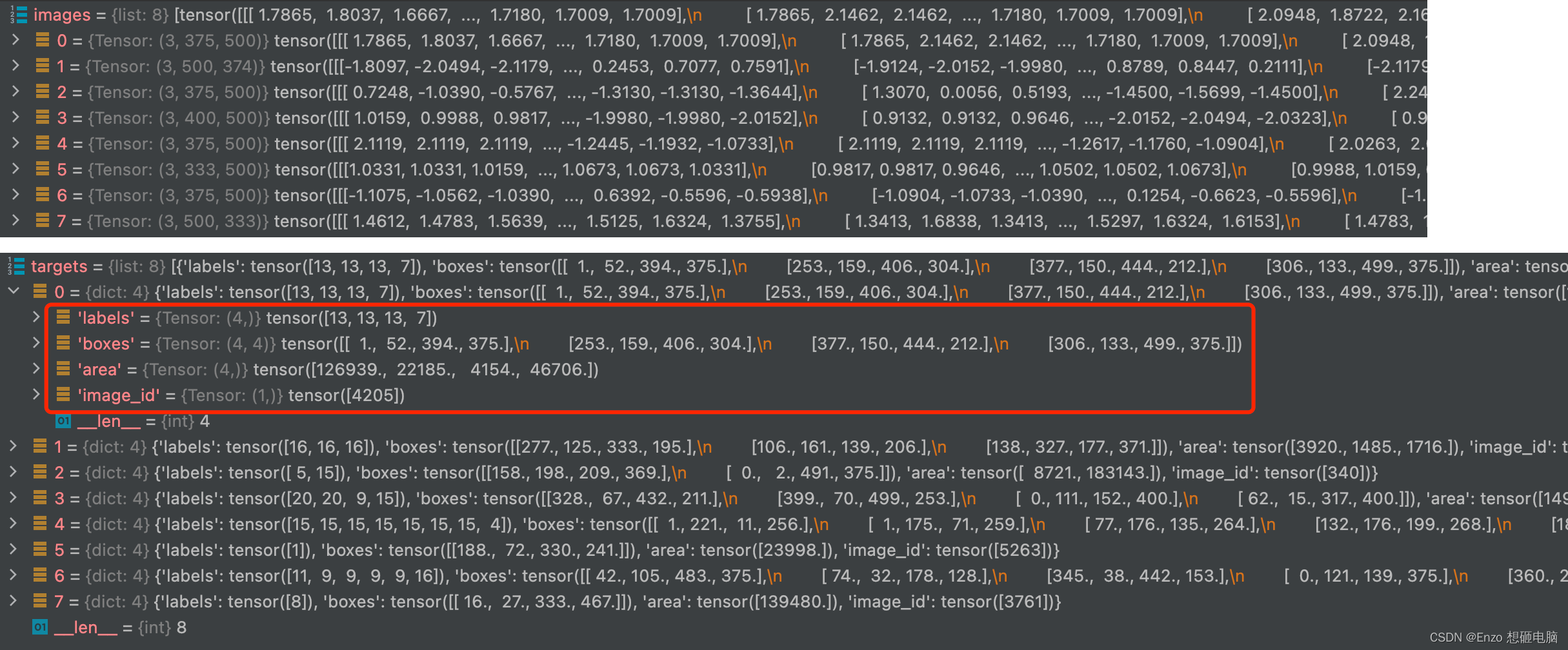
接下来,batch 中的 images 要传入 backbone 获得 feature map, 但是当前这些 images 存在一个问题,
就是这 batch 中的图像的尺寸 是不一致的,不能直接喂进 backbone。不论 backbone 是使用 vgg16 还是 resnet 还是其他,其本质都是卷积神经网络结构,需要输入形为(batch_size, channel, height, width)的图片数据。
所以这里,我们需要将 batch 中的图像统一尺寸。怎么做呢? 分为2个步骤: (这里概括,下面举例细讲)
- resize_image_and_bbox:(1)将batch 中的图像的高和宽全都 resize 到 [800,1333] 这个范围里,800和1333 是超参数,经验值。(2)图像resize了,ground trurh bounding box 的坐标自然也是要做相应的 resize。
- padding_images:(1)分别找到batch 中图像的最大的 高度height 和 最大的宽度 width。(2)为了内存效率,将最大高度和最大宽度向上取到32 的整数倍,作为这个batch 的最终高和宽(3)将所有 (resize之后的) 图像 padding到 batch 的高和宽,padding方式为:只padding 右边和下面,左边和上边不加padding
下面我们举例细讲:
假设 batch size = 4,
这4张图像尺寸分别为:[3, 375, 500]、[3, 500, 374]、[3, 375, 500]、[3, 400, 500]
第1张图像标注出了 2个 object,bounding box 坐标分别为[ 1., 52., 394., 375.]、 [253., 159., 406., 304.]
2、resize_image_and_bbox
我们使用for 循环,读取batch中的每一张图片和其标注信息,逐张图片做resize处理
for i in range(len(images)):
image = images[i]
target_index = targets[i] if targets is not None else None
image, target_index = self.resize_image_and_bbox(image, target_index) # resize image and boxes
images[i] = image
if targets is not None and target_index is not None:
targets[i] = target_index
上面代码第4行调用了 resize_image_and_bbox 函数,该函数中包括了 2部分,第一部分,先对 image 做resize,第二部分,对 bounding box 做resize
1)先对图像做resize处理
# ======================= resize image =======================
image_min_size = float(torch.min(im_shape))
image_max_size = float(torch.max(im_shape))
scale_factor = self.min_size / image_min_size # 按照短边进行缩放,计算缩放比例
# 根据短边的缩放比例来缩放长边,长边缩放后的结果是否超出预设的 max_size
if image_max_size * scale_factor > self.max_size:
scale_factor = self.max_size / image_max_size # 若超出预设 max_size, 则按照长边的比例进行缩放
image = torch.nn.functional.interpolate(image[None], scale_factor=scale_factor, mode="bilinear",
recompute_scale_factor=True, align_corners=False)[0]
以第一张图像为例,原图尺寸为 [3, 375, 500], 所以长边为 宽=500, 短边为高=375。
我们的目标是将长和宽都resize 到 [800, 1333] 的范围内。
1)先按照短边进行缩放,将 短边375 缩放到800, 计算出缩放因子 800/375=2.133。
2)将长边按照缩放因子进行缩放,判断缩放后有没有超出 1333上限。 500*2.133=1066.66, 没有超出1333的上限。如果超过了,就按照长边进行缩放,这种情况下,短边超过下限也没关系。
3)采用双线性插值的方式,将图像按照 缩放因子 scale_factor=2.133进行缩放。
2)再对 bounding box 做resize处理
# ======================= resize bbox =======================
boxes = target["boxes"]
ratios_height = torch.as_tensor(image.shape[1] / im_shape[0], dtype=torch.float32, device=boxes.device)
ratios_width = torch.as_tensor(image.shape[2] / im_shape[1], dtype=torch.float32, device=boxes.device)
xmin, ymin, xmax, ymax = boxes.unbind(1)
xmin = xmin * ratios_width
xmax = xmax * ratios_width
ymin = ymin * ratios_height
ymax = ymax * ratios_height
target["boxes"] = torch.stack((xmin, ymin, xmax, ymax), dim=1)
1)原图像的尺寸为 [3, 375, 500], 按照缩放因子 2.1333 进行双线性插值后得到的图像尺寸为 [3, 800, 1066]
所以,高的缩放比例为800/375=2.1333, 宽的缩放比例为1066/500=2.1320
2)将图像中的bounding box 的坐标解析出来,
第1个 bounding box 的坐标为 [xmin, ymin, xmax, ymax] = [ 1., 52., 394., 375.]
第2个 bounding box 的坐标为 [xmin, ymin, xmax, ymax] = [253., 159., 406., 304.]
将 xmin 和 xmax 按照 宽的缩放比例 2.1320 进行缩放
将 ymin 和 ymax 按照 高的缩放比例 2.1333 进行缩放
得:
第1个 bounding box resize后的坐标为 [xmin, ymin, xmax, ymax] = [ 2.1320, 110.9333, 840.0081, 799.9999]
第2个 bounding box resize后的坐标为 [xmin, ymin, xmax, ymax] = [ 539.3961, 339.2000, 865.5921, 648.5333]
** 这里求得的 bounding box 的坐标数据类型是 float32
3)batch 中所有图片都 resize 后,图片尺寸分别为
[3, 800, 1066]
[3, 1069, 800]
[3, 800, 1066]
[3, 800, 1000]
batch 中每张图片都 resize 到 限定的范围之后,就要把他们都padding到统一的尺寸了
3、padding_images
def padding_images(self, images, size_divisible=32):
image_size = [img.shape for img in images]
max_size = torch.max(torch.tensor(image_size), dim=0)[0]
stride = float(size_divisible)
max_size[1] = int(math.ceil(float(max_size[1]) / stride) * stride)
max_size[2] = int(math.ceil(float(max_size[2]) / stride) * stride)
batch_shape = [len(images)] + [v.item() for v in max_size]
'''以images[0]为基,创建带 padding 的 新tensor,
是为了新创建的 tensor 在相同的 device 上'''
batched_imgs = images[0].new_full(batch_shape, 0)
for img, pad_img in zip(images, batched_imgs):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
return batched_imgs
1)分别找到 这4张图中最大的 高度 和 最大的宽度。
4张图片resize 后的尺寸分别为:[3, 800, 1066]、[3, 1069, 800]、[3, 800, 1066]、[3, 800, 1000]
所以,最大高度为 1069,最大宽度为 1066
2)将最大高度和最大宽度 向上取到32 的整数倍 (这是为了内存的使用效率)
最大高度为 int( math.ceil(1069. / 32.) * 32)=1088
最大宽度为 int( math.ceil(1069. / 32.) * 32)=1088
所以,[1088, 1088] 就是 batch 中所有图像将要 padding 到的统一尺寸。
3)padding 成统一尺寸
将batch 中的所有图像都 padding 到 [1088, 1088] 尺寸
padding方式如下,左上角对齐,只在 右边和下边padidng。

至此,我们就已经得到了 shape 为 [batch_size, channel, height, width] = [4, 3, 1088, 1088] 的 batch 了。
代码
import torch
import math
import torch.nn as nn
class Resize_and_Padding(nn.Module):
def __init__(self, min_size, max_size):
super(Resize_and_Padding, self).__init__()
self.min_size = min_size # 指定图像的最小边长范围
self.max_size = max_size
def forward(self, images, targets=None):
for i in range(len(images)):
image = images[i]
target_index = targets[i] if targets is not None else None
image, target_index = self.resize_image_and_bbox(image, target_index) # resize image and boxes
images[i] = image
if targets is not None and target_index is not None:
targets[i] = target_index
image_sizes = [img.shape[-2:] for img in images]
images = self.padding_images(images) # 将batch 中的图像padding 到相同的尺寸
image_sizes_list = []
for image_size in image_sizes:
image_sizes_list.append((image_size[0], image_size[1]))
image_list = ImageList(images, image_sizes_list)
return image_list, targets
def resize_image_and_bbox(self, image, target):
im_shape = torch.tensor(image.shape[-2:])
# ======================= resize image =======================
image_min_size = float(torch.min(im_shape))
image_max_size = float(torch.max(im_shape))
scale_factor = self.min_size / image_min_size # 按照短边进行缩放,计算缩放比例
# 根据短边的缩放比例来缩放长边,长边缩放后的结果是否超出预设的 max_size
if image_max_size * scale_factor > self.max_size:
scale_factor = self.max_size / image_max_size # 若超出预设 max_size, 则按照长边的比例进行缩放
image = torch.nn.functional.interpolate(image[None], scale_factor=scale_factor, mode="bilinear",
recompute_scale_factor=True, align_corners=False)[0]
# ======================= resize bbox =======================
boxes = target["boxes"]
ratios_height = torch.as_tensor(image.shape[1] / im_shape[0], dtype=torch.float32, device=boxes.device)
ratios_width = torch.as_tensor(image.shape[2] / im_shape[1], dtype=torch.float32, device=boxes.device)
xmin, ymin, xmax, ymax = boxes.unbind(1)
xmin = xmin * ratios_width
xmax = xmax * ratios_width
ymin = ymin * ratios_height
ymax = ymax * ratios_height
target["boxes"] = torch.stack((xmin, ymin, xmax, ymax), dim=1)
return image, target
def padding_images(self, images, size_divisible=32):
image_size = [img.shape for img in images]
max_size = torch.max(torch.tensor(image_size), dim=0)[0]
stride = float(size_divisible)
max_size[1] = int(math.ceil(float(max_size[1]) / stride) * stride)
max_size[2] = int(math.ceil(float(max_size[2]) / stride) * stride)
batch_shape = [len(images)] + [v.item() for v in max_size]
'''以images[0]为基,创建带 padding 的 新tensor,
是为了新创建的 tensor 在相同的 device 上'''
batched_imgs = images[0].new_full(batch_shape, 0)
for img, pad_img in zip(images, batched_imgs):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
return batched_imgs


![[Golang实战]整理Golang忽略的问题](https://img-blog.csdnimg.cn/627a4096a8d04acf9af218eca9712e4e.png)