文章目录
- 1 前言
- 2 you-get
- 2.1 安装
- 2.2 简单使用
- 2.3 扩展
- 3 下载网页视频
- 3.1 概述
- 3.2 下载网页
- 4 代码
1 前言
过年了,想给家里长辈下几首戏曲,于是找到一个发布戏曲的网站,虽然可以通过IDM插件的资源嗅探来一一下载,但是内容太多,便想通过爬虫的方式来批量下载视频。
2 you-get
由于此前从未接触过爬虫,因此首先从“如何下载网页视频”开始检索,发现you-get是一个非常好用的工具,而且使用不是很复杂,于是便决定使用这个工具。
2.1 安装
you-get是python中的一个第三方包,可以直接通过pip install you-get来进行安装。安装完之后,在命令行中输入you-get -h,不报错表明安装成功。
之所以一个python第三方包可以直接在命令行运行,是因为它安装到pip所在文件夹了,如下图所示,这样能直接用pip即可直接用you-get。

除安装这个第三方包外,you-get的运行还需要依赖一个软件——ffmpeg。
首先打开ffmpeg的官网https://www.ffmpeg.org/,根据下图下载Windows系统下的安装程序。
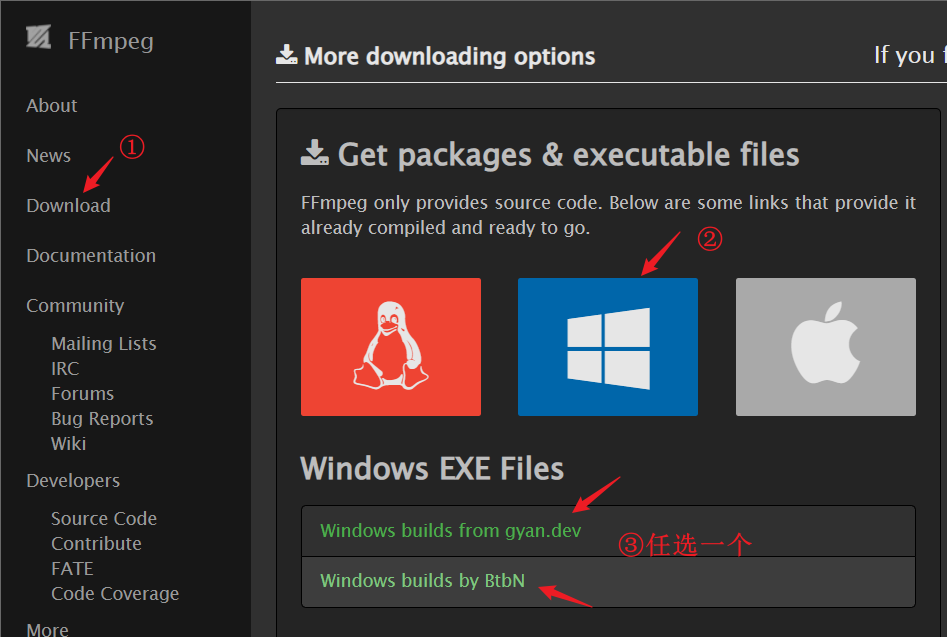
安装完成后,要将bin文件夹添加到环境变量,这一步一定不要漏掉!
2.2 简单使用
you-get最简单的使用方式就是you-get [视频链接],不过需要注意的是,这里的视频链接不是网页的链接,同时也不是IDM下载视频的那个下载链接。根据GitHub官网的说明可以发现,YouTube上的视频是可以直接用you-get下载的:
$ you-get 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
stream:
- itag: 43
container: webm
quality: medium
size: 0.5 MiB (564215 bytes)
# download-with: you-get --itag=43 [URL]
Downloading Me at the zoo.webm ...
100% ( 0.5/ 0.5MB) ├██████████████████████████████████┤[1/1] 6 MB/s
Saving Me at the zoo.en.srt ... Done.
此外,B站的视频链接也是可以直接通过you-get下载到原视频的。其他的视频平台有待大家继续探索。
2.3 扩展
其实除了用you-get去下载视频外,ffmpeg的其他功能也是非常强大,比如它可以用来合并视频,压缩视频等操作。具体可以参考这篇博客,讲得还是很详细的。
3 下载网页视频
3.1 概述
前面提到,有一些视频平台的网址即是视频链接,可以直接通过you-get下载,但是更多的网页中的视频链接是需要对HTML解析之后才能找到的。而上面提到的戏曲网站也属于这一种。
另外,还需要注意,这里可以通过you-get下载的视频链接似乎并不是IDM下载的链接,具体的区别有待继续研究。
3.2 下载网页
提到python爬虫,一般都绕不过一个库:requests,它可以获取某个网址对应的网页的HTML,但是很多网站的视频链接并不是在HTML中,而是在引入的js文件中。而js在网页打开时是会运行的,从而得到网页中的各个元素。
注意,这里的元素和源代码是有很大区别的。打开某个网页,按下F12,可以看到两栏分别是元素和源代码。源代码就只包含了HTML文件及其附带的js源码,而元素则是源代码执行之后得到的结果。
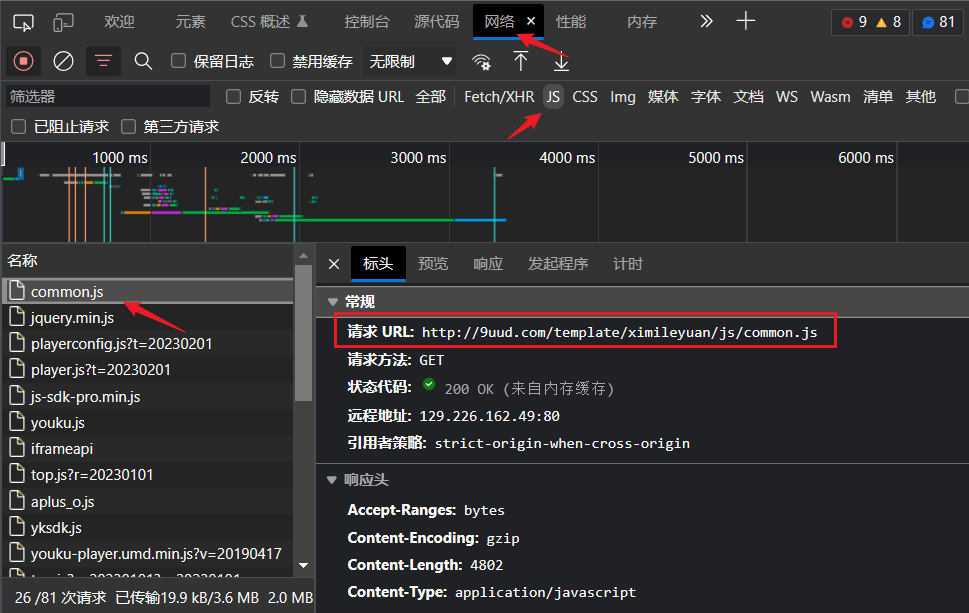
我们在使用requests模块时,如果给定的请求链接就是网址的话,只能得到这个网页的HTML文件,如果要获取js的源码,可以在网络标签页中找到,如下图所示。
那问题来了,上面这几种方式得到的都是网页的源码,即HTML或者js,那有没有什么办法可以得到js运行后的结果呢?查找资料后得知,可以是用python模拟浏览器环境,从而运行js文件,得到运行结果。但是这种方式代码会非常的臃肿。此外,就是在浏览器中打开开发者模式(F12),然后刷新网页,再在网络标签栏中找到刚刚运行的结果,然后把它们的网络请求复制下来,再给到代码中。
4 代码
import requests as req
import re
import subprocess
response = req.get("link") #获取对应网页的js
html = response.text
# print(html)
patter = 'XMT.{12}' # XMT加上后面12个字符,就是每个视频的代码
code = re.findall(patter, html,flags=0) # 获取所有匹配的字符串,生成一个列表
# print(len(code))
# print(code)
for item in code:
# print(item)
link = "https://player.com" + item
cmd = "you-get -f -o D:/1 --format=3gphd " + link
print(cmd)
p = subprocess.Popen(cmd) #能够实现执行完指令再进行下一个
while(p.wait() and p.stderr): # 忙碌时或出错时退出堵塞
print(p.stderr)
pass
print("down!")