智谱 AI 长期专注于大模型技术的研究,从 23 年开始,大模型受到了各行各业的关注,智谱 AI 也深度的参与到各种场景的大模型应用的建设当中,积累了丰富的模型落地应用的实战经验,其中 RAG 类应用占据了较大的比重。
所谓 RAG,简单来说,包含三件事情。第一,Indexing。即怎么更好地把知识存起来。第二,Retrieval。即怎么在大量的知识中,找到一小部分有用的,给到模型参考。第三,Generation。即怎么结合用户的提问和检索到的知识,让模型生成有用的答案。
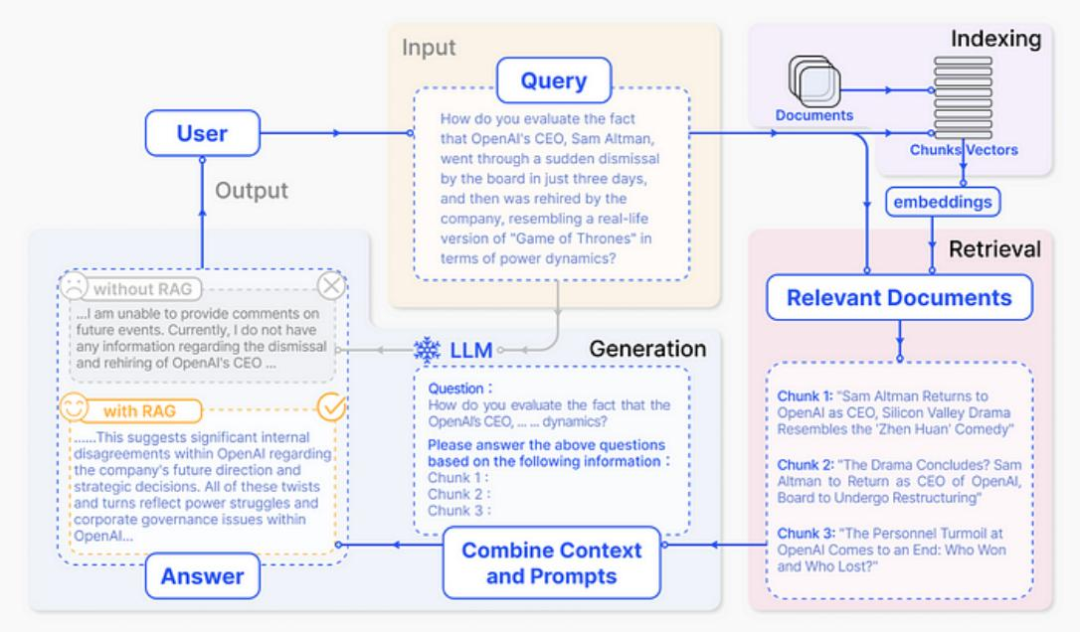
这三个步骤虽然看似简单,但在 RAG 应用从构建到落地实施的整个过程中,涉及较多复杂的工作内容。为此,智谱 AI 组建了一支专业团队,专注于打造企业服务场景的 RAG 系统,致力于为客户提供全面的支持与服务。

那么使用 RAG,有哪些优势呢?我们总结有以下几个方面:
1.与直接跟大模型对话的方法相比,RAG 可以更好地解决模型的幻觉、知识更新不及时等问题。
2.与传统的 FAQ 或者搜索的方式相比,RAG 可以显著降低实施成本。例如传统需要人工整理的 FAQ 的场景,今天我们只需要把手册资料交给 RAG,就能实现高效准确的问答。
3.相较于大模型直接生成内容的方式,基于 RAG 的生成可以追溯到内容的来源,知道答案具体来源于哪条知识。大模型就像是计算机的 CPU,负责计算答案;而知识库就像是计算机的硬盘,负责存储知识,这种计算和存储分离的架构,便可以对知识回答的范围进行权限管理。
4.目前大模型已具备了处理长上下文的能力,然后,如果每次问答都需要把几十万字的文档输入进去,那么会导致问答的成本成倍增加,特别是在客服场景。实际上我们只需要使用整个文档中一个很小的片段,就可以完成任务。所以在同样精度的情况下,利用 RAG 技术可以大大地降低整个成本。
智谱 -RAG 解决方案
技术方案
下图是技术方案的全景图
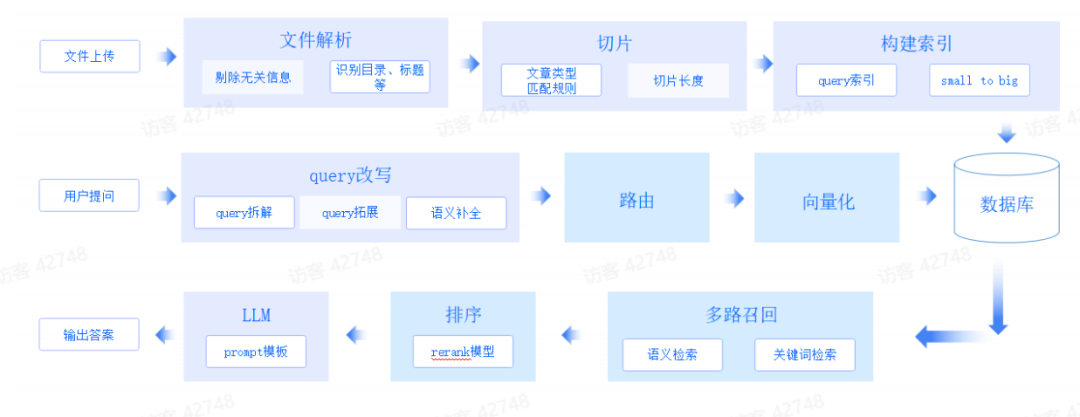
整个技术方案包括三个层面:文件上传、用户提问和答案输出。这三个层面都需要有大量的工程和策略的工作去进行打磨。
以文件上传为例。在文件解析过程中,我们需要将无关的信息(页眉页脚等)过滤掉、将图片改写成特定标识符、将表格改写成模型易于理解的 html 格式等操作。同时,我们会对目录、标题等进行识别,有效提取文档的结构信息;也会对文件中的序列信息进行识别,以确保知识的连续完整。
此外,Embedding 模型本身因为有窗口限制,文档切片过大会导致检索信息不准确。为了解决这个问题,我们采用了 small to big 的策略,即在原始文档切片基础上,扩展了更多粒度更小的文档切片。检索文档时如果检索到粒度细致的切片,会递归检索到其原始大切片,然后再将原始节点做为检索结果提交给 LLM。
产品方案
下面是产品方案的全景图
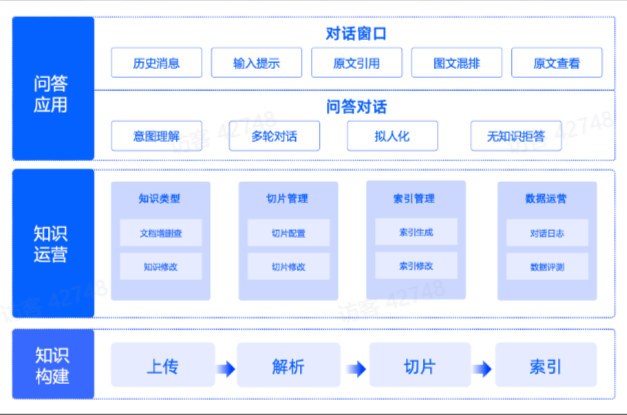
在知识构建过程,我们提供了包括知识类型管理、切片管理、索引管理和数据运营等知识运营和管理的工具,以此来辅助提升企业服务场景的落地效果。
在知识问答过程,我们提供了包括历史消息、输入提示、原文索引、图文混排、原文查看等功能,以此来加强用户对模型回复答案的信任。
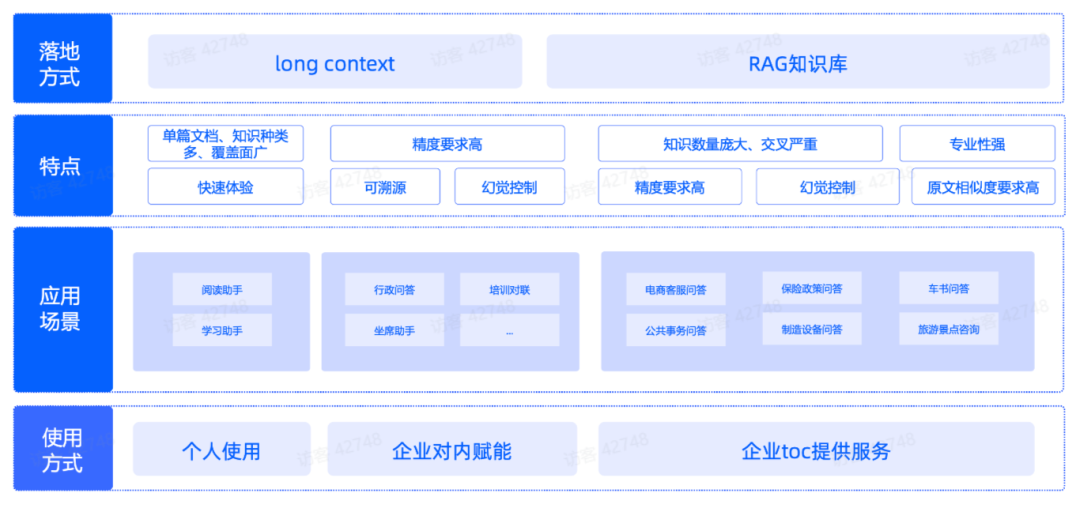
从产品应用层面,一般有三种常见的落地类型,分别为个人使用,企业对内赋能,企业 toC 提供服务等。
智谱 -RAG 在智能客服的实践
下面我以「公共事务客服问答场景」为例,介绍我们在 RAG 上的实践。
这个场景其实大家都比较熟悉。例如 12329 公积金便民热线。针对这样的场景,原来的做法主要是两大技术内容:对话引擎(脚本编排)和文档引擎(检索系统)。

但这样的技术面临着几个痛点:
1.知识整理成本高。例如,公积金领域,全国各市有不同政策。启动项目时,一个城市大约需要 3,000 个 FAQ,运营过程中会增加至 6,000 个,导致高昂的维护成本。
2.知识复用性差。人力专家是能全面解答全国各地的公积金问题,然而原有的智能系统无法跨城市复用知识,缺乏模型上的通用学习能力。
3.知识更新频繁。各市每年都会有年度政策版本出台,每隔几个月还会有补充性政策,增加维护成本。4、知识晦涩难懂。虽然涉及日常场景,但政策内容复杂,不易为大众理解。
此外,在交互层面,也同样存在问题:
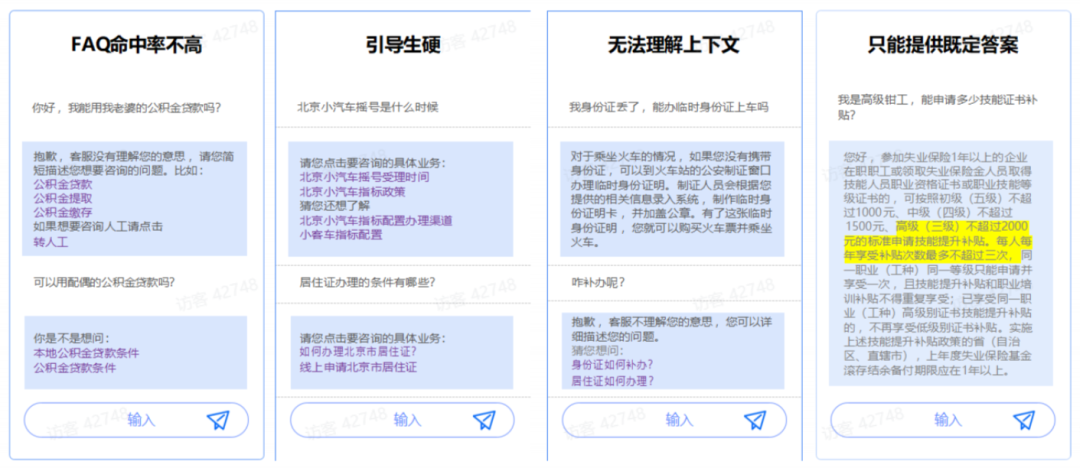
1.FAQ 模式的回答范围有限,无法涵盖所有问题,容易导致用户体验下降。
2.交互方式如电话菜单或文本弹窗缺乏拟人化体验,若无法命中问题,用户会快速失去对智能客服的耐心,转而寻求人工服务。
3.传统 NLP 技术缺乏对人类对话的理解能力,智谱 ChatGLM 大模型原生的就能够理解对话的上下文。
4.旧方法只能提供固定答案,无法针对特定情况精准回答,而智谱 ChatGLM 大模型能够生成有效答案或者推理生成更有针对性的答案。
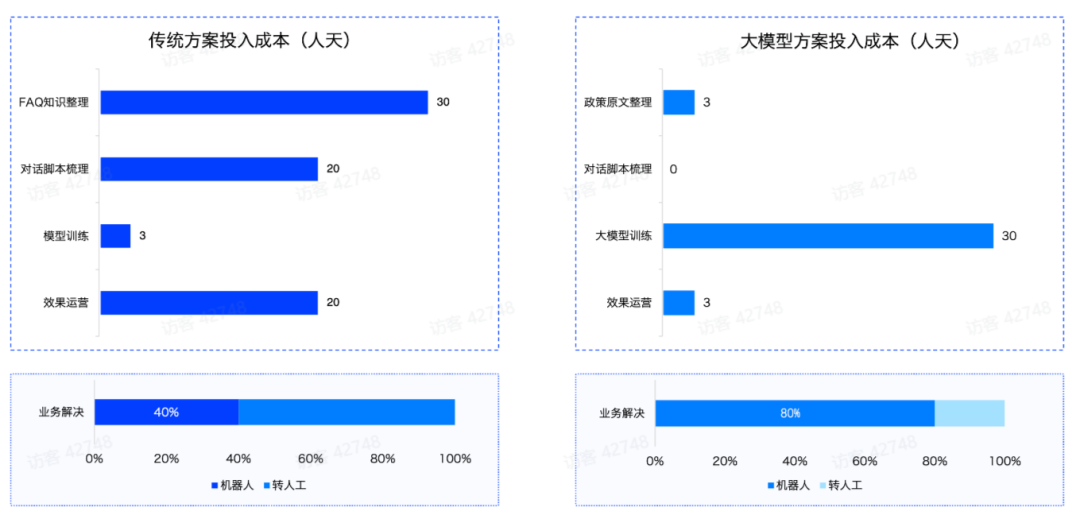
针对同样的场景问题,智谱通过“ChatGLM 大模型 +RAG”的方案来解决。整个成本和效果可以有大幅提升如,下图所示:
此项目面临如下几个技术挑战:
Embedding
第一个挑战是知识召回。
- 切片问题:传统按长度切片方法效果不佳,因为政策内容知识密度高,每句话都可能包含答案,且条款间关联性强,需要连续多个条款才能完整回答问题。
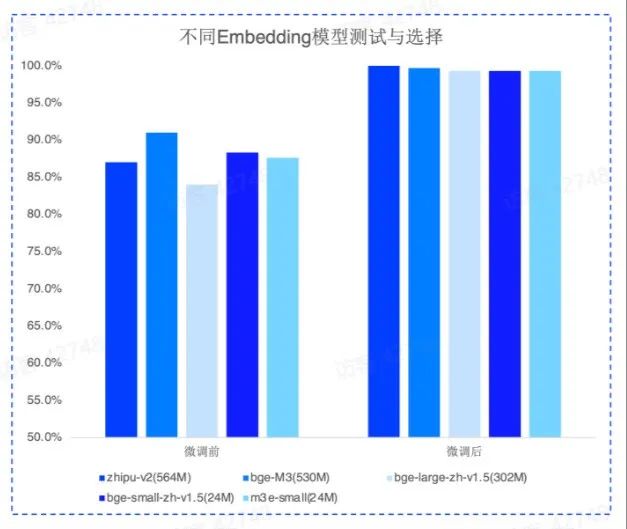
- Embedding 微调:通用 Embedding 模型不足以应对用户口语化严重的问题,需要针对具体业务场景进行微调,以过滤无关信息并提高准确度。
针对前者,我们采用文章结构切片以及 small to big 的索引策略可以很好地解决。针对后者,则需要对 Embedding 模型进行微调。我们有四种不同的构造数据的方案,在实践中都有不错的表现:
- Query vs Original:简单高效,数据结构是直接使用用户 query 召回知识库片段;
- Query vs Query:便于维护,即使用用户的 query 召回 query,冷启动的时候可以利用模型自动化从对应的知识片段中抽取 query;
- Query vs Summary:使用 query 召回知识片段的摘要,构建摘要和知识片段之间的映射关系;
- F-Answer vs Original:根据用户 query 生成 fake answer 去召回知识片段。
经过微调后的 Embedding 模型在召回上会有大幅地提升。top 5 召回达到 100%,而且不同 Embedding 模型微调后的召回差异在 1 个点之内,模型的参数规模影响极小。
SFT&DPO
另外一个挑战是答案生成。在生成环节中,我们面临以下数据挑战:
- 数据标注难度大:业务人员虽然知道正确答案,但难以标注出满足一致性和多样性要求的模型微调数据。因此,我们需要在获取基础答案后,通过模型润色改写答案或增加 COT 的语言逻辑,以提高数据的多样性和一致性。
- 问答种类多样:业务需要模型能够正确回答、拒答不相关问题和反问以获取完整信息。这要求我们通过构造特定的数据来训练提升模型在这些方面的能力。
- 知识混淆度高:在问答场景中,召回精度有限,模型需要先从大量相关知识片段中找到有效答案,这个过程在政务等领域难度很大,需要通过增加噪声数据来强化模型的知识搜索能力。
- 答案专业度高:在公共服务的客服场景,答案往往没有绝对准确性,资深的客服人员总能给出更有帮助性的答案。用户问题通常含糊,更加考验专业人员的回答能力。因此我们需要通过 DPO 方式训练模型,使模型能够在众多答案中找到最好最优的答案。为此,我们需要分别构造数据,并针对模型做 SFT 和 DPO。
在构造数据时,通常情况下,提供更多的高质量训练数据,微调效果越好。反之,如果训练数据中存在错误、瑕疵,将对微调效果产生一定的负面影响。
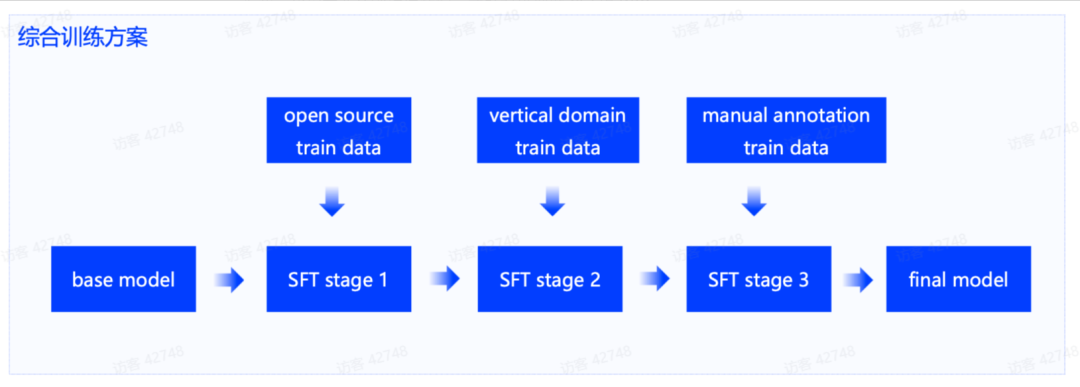
当构造了优质的数据后,模型微调上,我们一般会采用分阶段微调,即首先用开源通用问答数据进行微调,然后用垂域问答数据微调,最后用人工标注的高质量问答数据进行微调。
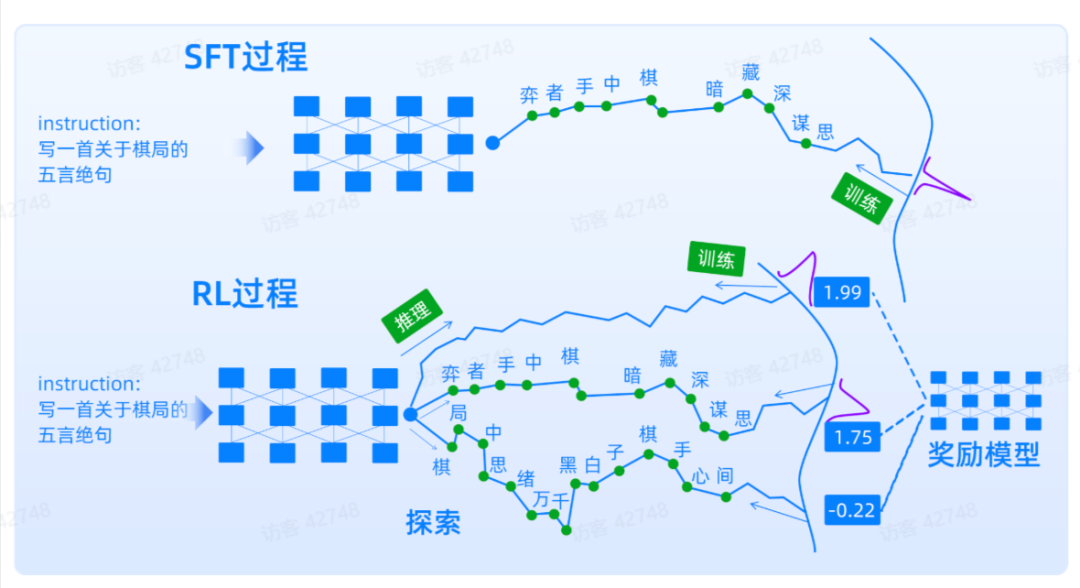
DPO 的训练目标就是让正样本概率加大,负样本概率变低。不仅教会模型什么是好的,也会告诉模型什么是差的。对于问答类场景非常有效果,从而让模型能够更好地向人类的真实需求进行对齐。
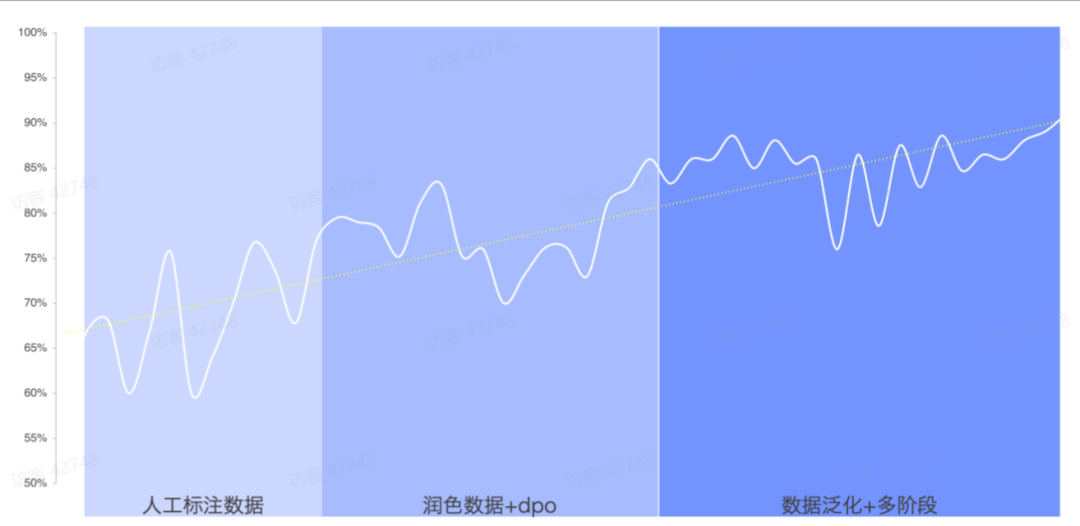
通过以上的方案,我们能够将原本只有 60% 左右的正确率,提升到 90% 以上。
评测
评测是模型训练过程中的指南针,好的评测集可以快速的帮助我们找到优化的方向,拉齐算法和业务之间的分歧。构建评测数据集要确保遵循几个原则:
- 真实性:评测集要能真实的反应业务实际需求,与实际发生的业务场景一致。例如评测问题应该尽量覆盖用户平时会问的问题,保持用户平时对问题的表述风格。
- 多样性:评测集要能够覆盖不同的业务内容,包括:不同的用户输入类型、期待的输出类型、以及答案生成的逻辑等。
- 等比例:评测集各种类型数据的分布比例应与实际业务场景接近,如果已有线上数据的可以根据线上数据抽样。
- 难度区分:生成式模型模拟人脑的思路来推断答案,题目的难度是一个非常重要的维度。业务人员往往很难系统的梳理这些难度,所以我们的算法同学需要主动的引导,构造出覆盖不同难度问题的评测集。
结尾
展望未来,RAG 技术将会在更多领域得到应用,并与其它 AI 技术相结合,例如多模态交互、个性化推荐、用户长期记忆等。智谱 AI 将继续致力于 RAG 技术的探索与实践,为企业在更多的领域落地大模型应用,提供更加智能、高效的服务体验。













![[Linux]对Linux中的命令的本质](https://i-blog.csdnimg.cn/direct/19e54adb69734bd3a4c20737ef94f7ee.png)


