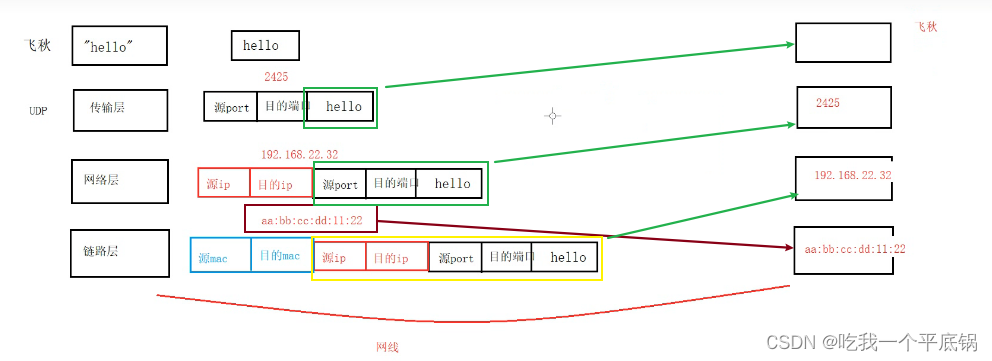
前言
从官网上下载的是长这个样子的

想看图片,咋办咧,看下面代码
import torch
import torchvision
import numpy as np
import os
import cv2
batch_size = 50
transform_predict = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])
#-----#
# train 为True 则是解压出训练图片 为Fasle的时候则解压出测试图片
#------#
image_data = torchvision.datasets.CIFAR10(
root='/home/netted/img_process_ml/temp', train=True, download=False, transform=transform_predict)
image_loader = torch.utils.data.DataLoader(
image_data, batch_size, shuffle=True, num_workers=0)
path = '/home/netted/img_process_ml/temp/train'
os.makedirs(path,exist_ok=True)
for i in range(10):
os.makedirs(f'{path}/{i}',exist_ok=True)
def format(image):
image = image.clone().detach().cpu().squeeze(0)
image = np.around(image.mul(255))
image = np.uint8(image).transpose(1, 2, 0)
return image
def data(image_loader):
idx0 = 0
idx1 = 0
idx2 = 0
idx3 = 0
idx4 = 0
idx5 = 0
idx6 = 0
idx7 = 0
idx8 = 0
idx9 = 0
for i, (data, target) in enumerate(image_loader):
for idx in range(len(data)):
label = target[idx].item()
image = format(data[idx])
if label == 0:
cv2.imwrite(f'{path}/{label}/plane_{idx0}.png',image)
idx0 += 1
if label == 1:
cv2.imwrite(f'{path}/{label}/car_{idx1}.png', image)
idx1 += 1
if label == 2:
cv2.imwrite(f'{path}/{label}/bird_{idx2}.png', image)
idx2 += 1
if label == 3:
cv2.imwrite(f'{path}/{label}/cat_{idx3}.png', image)
idx3 += 1
if label == 4:
cv2.imwrite(f'{path}/{label}/deer_{idx4}.png', image)
idx4 += 1
if label == 5:
cv2.imwrite(f'{path}/{label}/dog_{idx5}.png', image)
idx5 += 1
if label == 6:
cv2.imwrite(f'{path}/{label}/frog_{idx6}.png', image)
idx6 += 1
if label == 7:
cv2.imwrite(f'{path}/{label}/horse_{idx7}.png', image)
idx7 += 1
if label == 8:
cv2.imwrite(f'{path}/{label}/ship_{idx8}.png', image)
idx8 += 1
if label == 9:
cv2.imwrite(f'{path}/{label}/truck_{idx9}.png', image)
idx9 += 1
data(image_loader)
然后就解压出来了


当然可以自行调整将它们都合在一个文件夹里面,个人喜好
原包与自己生成好的链接如下:
链接:https://pan.baidu.com/s/1pkAFVjZ2f3ibPvMe4TtjOQ?pwd=noia
提取码:noia
欢迎大家点赞或收藏~
可以鼓励作者加快更新哟~