文章目录
- 前言
- 一、Hadoop集群 Kerberos安全配置详细步骤
- 1.1、安装libcrypto.so库
- 1.2、创建HDFS服务用户
- 1.3、配置各服务用户两两节点免密
- 1.4、修改本地目录权限
- 1.5、创建各服务Princial主体
- 1.6、修改Hadoop配置文件
- 1.6.1、配置core-site.xml
- 1.6.2、配置hdfs-site.xml
- 1.6.3、配置Yarn-site.xml
- 1.7、配置Hadoop Https访问
- 1.8、Yarn配置LCE
- 1.9、启动安全认证的Hadoop集群
- 二、访问Kerberos安全认证的Hadoop集群
- 2.1、Shell访问HDFS
- 2.1.2、未认证直接访问hdfs
- 2.1.3、创建认证主体认证访问hdfs
- 2.2、windows访问HDFS
- 2.3、Java代码访问Kerberos认证的HDFS
- 2.3.1、准备:服务器上获取认证资源文件
- 2.3.2、Java代码实现
- 2.4、Spark操作认证的HDFS
- 2.5、Flink操作认证的HDFS
前言
个人介绍
博主介绍:✌目前全网粉丝3W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
视频平台:b站-Coder长路
当前博客相关内容介绍
学习kerberos主要原因是目前部门里会有测试kerberos连通性的问题bug,所以以此来系统学习下kerberos安全认证,主要是学习在kerberos安全配置下如何去访问各个大数据组件。
Kerberos安全认证系列学习教程(B站):https://www.bilibili.com/video/BV1rr421t7Zt【马士兵的系列课程】
学习配套源码(Gitee):https://gitee.com/changluJava/demo-exer/tree/master/bigdata/kerberos/kerberosAuth
一、Hadoop集群 Kerberos安全配置详细步骤
1.1、安装libcrypto.so库
当使用Kerberos对Hadoop进行数据安全管理时,需要使用LinuxContainerExecutor,该类型Executor只支持在GNU / Linux操作系统上运行,并且可以提供更好的容器级别的安全性控制,例如通过在容器内运行应用程序的用户和组进行身份验证,此外,LinuxContainerExecutor还可以确保容器内的本地文件和目录仅能被应用程序所有者和NodeManager访问,这可以提高系统的安全性。
使用LinuxContainerExecutor时,会检测本地是否有libcrypto.so.1.1库,可以通过命令"find / -name "libcrypto.so.1.1""来确定该库是否存在,目前这里使用的Centos7系统中默认没有该库,这里需要在node1~node5各个节点上进行安装,安装步骤如下。
1、下载 openssl 源码包进行编译获取 libcrypto.so.1.1 库
在node1节点上下载openssl源码包,进行编译,步骤如下:
#下载openssl源码包,该源码也可以在资料中获取,名为:openssl-1.1.1k.tar.gz
cd /opt/tools && wget https://www.openssl.org/source/openssl-1.1.1k.tar.gz --no-check-certificate
#安装编译源码所需依赖
yum -y install gcc+ gcc-c++ zlib-devel
#解压并编译
tar -zxvf /opt/tools/openssl-1.1.1k.tar.gz -C /opt/server/
# 进入到指定解压目录
cd /opt/server/openssl-1.1.1k
# 配置
./config --prefix=/usr/local/openssl --openssldir=/usr/local/openssl shared zlib
make
make install
经过以上步骤已经获取了libcrypto.so.1.1库,位于/opt/server/openssl-1.1.1k目录下,此时可以测试下是否有该libcrypto.so.1.1:
find / -name "libcrypto.so.1.1

2、同步openssl 安装包到其他节点
这里同步编译好的openssl安装包到node2~node5节点:
cd /opt/server
# 分发到node2-5中
xsync openssl-1.1.1k
3、各个节点创建libcrypto.so.1.1 软链接
#在node1~node5节点执行如下命令,创建软链接
ln /opt/server/openssl-1.1.1k/libcrypto.so.1.1 /usr/lib64/libcrypto.so.1.1
1.2、创建HDFS服务用户
参考Hadoop文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SecureMode.html
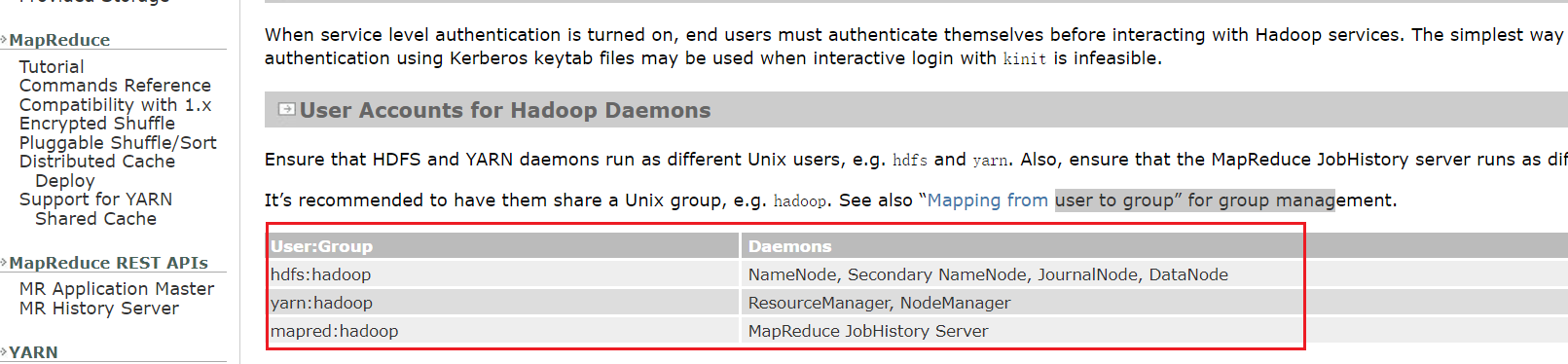
官方对于以上三种用户、所属组及管理的服务如下:
| User:Group | Daemons |
|---|---|
| hdfs:hadoop | NameNode, Secondary NameNode, JournalNode, DataNode |
| yarn:hadoop | ResourceManager, NodeManager |
| mapred:hadoop | MapReduce JobHistory Server |
按照如下步骤在所有节点【node1-5】上创建以上用户组、用户及设置密码:
1、创建 hadoop 用户组
#node1~node5所有节点执行如下命令,创建hadoop用户组
groupadd hadoop
2、创建用户
#node1~node5所有节点执行如下命令,创建各用户并指定所属hadoop组
useradd hdfs -g hadoop
useradd yarn -g hadoop
useradd mapred -g hadoop
3、设置各个用户密码
#node1~node5所有节点上设置以上用户密码,这里设置为123456
passwd hdfs
passwd yarn
passwd mapred
1.3、配置各服务用户两两节点免密
不同的服务采用不同的用户管理,默认针对不同的服务操作有不同的用户,例如操作HDFS有HDFS用户,操作yarn有yarn服务,操作mapreduce也有对应用户。
每个用户控制不同服务会涉及到各个节点之间通信,这时需要设置各个用户之间的免密通信,按照如下步骤实现。
1、设置 hdfs 用户两两节点之间免密(node1操作,分发到node2-5)
#所有节点切换成hdfs用户
su hdfs
cd ~
#node1~node5所有节点生成SSH密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
#node1~node5所有节点公钥复制到node1节点上,这个过程需要输入yes和密码
ssh-copy-id node1
# 测试查看是否五个节点公钥都在该文件中
cat ~/.ssh/authorized_keys
#将node1 authorized_keys文件分发到node1~node5各节点,这个过程需要输入密码
cd ~/.ssh/
# 分发到node2-node5节点
xsync authorized_keys
#两两节点进行ssh测试,这一步骤必须做,然后node1~node5节点退出当前hdfs用户
exit
2、设置 yarn 用户两两节点之间免密
#所有节点切换成yarn用户
su yarn
cd ~
#node1~node5所有节点生成SSH密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
#node1~node5所有节点公钥复制到node1节点上,这个过程需要输入yes和密码
ssh-copy-id node1
# 测试查看是否五个节点公钥都在该文件中
cat ~/.ssh/authorized_keys
#将node1 authorized_keys文件分发到node1~node5各节点,这个过程需要输入密码
cd ~/.ssh/
# 分发到node2-node5节点
xsync authorized_keys
#两两节点进行ssh测试,这一步骤必须做,然后node1~node5节点退出当前yarn用户
exit
3、设置 mapred 用户两两节点之间免密
#所有节点切换成mapred用户
su mapred
cd ~
#node1~node5所有节点生成SSH密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
#node1~node5所有节点公钥复制到node1节点上,这个过程需要输入yes和密码
ssh-copy-id node1
# 测试查看是否五个节点公钥都在该文件中
cat ~/.ssh/authorized_keys
#将node1 authorized_keys文件分发到node1~node5各节点,这个过程需要输入密码
cd ~/.ssh/
# 分发到node2-node5节点
xsync authorized_keys
#两两节点进行ssh测试,这一步骤必须做,然后node1~node5节点退出当前mapred用户
exit
1.4、修改本地目录权限
Hadoop中不同的用户对不同目录拥有不同权限,下面是Hadoop官方给出的不同Hadoop相关目录对应的权限,这里需要按照该权限进行设置。
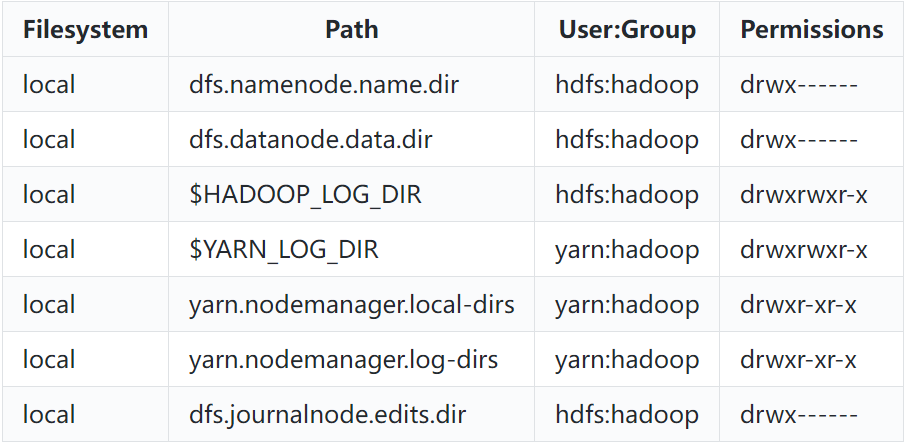
对于以上目录的解释如下:
- dfs.namenode.name.dir:该配置项用于指定NameNode的数据存储目录,NameNode将所有的文件、目录和块信息存储在该目录下。该配置项配置在hdfs-site.xml中,默认值为file://hadoop.tmp.dir/dfs/name,{hadoop.tmp.dir}配置于core-site.xml中,默认为/opt/data/hadoop。这里我们需要修改/opt/data/hadoop/dfs/name路径的所有者和组为hdfs:hadoop,访问权限为700。
- dfs.datanode.data.dir:该配置项用于指定DataNode的数据存储目录,DataNode将块数据存储在该目录下。在hdfs-site.xml中配置,默认值为file://${hadoop.tmp.dir}/dfs/data,这里我们需要修改/opt/data/hadoop/dfs/data路径的所有者和组为hdfs:hadoop,访问权限为700。
- HADOOP_LOG_DIR与YARN_LOG_DIR:HADOOP_LOG_DIR为Hadoop各组件的日志目录,YARN_LOG_DIR为YARN各组件的日志目录,两者默认日志路径为HADOOP_HOME/logs。这里我们需要修改/software/hadoop-3.3.4/logs/路径的所有者和组为hdfs:hadoop,访问权限为775。
- yarn.nodemanager.local-dirs:该配置指定指定NodeManager的本地工作目录。在yarn-site.xml中配置,默认值为file://${hadoop.tmp.dir}/nm-local-dir。这里我们修改/opt/data/hadoop/nm-local-dir路径的所有者和组为yarn:hadoop,访问权限为755。
- yarn.nodemanager.log-dirs:该配置项指定NodeManager的日志目录。在yarn-site.xml中配置,默认值为 HADOOP_LOG_DIR/userlogs。这里我们修改/software/hadoop-3.3.4/logs/userlogs/路径的所有者和组为yarn:hadoop,访问权限为755。
- dfs.journalnode.edits.dir:该配置项指定JournalNode的edits存储目录。在hdfs-site.xml中配置,默认值为/tmp/hadoop/dfs/journalnode/。这里我们配置的路径为/opt/data/journal/node/local/data,所以这里修改该路径的所有者和组为hdfs:hadoop,访问权限为700。
下面在node1~node5各个节点上执行如下命令进行以上用户和组、权限设置:
#在node1~node2 NameNode节点执行
chown -R hdfs:hadoop /opt/server/hadoop-3.3.4/data/dfs/name
chmod 700 /opt/server/hadoop-3.3.4/data/dfs/name
#在node3~node5 DataNode节点执行
chown -R hdfs:hadoop /opt/server/hadoop-3.3.4/data/dfs/data
chmod 700 /opt/server/hadoop-3.3.4/data/dfs/data
#在node1~node5所有节点执行
chown hdfs:hadoop /opt/server/hadoop-3.3.4/logs/
chmod 775 /opt/server/hadoop-3.3.4/logs/
#在node3~node5 NodeManager、JournalNode节点执行
chown -R yarn:hadoop /opt/server/hadoop-3.3.4/data/nm-local-dir
chmod -R 755 /opt/server/hadoop-3.3.4/data/nm-local-dir
chown yarn:hadoop /opt/server/hadoop-3.3.4/logs/userlogs/
chmod 755 /opt/server/hadoop-3.3.4/logs/userlogs/
chown -R hdfs:hadoop /opt/server/hadoop-3.3.4/data/journal/node/local/data
chmod 700 /opt/server/hadoop-3.3.4/data/journal/node/local/data
1.5、创建各服务Princial主体
Hadoop配置Kerberos安全认证后,为了让Hadoop集群中的服务能够相互通信并在集群中安全地进行数据交换,需要为每个服务实例配置其Kerberos主体,这样,各个服务实例就能够以其Kerberos主体身份进行身份验证,并获得访问Hadoop集群中的数据和资源所需的授权,Hadoop服务主体格式如下:ServiceName/HostName@REAL。
根据Hadoop集群各个节点服务分布,在Hadoop中创建的Kerbreos服务主体如下:
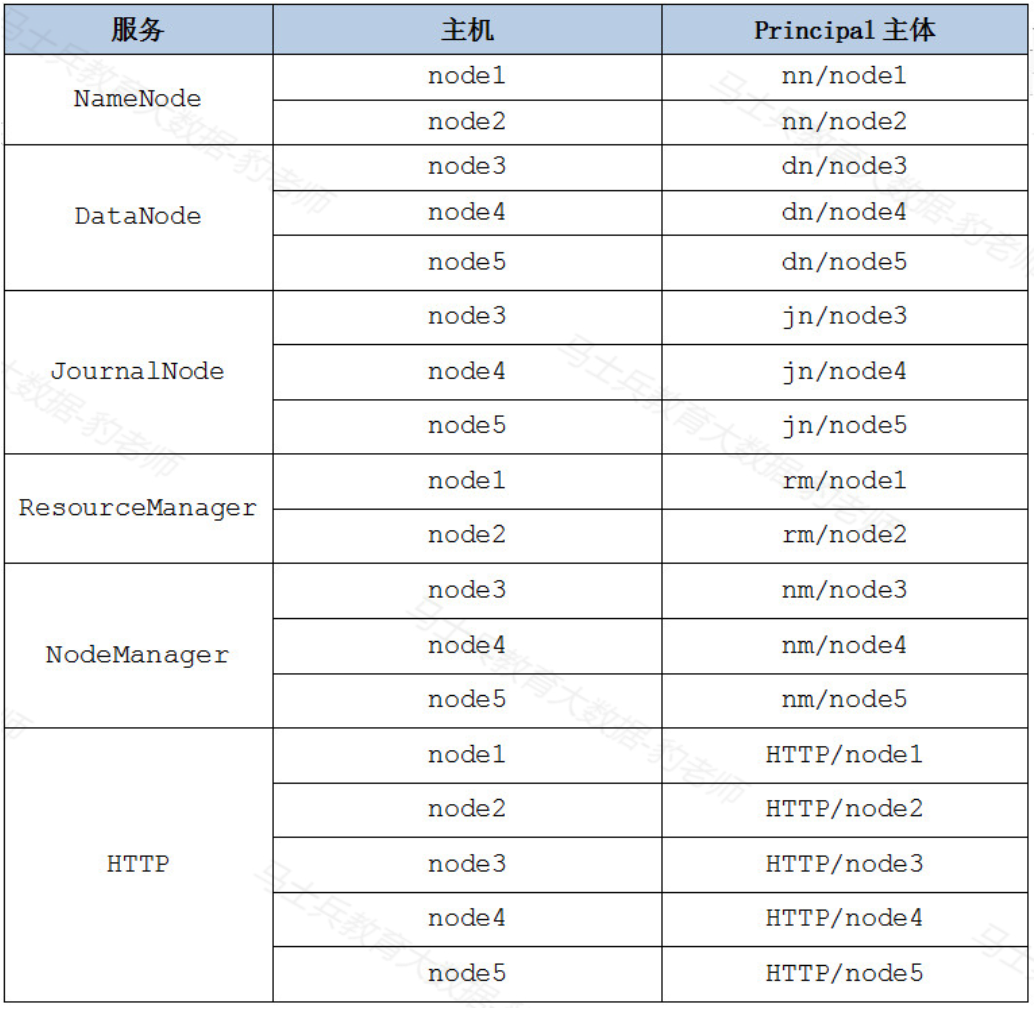
注意:以上HTTP服务主体用于Hadoop的Web控制台向Kerberos验证身份。
按照如下步骤在Kerberos服务端创建各个Hadoop服务主体并指定密码为123456。
#在Kerberos服务端node1节点执行如下命令
kadmin.local -q "addprinc -pw 123456 nn/node1"
kadmin.local -q "addprinc -pw 123456 nn/node2"
kadmin.local -q "addprinc -pw 123456 dn/node3"
kadmin.local -q "addprinc -pw 123456 dn/node4"
kadmin.local -q "addprinc -pw 123456 dn/node5"
kadmin.local -q "addprinc -pw 123456 jn/node3"
kadmin.local -q "addprinc -pw 123456 jn/node4"
kadmin.local -q "addprinc -pw 123456 jn/node5"
kadmin.local -q "addprinc -pw 123456 rm/node1"
kadmin.local -q "addprinc -pw 123456 rm/node2"
kadmin.local -q "addprinc -pw 123456 nm/node3"
kadmin.local -q "addprinc -pw 123456 nm/node4"
kadmin.local -q "addprinc -pw 123456 nm/node5"
kadmin.local -q "addprinc -pw 123456 HTTP/node1"
kadmin.local -q "addprinc -pw 123456 HTTP/node2"
kadmin.local -q "addprinc -pw 123456 HTTP/node3"
kadmin.local -q "addprinc -pw 123456 HTTP/node4"
kadmin.local -q "addprinc -pw 123456 HTTP/node5"
注意:以上命令也可以在客户端执行类似"kadmin -p test/admin -w 123456 -q “addprinc -pw 123456 xx/xx”"这种命令来创建Hadoop各服务主体。
查看下当前kadmin.local:
kadmin.local
# 查看数据库里主体,可以看到刚刚创建的主体信息
kadmin.local: listprincs
创建好Hadoop各服务主体后,可以将这些主体写入不同的Keytab密钥文件,然后将这些文件分发到Hadoop各个节点上,当Hadoop各服务之间通信认证时可以通过keytab密钥文件进行认证,按照如下步骤来完成keytab文件生成以及赋权:
1、创建存储 keytab 文件的路径
在node1~node5所有节点创建keytab文件路径,命令如下:
#node1~node5各节点执行如下命令
mkdir -p /home/keytabs
2、将 Hadoop 服务主体写入到 keytab 文件
在Kerberos服务端node1节点上,执行如下命令将Hadoop各服务主体写入到keytab文件。
#node1 节点执行如下命令
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/nn.service.keytab nn/node1@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/nn.service.keytab nn/node2@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/dn.service.keytab dn/node3@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/dn.service.keytab dn/node4@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/dn.service.keytab dn/node5@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/jn.service.keytab jn/node3@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/jn.service.keytab jn/node4@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/jn.service.keytab jn/node5@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/rm.service.keytab rm/node1@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/rm.service.keytab rm/node2@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/nm.service.keytab nm/node3@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/nm.service.keytab nm/node4@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/nm.service.keytab nm/node5@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/spnego.service.keytab HTTP/node1@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/spnego.service.keytab HTTP/node2@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/spnego.service.keytab HTTP/node3@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/spnego.service.keytab HTTP/node4@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/spnego.service.keytab HTTP/node5@EXAMPLE.COM"
以上命令执行之后,可以在node1节点/home/keytabs路径下看到创建的各个keytab文件。
[root@node1 ~]# ls /home/keytabs/
dn.service.keytab nm.service.keytab rm.service.keytab
jn.service.keytab nn.service.keytab spnego.service.keytab
3、发送 keytab 文件到其他节点
将在node1 kerberos服务端生成的keytab文件发送到Hadoop各个节点。
#node1节点执行如下命令,将keytabs文件分发到node1-node5中
xsync /home/keytabs
4、修改keytab 文件权限
这里修改各个节点的keytab文件访问权限目的是为了保证hdfs、yarn、mapred各个用户能访问到这些keytab文件。
#node1~node5各节点执行如下命令
chown -R root:hadoop /home/keytabs
chmod 770 /home/keytabs/*
chmod 770 /home/keytabs/
1.6、修改Hadoop配置文件
这里分别需要对Hadoop各个节点core-site.xml、hdfs-site.xml、yarn-site.xm配置kerberos安全认证。
1.6.1、配置core-site.xml
在node1~node5各个节点上配置core-site.xml,追加如下配置:
vim $HADOOP_HOME/etc/hadoop/core-site.xml
【node1】追加的配置内容如下:
<!-- 启用Kerberos安全认证 -->
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
<!-- 启用Hadoop集群授权管理 -->
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<!-- 外部系统用户身份映射到Hadoop用户的机制 -->
<property>
<name>hadoop.security.auth_to_local.mechanism</name>
<value>MIT</value>
</property>
<!-- Kerberos主体到Hadoop用户的具体映射规则 -->
<property>
<name>hadoop.security.auth_to_local</name>
<value>
RULE:[2:$1/$2@$0]([ndj]n\/.*@EXAMPLE\.COM)s/.*/hdfs/
RULE:[2:$1/$2@$0]([rn]m\/.*@EXAMPLE\.COM)s/.*/yarn/
RULE:[2:$1/$2@$0](jhs\/.*@EXAMPLE\.COM)s/.*/mapred/
DEFAULT
</value>
</property>
【node1】分发文件到【node2-5】:
xsync $HADOOP_HOME/etc/hadoop/core-site.xml
以上关于 "hadoop.security.auth_to_local"配置项中的value解释如下:
规则 RULE:[2:$1/$2@$0]([ndj]n/.*@EXAMPLE.COM)s/.*/hdfs/ 表示对于 Kerberos 主体中以 nn/、dn/、jn/ 开头的名称,在 EXAMPLE.COM 域中使用正则表达式 .* 进行匹配,将其映射为 Hadoop 中的 hdfs 用户名。其中,$0 表示 Kerberos 主体中的域名部分,$1 和 $2 表示其他两个部分。
1.6.2、配置hdfs-site.xml
在node1~node5各个节点上配置hdfs-site.xml:
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
【node1】节点中该文件追加如下配置:
<!-- 开启访问DataNode数据块需Kerberos认证 -->
<property>
<name>dfs.block.access.token.enable</name>
<value>true</value>
</property>
<!-- NameNode服务的Kerberos主体 -->
<property>
<name>dfs.namenode.kerberos.principal</name>
<value>nn/_HOST@EXAMPLE.COM</value>
</property>
<!-- NameNode服务的keytab密钥文件路径 -->
<property>
<name>dfs.namenode.keytab.file</name>
<value>/home/keytabs/nn.service.keytab</value>
</property>
<!-- DataNode服务的Kerberos主体 -->
<property>
<name>dfs.datanode.kerberos.principal</name>
<value>dn/_HOST@EXAMPLE.COM</value>
</property>
<!-- DataNode服务的keytab密钥文件路径 -->
<property>
<name>dfs.datanode.keytab.file</name>
<value>/home/keytabs/dn.service.keytab</value>
</property>
<!-- JournalNode服务的Kerberos主体 -->
<property>
<name>dfs.journalnode.kerberos.principal</name>
<value>jn/_HOST@EXAMPLE.COM</value>
</property>
<!-- JournalNode服务的keytab密钥文件路径 -->
<property>
<name>dfs.journalnode.keytab.file</name>
<value>/home/keytabs/jn.service.keytab</value>
</property>
<!-- 配置HDFS支持HTTPS协议 -->
<property>
<name>dfs.http.policy</name>
<value>HTTPS_ONLY</value>
</property>
<!-- 配置DataNode数据传输保护策略为仅认证模式 -->
<property>
<name>dfs.data.transfer.protection</name>
<value>authentication</value>
</property>
<!-- HDFS WebUI服务认证主体 -->
<property>
<name>dfs.web.authentication.kerberos.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- HDFS WebUI服务keytab密钥文件路径 -->
<property>
<name>dfs.web.authentication.kerberos.keytab</name>
<value>/home/keytabs/spnego.service.keytab</value>
</property>
<!-- NameNode WebUI 服务认证主体 -->
<property>
<name>dfs.namenode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- JournalNode WebUI 服务认证主体 -->
<property>
<name>dfs.journalnode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
注意:以上配置中"_HOST" 将被替换为运行 Web 服务的实际主机名。
此外,还需要修改hdfs-site.xml中如下属性为hdfs用户下的rsa私钥文件,否则在节点之间HA切换时不能正常切换。
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_rsa</value>
</property>
【node1】分发文件到【node2-5】:
xsync $HADOOP_HOME/etc/hadoop/hdfs-site.xml
1.6.3、配置Yarn-site.xml
在node1~node5各个节点上配置yarn-site.xml。
【node1】节点编辑文件:
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
追加如下配置:
<!-- ResourceManager 服务主体 -->
<property>
<name>yarn.resourcemanager.principal</name>
<value>rm/_HOST@EXAMPLE.COM</value>
</property>
<!-- ResourceManager 服务keytab密钥文件 -->
<property>
<name>yarn.resourcemanager.keytab</name>
<value>/home/keytabs/rm.service.keytab</value>
</property>
<!-- NodeManager 服务主体-->
<property>
<name>yarn.nodemanager.principal</name>
<value>nm/_HOST@EXAMPLE.COM</value>
</property>
<!-- NodeManager 服务keytab密钥文件 -->
<property>
<name>yarn.nodemanager.keytab</name>
<value>/home/keytabs/nm.service.keytab</value>
</property>
【node1】分发文件到【node2-5】:
xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
1.7、配置Hadoop Https访问
HTTP的全称是Hypertext Transfer Protocol Vertion (超文本传输协议),HTTPS的全称是Secure Hypertext Transfer Protocol(安全超文本传输协议),HTTPS基于HTTP开发,使用安全套接字层(SSL)进行信息交换,简单来说它是HTTP的安全版,HTTPS = HTTP+SSL。
SSL(Secure Sockets Layer)是一种加密通信协议,它使用公钥加密和私钥解密的方式来确保数据传输的安全性。Hadoop配置Kerberos对Hadoop访问进行认证时,官方建议对Hadoop采用HTTPS访问方式保证数据安全传输,防止在数据传输过程中被窃听、篡改或伪造等攻击,提高数据的保密性、完整性和可靠性。按照如下步骤对Hadoop设置HTTPS访问。
1、生成私钥和证书文件
在【node1】节点执行如下命令生成私钥和证书文件:
#执行如下命令需要输入密码,这里设置密码为123456
openssl req -new -x509 -keyout /root/hdfs_ca_key -out /root/hdfs_ca_cert -days 36500 -subj '/C=CN/ST=beijing/L=haidian/O=devA/OU=devB/CN=devC'
以上命令使用 OpenSSL 工具生成一个自签名的 X.509 证书,执行完成后,会在/root目录下生成私钥文件hdfs_ca_key和证书文件hdfs_ca_cert。
2、将证书文件和私钥文件发送到其他节点
【node1】节点这里将证书文件和私钥文件发送到node2~node5节点上,后续各节点需要基于两个文件生成SSL认证文件。
# 【node1】分发到【node2-5】
xsync /root/hdfs_ca_cert
xsync /root/hdfs_ca_key
3、生成 keystore 文件
keystore文件存储了SSL握手所涉及的私钥以及证书链信息,在【node1~node5】各节点执行如下命令,各个节点对应–alise不同且CN不同, 这里的 CN 虽说是组织名随意取名,但是在后续配置中建议配置为各节点的 hostname ,这样不会出现验证出错。
# 在下面不同的节点依次执行,注意每条命令中名称不同
[root@node1 ~]# keytool -keystore /root/keystore -alias node1 -genkey -keyalg RSA -dname "CN=node1, OU=dev, O=dev, L=dev, ST=dev, C=CN"
[root@node2 ~]# keytool -keystore /root/keystore -alias node2 -genkey -keyalg RSA -dname "CN=node2, OU=dev, O=dev, L=dev, ST=dev, C=CN"
[root@node3 ~]# keytool -keystore /root/keystore -alias node3 -genkey -keyalg RSA -dname "CN=node3, OU=dev, O=dev, L=dev, ST=dev, C=CN"
[root@node4 ~]# keytool -keystore /root/keystore -alias node4 -genkey -keyalg RSA -dname "CN=node4, OU=dev, O=dev, L=dev, ST=dev, C=CN"
[root@node5 ~]# keytool -keystore /root/keystore -alias node5 -genkey -keyalg RSA -dname "CN=node5, OU=dev, O=dev, L=dev, ST=dev, C=CN"
以上命令执行时需要密钥库口令,这里设置为123456,执行完成后会在/root目录下产生keystore文件。关于该命令每个选项和参数解释如下:
- keytool:Java密钥和证书管理工具的命令行实用程序。
- -keystore /home/keystore:指定密钥库的位置和名称,这里为"/home/keystore"。
- -alias jetty:指定别名,这里为各节点hostname,用于标识存储在密钥库中的密钥对。
- -genkey:指定将生成新密钥对的操作。
- -keyalg RSA:指定密钥算法,这里为RSA。
- -dname “CN=dev1, OU=dev2, O=dev3, L=dev4, ST=dev5, C=CN”:指定用于生成证书请求的"主题可分辨名称",包含以下信息:
- CN(Common Name):指定通用名称,这里建议配置为各hostname。
- OU(Organizational Unit):指定组织单位。
- O(Organization):指定组织名称。
- L(Locality):指定所在城市或地点。
- ST(State or Province):指定所在省份或州。
- C(Country):指定所在国家或地区,这里为"CN"(中国)。
4、生成 truststore 文件
truststore文件存储了可信任的根证书,用于验证服务器证书链中的证书是否可信,在【node1~node5】各个节点执行如下命令生成truststore文件。
# 过程中输入密码123456,回答Y
keytool -keystore /root/truststore -alias CARoot -import -file /root/hdfs_ca_cert
以上命令使用 Java 工具 keytool 将之前生成的自签名 CA 证书 hdfs_ca_cert 导入到指定的 truststore 文件中,并将其命名为 CARoot。命令执行后会在各个节点/root目录下生成truststore文件。
5、从 keystore 中导出 cert
在各个节点上执行命令,从对应的keystore文件中提取证书请求并保存在cert文件中。
#各节点-alias不同,需要输入口令,这里设置为123456
[root@node1 ~]# keytool -certreq -alias node1 -keystore /root/keystore -file /root/cert
[root@node2 ~]# keytool -certreq -alias node2 -keystore /root/keystore -file /root/cert
[root@node3 ~]# keytool -certreq -alias node3 -keystore /root/keystore -file /root/cert
[root@node4 ~]# keytool -certreq -alias node4 -keystore /root/keystore -file /root/cert
[root@node5 ~]# keytool -certreq -alias node5 -keystore /root/keystore -file /root/cert
注意:–alias 需要与各节点生成keystore指定的别名一致。命令执行后,在各个节点上会生成/root/cert文件。
6、生成自签名证书
这里使用最开始生成的hdfs_ca_cert证书文件和hdfs_ca_key密钥文件对cert进行签名,生成自签名证书。在node1~node5各节点执行如下命令,命令执行后会在/root下生成cert_signed文件。
#【node1-5】执行如下命令需要输入CA证书文件口令,默认123456
openssl x509 -req -CA /root/hdfs_ca_cert -CAkey /root/hdfs_ca_key -in /root/cert -out /root/cert_signed -days 36500 -CAcreateserial
7、将 CA 证书导入到 keystore
在node1~node5各个节点上执行如下命令,将之前生成的hdfs_ca_cert证书文件导入到keystore中。
#执行如下命令,需要输入keystore口令,默认123456以及Y
keytool -keystore /root/keystore -alias CARoot -import -file /root/hdfs_ca_cert
8、将自签名证书导入到 keystore
在node1~node5各个节点上执行如下命令,将生成的cert_signed自签名证书导入到keystore中:
#各个节点 alias不同。执行如下命令,需要输入keystore口令,默认123456
[root@node1 ~]# keytool -keystore /root/keystore -alias node1 -import -file /root/cert_signed
[root@node2 ~]# keytool -keystore /root/keystore -alias node2 -import -file /root/cert_signed
[root@node3 ~]# keytool -keystore /root/keystore -alias node3 -import -file /root/cert_signed
[root@node4 ~]# keytool -keystore /root/keystore -alias node4 -import -file /root/cert_signed
[root@node5 ~]# keytool -keystore /root/keystore -alias node5 -import -file /root/cert_signed
9、将 keystore 和 trustores 存入 /home 目录
将目前在/root目录下生成的keystore和trustores文件复制到/home目录下,并修改访问权限。
#在node1~node5所有节点执行如下命令
cp keystore truststore /home/
chown -R root:hadoop /home/keystore
chown -R root:hadoop /home/truststore
chmod 770 /home/keystore
chmod 770 /home/truststore
10、配置 ssl-server.xml 文件
ssl-server.xml位于HADOOP_HOME/etc/hadoop/目录下,包含了Hadoop服务器端(如NameNode和DataNode)用于配置SSL/TLS连接的参数。在node1~node5所有节点中都需要配置ssl-server.xml文件。
【node1】节点执行编辑如下配置:
cd /opt/server/hadoop-3.3.4/etc/hadoop/
mv ssl-server.xml.example ssl-server.xml
# 编辑配置文件
vim /opt/server/hadoop-3.3.4/etc/hadoop/ssl-server.xml
配置文件内容如下:
#配置的ssl-server.xml文件内容如下:
<configuration>
<property>
<name>ssl.server.truststore.location</name>
<value>/home/truststore</value>
<description>Truststore to be used by NN and DN. Must be specified.
</description>
</property>
<property>
<name>ssl.server.truststore.password</name>
<value>123456</value>
<description>Optional. Default value is "".
</description>
</property>
<property>
<name>ssl.server.truststore.type</name>
<value>jks</value>
<description>Optional. The keystore file format, default value is "jks".
</description>
</property>
<property>
<name>ssl.server.truststore.reload.interval</name>
<value>10000</value>
<description>Truststore reload check interval, in milliseconds.
Default value is 10000 (10 seconds).
</description>
</property>
<property>
<name>ssl.server.keystore.location</name>
<value>/home/keystore</value>
<description>Keystore to be used by NN and DN. Must be specified.
</description>
</property>
<property>
<name>ssl.server.keystore.password</name>
<value>123456</value>
<description>Must be specified.
</description>
</property>
<property>
<name>ssl.server.keystore.keypassword</name>
<value>123456</value>
<description>Must be specified.
</description>
</property>
<property>
<name>ssl.server.keystore.type</name>
<value>jks</value>
<description>Optional. The keystore file format, default value is "jks".
</description>
</property>
<property>
<name>ssl.server.exclude.cipher.list</name>
<value>TLS_ECDHE_RSA_WITH_RC4_128_SHA,SSL_DHE_RSA_EXPORT_WITH_DES40_CBC_SHA,
SSL_RSA_WITH_DES_CBC_SHA,SSL_DHE_RSA_WITH_DES_CBC_SHA,
SSL_RSA_EXPORT_WITH_RC4_40_MD5,SSL_RSA_EXPORT_WITH_DES40_CBC_SHA,
SSL_RSA_WITH_RC4_128_MD5</value>
<description>Optional. The weak security cipher suites that you want excluded
from SSL communication.</description>
</property>
</configuration>
【node1】分发到所有节点【node2-5】:
xsync /opt/server/hadoop-3.3.4/etc/hadoop/ssl-server.xml
11、配置ssl-client.xml 文件
ssl-client.xml位于HADOOP_HOME/etc/hadoop/目录下,包含了Hadoop客户端端(如HDFS客户端和YARN客户端)用于配置SSL/TLS连接的参数。在node1~node5所有节点中都需要配置ssl-client.xml文件。
【node1】编辑配置client文件:
cd /opt/server/hadoop-3.3.4/etc/hadoop/
mv ssl-client.xml.example ssl-client.xml
# 编辑配置文件
vim /opt/server/hadoop-3.3.4/etc/hadoop/ssl-client.xml
配置文件内容如下:
#配置的ssl-client.xml文件内容如下:
<configuration>
<property>
<name>ssl.client.truststore.location</name>
<value>/home/truststore</value>
<description>Truststore to be used by clients like distcp. Must be
specified.
</description>
</property>
<property>
<name>ssl.client.truststore.password</name>
<value>123456</value>
<description>Optional. Default value is "".
</description>
</property>
<property>
<name>ssl.client.truststore.type</name>
<value>jks</value>
<description>Optional. The keystore file format, default value is "jks".
</description>
</property>
<property>
<name>ssl.client.truststore.reload.interval</name>
<value>10000</value>
<description>Truststore reload check interval, in milliseconds.
Default value is 10000 (10 seconds).
</description>
</property>
<property>
<name>ssl.client.keystore.location</name>
<value>/home/keystore</value>
<description>Keystore to be used by clients like distcp. Must be
specified.
</description>
</property>
<property>
<name>ssl.client.keystore.password</name>
<value>123456</value>
<description>Optional. Default value is "".
</description>
</property>
<property>
<name>ssl.client.keystore.keypassword</name>
<value>123456</value>
<description>Optional. Default value is "".
</description>
</property>
<property>
<name>ssl.client.keystore.type</name>
<value>jks</value>
<description>Optional. The keystore file format, default value is "jks".
</description>
</property>
</configuration>
【node1】分发到所有节点【node2-5】:
xsync /opt/server/hadoop-3.3.4/etc/hadoop/ssl-client.xml
1.8、Yarn配置LCE
LinuxContainerExecutor(LCE)是Hadoop用于管理容器的一种执行器,它可以创建、启动和停止应用程序容器,并且能够隔离和限制容器内的资源使用,例如内存、CPU、网络和磁盘等资源。在使用Kerberos进行身份验证和安全通信时,需要使用LCE作为容器的执行器。可以按照如下步骤进行配置。
1、修改 container-executor 所有者和权限
container-executor位于HADOOP_HOME/bin目录中,该文件是LinuxContainerExecutor的可执行脚本文件,该文件所有者和权限如下:
#node1~node5所有节点执行
chown root:hadoop /opt/server/hadoop-3.3.4/bin/container-executor
chmod 6050 /opt/server/hadoop-3.3.4/bin/container-executor
2、配置 container-executor.cfg 文件
container-executor.cfg文件位于HADOOP_HOME/etc/hadoop/中,该文件是Hadoop中LinuxContainerExecutor(LCE)使用的配置文件,它定义了LCE如何运行容器,以及如何设置容器的用户和组映射。
在node1~node5所有节点上修改HADOOP_HOME/etc/hadoop/container-executor.cfg文件配置,内容如下:
# node1配置该文件
vim /opt/server/hadoop-3.3.4/etc/hadoop/container-executor.cfg
配置内容如下:
yarn.nodemanager.linux-container-executor.group=hadoop
banned.users=hdfs,yarn,mapred
min.user.id=1000
allowed.system.users=foo,bar
feature.tc.enabled=false
【node1】分发到所有节点【node2-5】:
xsync /opt/server/hadoop-3.3.4/etc/hadoop/container-executor.cfg
3、修改 container-executor.cfg 所有者和权限
container-executor.cfg文件所有者和权限设置如下:
#node1~node5所有节点执行
chown root:hadoop /opt/server/hadoop-3.3.4/etc/hadoop/container-executor.cfg
chown root:hadoop /opt/server/hadoop-3.3.4/etc/hadoop
chown root:hadoop /opt/server/hadoop-3.3.4/etc
chown root:hadoop /opt/server/hadoop-3.3.4
chown root:hadoop /opt/server
chmod 400 /opt/server/hadoop-3.3.4/etc/hadoop/container-executor.cfg
4、配置 yarn-site.xml
需要在hadoop各个节点上配置yarn-site.xml配置文件,指定使用LinuxContainerExecutor。这里在node1~node5各个节点上向yarn-site.xml追加如下内容。
【node1】节点上配置该文件,然后进行分发:
vim /opt/server/hadoop-3.3.4/etc/hadoop/yarn-site.xml
配置文件内容如下:
<!-- 配置NodeManager使用LinuxContainerExecutor管理Container -->
<property>
<name>yarn.nodemanager.container-executor.class</name>
<value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor</value>
</property>
<!-- 配置NodeManager的启动用户的所属组 -->
<property>
<name>yarn.nodemanager.linux-container-executor.group</name>
<value>hadoop</value>
</property>
<!-- LinuxContainerExecutor脚本路径 -->
<property>
<name>yarn.nodemanager.linux-container-executor.path</name>
<value>/opt/server/hadoop-3.3.4/bin/container-executor</value>
</property>
【node1】分发到所有节点【node2-5】:
xsync /opt/server/hadoop-3.3.4/etc/hadoop/yarn-site.xml
1.9、启动安全认证的Hadoop集群
这里首先需要配置HADOOP_HOME/sbin/目录中的start-dfs.sh、stop-dfs.sh、start-yarn.sh、stop-yarn.sh启动脚本中不同服务对应用户信息。配置如下:
1、配置 dfs 启停脚本
在node1节点上配置start-dfs.sh && stop-dfs.sh,两文件中修改如下配置:
vim $HADOOP_HOME/sbin/start-dfs.sh
vim $HADOOP_HOME/sbin/stop-dfs.sh
# 在两个文件中加入如下配置
HDFS_DATANODE_USER=hdfs
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=hdfs
HDFS_JOURNALNODE_USER=hdfs
HDFS_ZKFC_USER=hdfs
2、配置 yarn 启停脚本
在node1 节点上配置start-yarn.sh && stop-yarn.sh,两文件中修改如下配置:
vim $HADOOP_HOME/sbin/start-yarn.sh
vim $HADOOP_HOME/sbin/stop-yarn.sh
#在两个文件中加入如下配置
YARN_RESOURCEMANAGER_USER=yarn
YARN_NODEMANAGER_USER=yarn
3、分发到所有 hadoop 节点
将以上配置文件从node1分发到node2~node5所有节点上:
#node1节点执行,分发到其他节点
cd /opt/server/hadoop-3.3.4/sbin/
[root@node1 sbin]# scp ./start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh node2:`pwd`
[root@node1 sbin]# scp ./start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh node3:`pwd`
[root@node1 sbin]# scp ./start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh node4:`pwd`
[root@node1 sbin]# scp ./start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh node5:`pwd`
以上配置完成后,在node1节点启动Kerberos认证的HDFS集群,首先我们需要检查下服务端【node1】是否已经启动了kadmin以及krb5kdc:
# 状态应该是在active(running)
systemctl status krb5kdc
systemctl status kadmin
# 启动Kerberos服务,关闭 stop,状态 status
systemctl start krb5kdc
systemctl start kadmin
命令如下:
#在node1节点执行如下命令启动Hadoop集群
[root@node1 ~]# start-dfs.sh
[root@node1 ~]# start-yarn.sh
接着我们可以使用jps查看下java进程,如下:
jps
正常运行结果,对应服务启动了:
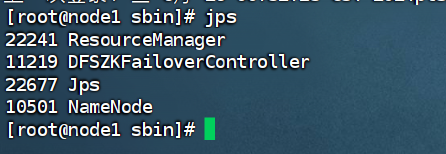
若是只有一个jps可见报错日志:
/opt/server/hadoop-3.3.4/logs/hadoop-hdfs-namenode-node1.log
若是出现下面报错不可达,那么基本就是你本地服务域名映射问题或者就是kadmin、krb5kdc没有配置了:

此时我们来访问下网址,注意启动HDFS后,由于开启的SSL配置,HDFS默认的WEBUI访问端口为9871。HDFS访问URL为https://node1:9871,Yarn访问URL为http://node1:8088。
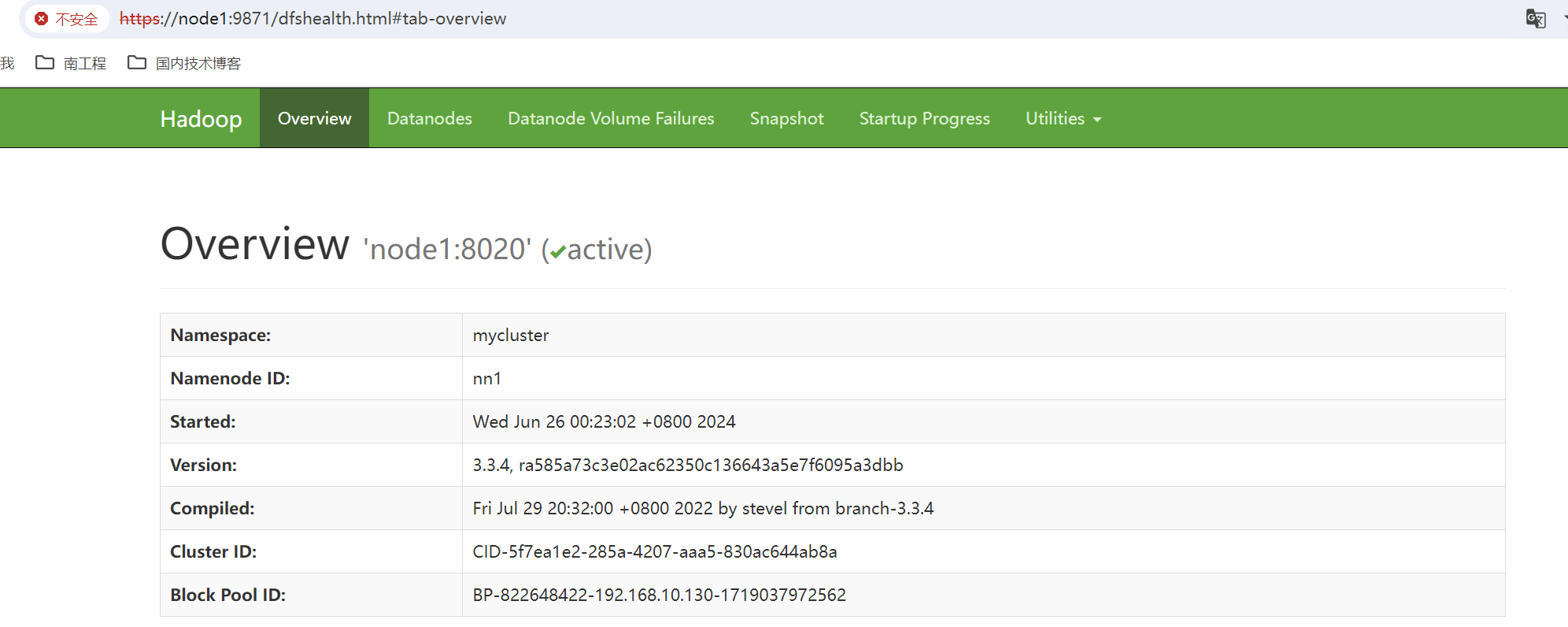
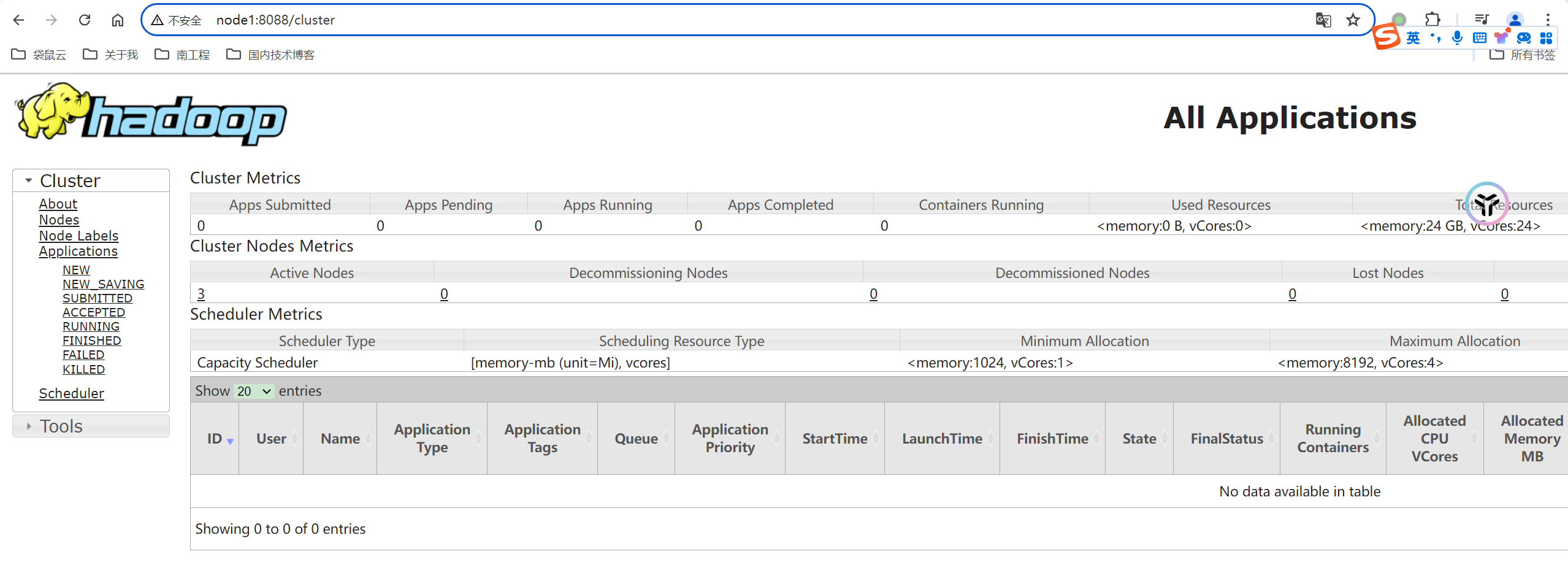
注意:目前仅仅对hdfs进行了ssl配置,yarn并没有做ssl配置处理。
文章目录
- 前言
- 一、Hadoop集群 Kerberos安全配置详细步骤
- 1.1、安装libcrypto.so库
- 1.2、创建HDFS服务用户
- 1.3、配置各服务用户两两节点免密
- 1.4、修改本地目录权限
- 1.5、创建各服务Princial主体
- 1.6、修改Hadoop配置文件
- 1.6.1、配置core-site.xml
- 1.6.2、配置hdfs-site.xml
- 1.6.3、配置Yarn-site.xml
- 1.7、配置Hadoop Https访问
- 1.8、Yarn配置LCE
- 1.9、启动安全认证的Hadoop集群
- 二、访问Kerberos安全认证的Hadoop集群
- 2.1、Shell访问HDFS
- 2.1.2、未认证直接访问hdfs
- 2.1.3、创建认证主体认证访问hdfs
- 2.2、windows访问HDFS
- 2.3、Java代码访问Kerberos认证的HDFS
- 2.3.1、准备:服务器上获取认证资源文件
- 2.3.2、Java代码实现
- 2.4、Spark操作认证的HDFS
- 2.5、Flink操作认证的HDFS
二、访问Kerberos安全认证的Hadoop集群
2.1、Shell访问HDFS
说明:在此之前生成的keytab文件是用于服务与服务之间进行访问权限的主体配置,而对于用户则需要建立新的kerberos主体之后访问hdfs的时候来完成认证后访问。
在【node1-5】中执行下面创建hadoop组中的用户命令:
useradd zhangsan -g hadoop
# 设置密码123456
passwd zhangsan
# 查看所属组
groups zhangsan
2.1.2、未认证直接访问hdfs
在【node5】中切换为zhangsan用户,接着使用hdfs来进行遍历查看目录:
su zhangsan
# 此时若是直接使用该用户去访问hdfs目录,此时不会通过kerberos认证
hdfs dfs -ls /
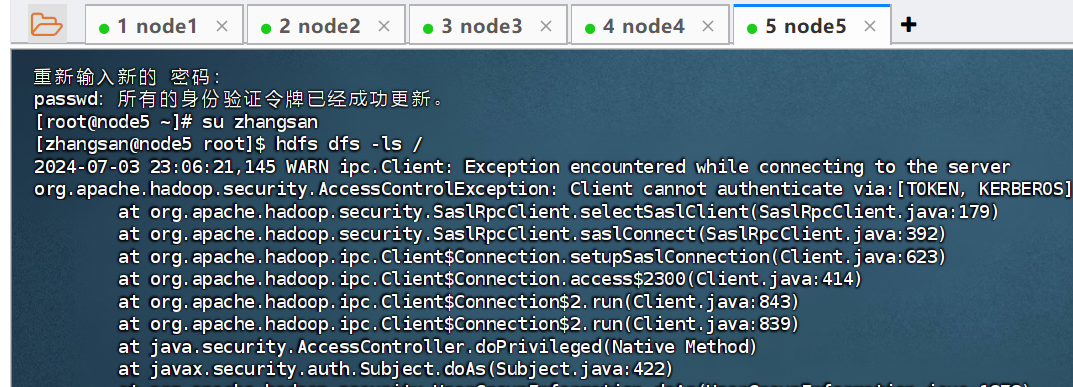
2.1.3、创建认证主体认证访问hdfs
此时在【node1】中创建一个普通用户主体:
kadmin.local -q "addprinc -pw 123456 zhangsan"
接着在【node5】中去进行使用密码认证:
# 输入密码
kinit zhangsan
klist
# 此时即可访问hdfs
hdfs dfs -ls /

在【node5】节点上创建目录,然后将文件上传,测试查看:
# 创建目录
hdfs dfs -mkdir /input
# 查看目录
hdfs dfs -ls /
# 创建一个文件
vim a.txt
# 编辑内容如下:
aaaa
bbbb
cccc
# 上传文件到指定目录下
hdfs dfs -put ./aa.txt /input/
# 查看目录
hdfs dfs -ls /input

在【node5】提交一个mapreduce任务:
# 使用指定程序来去指定wordcount类,输入文件为/input/a.txt,输出文件为/output
hadoop jar /opt/server/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input/aa.txt /output
# 任务执行完成之后,可以查看结果
hdfs dfs -cat /output/part-r-0000
若是上面出现对/tmp有权限无法操作,进行下面操作进行授权,之后重新执行:
su hdfs
# 输入123456
kinit nn/node1
# 授权
hadoop fs -chmod -R 777 /tmp
若是出现下面打印表示正常运行:
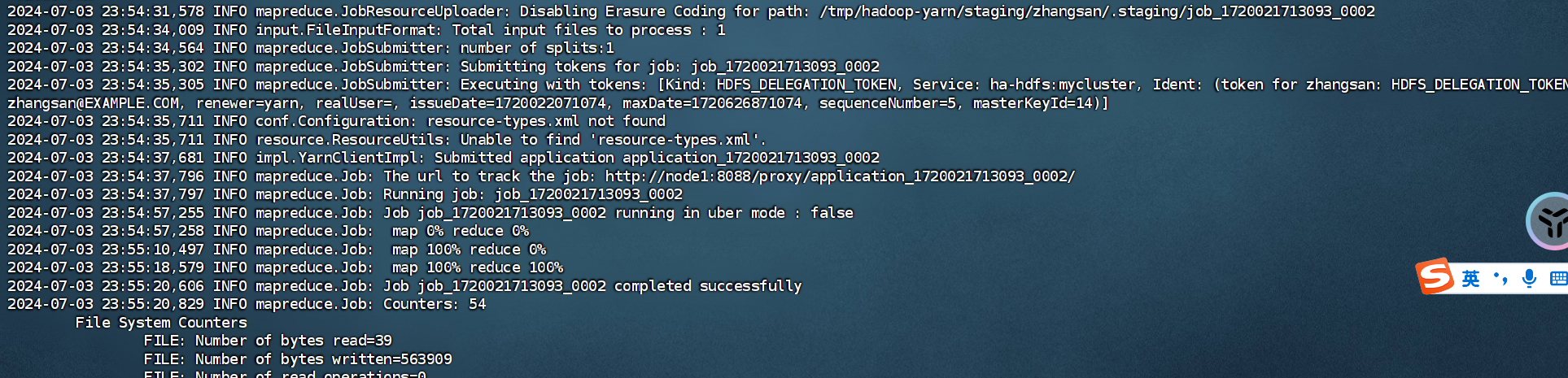
我们也可以访问web界面,去查看指定yarn任务日志:http://node1:8088/cluster/apps/ACCEPTED
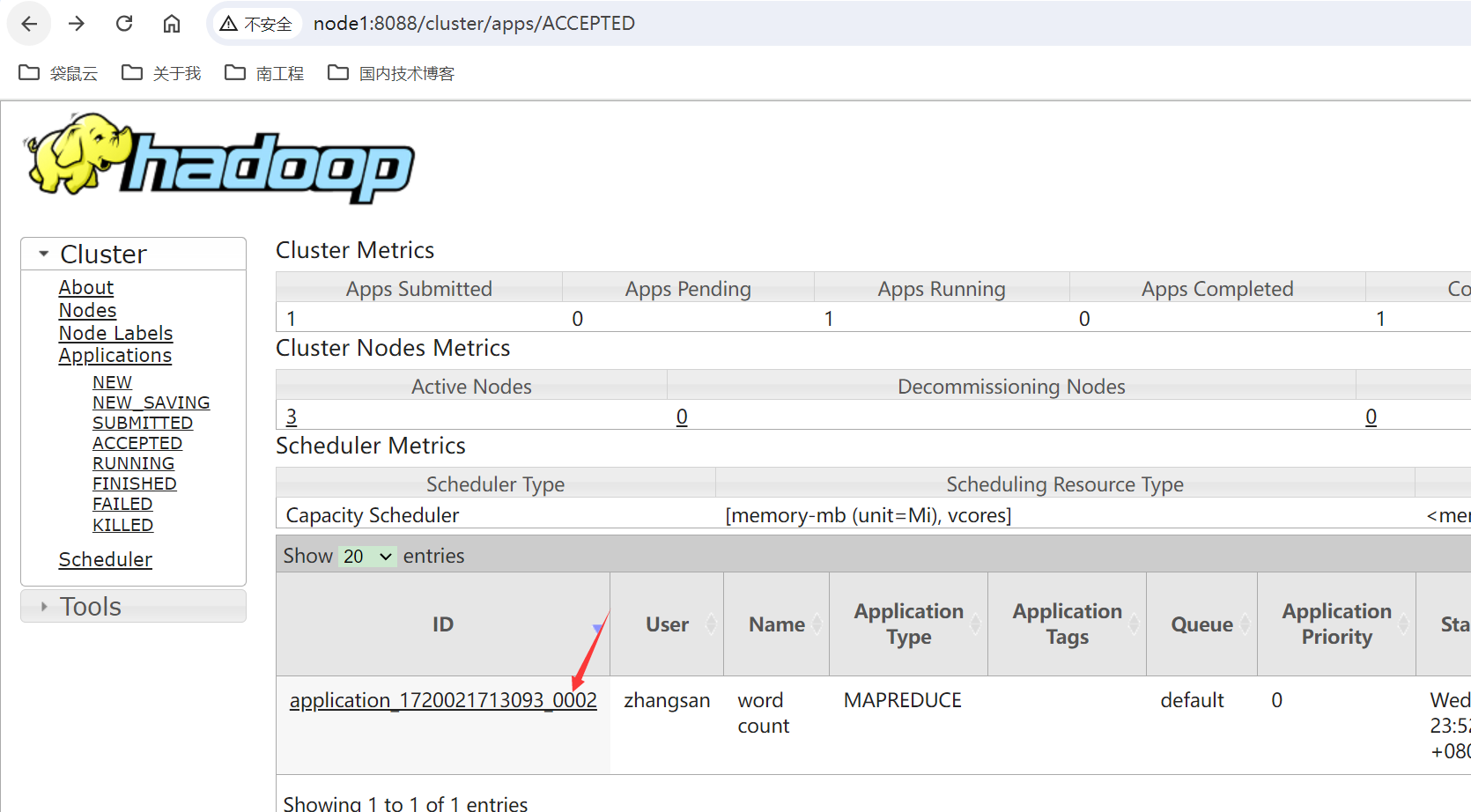
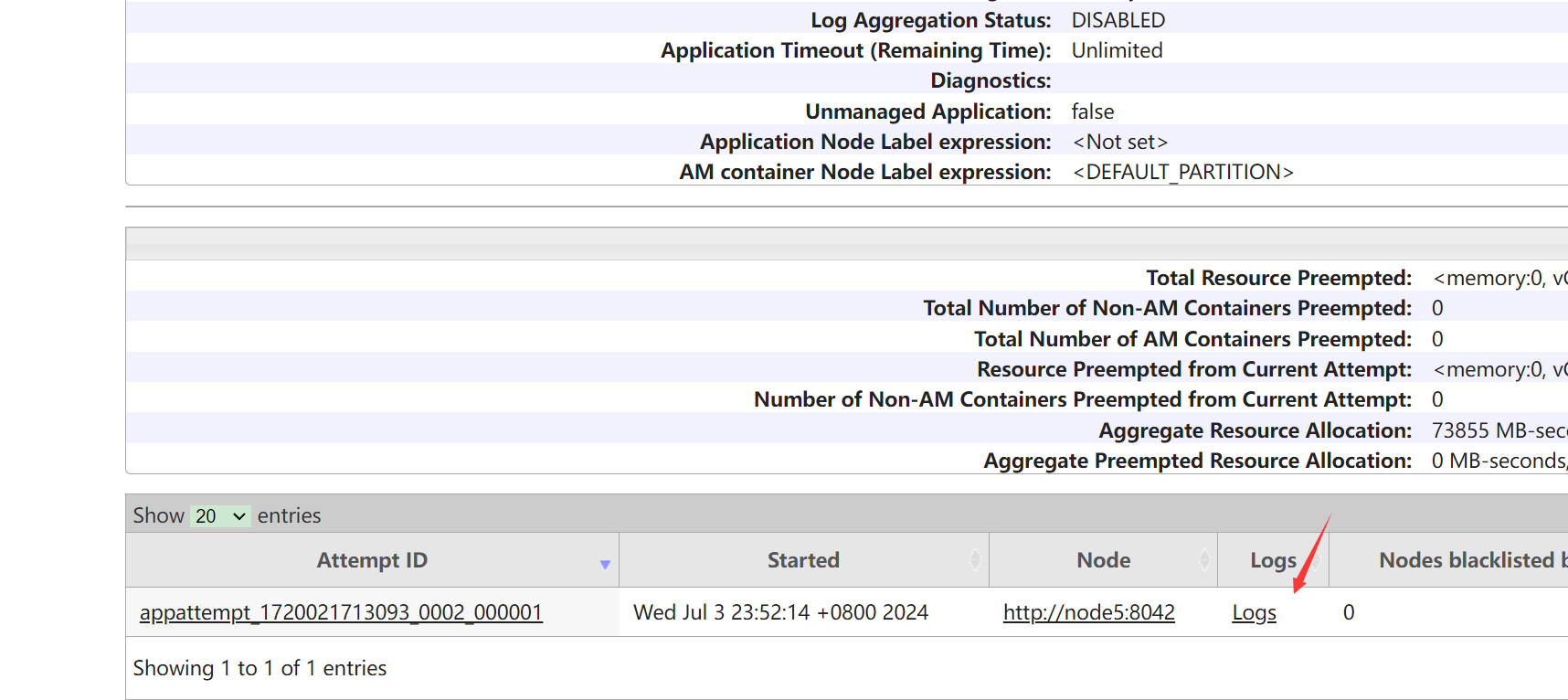
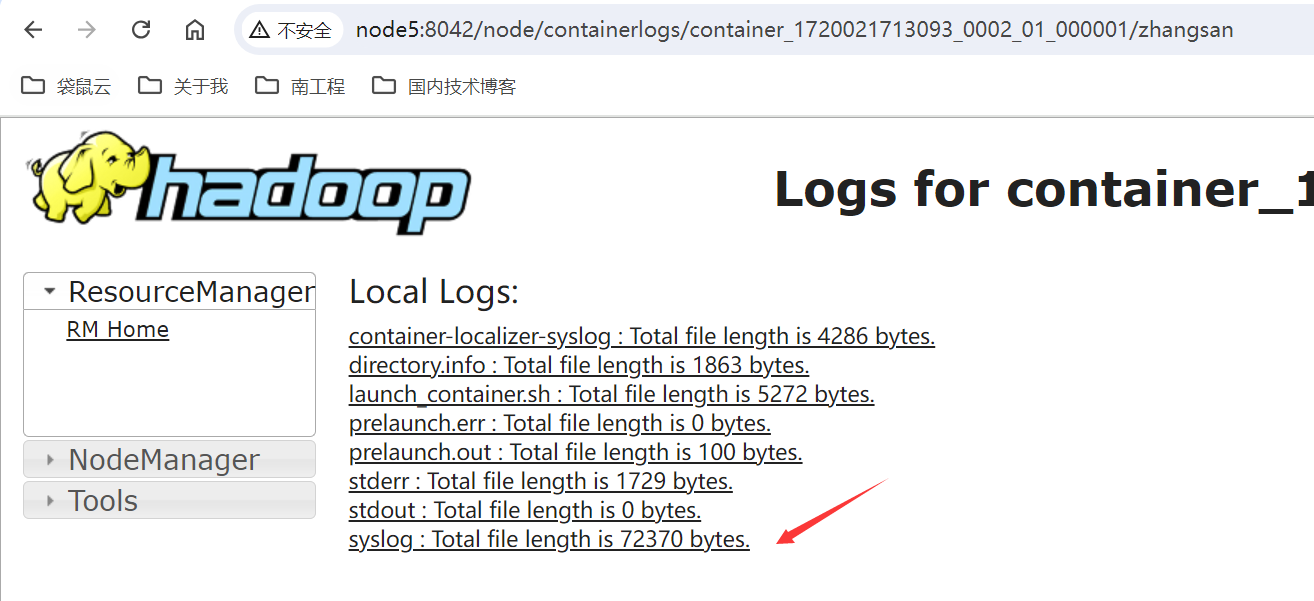
可以选择full日志,就可以看到完整任务的日志了:
【node5】执行完成之后可以看下指定目录下输出的文件内容:
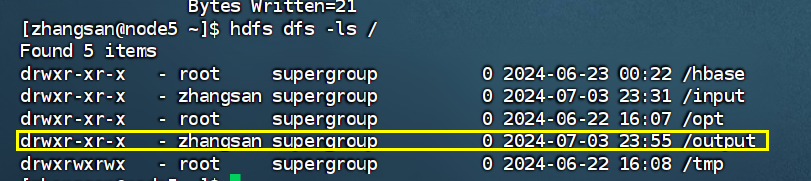
# 查看目录有无/output
hdfs dfs -ls /
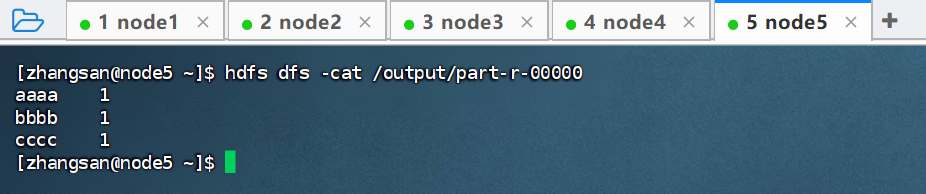
# 查看指定文件内容
hdfs dfs -cat /output/part-r-00000
2.2、windows访问HDFS
我们可以通过Window访问keberos安全认证的HDFS WebUl,如果Windows客户端没有进行kerberos主体认证
会导致在HDFS WebUl中看不到HDFS目录,这时需要我们在Window客户端进行Kerberos主体认证,在
Window中进行Kerberos认证时可以使用Kerberos官方提供的认证工具,该下载地址:
http://web.mit.edu/kerberos/dist/

下载双击安装到指定目录即可,接下来进行下面步骤,当Window kerberos客户端工具安装完成后,需要按照如下步骤进行配置才可以正确的进行Window 客户端kerberos主体认证。
1、配置krb5.ini
当keberos客户端安装完成后自动会在C:\ProgramData\MIT\Kerberos5路径中创建krb5.ini配置文件,我们需要配置该文件指定
Kerberos服务节点及域信息,配置如下,该文件配置可以参考Kerberos服务端/etc/krb5.conf文件。
在【node1】中访问krb5.conf:
cat /etc/krb5.conf
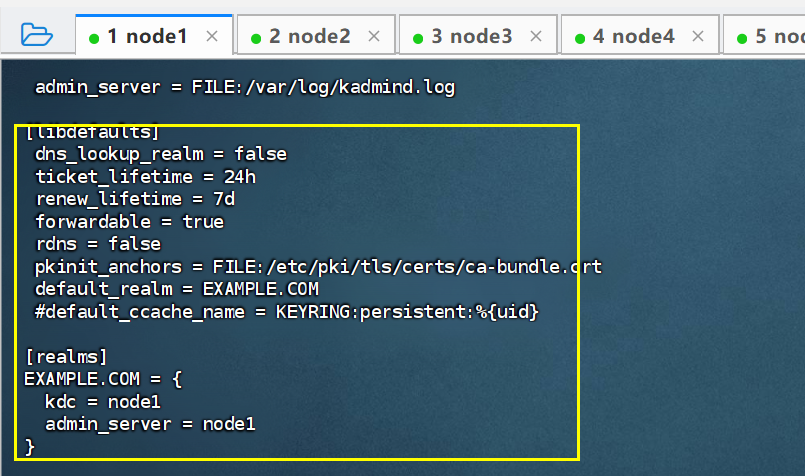
将其中这两部分内容复制到指定配置文件目录下:C:\ProgramData\MIT\Kerberos5\krb5.ini
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
default_realm = EXAMPLE.COM
[realms]
EXAMPLE.COM = {
kdc = node1
admin_server = node1
}
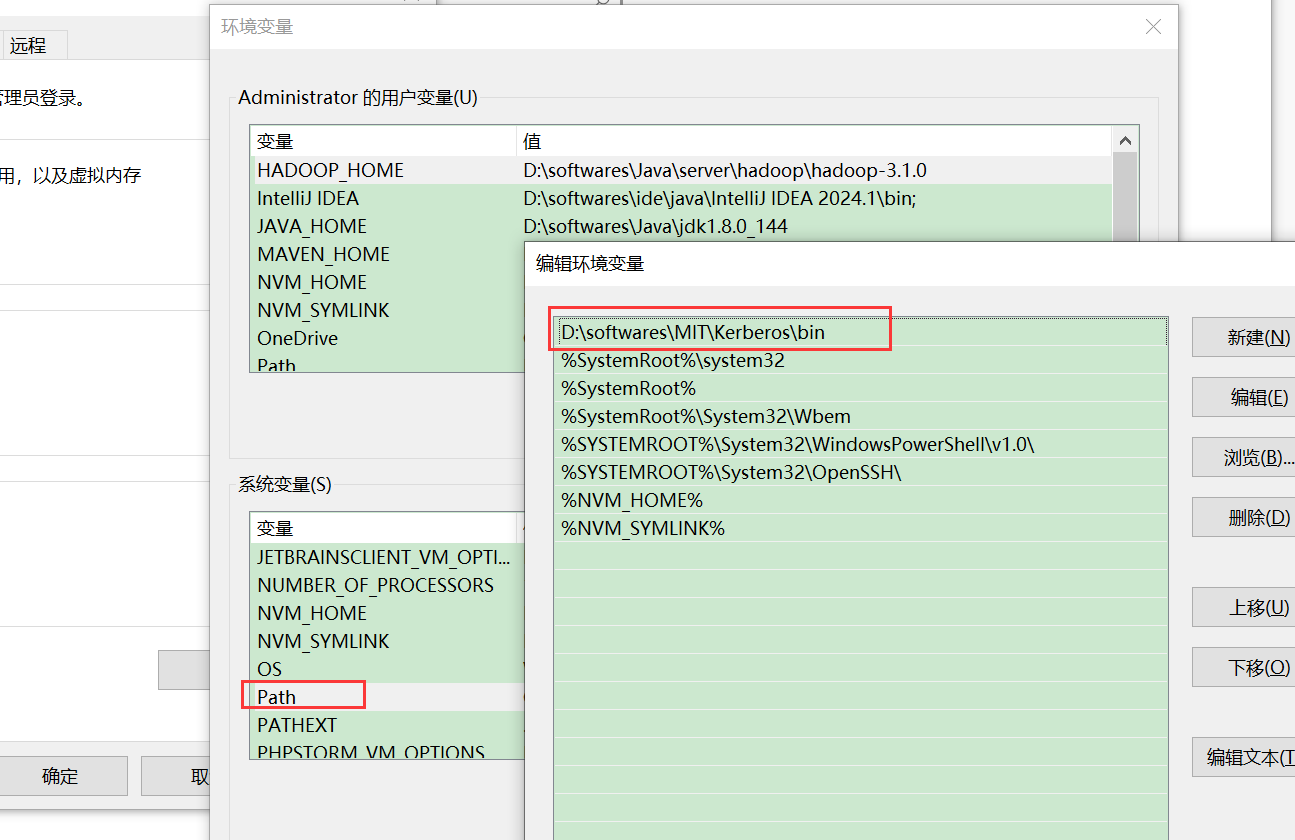
2、设置环境变量,指定kerberos环境变量上移,因为jdk的bin中也有kinit
3、使用工具认证或者命令
①使用工具认证,直接打开Mit kerberos工具输入主体及密码完成认证
zhangsan@EXAMPLE.COM
123456
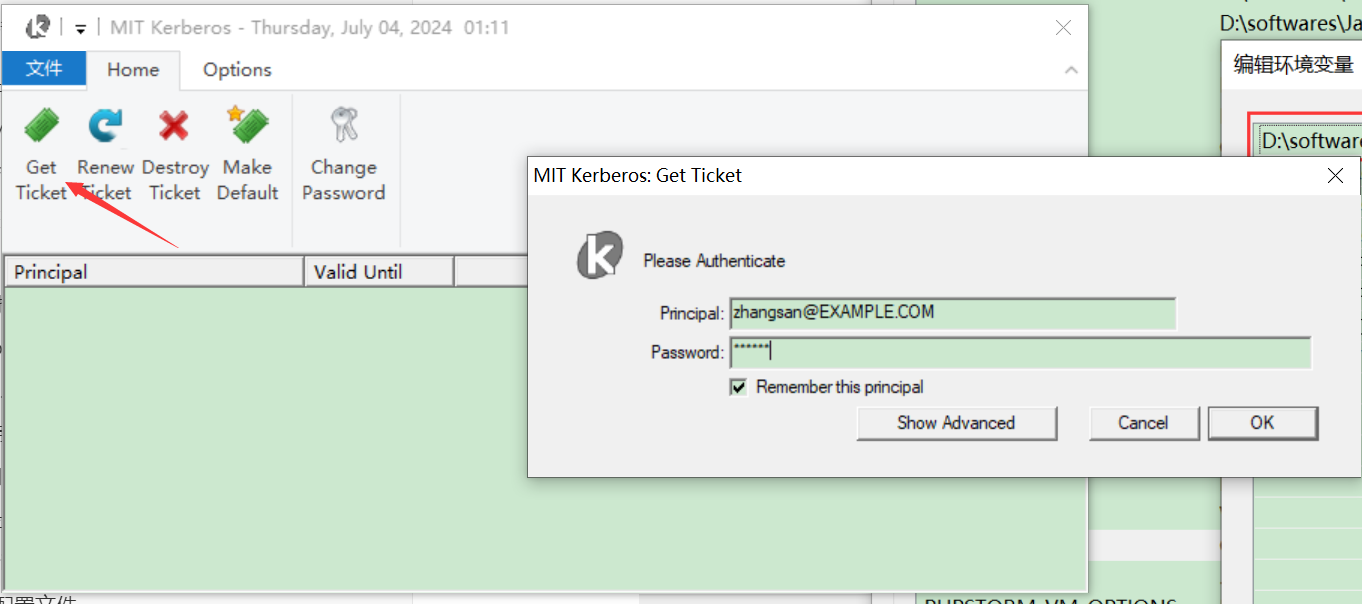
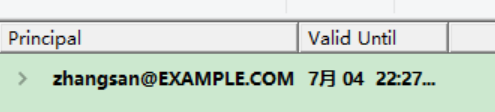
点击ok若是有下面主体信息,表示认证成功:
②命令行执行认证
# 输入密码123456
kinit zhangsan
klist
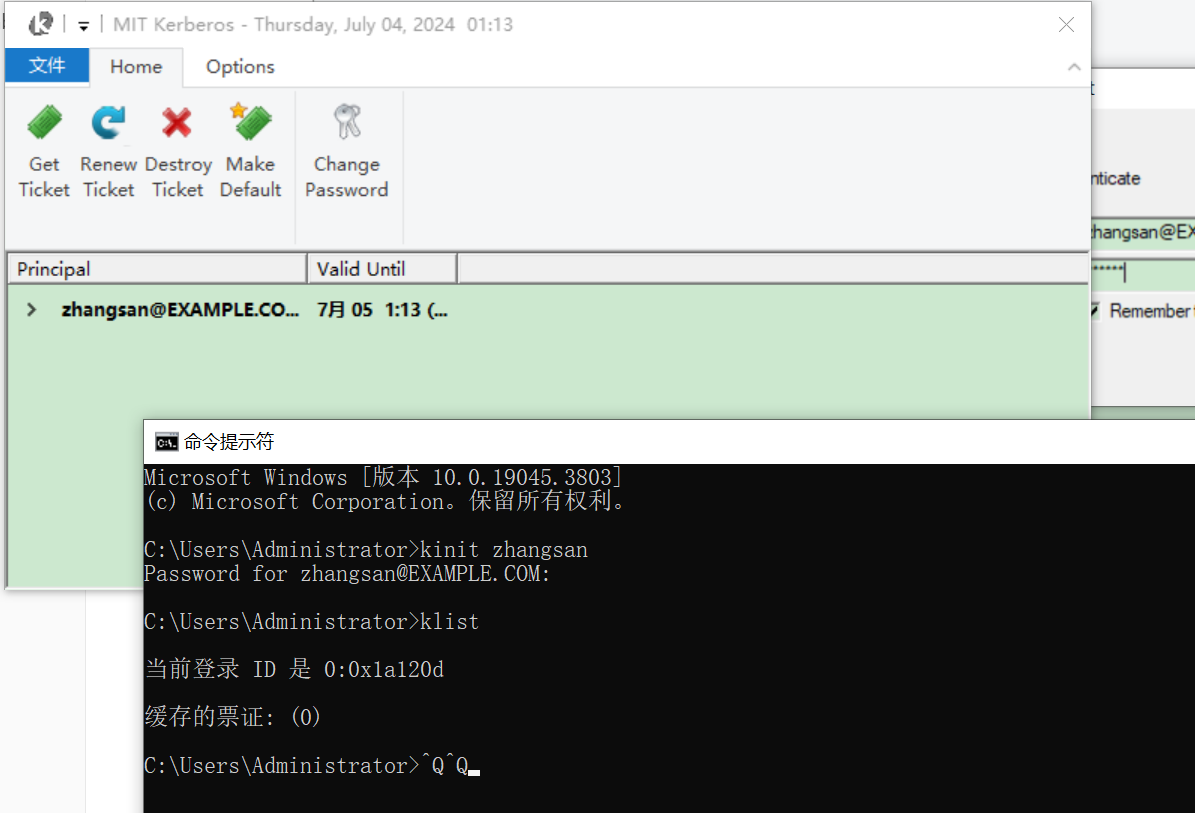
此时MIT Kerberos工具依旧会显示该主体认证。
4、建议使用firefox火狐浏览器好配置
浏览器打开首先输入如下内容,接受风险并继续:
about:config
执行命令,并设置node1,node2:
network.negotiate-auth.trusted-uris

将下面参数设置为false:
network.auth.use-sspi

设置完成重启火狐浏览器进行HDFS即可访问。
注意:在Hadoop3.3.x版本后,通过浏览器访问Kerberos认证的HDFS服务,会出现下面报错:
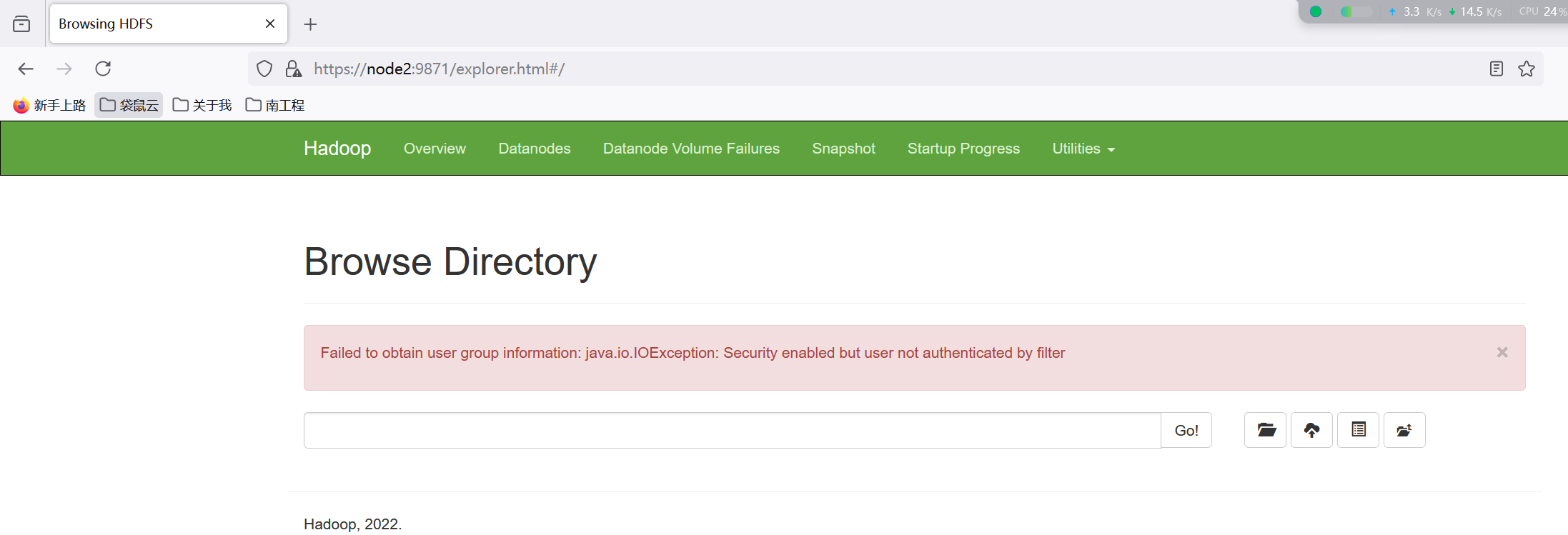
通过网上调研Hadoop3.1、3.2此时应该能正常访问,Hadoop3.3有bug,对应详细信息参考:https://issues.apache.org/jira/browse/HDFS-16441。
本章节主要理解windows如何进行配置即可。
2.3、Java代码访问Kerberos认证的HDFS
2.3.1、准备:服务器上获取认证资源文件
说明:一般使用Java代码认证都是使用keytab文件。
①首先需要的是服务器上的主kadmin的krb5.conf以及生成认证的keytab文件
在【node1】服务器上下载该文件:
cat /etc/krb5.conf
同样在【node1】节点上构建keytab文件:
kadmin.local -q "ktadd -norandkey -kt /root/zhangsan.keytab zhangsan@EXAMPLE.COM"
②下载服务器上hadoop中的三个配置文件
登录到【node1】节点,准备core-site.xml、hdfs-site.xml、yarn-site.xml,全部在服务器的下面目录下获取:
# 即/opt/server/hadoop-3.3.4/etc/hadoop
cd $HADOOP_HOME/etc/hadoop/
注意:若是这三个文件没有放置到resources目录,会出现下面报错,添加即可

③添加Maven依赖:
<!-- 操作hadoop依赖客户端sdk -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
2.3.2、Java代码实现
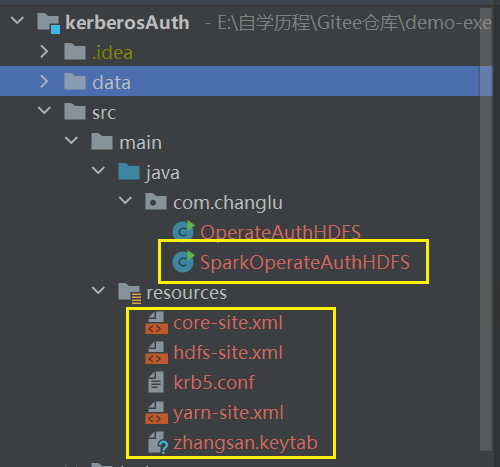
工程目录如下:
准备上传的data目录下的test.txt文件:
1,zs,100
2,changlu,200
3,zhuzhu,300
构建Java代码文件OperateAuthHDFS:
/**
* @description TODO
* @author changlu
* @date 2024/07/05 00:47
* @version 1.0
*/
package com.changlu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.security.UserGroupInformation;
import org.checkerframework.checker.units.qual.C;
import org.jline.reader.Buffer;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.InputStreamReader;
import java.security.PrivilegedExceptionAction;
/**
* @description 操作kerberos认证的HDFS
* @author changlu
* @date 2024-07-05 0:49
*/
public class OperateAuthHDFS {
private static FileSystem fs;
public static void main(String[] args) throws Exception {
final Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://mycluster");
//设置kerberos认证
System.setProperty("java.security.krb5.conf", "E:\\自学历程\\Gitee仓库\\demo-exer\\bigdata\\kerberos\\kerberosAuth\\kerberosAuth\\src\\main\\resources\\krb5.conf");
UserGroupInformation.loginUserFromKeytab("zhangsan", "E:\\自学历程\\Gitee仓库\\demo-exer\\bigdata\\kerberos\\kerberosAuth\\kerberosAuth\\src\\main\\resources\\zhangsan.keytab");
UserGroupInformation ugi = UserGroupInformation.getLoginUser();
fs = ugi.doAs(new PrivilegedExceptionAction<FileSystem>() {
@Override
public FileSystem run() throws Exception {
return FileSystem.get(conf);
}
});
//查看HDFS路径文件
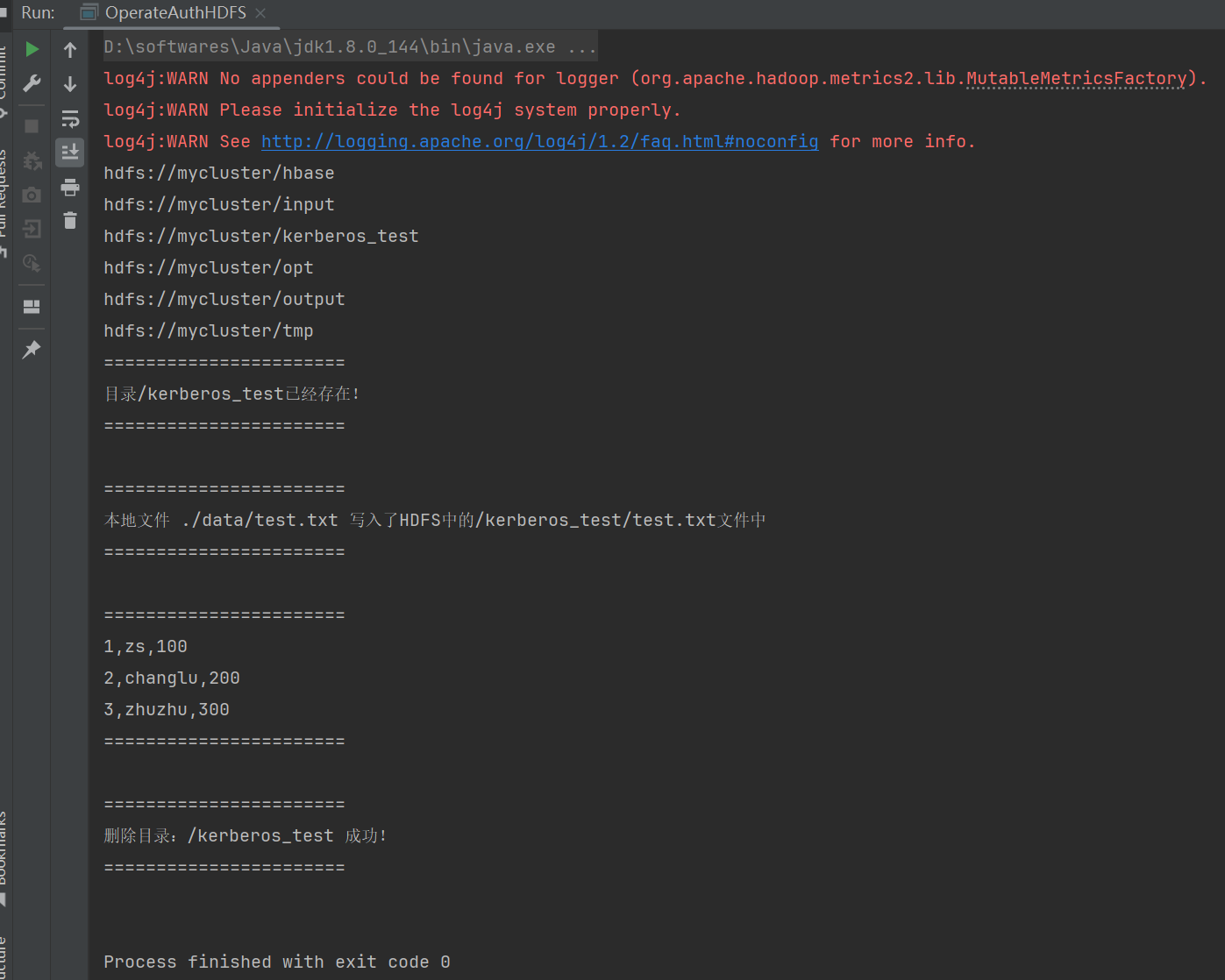
listHDFSPathDir("/");
//创建目录
System.out.println("=======================");
mkdirOnHDFS("/kerberos_test");
System.out.println("=======================\n");
//向HDFS中写入数据
System.out.println("=======================");
writeFileToHDFS("E:\\自学历程\\Gitee仓库\\demo-exer\\bigdata\\kerberos\\kerberosAuth\\kerberosAuth\\data\\test.txt", "/kerberos_test/test.txt");
System.out.println("=======================\n");
//读取HDFS中数据
System.out.println("=======================");
readFileFromHDFS("/kerberos_test/test/txt");
System.out.println("=======================\n");
//删除HDFS中目录或文件
System.out.println("=======================");
deleteFileOrDirFromHDFS("/kerberos_test");
System.out.println("=======================\n");
fs.close();
}
private static void deleteFileOrDirFromHDFS(String hdfsFileOrDirPath)throws Exception {
//判断文件是否存在HDFS
Path path = new Path(hdfsFileOrDirPath);
if (!fs.exists(path)) {
System.out.println("HDFS目录或者文件不存在");
return;
}
//第二个参数表示是否递归删除
boolean result = fs.delete(path, true);
if (result) {
System.out.println("删除目录:" + path + " 成功!");
}else {
System.out.println("删除目录:" + path + " 失败!");
}
}
private static void readFileFromHDFS(String hdfsFilePath)throws Exception {
//读取HDFS文件
Path path = new Path(hdfsFilePath);
FSDataInputStream in = fs.open(path);
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String newLine = "";
while ((newLine = br.readLine()) != null) {
System.out.println(newLine);
}
//关闭流对象
br.close();
in.close();
}
private static void writeFileToHDFS(String localFilePath, String hdfsFilePath) throws Exception{
//判断HDFS文件是否存在,存在则删除
Path hdfsPath = new Path(hdfsFilePath);
if (fs.exists(hdfsPath)) {
fs.delete(hdfsPath, true);
}
//创建HDFS文件路径
Path path = new Path(hdfsFilePath);
FSDataOutputStream out = fs.create(path);
//读取本地文件写入HDFS路径中
FileReader fr = new FileReader(localFilePath);
BufferedReader br = new BufferedReader(fr);
String newLine = "";
while ((newLine = br.readLine()) != null) {
out.write(newLine.getBytes());
out.write("\n".getBytes());
}
//关闭流对象
out.close();
br.close();
fr.close();
System.out.println("本地文件 ./data/test.txt 写入了HDFS中的" + path.toString() + "文件中");
}
private static void mkdirOnHDFS(String dirPath)throws Exception {
Path path = new Path(dirPath);
//判断目录是否存在
if (fs.exists(path)) {
System.out.println("目录" + dirPath + "已经存在!");
return;
}
//创建HDFS目录
boolean result = fs.mkdirs(path);
if (result) {
System.out.println("创建目录:" + dirPath + " 成功!");
}else {
System.out.println("创建目录:" + dirPath + " 失败!");
}
}
private static void listHDFSPathDir(String hdfsPath) throws Exception {
FileStatus[] fileStatuses = fs.listStatus(new Path(hdfsPath));
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath());
}
}
}
测试运行下:
2.4、Spark操作认证的HDFS
下面的几个resources资源我呢间与5.3的一致即可
流程如下所示:
1、准备 krb5.conf 及 keytab 文件
在【node1】 kerberos服务端将/etc/krb5.conf文件放在window固定路径中,同时将hive主体对应的keytab密钥文件放在windows固定路径中。这里项目中已经有了,可以忽略。
2、准备访问 Hive 需要的资源文件
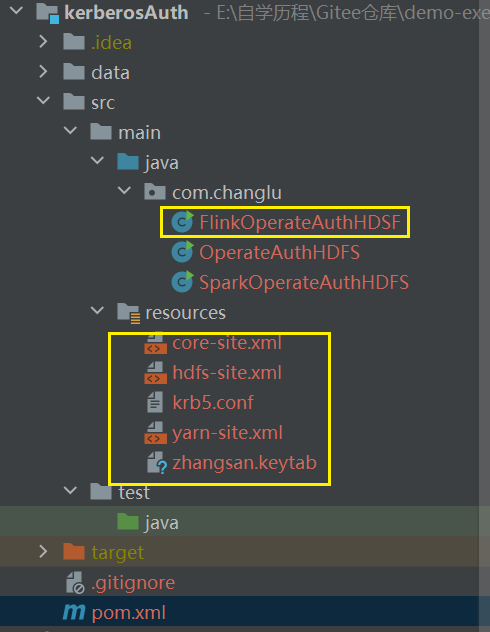
将HDFS中【node1】的core-site.xml 、hdfs-site.xml 、yarn-site.xml文件及Hive客户端配置hive-site.xml上传到项目resources资源目录中。
3、添加Spark对应的maven依赖
在IDEA项目中将hive-jdbc依赖进行注释,该包与SparkSQL读取Hive中的数据的包有冲突,向maven依赖中导入如下依赖包:
<!-- Spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.4.0</version>
</dependency>
4、编写 SparkSQL 读取txt文件内容
首先使用【node5】来创建文件并上传到hdfs:
cd ~
# 编辑wc.txt文件
vim wc.txt
# 将本地文件进行上传
hdfs dfs -put ./wc.txt /
# 查看目录
hdfs dfs -ls /
# 查看文件内容
hdfs dfs -cat /wc.txt
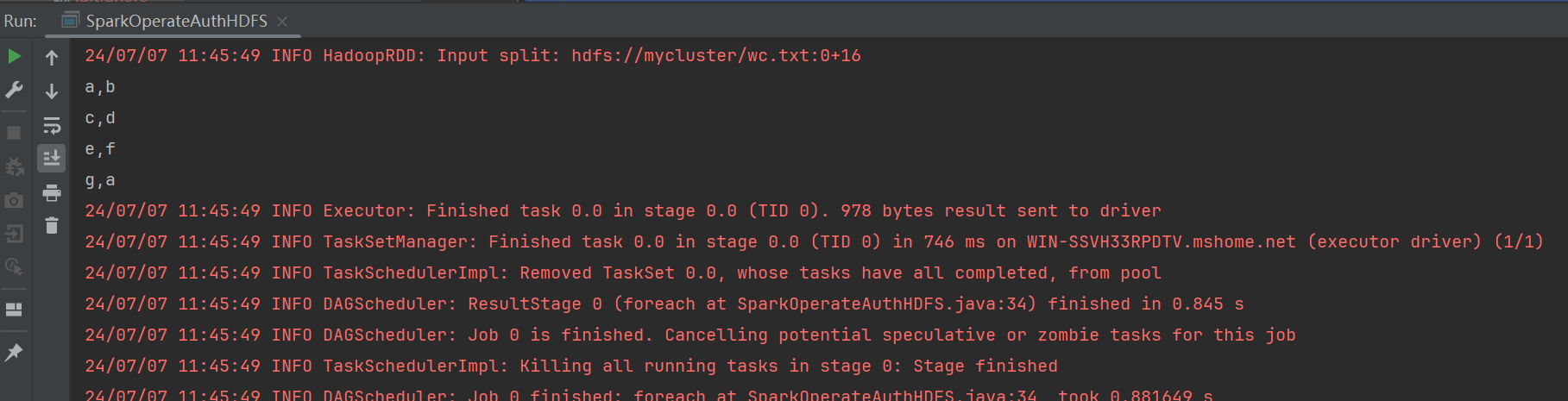
使用spark来去读取文件并逐行打印内容如下:
/**
* @description TODO
* @author changlu
* @date 2024/07/06 20:55
* @version 1.0
*/
package com.changlu;
import com.sun.org.apache.bcel.internal.generic.NEW;
import org.apache.hadoop.security.UserGroupInformation;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
/**
* @description Spark操作kerberos认证的HDFS
* @author changlu
* @date 2024-07-06 20:55
*/
public class SparkOperateAuthHDFS {
public static void main(String[] args) throws Exception {
//进行kerberos认证
System.setProperty("java.security.krb5.conf", "E:\\自学历程\\Gitee仓库\\demo-exer\\bigdata\\kerberos\\kerberosAuth\\kerberosAuth\\src\\main\\resources\\krb5.conf");
String principal = "zhangsan@EXAMPLE.COM";
String keytabPath = "E:\\自学历程\\Gitee仓库\\demo-exer\\bigdata\\kerberos\\kerberosAuth\\kerberosAuth\\src\\main\\resources\\zhangsan.keytab";
UserGroupInformation.loginUserFromKeytab(principal, keytabPath);
//进行spark配置
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("SparkOperateAuthHDFS");
JavaSparkContext jsc = new JavaSparkContext(conf);
//读取指定的hdfs文件,进行逐行打印
jsc.textFile("hdfs://mycluster/wc.txt").foreach(line -> System.out.println(line));
jsc.stop();
}
}
2.5、Flink操作认证的HDFS
与Spark认证相同,需要的配置文件依旧如下:
接着我们引入依赖:
<!-- Flink批和流开发依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.16.0</version>
</dependency>
<!-- DataStream files connector -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.16.0</version>
</dependency>
编写的FlinkOperateAuthHDSF代码如下:
/**
* @description TODO
* @author changlu
* @date 2024/07/07 12:18
* @version 1.0
*/
package com.changlu;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.hadoop.security.UserGroupInformation;
/**
* @description Flink安全认证
* @author changlu
* @date 2024-07-07 12:18
*/
public class FlinkOperateAuthHDSF {
public static void main(String[] args) throws Exception {
//进行kerberos认证
System.setProperty("java.security.krb5.conf", "E:\\自学历程\\Gitee仓库\\demo-exer\\bigdata\\kerberos\\kerberosAuth\\kerberosAuth\\src\\main\\resources\\krb5.conf");
String principal = "zhangsan@EXAMPLE.COM";
String keytabPath = "E:\\自学历程\\Gitee仓库\\demo-exer\\bigdata\\kerberos\\kerberosAuth\\kerberosAuth\\src\\main\\resources\\zhangsan.keytab";
UserGroupInformation.loginUserFromKeytab(principal, keytabPath);
//flink流式处理
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FileSource<String> fileSource = FileSource.forRecordStreamFormat(
new TextLineInputFormat(),
new Path("hdfs://mycluster/wc.txt")
).build();
DataStreamSource<String> dataStream = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "file-source");
dataStream.print();
env.execute();
}
}
说明:其中使用的wc.txt文件与5.4中使用的一致,见5.4即可。
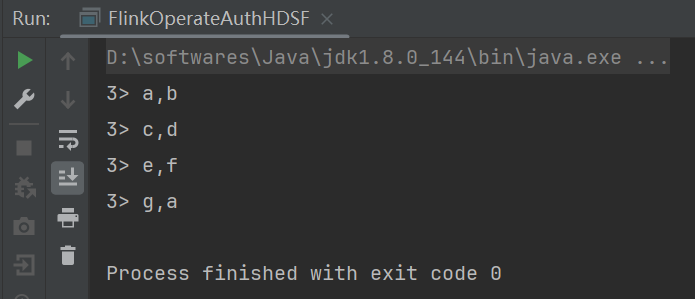
运行下代码,测试结果如下: