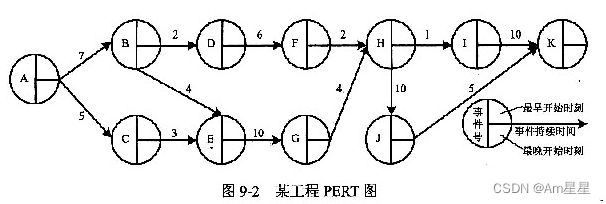
概述
没有看上一期的小伙伴请先看上一期【Flink】浅谈Flink架构和调度,上一期的一个核心内容就是 Flink 中的执行图可以分成四层:StreamGraph → JobGraph → ExecutionGraph → 物理执行图。
今天我们好好谈论一下StreamGraph,StreamGraph 是客户端根据 Flink-API 生成的数据流图,是 Flink 任务执行流程拓扑图的封装。当 Environment对象调用 execute 方法时,我们编写的程序(数据处理流程)就会转变为 StreamGraph。
接下来的分析有些冗长,不需要深入了解的朋友们可以直接跳到最后的结论。
Execute 方法
接下来我们以流式环境【StreamExecutionEnvironment】为例来讨论 StreamGraph 的生成。
上文介绍到当 Environment对象调用 execute 方法的时候,我们编写的程序(数据处理流程)就会转变为 StreamGraph,以下是【StreamExecutionEnvironment】类的源码分析:
// 默认的Flink-Job名称
public static final String DEFAULT_JOB_NAME = "Flink Streaming Job";
// 生成 StreamGraph 的入口
public JobExecutionResult execute() throws Exception {
return execute(getJobName());
}
/*--------------------------------------------------*/
// 一般我们都是调用【getExecutionEnvironment】方法来获取流式运行环境
// 在生成运行环境的时候还会生成配置信息
public static StreamExecutionEnvironment getExecutionEnvironment() {
return getExecutionEnvironment(new Configuration());
}
// 获取 Flink-Job名称
private String getJobName() {
return configuration.getString(PipelineOptions.NAME, DEFAULT_JOB_NAME);
}
// Configuration 的核心是有一个HashMap对象,用于存储键值对配置信息
public Configuration() {
this.confData = new HashMap<>();
}
/*--------------------------------------------------*/
// execute方法的第一层包装
public JobExecutionResult execute(String jobName) throws Exception {
// 检查一下任务名称
Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");
return execute(getStreamGraph(jobName));
}
// 获取StreamGraph
// jobName:Flink任务名称
public StreamGraph getStreamGraph(String jobName) {
return getStreamGraph(jobName, true);
}
/*--------------------------------------------------*/
// 获取StreamGraph的实际执行方法
// jobName:Flink任务名称
// clearTransformations:是否清除以前注册的transformations
public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) {
// 创建一个StreamGraphGenerator对象,设置参数,并调用generate方法生成StreamGraph对象
StreamGraph streamGraph =
getStreamGraphGenerator()
// 设置任务名称
.setJobName(jobName)
.generate();
// 清除以前注册的transformations
if (clearTransformations) {
this.transformations.clear();
}
return streamGraph;
}
// 获取 StreamGraphGenerator 对象
private StreamGraphGenerator getStreamGraphGenerator() {
// 对transformations的数量进行校验
if (transformations.size() <= 0) {
throw new IllegalStateException(
"No operators defined in streaming topology. Cannot execute.");
}
final RuntimeExecutionMode executionMode = configuration.get(ExecutionOptions.RUNTIME_MODE);
// 向 StreamGraphGenerator传入transformations并进行相关信息的配置
return new StreamGraphGenerator(transformations, config, checkpointCfg, getConfiguration())
// 设置运行时配置
.setRuntimeExecutionMode(executionMode)
// 设置状态后端
.setStateBackend(defaultStateBackend)
// 设置保存点路径
.setSavepointDir(defaultSavepointDirectory)
// 设置算子链优化
.setChaining(isChainingEnabled)
// StreamExecutionEnvironment的cacheFile会传入该变量
// cacheFile是需要分发到各个TM的用户文件
.setUserArtifacts(cacheFile)
// 设置时间意义
.setTimeCharacteristic(timeCharacteristic)
// 设置超时时间
.setDefaultBufferTimeout(bufferTimeout);
}
// generate 方法
public StreamGraph generate() {
// 创建一个初始的 streamGraph 对象
streamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);
// shouldExecuteInBatchMode是一个布尔值,用来表示是否使用Batch模式
shouldExecuteInBatchMode = shouldExecuteInBatchMode(runtimeExecutionMode);
configureStreamGraph(streamGraph);
// 储存已经被处理的transformation
alreadyTransformed = new HashMap<>();
// 逐个处理transformation,实际就是尾StreamGraph生成各个节点(Node)
for (Transformation<?> transformation : transformations) {
transform(transformation);
}
for (StreamNode node : streamGraph.getStreamNodes()) {
if (node.getInEdges().stream().anyMatch(edge -> edge.getPartitioner().isPointwise())) {
for (StreamEdge edge : node.getInEdges()) {
edge.setSupportsUnalignedCheckpoints(false);
}
}
}
// 获取生成完毕的streamGraph
final StreamGraph builtStreamGraph = streamGraph;
// 清除中间变量
alreadyTransformed.clear();
alreadyTransformed = null;
streamGraph = null;
return builtStreamGraph;
}
我们简略画一下上述过程的时序图以更好的帮助大家理解其过程;
总结一下调用 execute 的流程:
- 根据代码和配置信息生成 StreamGraphGenerator 对象;
- StreamGraphGenerator 对象调用
generate()方法生成 StreamGraph 对象,底层操作是遍历transformations集合,创建StreamNode和StreamEdge,构造 StreamGraph对象; - 根据 StreamGraph 对象执行;
我们可以看到在 generate() 方法中生成节点时使用的是【Transformation】对象,那么这个对象是什么呢?在创建 StreamGraphGenerator 对象时我们传递了一个重要参数transformations,它是 env 的成员变量之一,用一个 List<Transformation<?>> 对象来保存。Transformation 对象代表了一个或多个 DataStream 生成新 DataStream 的操作,也可以理解为是数据流处理环节中的一步,更简单的说话就是一个算子或者多个算子的组合。
A Transformation represents the operation that creates a DataStream. Every DataStream has an underlying Transformation that is the origin of said DataStream.
API operations such as DataStream#map create a tree of Transformations underneath. When the stream program is to be executed this graph is translated to a StreamGraph using StreamGraphGenerator.
算子的底层实现
既然明确了【Transformation】对象的本质就是生成 DataStream 的一个或者一组算子,那么我们来看看 Flink 中各个算子的底层究竟是什么样子。
以 map 为例,它的源码分析如下:
/*--------------------- DataStream -----------------------------*/
// DataStream类
public class DataStream<T> {
// 运行环境
protected final StreamExecutionEnvironment environment;
// 生成该DataStream的transformation
protected final Transformation<T> transformation;
...
}
/*-------------------------------------------------------------*/
// map方法入口
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper) {
// 获取Mapper函数的返回类型
TypeInformation<R> outType =
TypeExtractor.getMapReturnTypes(
clean(mapper), getType(), Utils.getCallLocationName(), true);
// 返回SingleOutputStreamOperator
return map(mapper, outType);
}
// map方法核心
// mapper:MapFunction
// outputType:mapper函数的返回类型
public <R> SingleOutputStreamOperator<R> map(
MapFunction<T, R> mapper, TypeInformation<R> outputType) {
return transform("Map", outputType, new StreamMap<>(clean(mapper)));
}
// operatorName:算子名称
// outTypeInfo:算子返回类型信息
// operator:包含转换逻辑的算子
public <R> SingleOutputStreamOperator<R> transform(
String operatorName,
TypeInformation<R> outTypeInfo,
OneInputStreamOperator<T, R> operator) {
return doTransform(operatorName, outTypeInfo, SimpleOperatorFactory.of(operator));
}
// operatorName:算子名称
// outTypeInfo:算子返回类型信息
// operatorFactory:算子工厂
protected <R> SingleOutputStreamOperator<R> doTransform(
String operatorName,
TypeInformation<R> outTypeInfo,
StreamOperatorFactory<R> operatorFactory) {
// 如果transformation的输出类型为MissingTypeInfo的话,程序会抛异常
transformation.getOutputType();
// 构造新的transformation
// map类型的transformation只有一个输入,因此它输入OneInputTransformation
// 新的transformation会连接上当前DataStream中的transformation,从而构建成一棵树
// 生成StreamGraph依赖于transformation构建的树
OneInputTransformation<T, R> resultTransform =
new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({"unchecked", "rawtypes"})
SingleOutputStreamOperator<R> returnStream =
new SingleOutputStreamOperator(environment, resultTransform);
// 将transformation写入ExecutionEnvironment中
// ExecutionEnvironment维护了一个叫做transformations的ArrayList对象,用于储存所有的transformation
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
/// 获取运行环境
public StreamExecutionEnvironment getExecutionEnvironment() {
return environment;
}
/*--------------- StreamExecutionEnvironment -----------------*/
// 保存所有的transformation
protected final List<Transformation<?>> transformations = new ArrayList<>();
// 向env中添加transformation
public void addOperator(Transformation<?> transformation) {
Preconditions.checkNotNull(transformation, "transformation must not be null.");
this.transformations.add(transformation);
}
/*-------------------------------------------------------------*/
/*---------------- OneInputTransformation ----------------------*/
public class OneInputTransformation<IN, OUT> extends PhysicalTransformation<OUT> {
// 前一个Transformation的指针
private final Transformation<IN> input;
// 封装的StreamOperator工厂
private final StreamOperatorFactory<OUT> operatorFactory;
...
}
/*-------------------------------------------------------------*/
现在我们小结一下,将几个名词做一下统一的梳理:
- Transformation:描述一个 DataStream 的生成的对象,内部对算子进行了封装;
- StreamOperator:DataStream 上的每一个 transformation 内部都对应了一个 StreamOperator,StreamOperator 是运行时的具体实现。
基于上述分析,一个 StreamGraph 的生成逻辑链如下:
- 每一个算子的底层都是一个 Operator,先封装到 OperatorFactory 中,然后用一个 Transformation 对象进行封装;
- 每一个 Transformation 通过【input】指针连接在一起构成一个树;
- 通过 Transformation 树构造一个 StreamGraph;
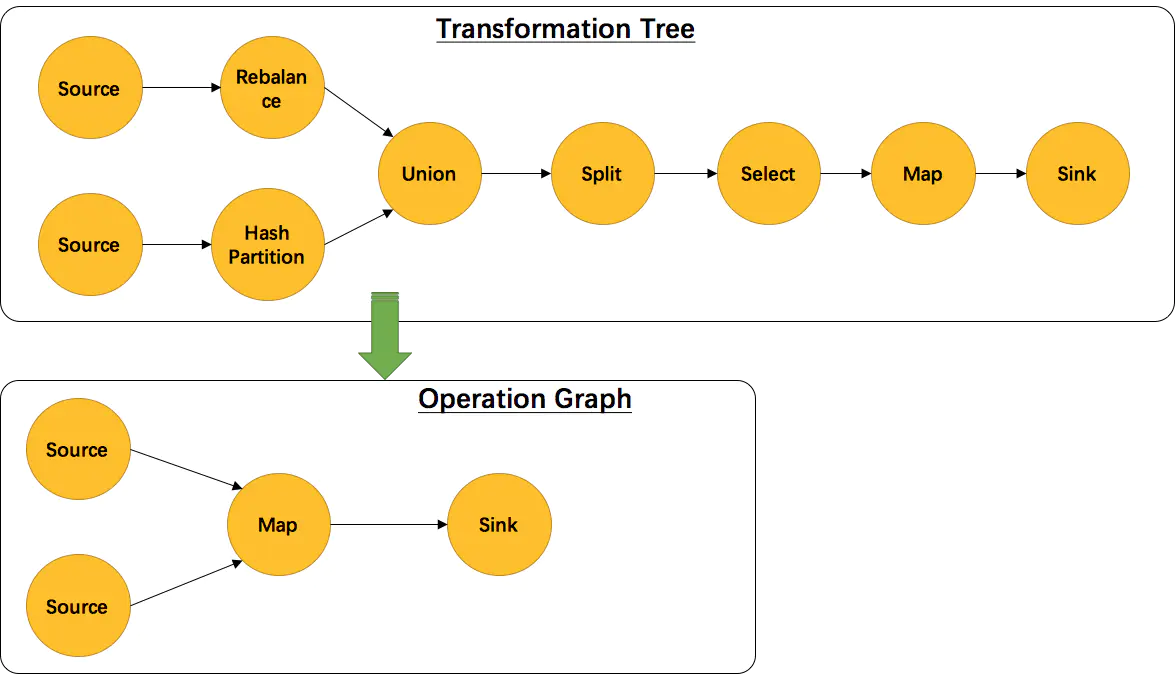
为了更好的理解上述过程,以 map 算子为例,其 Transformation 树如下:

一个更加通用的算子实现简图如下:

需要注意的一点是并不是每一个 Transformation 都会被转换成 StreamGraph 的实体节点,有一些逻辑概念,比如 union、split、partition 等,官方的示例如下:
StreamOperator
DataStream 上的每一个 Transformation 都对应了一个 StreamOperator,StreamOperator 是运行时的具体实现,会决定 UDF (User-Defined Funtion) 的调用方式。下图所示为 StreamOperator 的继承关系:

Transformation
OneInputTransformation
顾名思义 OneInputTransformation 只有一个输入,它主要包装 map、flatmap、filter 等算子。
TwoInputTransformation
TwoInputTransformation 具有两个输入。ConnectedStream 的算子为双流运算,它的算子会被转换为 TwoInputTransformation。
SourceTransformation
在环境中配置数据源的时候会创建一个 DataStreamSource 对象。该对象为 DataStream 的源头。在 DataStreamSource 的构造函数中就会创建一个 SourceTransformation 对象;
SinkTransformation
同 SourceTransformation,DataStream 对象添加 sink 源的时候就会生成一个 DataStreamSink 对象,同时构造一个 SinkTransformation 对象。
UnionTransformation
UnionTransformation 合并多个 input 到一个流中。代表算子为 union。
FeedbackTransformation
创建 IterativeStream 的时候会使用到 FeedbackTransformation,它实质上表示拓扑中的反馈节点。
CoFeedbackTransformation
创建 ConnectedIterativeStream 的时候会使用到 CoFeedbackTransformation。
PartitionTransformation
涉及到控制数据流向的算子都属于 PartitionTransformation,例如 shuffle,forward,rebalance,broadcast,rescale,global,partitionCustom 和 keyBy 等。
SideOutputTransformation
当获取侧输出流的时候会生成 SideOutputTransformation。
示例
现在来看一下官方的 SocketWindowWordCount 示例,该示例的数据处理流程是【Source→Flat Map→Hash (keyBy)→TriggerWindow→Sink】, 那么它的 Transformations 树如下,其中 * 代表 input 指针;
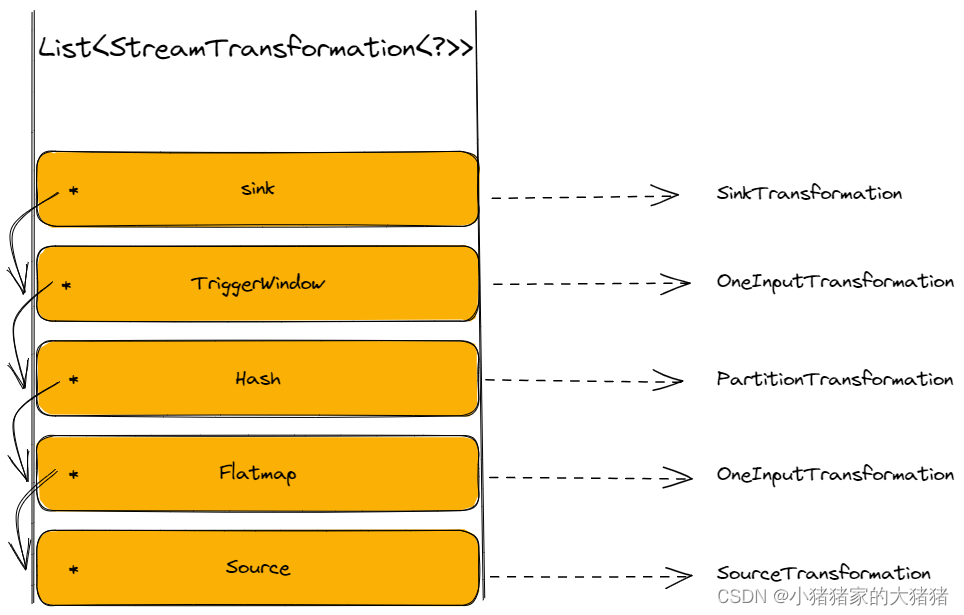
StreamGraph 的生成
在搞清楚 Transformations 树如何构建之后,我们就要讨论一下 StreamGraph 的生成问题。上面也介绍了生成 StreamGraph 的流程,就是先生成节点,然后生成边,废话不多说,源码分析如下:
// transform方法
private Collection<Integer> transform(Transformation<?> transform) {
// 如果一个 Transformation 已经被处理,那么直接返回
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
// 如果transformation的最大并行度没有设置,全局的最大并行度已设置,将全局最大并行度设置给transformation
if (transform.getMaxParallelism() <= 0) {
// if the max parallelism hasn't been set, then first use the job wide max parallelism
// from the ExecutionConfig. int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism();
if (globalMaxParallelismFromConfig > 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
// 检查transformation的输出类型,如果是MissingTypeInfo则程序抛出异常
transform.getOutputType();
// 根据Transformation 获取translator
@SuppressWarnings("unchecked")
final TransformationTranslator<?, Transformation<?>> translator =
(TransformationTranslator<?, Transformation<?>>)
translatorMap.get(transform.getClass());
// 使用translator进行转换
Collection<Integer> transformedIds;
if (translator != null) {
transformedIds = translate(translator, transform);
} else {
transformedIds = legacyTransform(transform);
}
// 应为有反馈边的存在,所以需要进行这一步检查
// 防止递归情况下的重复
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
return transformedIds;
}
private Collection<Integer> translate(
final TransformationTranslator<?, Transformation<?>> translator,
final Transformation<?> transform) {
checkNotNull(translator);
checkNotNull(transform);
final List<Collection<Integer>> allInputIds = getParentInputIds(transform.getInputs());
// 防递归调用
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
// 获取共享Slot组
final String slotSharingGroup =
determineSlotSharingGroup(
transform.getSlotSharingGroup(),
allInputIds.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList()));
// 获取上下文对象
final TransformationTranslator.Context context =
new ContextImpl(this, streamGraph, slotSharingGroup, configuration);
// 根据Batch模式还是Streaming模式进行转换
// 就需要两个参数一个transform,一个context(上下文)
return shouldExecuteInBatchMode
? translator.translateForBatch(transform, context)
: translator.translateForStreaming(transform, context);
}
/*---------------- StreamGraphGenerator --------------------*/
// 使用一个HashMap保存各个Transformation的转换器
private static final Map<
Class<? extends Transformation>,
TransformationTranslator<?, ? extends Transformation>>
translatorMap;
// 在一个静态代码块中添加Transformation-TransformationTranslator
static {
@SuppressWarnings("rawtypes")
Map<Class<? extends Transformation>, TransformationTranslator<?, ? extends Transformation>>
tmp = new HashMap<>();
tmp.put(OneInputTransformation.class, new OneInputTransformationTranslator<>());
tmp.put(TwoInputTransformation.class, new TwoInputTransformationTranslator<>());
tmp.put(MultipleInputTransformation.class, new MultiInputTransformationTranslator<>());
tmp.put(KeyedMultipleInputTransformation.class, new MultiInputTransformationTranslator<>());
tmp.put(SourceTransformation.class, new SourceTransformationTranslator<>());
tmp.put(SinkTransformation.class, new SinkTransformationTranslator<>());
tmp.put(LegacySinkTransformation.class, new LegacySinkTransformationTranslator<>());
tmp.put(LegacySourceTransformation.class, new LegacySourceTransformationTranslator<>());
tmp.put(UnionTransformation.class, new UnionTransformationTranslator<>());
tmp.put(PartitionTransformation.class, new PartitionTransformationTranslator<>());
tmp.put(SideOutputTransformation.class, new SideOutputTransformationTranslator<>());
tmp.put(ReduceTransformation.class, new ReduceTransformationTranslator<>());
tmp.put(
TimestampsAndWatermarksTransformation.class,
new TimestampsAndWatermarksTransformationTranslator<>());
tmp.put(BroadcastStateTransformation.class, new BroadcastStateTransformationTranslator<>());
tmp.put(
KeyedBroadcastStateTransformation.class,
new KeyedBroadcastStateTransformationTranslator<>());
// 赋给成员变量translatorMap
translatorMap = Collections.unmodifiableMap(tmp);
}
/*-------------------------------------------------------------*/
从上面的分析可以看到,想要生成 StreamGraph 的一个节点,需要一个 Context 对象和 Transformation 对象,并且每一个转换器会根据运行模式的不同进行不同的转换,所有的转换器都实现了 TransformationTranslator 接口,它的源码分析如下:
public interface TransformationTranslator<OUT, T extends Transformation<OUT>> {
// 批处理模式下的转换方法
// transformation:要转换的Transformation;
// context:上下文对象,给转换提供必要信息
Collection<Integer> translateForBatch(final T transformation, final Context context);
// 流式处理模式下的转换方法
// transformation:要转换的Transformation;
// context:上下文对象,给转换提供必要信息
Collection<Integer> translateForStreaming(final T transformation, final Context context);
// 上下文接口
interface Context {
// 返回正在创建的 StreamGraph
StreamGraph getStreamGraph();
// 根据Transformation对象返回节点ID
Collection<Integer> getStreamNodeIds(final Transformation<?> transformation);
// 根据给定的Transformations返回Slot共享组
String getSlotSharingGroup();
// 返回默认超时时间
long getDefaultBufferTimeout();
// 返回额外配置信息
ReadableConfig getGraphGeneratorConfig();
}
}
接下来我们以 OneInputTransformationTranslator 来进一步说明转换流程,它的源码分析如下:
// 流模式下的转换方法
public Collection<Integer> translateForStreamingInternal(
final OneInputTransformation<IN, OUT> transformation, final Context context) {
return translateInternal(
transformation,
transformation.getOperatorFactory(),
transformation.getInputType(),
transformation.getStateKeySelector(),
transformation.getStateKeyType(),
context);
}
protected Collection<Integer> translateInternal(
final Transformation<OUT> transformation,
final StreamOperatorFactory<OUT> operatorFactory,
final TypeInformation<IN> inputType,
@Nullable final KeySelector<IN, ?> stateKeySelector,
@Nullable final TypeInformation<?> stateKeyType,
final Context context) {
checkNotNull(transformation);
checkNotNull(operatorFactory);
checkNotNull(inputType);
checkNotNull(context);
// 由context对象获取StreamGraph对象
final StreamGraph streamGraph = context.getStreamGraph();
// 由context对象获取slot共享组
final String slotSharingGroup = context.getSlotSharingGroup();
// 获取Transformation对象的ID
final int transformationId = transformation.getId();
// 获取运行时配置信息
final ExecutionConfig executionConfig = streamGraph.getExecutionConfig();
// 添加 Operator
streamGraph.addOperator(
transformationId,
slotSharingGroup,
transformation.getCoLocationGroupKey(),
operatorFactory,
inputType,
transformation.getOutputType(),
transformation.getName());
if (stateKeySelector != null) {
TypeSerializer<?> keySerializer = stateKeyType.createSerializer(executionConfig);
streamGraph.setOneInputStateKey(transformationId, stateKeySelector, keySerializer);
}
// 获取并行度
int parallelism =
transformation.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT
? transformation.getParallelism()
: executionConfig.getParallelism();
// 设置并行度
streamGraph.setParallelism(transformationId, parallelism);
// 设置最大并行度
streamGraph.setMaxParallelism(transformationId, transformation.getMaxParallelism());
final List<Transformation<?>> parentTransformations = transformation.getInputs();
checkState(
parentTransformations.size() == 1,
"Expected exactly one input transformation but found "
+ parentTransformations.size());
// 添加边信息
for (Integer inputId : context.getStreamNodeIds(parentTransformations.get(0))) {
streamGraph.addEdge(inputId, transformationId, 0);
}
return Collections.singleton(transformationId);
}
/*------------------------ StreamGraph ---------------------------*/
// 添加Operator方法
private <IN, OUT> void addOperator(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
StreamOperatorFactory<OUT> operatorFactory,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName,
Class<? extends AbstractInvokable> invokableClass) {
// 添加节点信息
// 这一步已经创建节点并添加到HashMap中了
addNode(
vertexID,
slotSharingGroup,
coLocationGroup,
invokableClass,
operatorFactory,
operatorName);
// 这一步设置了输入、输出序列化器
setSerializers(vertexID, createSerializer(inTypeInfo), null, createSerializer(outTypeInfo));
// operator工厂设置输出类型,在创建StreamGraph的时候就必须确定
if (operatorFactory.isOutputTypeConfigurable() && outTypeInfo != null) {
operatorFactory.setOutputType(outTypeInfo, executionConfig);
}
// operator工厂设置输入类型
if (operatorFactory.isInputTypeConfigurable()) {
operatorFactory.setInputType(inTypeInfo, executionConfig);
}
// 打印日志
if (LOG.isDebugEnabled()) {
LOG.debug("Vertex: {}", vertexID);
}
}
// 创建序列化器
private <T> TypeSerializer<T> createSerializer(TypeInformation<T> typeInfo) {
// 如果typeInfo是null或者MissingTypeInfo,那么序列化器就是null
// 如果不是则调用typeInfo的createSerializer创建序列化器
return typeInfo != null && !(typeInfo instanceof MissingTypeInfo)
? typeInfo.createSerializer(executionConfig)
: null;
}
// StreamNode设置序列化器
public void setSerializers(
Integer vertexID, TypeSerializer<?> in1, TypeSerializer<?> in2, TypeSerializer<?> out) {
// 根据ID获取 StreamNode 对象
StreamNode vertex = getStreamNode(vertexID);
// StreamNode设置输入序列化器
vertex.setSerializersIn(in1, in2);
// StreamNode设置输出序列化器
vertex.setSerializerOut(out);
}
// 添加节点
protected StreamNode addNode(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
Class<? extends AbstractInvokable> vertexClass,
StreamOperatorFactory<?> operatorFactory,
String operatorName) {
// 检查是否重复添加了同样的节点
if (streamNodes.containsKey(vertexID)) {
throw new RuntimeException("Duplicate vertexID " + vertexID);
}
// 创建StreamNode对象,
StreamNode vertex =
new StreamNode(
vertexID,
slotSharingGroup,
coLocationGroup,
operatorFactory,
operatorName,
vertexClass);
// 使用一个HashMap保存各个vertexID-StreamNode键值对
streamNodes.put(vertexID, vertex);
return vertex;
}
/*-------------------------------------------------------------*/
/*---------------------- StreamNode -----------------------*/
public class StreamNode {
// 节点的最大并行度,用于扩、缩容时的上限,以及分区时候的键组数
private int maxParallelism;
// 节点所需最小资源
private ResourceSpec minResources = ResourceSpec.DEFAULT;
// 节点所需最佳资源
private ResourceSpec preferredResources = ResourceSpec.DEFAULT;
// Operator生成工厂
private StreamOperatorFactory<?> operatorFactory;
// 输入序列化器
private TypeSerializer<?>[] typeSerializersIn = new TypeSerializer[0];
// 输出序列化器
private TypeSerializer<?> typeSerializerOut;
// 节点输入的边
private List<StreamEdge> inEdges = new ArrayList<StreamEdge>();
// 节点输出的边
private List<StreamEdge> outEdges = new ArrayList<StreamEdge>();
// 输入格式器
// 1. 它描述了如何将输入进行并行拆分
// 2. 它描述了如何从输入中读取数据
// 3. 它描述了如何从输入中进行统计
private InputFormat<?, ?> inputFormat;
// 输出格式器
// 它描述了如何将节点结果进行输出
private OutputFormat<?> outputFormat;
// 网络超时时间
private long bufferTimeout;
// 算子名称
private final String operatorName;
// Slot共享组组名
private @Nullable String slotSharingGroup;
...
}
/*---------------------------------------------------------*/
到这一步 StreamGraph 已经完成添加节点的工作,接下来将添加边(各个节点之间的连接)。
/*------------------------ StreamGraph ---------------------------*/
// 用来存储SideOut虚拟节点
private Map<Integer, Tuple2<Integer, OutputTag>> virtualSideOutputNodes;
// 用来存储Partition虚拟节点
private Map<Integer, Tuple3<Integer, StreamPartitioner<?>, ShuffleMode>> virtualPartitionNodes;
// 添加边入口
public void addEdge(Integer upStreamVertexID, Integer downStreamVertexID, int typeNumber) {
addEdgeInternal(
upStreamVertexID,
downStreamVertexID,
typeNumber,
null,
new ArrayList<String>(),
null,
null);
}
// 添加节点之间的连接
private void addEdgeInternal(
Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
List<String> outputNames,
OutputTag outputTag,
ShuffleMode shuffleMode) {
// 当上游是sideOutput时,递归调用,并传入sideOutput信息,递归寻找非virtual节点
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;
if (outputTag == null) {
outputTag = virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(
upStreamVertexID,
downStreamVertexID,
typeNumber,
partitioner,
null,
outputTag,
shuffleMode);
// 当上游是select时,递归调用,并传入select信息,递归寻找非virtual节点
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
shuffleMode = virtualPartitionNodes.get(virtualId).f2;
addEdgeInternal(
upStreamVertexID,
downStreamVertexID,
typeNumber,
partitioner,
outputNames,
outputTag,
shuffleMode);
} else {
// 上游节点
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
// 下游节点
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
// 如果没有指定具体的分区器,且上下游节点的并行度一致使用ForwardPartitioner
// 其他情况都是用RebalancePartitioner
if (partitioner == null
&& upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
// 检查如果指定了ForwardPartitioner但是上下游并行度不一致,则抛出异常
if (partitioner instanceof ForwardPartitioner) {
if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
throw new UnsupportedOperationException(
"Forward partitioning does not allow "
+ "change of parallelism. Upstream operation: "
+ upstreamNode
+ " parallelism: "
+ upstreamNode.getParallelism()
+ ", downstream operation: "
+ downstreamNode
+ " parallelism: "
+ downstreamNode.getParallelism()
+ " You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
// 如果没有执行shuffleMode则使用ShuffleMode.UNDEFINED
// 下面将会详细讲解ShuffleMode的各个枚举值含义
if (shuffleMode == null) {
shuffleMode = ShuffleMode.UNDEFINED;
}
// 创建一个StreamEdge对象
StreamEdge edge =
new StreamEdge(
upstreamNode,
downstreamNode,
typeNumber,
partitioner,
outputTag,
shuffleMode);
// 在输入和输出投添加创建的StreamEdge对象
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}
}
/*---------------------------------------------------------*/
/*---------------------- StreamNode -----------------------*/
// 添加节点输入边
public void addInEdge(StreamEdge inEdge) {
// 检查StreamNode的ID是否匹配
if (inEdge.getTargetId() != getId()) {
throw new IllegalArgumentException("Destination id doesn't match the StreamNode id");
} else {
// 添加到ArrayList对象中
inEdges.add(inEdge);
}
}
// 添加节点输出边
public void addOutEdge(StreamEdge outEdge) {
// 检查StreamNode的ID是否匹配
if (outEdge.getSourceId() != getId()) {
throw new IllegalArgumentException("Source id doesn't match the StreamNode id");
} else {
// 添加到ArrayList对象中
outEdges.add(outEdge);
}
}
/*---------------------------------------------------------*/
// 该枚举类定义了两个算子之间的数据交换方式
public enum ShuffleMode {
// 生产者和消费者同时在线。消费者立即收到生成的数据。这就流式处理。
PIPELINED,
// 生产者首先生产其全部结果并完成。之后,消费者被启动并可以消费数据。这就是批处理模式。
BATCH,
// 属于中间变量,该枚举值代表由框架自身来决定shuffle模式。
// 在运行时只能是PIPELINED或者BATCH
UNDEFINED
}
稍微总结一下,virtualSideOutputNodes,virtualSelectNodes 和 virtualPartitionNodes 的处理逻辑。这几类 transformation 会被处理为虚拟节点。可以看出他们三者的共性是不需要用户传入自定义的处理逻辑,即 userDefinedFunction。虚拟节点严格来说不是 StreamNode 类型(尽管他们都是 StreamNode 对象),不包含物理转换逻辑。
虚拟节点不会出现在 StreamGraph 的处理流中,在添加 edge 的时候如果节点为虚拟节点,会通过递归的方式寻找上游节点,直至找到一个非虚拟节点,再执行添加 edge 逻辑。分区器的相关问题可以看我在【大数据】专栏中的文章,那里有详细的解释。
我们都知道 Flink 中算子的分类其实可以简单分为 Source、Transformation 和 Sink,上文已经分析了 Transformation 类算子转换为 StreamNode 的过程,接下来看一下 SourceTransformation 和 SinkTransformation 如何进行转换的。
/*------------------------ StreamGraph ---------------------------*/
// 用来存储Source
private Set<Integer> sources;
// 用来存储Sink
private Set<Integer> sinks;
// 添加Source节点
public <IN, OUT> void addSource(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
SourceOperatorFactory<OUT> operatorFactory,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName) {
// Source算子的转换和Transformation算子没有什么大的区别
addOperator(
vertexID,
slotSharingGroup,
coLocationGroup,
operatorFactory,
inTypeInfo,
outTypeInfo,
operatorName,
SourceOperatorStreamTask.class);
// 唯一的区别在于要在sources集合中添加一下ID
sources.add(vertexID);
}
// 添加Sink节点
public <IN, OUT> void addSink(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
StreamOperatorFactory<OUT> operatorFactory,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName) {
// Sink算子的转换和Transformation算子没有什么大的区别
addOperator(
vertexID,
slotSharingGroup,
coLocationGroup,
operatorFactory,
inTypeInfo,
outTypeInfo,
operatorName);
if (operatorFactory instanceof OutputFormatOperatorFactory) {
setOutputFormat(
vertexID, ((OutputFormatOperatorFactory) operatorFactory).getOutputFormat());
}
// 唯一的区别在于要在sinks集合中添加一下ID
sinks.add(vertexID);
}
/*---------------------------------------------------------*/
综合示例
以如下程序为例:
DataStreamSource<String> stream = env.readTextFile("input/test.txt");
stream.map(String::toLowerCase)
.keyBy(a -> a.indexOf(0))
.countWindow(1)
.aggregate(new AggregateFunction<String, Integer, Integer>() {
@Override
public Integer createAccumulator() {
return 0;
}
@Override
public Integer add(String value, Integer accumulator) {
return accumulator + value.length();
}
@Override
public Integer getResult(Integer accumulator) {
return accumulator;
}
@Override
public Integer merge(Integer a, Integer b) {
return null;
}
}).print();
其转换流程图如下:
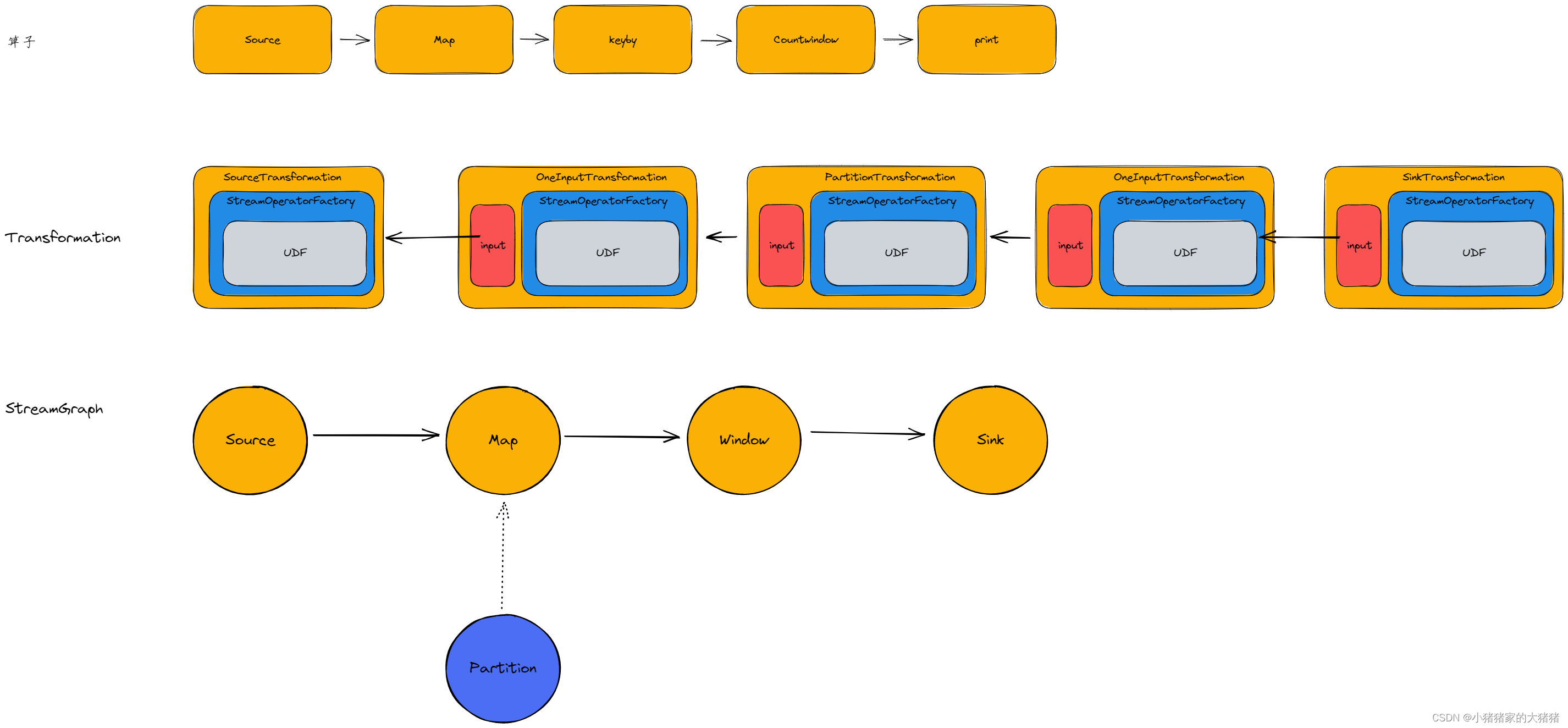
其中 map、countWindow 都是【OneInputTransformation】对象;print 是【SinkTransformation】对象。
总结
首先,用户通过 DataStream API 编写程序,客户端根据编写的程序进行转换得到一系列Transformation对象,然后调用 streamGraphGenerator.generate(env, transformations) 构造出 StreamGraph 对象。
构造 StreamGraph 对象的第一步是遍历 transformations 集合,并对其每一个 Transformation 对象调用 transform() 方法转换为 StreamNode 对象;接着通过构建 StreamEdge 对象进行上、下游 StreamNode 对象的连接,此处需要特别注意,对 PartitionTransformation 等不需要传递 UDF 的 Transformation 对象,都会将其添加到虚拟节点集合中,虽然都是 StreamNode 对象,但是不会构建真正的 StreamEdge;添加完边之后整个 StreamGraph 构造完毕。
往期回顾
- 【Flink】浅谈Flink架构和调度
- 【Flink】详解Flink的八种分区
- 【Flink】浅谈Flink背压问题(1)
- 【分布式】浅谈CAP、BASE理论(1)
文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,相关的知识点也可进行分享,希望大家都能有所收获!!